Java集合:LinkedList (JDK1.8 源码解读)
LinkedList介绍
还是和ArrayList同样的套路,顾名思义,linked,那必然是基于链表实现的,链表是一种线性的储存结构,将储存的数据存放在一个存储单元里面,并且这个存储单元里面还维护了下一个存储单元的地址。在LinkedList的链表储存单元中,不仅存放了下一个存储单元的地址,还存放了上一个单元的储存地址,因为Linked是双向链表,双向链表就是可以通过链表中任意一个存储单元可以获取到上一个存储单元和下一个存储单元。
先看一下这个神秘的储存单元,在LinkedList的内部类中声明:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node就是LinkedList的储存单元,在JDK1.6中叫Entry,不过结构还是一样的,里面有三个变量一个带这三个参数的构造方法,这三个变量分别是
1.item:存储在存储单元Node中的元素
2.next:下一个存储单元
3.prev:下一个存储单元
LinkedList的关注点
1.是否允许为空:是
2.是否允许重复数据:是
3.是否有序:是
4.是否线程安全:否
和之前讲的ArrayList的四个关注点一模一样
LinkedList的声明:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0; transient Node<E> first; transient Node<E> last; ...
}
LinkedList除了实现List、Cloneable和Serializable接口外还实现了Deque接口,说明LinkedList具有队列的特性,可以当做队列使用
举个简单的小栗子:
List<String> list= new LinkedList<>();
list.add("11");
list.add("22");
list.add("33");
LinkedList提供了两种构造方法,例子使用的是第一种也是最常用的无参构造器:
public LinkedList() {
}
这个构造方法没有执行其他任何的操作,这与jdk1.6有所不同,jdk1.6中声明了一个header节点,然后执行了 header.next = header.previous = header,jdk1.8中声明了first和last两个节点,但是构造的时候没有操作这两个节点。
第二种构造器和ArrayList一样提供了一个传入集合的构造方法public LinkedList(Collection<? extends E> c)
添加元素
接着看第二行list.add("11")做了什么:
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
LinkedList的add方法执行的是linkLast方法,linkLast方法就是把元素e链接成列表的最后一个元素,
1.首先声明一个变量l,将这个l指向last也就是列表最后一个节点
2.new一个新的Node节点newNode,这个newNode就是新增元素的储存单元,根据之前给的Node的构造方法,它创建了一个上一个节点为l节点,储存元素为你新增的元素e,下一个节点为null的储存单元
3.将代表列表最后一个节点的last变量指向新的节点newNode,也就是将列表的最后一个储存单元变成了新的newNode节点
4.如果l==null,也就是列表最后一个节点是null,那么列表第一个节点也是newNode,也就是说如果列表是空,newNode就是第一个也是目前唯一一个储存单元,它既是头也是尾。如果之前的最后一个储存单元不是null,就将之前的储存单元的下一个节点地址改为新增的储存单元
可能说的比较绕比较抽象,画图表示一下:
假设null的内存地址是0x0000,新增元素“11”的存储单元地址是0x0001,元素“22”储存单元地址是0x0002,元素“33”储存单元地址是0x0003,每一步修改的地方我都用红色标记出来

查找元素
LinkedList查找元素也是使用的get方法,当然也有别的方法,先看一下get方法怎么写的:
public E get(int index) {
checkElementIndex(index); //index >= 0 && index < size
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
LinkedList查找元素也是先检查下标,检查的判断已经写在第二行的备注中,然后通过node()方法去寻找元素
查询对应下标节点的时候首先用了一个判断,这个判断很有意思,它判断指定下标index是否小于元素个数的一半,如果小于一半也就是你指定的下标位于列表前半段它就从列表第一个节点开始遍历,通过循环获取每个节点的next节点,如果大于一半位于列表后半段就从列表最后一个节点开始遍历,循环获取每个节点的prev节点,这样做的好处就是假如列表有1000个元素,get(999)就得遍历999次才能找到元素,这就是双向链表的好处,通过维护前置节点,虽然增加了编程复杂度,也消耗了更多的空间,却能提升查找效率。
