Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1、主机规划
序号
主机名
IP地址
角色
1
nn-1
192.168.9.21
NameNode、mr-jobhistory、zookeeper、JournalNode
2
nn-2
192.168.9.22
Secondary NameNode、JournalNode
3
dn-1
192.168.9.23
DataNode、JournalNode、zookeeper、ResourceManager、NodeManager
4
dn-2
192.168.9.24
DataNode、zookeeper、ResourceManager、NodeManager
5
dn-3
192.168.9.25
DataNode、NodeManager
集群说明:
(1)、对于集群规模小于7台和以下的, 可以不做NameNode HA。
(2)、HA的集群, JournalNode节点要在3个以上, 建议设置成5个节点。JournalNode是轻量级服务, 为了本地性, 其中两个JournalNode和两台NameNode节点复用。其他JournalNode和分散在其他节点上。
(3)、HA的集群,zookeeper节点要在3个以上, 建议设置成5个或者7个节点。zookeeper可以和DataNode节点复用。
(4)、HA的集群,ResourceManager建议单独一个节点。对于较大规模的集群,且有空闲的主机资源, 可以考虑设置ResourceManager的HA。
2、主机环境设置
2.1 配置JDK
卸载OpenJDK:
--查看java版本[root@dtgr ~]# java -versionjava version "1.7.0_45"OpenJDK Runtime Environment (rhel-2.4.3.3.el6-x86_64 u45-b15)OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)--查看安装源
[root@dtgr ~]# rpm -qa | grep javajava-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64-- 卸载[root@dtgr ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64- --验证是否卸载成功
[root@dtgr ~]# rpm -qa | grep java[root@dtgr ~]# java -version-bash: /usr/bin/java: 没有那个文件或目录
安装jdk:
-- 下载并解压java源码包[root@dtgr java]# mkdir /usr/local/java[root@dtgr java]# mv jdk-7u79-linux-x64.tar.gz /usr/local/java[root@dtgr java]# cd /usr/local/java[root@dtgr java]# tar xvf jdk-7u79-linux-x64.tar.gz[root@dtgr java]# lsjdk1.7.0_79 jdk-7u79-linux-x64.tar.gz[root@dtgr java]# --- 添加环境变量[root@dtgr java]# vim /etc/profile[root@dtgr java]# tail /etc/profileexport JAVA_HOME=/usr/local/java/jdk1.7.0_79export JRE_HOME=/usr/local/java/jdk1.7.0_79/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATHexport PATH=$JAVA_HOME/bin:$PATH-- 生效环境变量[root@dtgr ~]# source /etc/profile-- 验证[root@dtgr ~]# java -versionjava version "1.7.0_79"Java(TM) SE Runtime Environment (build 1.7.0_79-b15)Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)[root@dtgr ~]# javac -versionjavac 1.7.0_79
2.2 修改主机名和配置主机名解析
在所有节点按照规划修改主机名, 并将主机名加入/etc/hosts文件。
修改主机名:
[root@dn-3 ~]# cat /etc/sysconfig/networkNETWORKING=yesHOSTNAME=dn-3[root@dn-3 ~]# hostname dn-3
配置/etc/hosts, 并分发到所有节点:
[root@dn-3 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.9.21 nn-1192.168.9.22 nn-2192.168.9.23 dn-1192.168.9.24 dn-2192.168.9.25 dn-3
2.3 新建hadoop账户
用户和组均为hadoop, 密码为hadoop, home目录为/hadoop。
