深入理解 ZK集群中通过Processor保证数据一致性
入口
书接上篇博客中的ZK集群启动后完成数据的统一性恢复后,来到启动ZkServer的逻辑,接下来的重点工作就是启动不同角色的对应的不同的处理器Processor
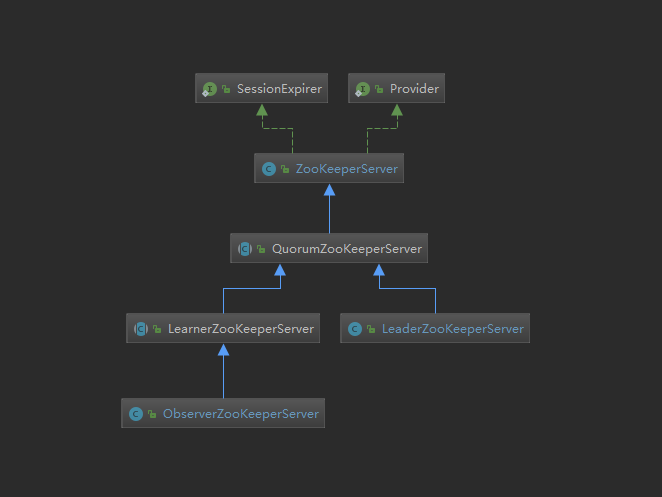
如上图查看ZooKeeperServer的继承图,三种不同的角色有不同的ZooKeeperServer的实现逻辑类
三者启动时,都将会来到ZooKeeperServer.java中的startUp()方法中,源码如下,但是,不同的角色针对setupRequestProcessors();进行了不同的重写,所以本篇博客的重点即使看一下他们是如何重写的
public synchronized void startup() {
if (sessionTracker == null) {
// todo 创建session计时器
createSessionTracker();
}
// todo 开启计时器
startSessionTracker();
// todo 设置请求处理器, zookeeper中存在不同的请求处理器, 就在下面
setupRequestProcessors();
//todo 是一个为应用程序、设备、系统等植入管理功能的框架。
//todo JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用
registerJMX();
// todo 修改状态 --> running
setState(State.RUNNING);
// todo 唤醒所有线程, 因为前面有一个线程等待处理器 睡了一秒
notifyAll();
}
Leader重写setupRequestProcessors
源码如下: 可以看到它初始化的处理器的个数
- PrepRequestProcessor (checkAcl 构造tnx)
- ProposalRequestProcessor (发起提议)
- CommitProcessor (提交提议)
- ToBeAppliedRequestProcessor
- FinalRequestProcessor (响应客户端,更新内存)
SyncRequestProcessor(单独开启的,他是一个线程) 作用: 持久化txn
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(
finalProcessor, getLeader().toBeApplied);