注:即便LinkedList使用了这种巧妙的思想,但是查找速度还是不及ArrayList的随机访问模式,毕竟需要遍历
删除元素
LinkedList删除元素和ArrayList一样支持按照下标删除和按照元素删除,举个例子:
List<String> list = new LinkedList<>();
list.add("11");
list.add("22");
list.add("33");
list.remove(1);
看看remove方法代码:
1 public E remove(int index) {
2 checkElementIndex(index);
3 return unlink(node(index));
4 }
5
6 E unlink(Node<E> x) {
7 // assert x != null;
8 final E element = x.item;
9 final Node<E> next = x.next;
10 final Node<E> prev = x.prev;
11
12 if (prev == null) {
13 first = next;
14 } else {
15 prev.next = next;
16 x.prev = null;
17 }
18
19 if (next == null) {
20 last = prev;
21 } else {
22 next.prev = prev;
23 x.next = null;
24 }
25
26 x.item = null;
27 size--;
28 modCount++;
29 return element;
30 }
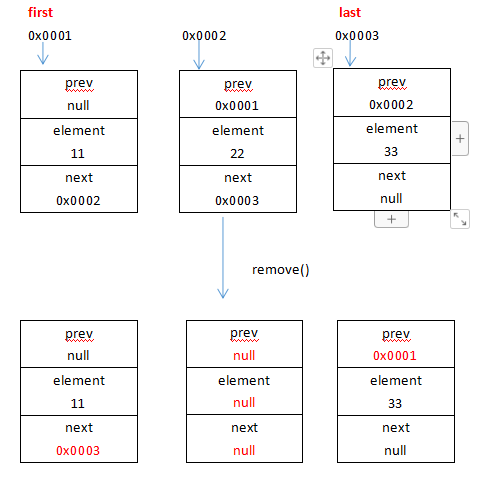
先检查下标,然后通过node方法找到指定下标的元素,交给unlink方法去执行删除的操作,说一下unlink的步骤
1.先获取当前节点x的元素,当前节点x的下一个储存单元节点next和上一个储存单元的节点prev
2.如果上一个储存单元为null,那说明当前节点是链表的第一个节点,所以需要把代表第一个节点的first变量指向当前x节点的next节点,如果下一个储存单元为null,当前节点为链表的最后一个节点,同样的需要把last节点指向x节点的prev节点
3.如果既不是第一个节点也不是最后一个节点这种特殊情况,也就是执行两个else里面的操作,先把x节点的上一个节点的next指向x节点的下一个节点,并且把x.prev赋值null,然后把x节点的下一个节点的prev指向x的上一个节点,并且把x.next赋值null
4.最后把当前x节点的元素赋值null,元素个数减一
经过步骤2和步骤3,成功的切断了x节点这个储存单元与上下节点的联系,经过步骤234把x节点的prev、element、next全部变成了null,让GC去回收它,这个步骤有点绕画图了解一下remove方法的执行:
假设元素‘11’的储存单元的地址是0x0001,元素‘22’的储存单元的地址是0x0002,元素‘33’的储存单元的地址是0x0003,现在first指向0x0001,last指向0x0003,执行list.remove(1)操作,修改的地方我用红色字体标记
插入元素
与ArrayList一样的,Linked同样提供了在指定下标插入元素的方法,之所以放在删除之后讲是因为插入元素和删除执行的操作有些类似,举个例子:
1 List<String> list = new LinkedList<>();
2 list.add("11");
3 list.add("33");
5 list.add(1,"22");
直接看第四行list.add(1,"22")执行了什么:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
还是先检查如果插入的下标(index >= 0 && index <= size),如果下标正好是元素的个数就相当于往链表最后插入一个元素,执行之前介绍过的linkLast方法,大部分情况插入都是往链表中间插入元素执行linkBefore方法:
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
往列表中间插入元素的话会先使用node方法查到对应下标的储存单元节点,记录此节点的前置节点prev,然后新建一个前置节点为index下标原储存单元前置节点、元素为e、后置节点为index下标原储存单元的储存单元节点,如果前置节点为nulll,就将first节点指向新建的节点,否则将index下标原储存单元的前置节点改为新增的节点newNode,如图:
假设元素‘11’的储存单元的地址是0x0001,元素‘33’的储存单元的地址是0x0002,新插入的元素‘22’的储存单元的地址是0x0002,现在first指向0x0001,last指向0x0002,执行list.add(1,"22")操作,修改的地方我用红色字体标记

图上半部分是插入前,图下半部分是插入后,抛开插入和删除的储存单元不谈,这两个操作都是改变上一个储存单元节点的next地址和下一个储存单元的prev地址,是不是很相似?所以只要理解了LinkedList的这种结构,LinkedList这些操作也是很好理解的。