[root@dn-3 ~]# useradd -d /hadoop hadoop
2.4 配置ntp时钟同步
将nn-1主机作为时钟源)
#vi /etc/ntp.conf
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
server nn-1
配置ntp服务自启动
#chkconfig ntpd on
启动ntp服务
#service ntpd start
2.5 关闭防火墙iptables和selinux
(1)、关闭iptables
[root@dn-3 ~]# service iptables stop[root@dn-3 ~]# chkconfig iptables off[root@dn-3 ~]# chkconfig --list | grep iptablesiptables 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭[root@dn-3 ~]#
(2)、关闭selinux
[root@dn-3 ~]# setenforce 0setenforce: SELinux is disabled[root@dn-3 ~]# vim /etc/sysconfig/selinux
SELINUX=disabled
2.6 设置ssh无密码登陆
(1)、在所有节点生成密钥
所有节点, 切换到hadoop用户下,生成密钥,一路回车:
[hadoop@nn-1 ~]$ ssh-keygen -t rsa
(2)、在nn-1上面,将公钥复制到文件authorized_keys中:
命令:$ ssh 主机名 'cat ./.ssh/id_rsa.pub' >> authorized_keys
将上面的命令的主机名替换成实际的主机名, 在nn-1上面将所有的主机都执行一次,包括自己, 如下示例:
[hadoop@nn-1 ~]$ ssh nn-1 'cat ./.ssh/id_rsa.pub' >> authorized_keyshadoop@nn-1's password:
(3)、设置权限
[hadoop@nn-1 .ssh]$ chmod 644 authorized_keys
(4)、将authorized_keys分发到所有节点: $HOME/.ssh/ 。
如下示例:
[hadoop@nn-1 .ssh]$ scp authorized_keys hadoop@nn-2:/hadoop/.ssh/
3、安装配置Hadoop
说明: 先在nn-1上面修改配置, 配置完毕批量分发到其他节点。
3.1 上传hadoop、zookeeper安装包
复制安装包到/hadoop目录下。
解压安装包: [hadoop@nn-1 ~]$ tar -xzvf hadoop2-js-0121.tar.gz
3.2 修改hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export HADOOP_HEAPSIZE=2000export HADOOP_NAMENODE_INIT_HEAPSIZE=10000export HADOOP_OPTS="-server $HADOOP_OPTS -Djava.net.preferIPv4Stack=true"export HADOOP_NAMENODE_OPTS="-Xmx15000m -Xms15000m -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
3.3 修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://dpi</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/hadoop/hdfs/temp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.hduser.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hduser.groups</name> <value>*</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>dn-1:2181,dn-2:2181,dn-3:2181</value> </property></configuration>
3.4 修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>nn-1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/hdfs/data,file:/hadoopdata/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.nameservices</name> <value>dpi</value> </property> <property> <name>dfs.ha.namenodes.dpi</name> <value>nn-1,nn-2</value> </property> <property> <name>dfs.namenode.rpc-address.dpi.nn-1</name> <