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false,
getZooKeeperServerListener());
commitProcessor.start();
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,
commitProcessor);
proposalProcessor.initialize();
firstProcessor = new PrepRequestProcessor(this, proposalProcessor);
((PrepRequestProcessor)firstProcessor).start();
Follower重写setupRequestProcessors
- FollowerRequestProcessor
- CommitProcessor
- SendAckRequestProcessor
- FinalRequestProcessor
SyncRequestProcessor(单独开启的,他是一个线程) 作用: 持久化txn
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this,
new SendAckRequestProcessor((Learner) getFollower()));
syncProcessor.start();
Observer重写setupRequestProcessors
- ObserverRequestProcessor
- CommitProcessor
- FinalRequestProcessor
通过配置判断是否添加
SyncRequestProcessor来持久化它的事务
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new ObserverRequestProcessor(this, commitProcessor);
((ObserverRequestProcessor) firstProcessor).start();
// todo 通过这个判断控制需不需要Observer 对事务进行持久化
if (syncRequestProcessorEnabled) {
syncProcessor = new SyncRequestProcessor(this, null);
syncProcessor.start();
}
实验1: Leader接受到写请求
直接给出当Leader接收到请求时,request在集群中各个处理器中的运行流程图
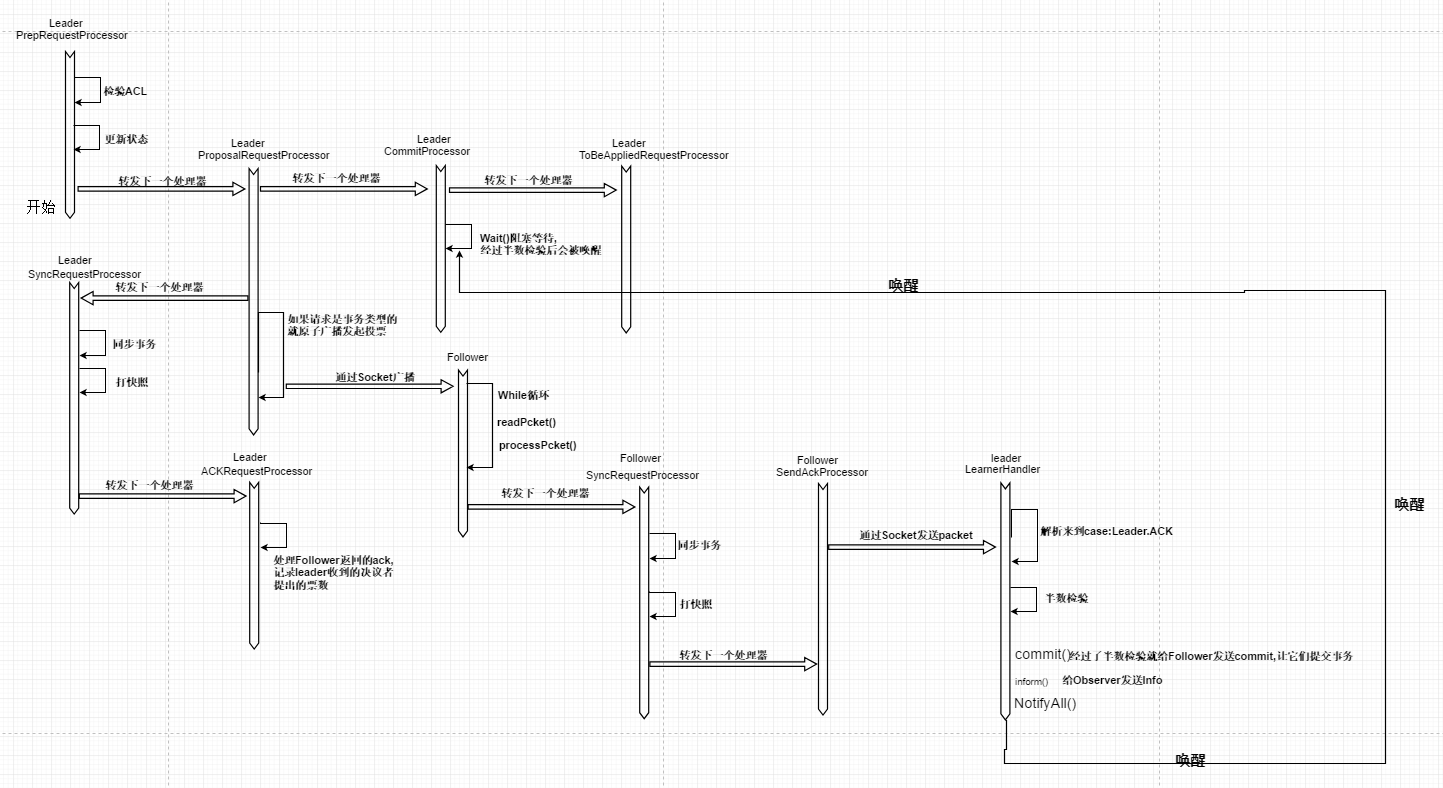
通过上图看,当leader接收到请求后,request肯定会依次流经它的处理器,PrepRequestProcessor-->ProposalRequestProcessor
在ProposalRequestProcessor处理器中,同样是直接将request提交给CommitProcessor,但是同样会被阻塞住
接着在request被Leader通过原子广播,告诉所有的Follower这个request
原子广播之后自己会立即使用SyncRequestProcessor完成持久化
同时Follower接受到request之后,也会使用他们自己的SyncRequestProcess进行持久化,完成持久化后就给Leader的LearnerHandler发送ACK确认消息,在这个LearnerHandler会存在过半检查机制,没当一个Follower发送一个ACK,就触发检查一次,直到达到一半以上,就会触发notify(),然后leader刚刚在commitProcessor中wait(),等待提交的函数就会被唤醒,由leader广播commit,全体learner进行commit,达成数据的一致性
实验2: Follower或Observer接收到写请求
直接给出当Follower或者Observer接收到请求时,request在集群中各个处理器中的运行流程图
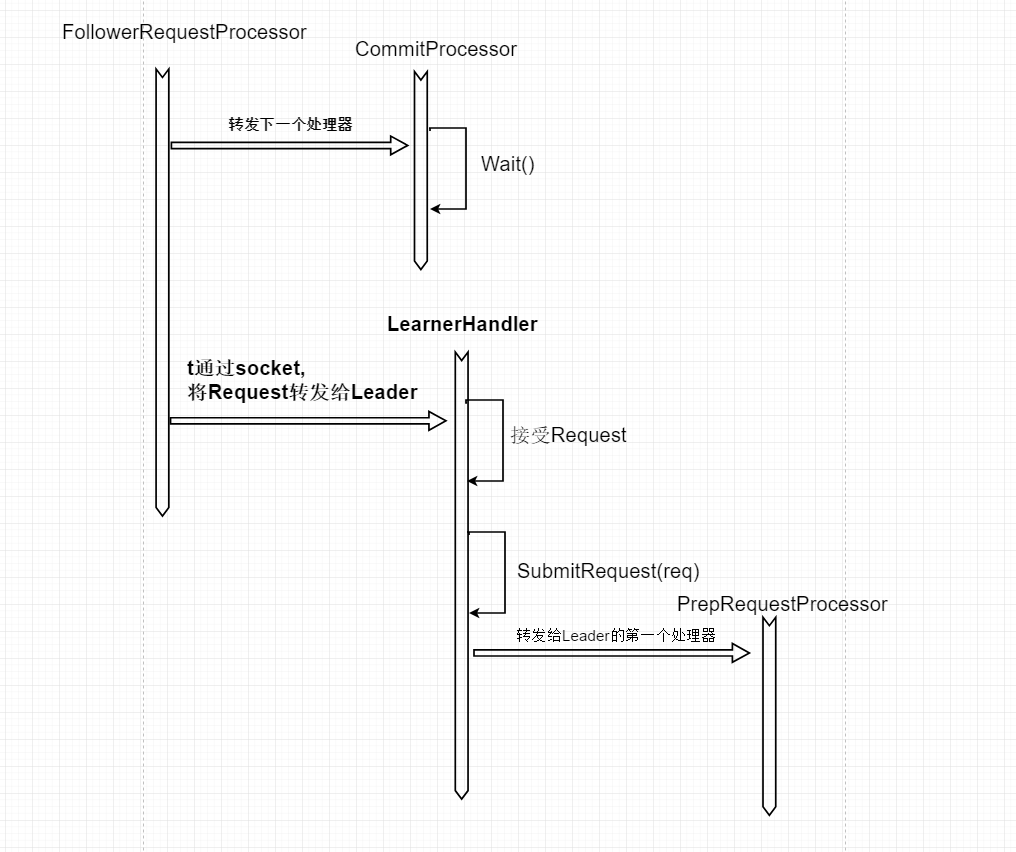
通过上面图可以看到,当Follower或者Observer接收到请求后会首先会提交给本地的commitProcessor处理器,但是不会立刻commit事务,而是将request转发给Leader的第一个处理器,再之后就和上面的图同样的处理流程
深入理解 ZK集群中通过Processor保证数据一致性的更多相关文章
- ZK集群如何保证数据一致性源码阅读
什么是数据一致性? 只有当服务端的ZK存在多台时,才会出现数据一致性的问题, 服务端存在多台服务器,他们被划分成了不同的角色,只有一台Leader,多台Follower和多台Observer, 他们中 ...
- ZK集群的Leader选举源码阅读
前言 ZooKeeper对Zab协议的实现有自己的主备模型,即Leader和learner(Observer + Follower),有如下几种情况需要进行领导者的选举工作 情形1: 集群在启动的过程 ...