拿ArrayList对比总结一下LinkedList
1.查找元素的速度,如果是按照下标查找那么ArrayList效率肯定是高于LinkedList的,ArrayList支持随机访问,而LinkedList需要遍历
2.顺序添加元素,虽然LinkedList顺序添加也比较方便,但是需要new对象并且需要修改一些储存单元的引用,而ArrayList的数组是事先new好的,只需要往指定位置插入元素就行,所以大部分情况下ArrayList优于LinkedList,特殊情况ArrayList添加元素需要扩容了,随着元素数量的增加,ArrayList扩容会越来越慢
3.删除插入的速度,LinkedList删除插入操作效率几乎是固定的,先寻址,后修改前后Node的next、prev引用地址,而ArrayList寻址较快,慢在复制数组元素,所以如果插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList;越往后,ArrayList要批量copy的元素越来越少,速度会越来越快,所以删除插入操作并不能说谁一定快
4.遍历元素,前面说过ArrayList是实现了RandomAccess接口的支持随机访问,而LinkedList是没有实现这个接口的,所以ArrayList在使用普通for循环会更快,而LinkedList使用foreach循环会更快,那么它们使用各自最快的遍历方式谁更快呢?
我们做个测试:
public class TestList {
private static int size = 100000;
public static void loop(List<Integer> list){
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.get(i);
}
System.out.println(list.getClass().getSimpleName() + "for循环遍历时间:" + (System.currentTimeMillis() - startTime) + "ms");
startTime = System.currentTimeMillis();
for (Integer i: list) {
}
System.out.println(list.getClass().getSimpleName() + "foreach循环遍历时间:" + (System.currentTimeMillis() - startTime) + "ms");
}
public static void main(String[] args) {
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < size; i++) {
arrayList.add(i);
linkedList.add(i);
}
loop(arrayList);
loop(linkedList);
}
}
执行多次的结果:
ArrayListfor循环遍历时间:3ms
ArrayListforeach循环遍历时间:4ms
LinkedListfor循环遍历时间:4638ms
LinkedListforeach循环遍历时间:3ms ArrayListfor循环遍历时间:2ms
ArrayListforeach循环遍历时间:4ms
LinkedListfor循环遍历时间:4753ms
LinkedListforeach循环遍历时间:2ms ArrayListfor循环遍历时间:3ms
ArrayListforeach循环遍历时间:4ms
LinkedListfor循环遍历时间:4520ms
LinkedListforeach循环遍历时间:2ms
从执行测试程序的时候就可以看出来,LinkedList使用普通for循环遍历出奇的慢,而在使用foreach遍历的时候LinkedList遍历明显更快,甚至略优于ArrayList的foreach遍历,所以在数据量比较大的情况下,千万不要使用普通for循环遍历LinkedList
Java集合:LinkedList (JDK1.8 源码解读)的更多相关文章
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Java集合:ArrayList (JDK1.8 源码解读)
ArrayList ArrayList几乎是每个java开发者最常用也是最熟悉的集合,看到ArrayList这个名字就知道,它必然是以数组方式实现的集合 关注点 说一下ArrayList的几个特点,也 ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- Java集合 - List介绍及源码解析
(源码版本为 JDK 8) 集合类在java.util包中,类型大体可以分为3种:Set.List.Map. JAVA 集合关系(简图) (图片来源网络) List集合和Set集合都是继承Collec ...