value>nn-1:9000</value> </property> <property> <name>dfs.namenode.http-address.dpi.nn-1</name> <value>nn-1:50070</value> </property> <property> <name>dfs.namenode.rpc-address.dpi.nn-2</name> <value>nn-2:9000</value> </property> <property> <name>dfs.namenode.http-address.dpi.nn-2</name> <value>nn-2:50070</value> </property> <property> <name>dfs.namenode.servicerpc-address.dpi.nn-1</name> <value>nn-1:53310</value> </property> <property> <name>dfs.namenode.servicerpc-address.dpi.nn-2</name> <value>nn-2:53310</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://nn-1:8485;nn-2:8485;dn-1:8485/dpi</value> </property> <property> <name>dfs.client.failover.proxy.provider.dpi</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/hadoop/hdfs/journal</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/hadoop/.ssh/id_rsa</value> </property></configuration>
新建配置文件中的目录:
mkdir -p /hadoop/hdfs/namemkdir -p /hadoop/hdfs/datamkdir -p /hadoop/hdfs/tempmkdir -p /hadoop/hdfs/journal授权:chmod 755 /hadoop/hdfsmkdir -p /hadoopdata/hdfs/datachmod 755 /hadoopdata/hdfs
属主和属组修改为:hadoop:hadoop
3.5 修改mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>nn-1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>nn-1:19888</value> </property></configuration>
3.6 修改yarn-site.xml
启用yarn ha功能, 根据规划, dn-1和dn-2为ResourceManager节点
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>dn-1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>dn-2</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>dn-1:2181,dn-2:2181,dn-3:2181</value> <description>For multiple zk services, separate them with comma</description> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property></configuration>
3.7 修改slaves
将所有的DataNode节点加入到slaves文件中:
dn-1dn-2dn-3
3.8 修改yarn-env.sh
# some Java parameters# export JAVA_HOME=/home/y/libexec/jdk1.6.0/if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=/usr/local/java/jdk1.7.0_79fiJAVA_HEAP_MAX=-Xmx15000mYARN_HEAPSIZE=15000export YARN_RESOURCEMANAGER_HEAPSIZE=5000export YARN_TIMELINESERVER_HEAPSIZE=10000export YARN_NODEMANAGER_HEAPSIZE=10000
3.9 分发配置好的hadoop目录到所有节点
[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@nn-2:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-2:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-3:/hadoop
4 安装配置zookeeper
切换到hadoop目录下面, 根据规划, 三台zookeeper节点为:nn-1, dn-1, dn-2。