- 搭建互联网架构学习--006--duboo准备之zk集群部署安装
dubbo集群部署安装依赖于zookeeper,所以先安装zookeeper集群. 1.准备三台机器做集群 2.配置 配置java环境 ,2,修改操作系统的/etc/hosts文件,添加IP与主机名 ...
- 在开启DRS的集群中修复VMware虚拟主机启动问题
通过iSCSI方式连接到ESXi主机上的外挂存储意外失联了一段时间,导致部分虚拟主机在集群中呈现出孤立的状态,单独登陆到每台ESXi上可以看到这些虚拟主机都变成了unknow状态.因为有过上一次(VM ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- Storm集群中执行的各种组件及其并行
一.Storm中执行的组件 我们知道,Storm的强大之处就是能够非常easy地在集群中横向拓展它的计算能力,它会把整个运算过程切割成多个独立的tasks在集群中进行并行计算.在Storm中 ...
- kafka集群中常见错误的解决方法:kafka.common.KafkaException: Should not set log end offset on partition
问题描述:kafka单台机器做集群操作是没有问题的,如果分布多台机器并且partitions或者备份的个数大于1都会报kafka.common.KafkaException: Should not s ...
- 用Go造轮子-管理集群中的配置文件
写在前面 最近一年来,我都在做公司的RTB广告系统,包括SSP曝光服务,ADX服务和DSP系统.因为是第一次在公司用Go语言实现这么一个大的系统,中间因为各种原因造了很多轮子.现在稍微有点时间,觉着有 ...
- 单机器搭建 zk 集群
在一台机器上配置 2 节点的 zk 集群,zk1 和 zk2 的 serverid 分别为 1 和 2,本机 ip 是 192.168.40.1 zk1 相关配置: dataDir=E:/test/z ...
随机推荐
- @PathVariable 处理参数为空的情况
@RequestMapping(value = "/get/{id}/{userId}", method = RequestMethod.GET) public Result ge ...
- Spring Boot 自动装配(一)
目录 目录 前言 1.起源 2.Spring 模式注解 2.1.装配方式 2.2.派生性 3.Spring @Enable 模块驱动 3.1.Spring框架中@Enable实现方式 3.2.自定义@ ...
- DRF Django REST framework APIView(一)
什么是REST? REST是一个标准,一种规范,遵循REST风格可以使开发的接口通用,便于调用者理解接口的作用. 使url更容易理解,让增删改清晰易懂,在前后端分离开发中按照这一规范能加快开发效率,减 ...
- C#程序编写高质量代码改善的157个建议【13-15】[为类型输出格式化字符串、实现浅拷贝和深拷贝、用dynamic来优化反射]
前言 本文已更新至http://www.cnblogs.com/aehyok/p/3624579.html .本文主要学习记录以下内容: 建议13.为类型输出格式化字符串 建议14.正确实现浅拷贝和深 ...
- 全栈项目|小书架|微信小程序-实现搜索功能
效果图 上图是小程序端实现的搜索功能效果图. 从图中可以看出点击首页搜索按钮即可进入搜索页面. 布局样式是:搜索框 + 热搜内容 + 搜索列表. 搜索框使用 lin-ui 中的 Searchbar组件 ...
- springboot整合thymleaf模板引擎
thymeleaf作为springboot官方推荐使用的模板引擎,简单易上手,功能强大,thymeleaf的功能和jsp有许多相似之处,两者都属于服务器端渲染技术,但thymeleaf比jsp的功能更 ...
- 简而意赅 HTTP HTTPS SSL TLS 之间有什么不同
HTTP HTTPS SSL TLS 之间有什么不同? SSL是Secure Sockets Layer的缩写.SSL的作用是为网络上的两台机器或设备提供了一个安全的通道. TLS是SSL的一个新的名 ...
- Unity3D for iOS初级教程:Part 3/3(下)
转自:http://www.cnblogs.com/alongu3d/archive/2013/06/01/3111739.html 消息不会自动消除 你基本的游戏功能已经完成了,但是显示一些关于游戏 ...
- 【原创】(十三)Linux内存管理之vma/malloc/mmap
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- AtCoder-3867
Find the maximum possible sum of the digits (in base 10) of a positive integer not greater than N. C ...