- HashMap底层原理及jdk1.8源码解读
一.前言 写在前面:小编码字收集资料花了一天的时间整理出来,对你有帮助一键三连走一波哈,谢谢啦!! HashMap在我们日常开发中可谓经常遇到,HashMap 源码和底层原理在现在面试中是必问的.所以 ...
- Java集合系列:-----------03ArrayList源码分析
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- 【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
1.HashMap的概念 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io ...
- Java集合系列[1]----ArrayList源码分析
本篇分析ArrayList的源码,在分析之前先跟大家谈一谈数组.数组可能是我们最早接触到的数据结构之一,它是在内存中划分出一块连续的地址空间用来进行元素的存储,由于它直接操作内存,所以数组的性能要比集 ...
随机推荐
- Unity基于NGUI的简单并可直接使用的虚拟摇杆实现(一)
可能大家都听说过大名鼎鼎的easytouch,然而easytouch是基于UGUI的,两种不同的UI混用,可能会造成项目管理的混乱,并且可能会出现各种幺蛾子,比如事件传递互相扰乱的问题. 于是就想找一 ...
- 学习TensorFlow的第一天
https://www.cnblogs.com/wangxiaocvpr/p/5902086.html
- FTP工具-FileZilla安装使用教程
1.首先,百度搜索“FileZilla”,进入官网,下载地址:https://www.filezilla.cn/download/client ,根据自己电脑配置去下载 2.下载本地,双击运行安装程 ...
- 阿里P8Java大牛仅用46张图让你弄懂JVM的体系结构与GC调优。
本PPT从JVM体系结构概述.GC算法.Hotspot内存管理.Hotspot垃圾回收器.调优和监控工具六大方面进行讲述.图文并茂不生枯燥. 此PPT长达46页,全部展示篇幅过长,本文优先分享前十六页 ...
- Spring系列(二):Spring IoC应用
一.Spring IoC的核心概念 IoC(Inversion of Control 控制反转),详细的概念见Spring系列(一):Spring核心概念 二.Spring IoC的应用 1.定义B ...
- 关于JVM内存溢出的原因分析及解决方案探讨
前言:JVM中除了程序计数器,其他的区域都有可能会发生内存溢出. 0.什么是内存溢出 当程序需要申请内存的时候,由于没有足够的内存,此时就会抛出OutOfMemoryError,这就是内存溢出. 1. ...
- android ——悬浮按钮及可交互提示
一.悬浮按钮 FloatingActionButton是Design Support中的一个控件,它会默认colorAccent作为按钮的颜色,还可以给按钮一个图标. 这是没有图标的,这是有图标的. ...
- 洛谷 P5367 【模板】康托展开(数论,树状数组)
题目链接 https://www.luogu.org/problem/P5367 什么是康托展开 百度百科上是这样说的: “康托展开是一个全排列到一个自然数的双射,常用于构建哈希表时的空间压缩. ...
- linux后台运行的几种方式
1.nohup将程序以忽略挂起信号的方式运行起来 补充说明nohup命令 可以将程序以忽略挂起信号的方式运行起来,被运行的程序的输出信息将不会显示到终端.无论是否将 nohup 命令的输出重定向到终端 ...
- Sublime Text 3 使用手册
Ctrl+Shift+P:打开命令面板 Ctrl+P:搜索项目中的文件 Ctrl+G:跳转到第几行 Ctrl+W:关闭当前打开文件 Ctrl+Shift+W:关闭所有打开文件 Ctrl+Shift+V ...