先在nn-1节点配置zookeeper, 然后分发至三个zookeeper节点:
4.1 在nn-1上传并解压zookeeper
4.2 修改配置文件/hadoop/zookeeper/conf/zoo.cfg
dataDir=/hadoop/zookeeper/data/dataLogDir=/hadoop/zookeeper/log/# the port at which the clients will connectclientPort=2181server.1=nn-1:2887:3887server.2=dn-1:2888:3888server.3=dn-2:2889:3889
4.3 从nn-1分发配置的zookeeper目录到其他节点
[hadoop@nn-1 ~]$ scp -rp zookeeper hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp zookeeper hadoop@dn-2:/hadoop
4.4 在所有zk节点创建目录
[hadoop@dn-1 ~]$ mkdir /hadoop/zookeeper/data/[hadoop@dn-1 ~]$ mkdir /hadoop/zookeeper/log/
4.5 修改myid
在所有zk节点, 切换到目录/hadoop/zookeeper/data,创建myid文件:
注意:myid文件的内容为zoo.cfg文件中配置的server.后面的数字(即nn-1为1,dn-1为2,dn-2为3)。
在nn-1节点的myid内容为:
[hadoop@nn-1 data]$ echo 1 > /hadoop/zookeeper/data/myid
其他zk节点也安要求创建myid文件。
4.6 设置环境变量
$ echo "export ZOOKEEPER_HOME=/hadoop/zookeeper" >> $HOME/.bash_profile$ echo "export PATH=$ZOOKEEPER_HOME/bin:\$PATH" >> $HOME/.bash_profile$ source $HOME/.bash_profile
5 集群启动
5.1 启动zookeeper
根据规划, zk的节点为nn-1、dn-1和dn-2, 在这三台节点分别启动zk:
启动命令:
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh startJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgStarting zookeeper ... STARTED
查看进程, 可以看到QuorumPeerMain:
[hadoop@nn-1 ~]$ jps9382 QuorumPeerMain9407 Jps
查看状态, 可以看到Mode: follower, 说明这是zk的从节点:
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: follower
查看状态, 可以看到Mode: leader, 说明这是zk的leader节点:
[hadoop@dn-1 data]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: leader
5.2 格式化zookeeper集群(只做一次)(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hdfs zkfc -formatZK
中间有个交互的步骤, 输入Y:
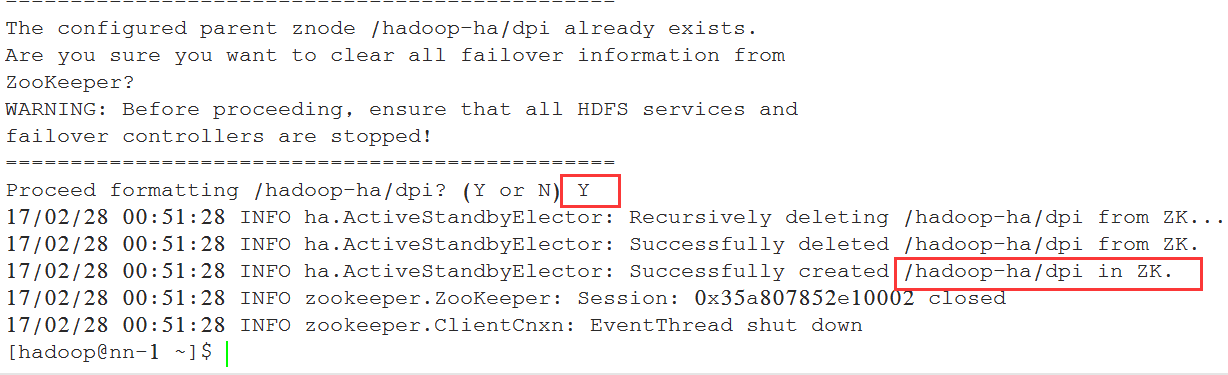 进入zk, 查看是否创建成功:
进入zk, 查看是否创建成功:
[hadoop@nn-1 bin]$ ./zkCli.sh

5.3 启动zkfc(机器nn-1,nn-2上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start zkfcstarting zkfc, logging to /hadoop/hadoop/logs/hadoop-hadoop-zkfc-nn-1.out
使用jps, 可以看到进程DFSZKFailoverController:
[hadoop@nn-1 ~]$ jps9681 Jps9638 DFSZKFailoverController9382 QuorumPeerMain
5.4 启动journalnode
根据规划, 启动journalnode节点为nn-1、nn-2和dn-1, 在这三个节点分别使用如下的命令启动服务:
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /hadoop/hadoop/logs/hadoop-hadoop-journalnode-nn-1.out
使用jps命令可以看到进程JournalNode:
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain9762 Jps
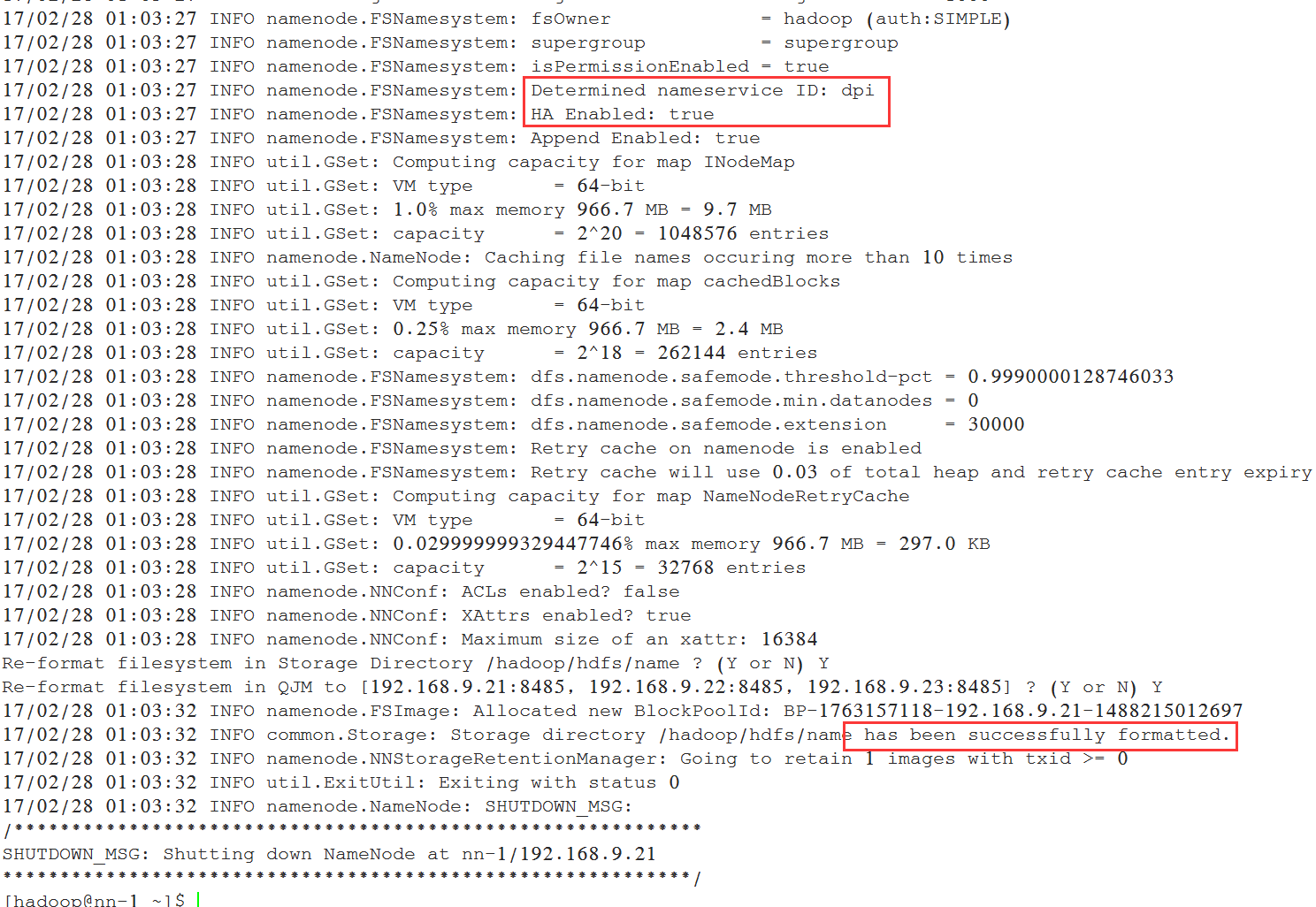
5.5 格式化namenode(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hadoop namenode -format
查看日志信息:
5.6 启动namenode(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
使用jps命令可以看到进程NameNode:
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain10157 NameNode10269 Jps
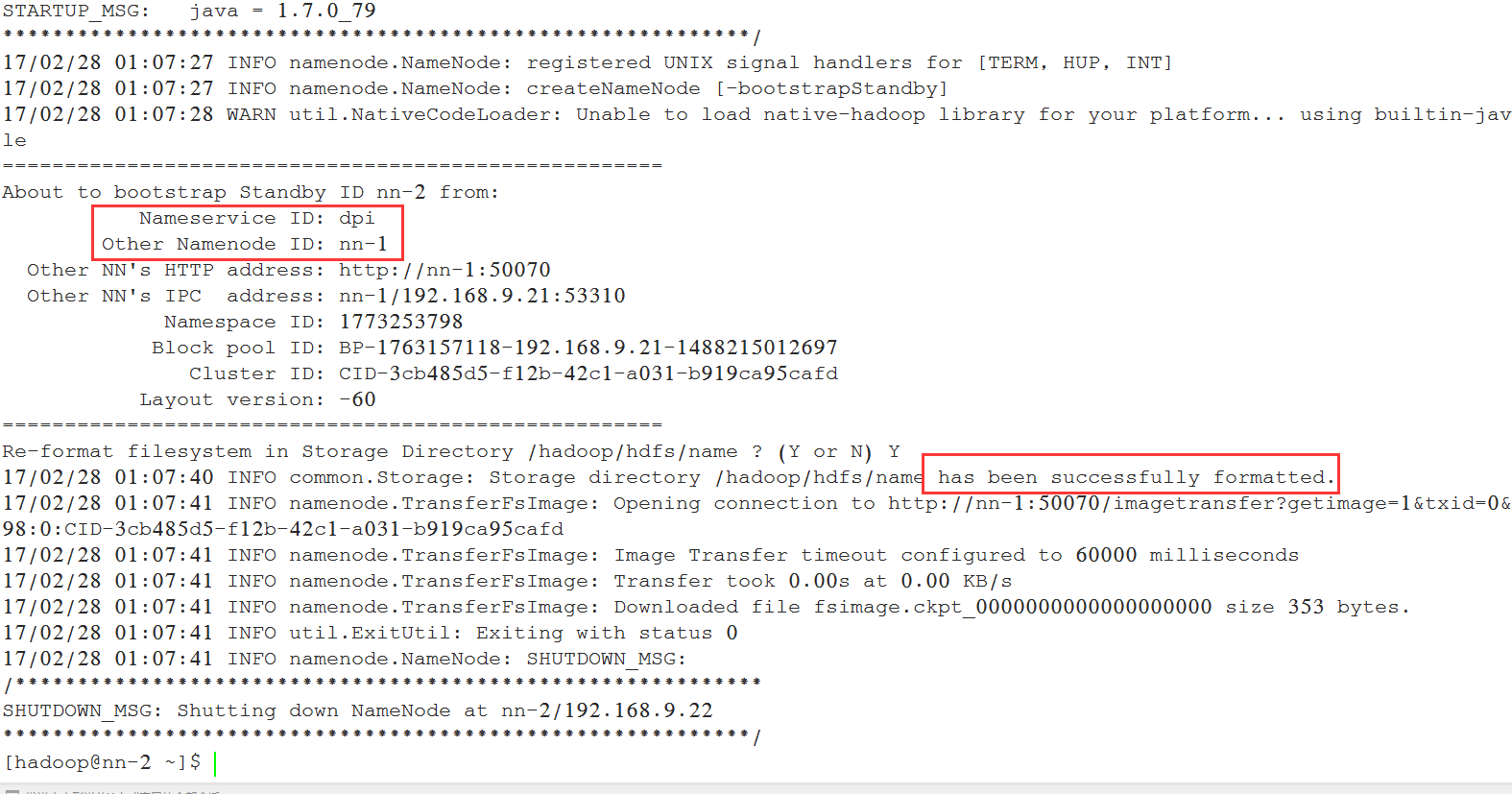
5.7 格式化secondnamnode(机器nn-2上执行)
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs namenode -bootstrapStandby
部分日志如下:
5.8 启动namenode(机器nn-2上执行)
[hadoop@nn-2 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-2.out
使用jps命令可以看到进程NameNode:
[hadoop@nn-2 ~]$ jps53990 NameNode54083 Jps53824 JournalNode53708 DFSZKFailoverController
5.9 启动datanode(机器dn-1到dn-3上执行)
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start datanode
使用jps可以看到DataNode进程:
[hadoop@dn-1 temp]$ jps57007 Jps56927 DataNode56223 QuorumPeerMain
5.10 启动resourcemanager
根据规划,resourcemanager做了HA, 服务在节点dn-1和dn-2上面, 在dn-1和dn-2上面启动resourcemanager:
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-resourcemanager-dn-1.out
使用jps, 可以看到进程ResourceManager:
[hadoop@dn-1 ~]$ jps57173 QuorumPeerMain58317 Jps57283 JournalNode58270 ResourceManager58149 DataNode
5.11 启动jobhistory
根据规划, jobhistory服务在nn-1上面, 使用如下命令启动:
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /hadoop/hadoop/logs/mapred-hadoop-historyserver-nn-1.out
使用jps, 可以看到进程JobHistoryServer:
[hadoop@nn-1 ~]$ jps11210 JobHistoryServer9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain11039 NameNode11303 Jps
5.12 启动NodeManager
根据规划, dn-1、dn-2和dn-3是nodemanager, 在这三个节点启动NodeManager:
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start nodemanagerstarting nodemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-nodemanager-dn-1.out
使用jps可以看到进程NodeManager:
[hadoop@dn-1 ~]$ jps58559 NodeManager57173 QuorumPeerMain58668 Jps57283 JournalNode58270 ResourceManager58149 DataNode
6、安装后查看和验证
6.1 HDFS相关操作命令
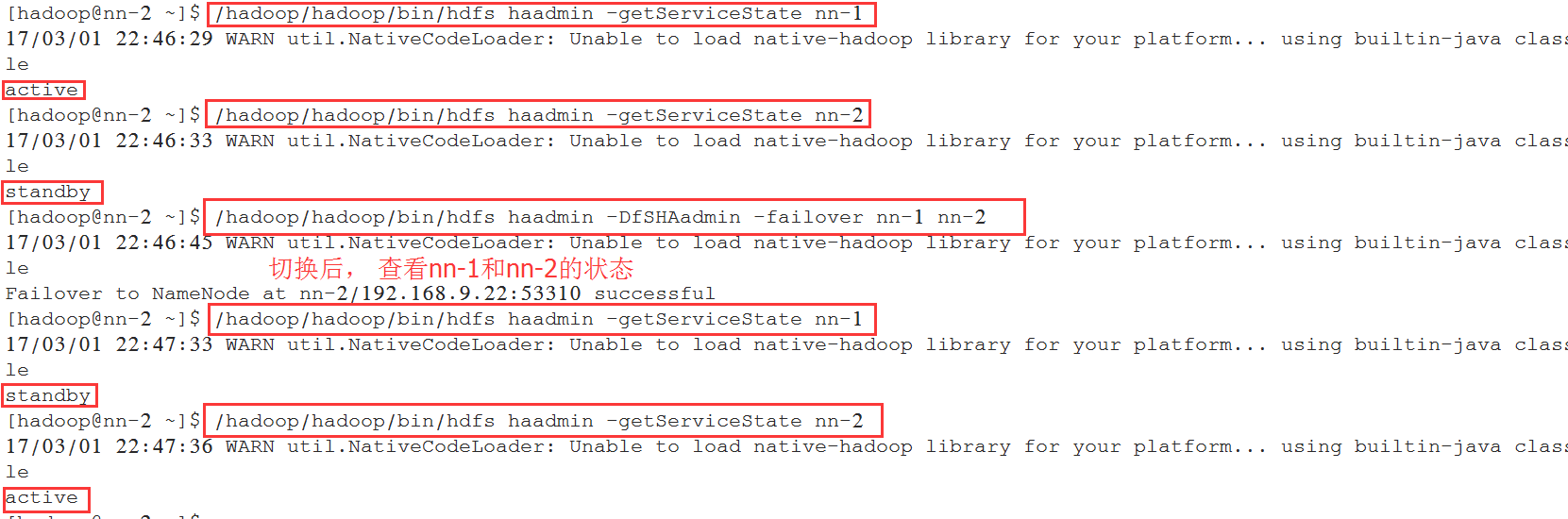
查看NameNode状态的命令
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -getServiceState nn-1
手工切换,将active的NameNode从nn-1切换到nn-2 。
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -DfSHAadmin -failover nn-1 nn-2
 NameNode健康检查:
NameNode健康检查:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-1
 将其中一台NameNode给kill后, 查看健康状态:
将其中一台NameNode给kill后, 查看健康状态:
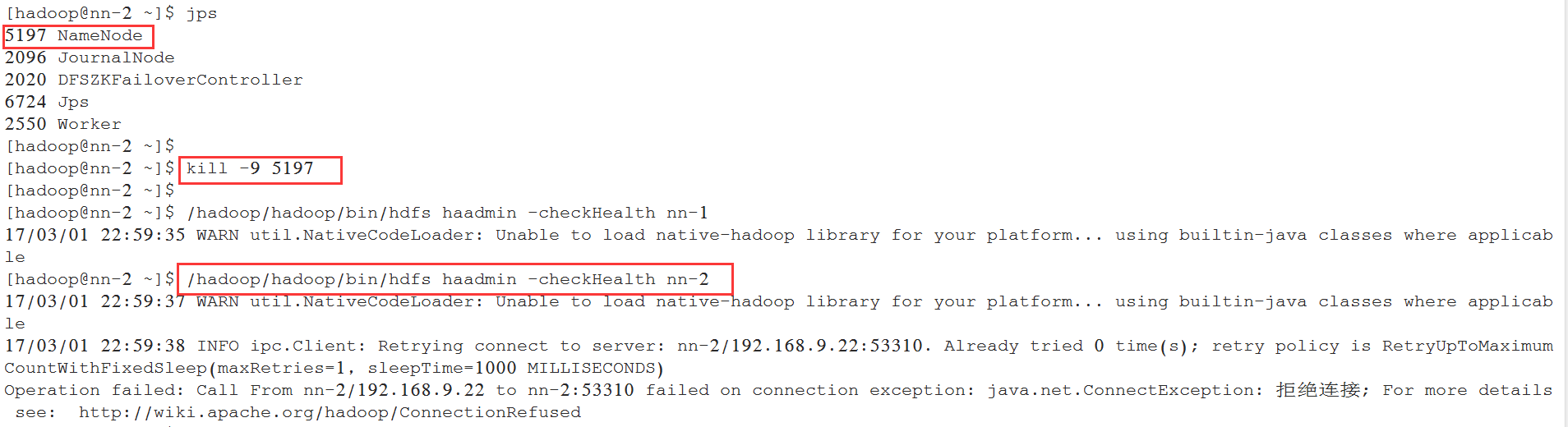
查看所有的DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report | more
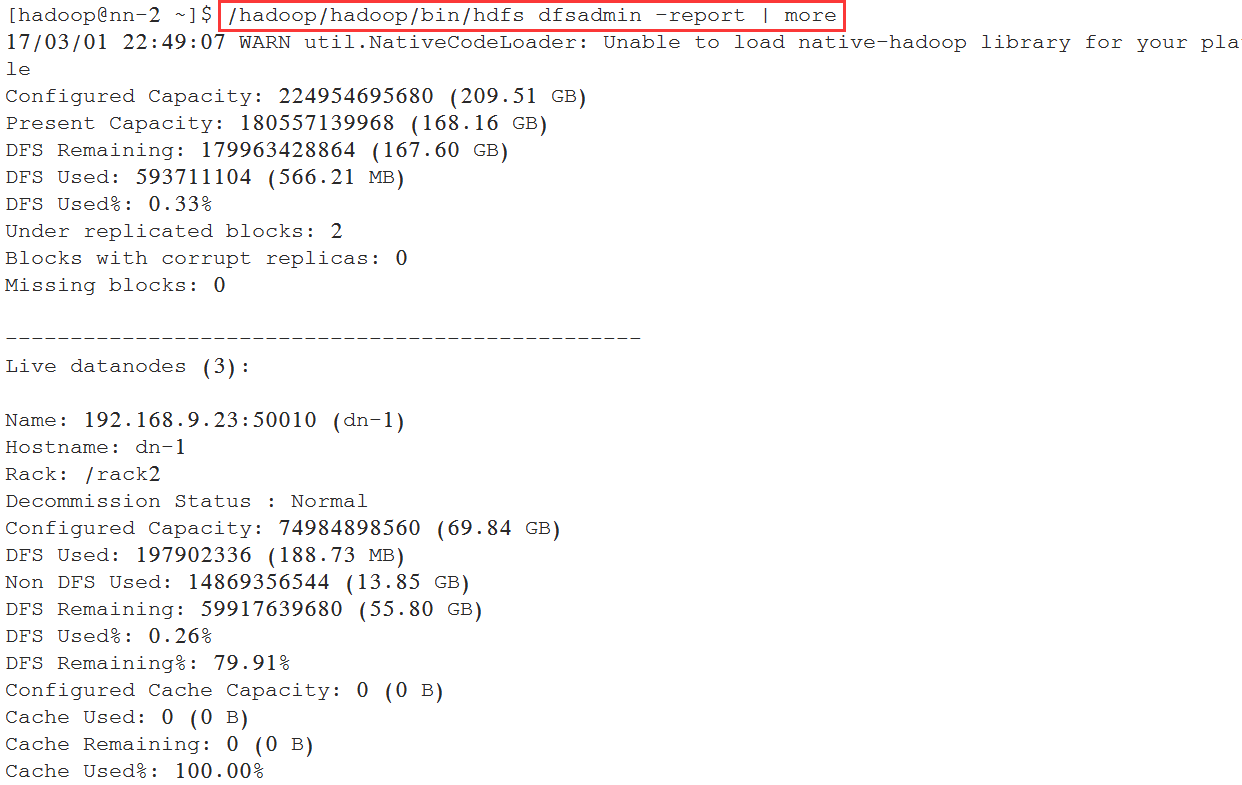 查看正常DataNode列表:
查看正常DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -live17/03/01 22:49:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableConfigured Capacity: 224954695680 (209.51 GB)Present Capacity: 180557139968 (168.16 GB)DFS Remaining: 179963428864 (167.60 GB)DFS Used: 593711104 (566.21 MB)DFS Used%: 0.33%Under replicated blocks: 2Blocks with corrupt replicas: 0Missing blocks: 0-------------------------------------------------Live datanodes (3):Name: 192.168.9.23:50010 (dn-1)Hostname: dn-1Rack: /rack2Decommission Status : NormalConfigured Capacity: 74984898560 (69.84 GB)DFS Used: 197902336 (188.73 MB)Non DFS Used: 14869356544 (13.85 GB)DFS Remaining: 59917639680 (55.80 GB)DFS Used%: 0.26%DFS Remaining%: 79.91%Configured Cache Capacity: 0 (0 B)Cache Used: 0 (0 B)Cache Remaining: 0 (0 B)Cache Used%: 100.00%Cache Remaining%: 0.00%Xceivers: 1Last contact: Wed Mar 01 22:49:42 CST 2017
查看异常DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -dead
获取指定DataNode信息(运行时间及版本等):
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-217/03/01 22:55:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-117/03/01 22:55:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
6.2 YARN相关的命令
查看resourceManager状态的命令:
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm1- active
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm2- standby
查看所有的yarn节点:
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -all -list17/03/01 23:06:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers dn-2:55506 RUNNING dn-2:8042 0 dn-1:56447 RUNNING dn-1:8042 0 dn-3:37533 RUNNING dn-3:8042 0
查看正常的yarn节点:
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -list17/03/01 23:07:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers dn-2:55506 RUNNING dn-2:8042 0 dn-1:56447 RUNNING dn-1:8042 0 dn-3:37533 RUNNING dn-3:8042 0
查看指定节点的信息:
/hadoop/hadoop/bin/yarn node -status <NodeId>
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -status dn-2:5550617/03/01 23:08:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableNode Report : Node-Id : dn-2:55506 Rack : /default-rack Node-State : RUNNING Node-Http-Address : dn-2:8042 Last-Health-Update : 星期三 01/三月/17 11:06:21:373CST Health-Report : Containers : 0 Memory-Used : 0MB Memory-Capacity : 8192MB CPU-Used : 0 vcores CPU-Capacity : 8 vcores Node-Labels :
查看当前运行的MapReduce任务:
[hadoop@dn-2 ~]$ /hadoop/hadoop/bin/yarn application -list17/03/01 23:10:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1 Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URLapplication_1488375590901_0004 QuasiMonteCarlo MAPREDUCE hadoop default RUNNING UNDEFINED
6.3 使用自带的例子测试
[hadoop@dn-1 ~]$ cd hadoop/[hadoop@dn-1 hadoop]$ [hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
[hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 01:51:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 01:51:15 INFO input.FileInputFormat: Total input paths to process : 217/02/28 01:51:15 INFO mapreduce.JobSubmitter: number of splits:217/02/28 01:51:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000117/02/28 01:51:16 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000117/02/28 01:51:16 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0001/17/02/28 01:51:16 INFO mapreduce.Job: Running job: job_1488216892564_000117/02/28 01:51:24 INFO mapreduce.Job: Job job_1488216892564_0001 running in uber mode : false17/02/28 01:51:24 INFO mapreduce.Job: map 0% reduce 0%17/02/28 01:51:38 INFO mapreduce.Job: map 100% reduce 0%17/02/28 01:51:49 INFO mapreduce.Job: map 100% reduce 100%17/02/28 01:51:49 INFO mapreduce.Job: Job job_1488216892564_0001 completed successfully17/02/28 01:51:50 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=326922 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=510 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=25604 Total time spent by all reduces in occupied slots (ms)=7267 Total time spent by all map tasks (ms)=25604 Total time spent by all reduce tasks (ms)=7267 Total vcore-seconds taken by all map tasks=25604 Total vcore-seconds taken by all reduce tasks=7267 Total megabyte-seconds taken by all map tasks=26218496 Total megabyte-seconds taken by all reduce tasks=7441408 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=274 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=419 CPU time spent (ms)=6940 Physical memory (bytes) snapshot=525877248 Virtual memory (bytes) snapshot=2535231488 Total committed heap usage (bytes)=260186112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97Job Finished in 35.466 secondsEstimated value of Pi is 3.17000000000000000000
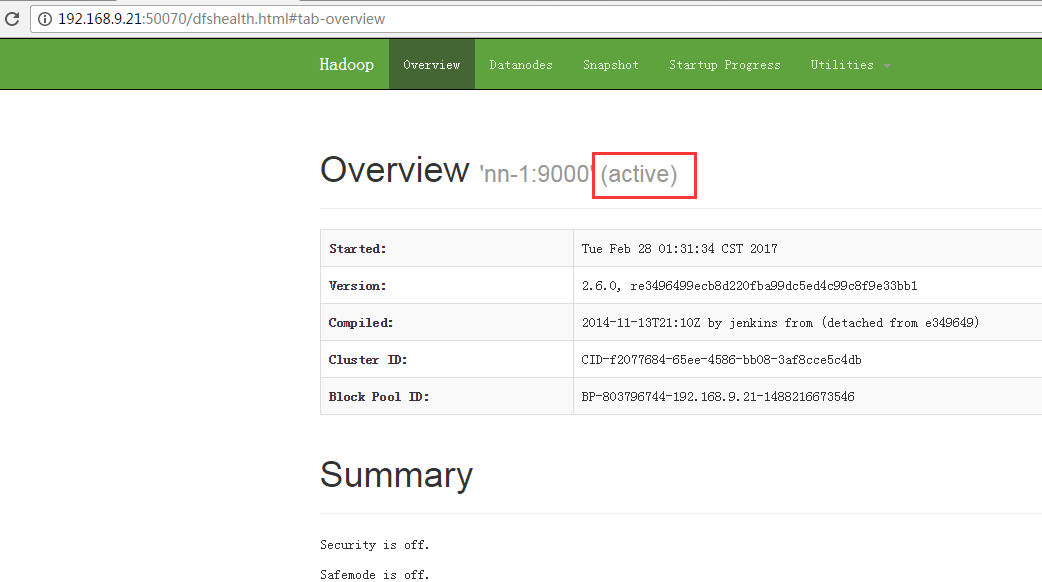
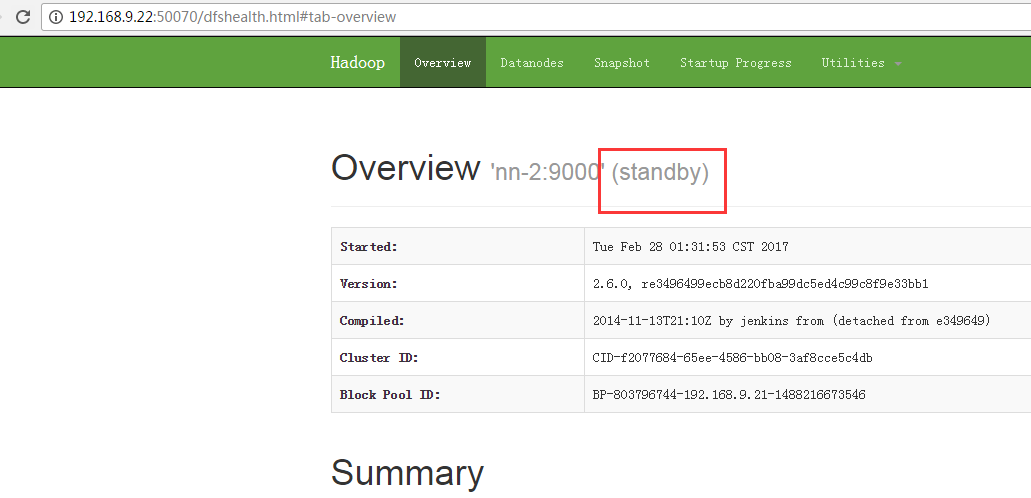
6.4 查看NameNode
链接分别为:
192.168.9.21和192.168.9.22分别为NameNode和Secondary NameNode的地址。
6.5 查看NameNode 的HA切换是否正常
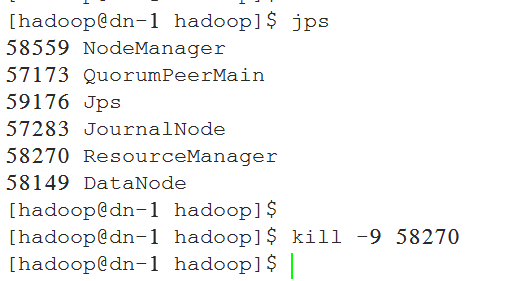
将nn-1上状态为active的NameNode进程kill, 查看nn-2上的NameNode能否从standby切换为active:
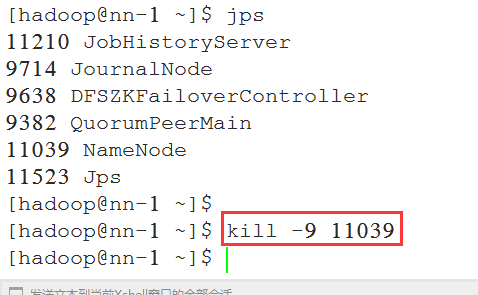
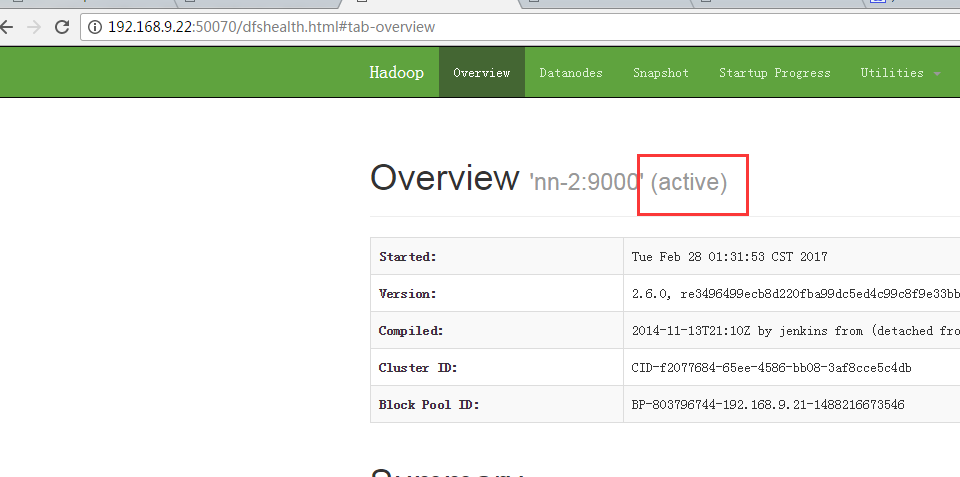
6.6 查看RM页面
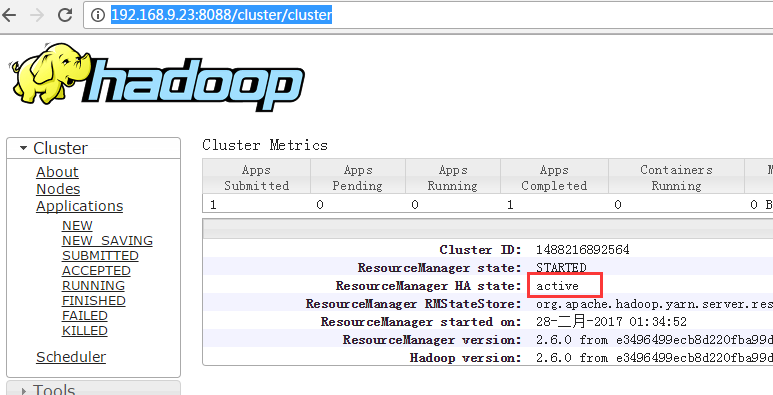
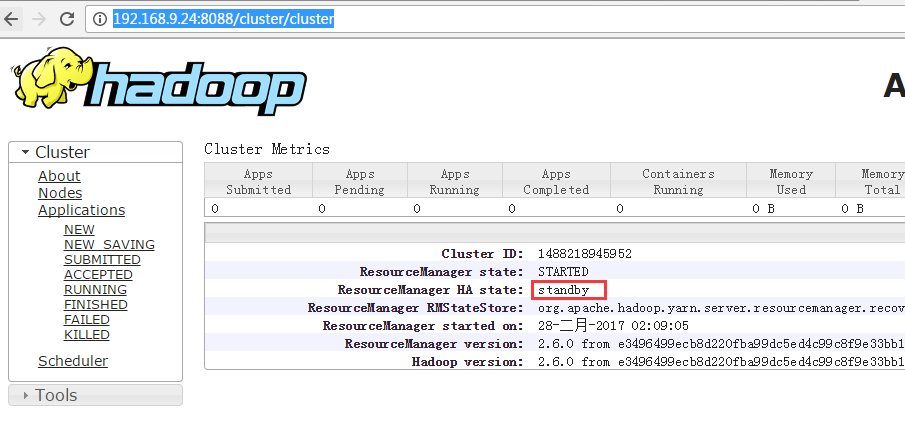
查看节点信息, 192.168.9.23为Resource服务所在的active节点。
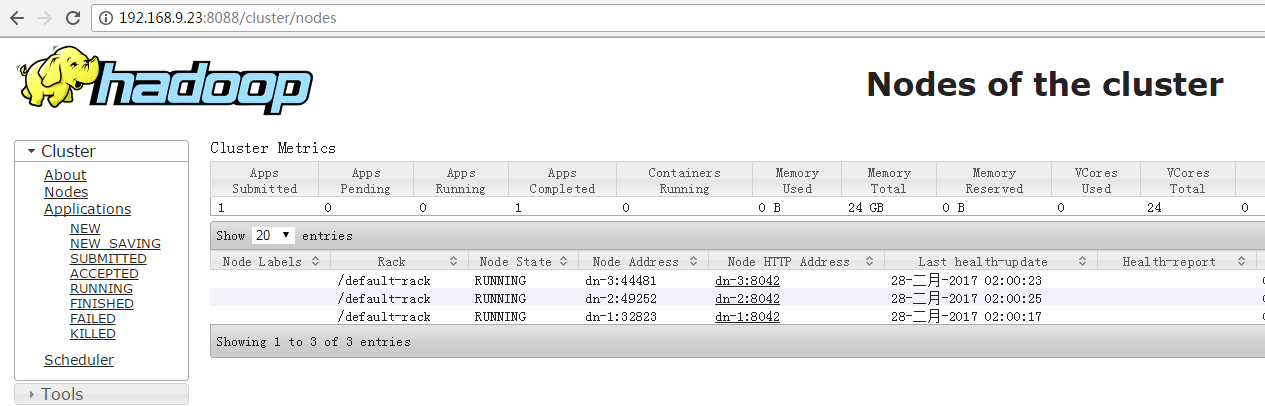
运行测试任务, 查看YARN HA能否自动切换:
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
运行到中间的时候, 将rm1上的rm给kill掉, 查看切换是否正常:
 查看standby的HA state变成了active:
查看standby的HA state变成了active:

查看下面的日志, 程序运行期间由于rm1被kill, 程序报错, 然后Trying to fail over immediately, 最终程序运行成功。
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 02:11:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 02:11:12 INFO input.FileInputFormat: Total input paths to process : 217/02/28 02:11:12 INFO mapreduce.JobSubmitter: number of splits:217/02/28 02:11:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000217/02/28 02:11:13 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000217/02/28 02:11:13 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0002/17/02/28 02:11:13 INFO mapreduce.Job: Running job: job_1488216892564_000217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1. Trying to fail over immediately.java.io.EOFException: End of File Exception between local host is: "dn-2/192.168.9.24"; destination host is: "dn-1":8032; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1071) at org.apache.hadoop.ipc.Client$Connection.run(Client.java:966)17/02/28 02:11:18 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm2 after 1 fail over attempts. Trying to fail over after sleeping for 40859ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-2:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 43 more17/02/28 02:11:59 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm117/02/28 02:11:59 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1 after 2 fail over attempts. Trying to fail over after sleeping for 17213ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-1:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 42 more17/02/28 02:12:16 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:12:18 INFO mapreduce.Job: Job job_1488216892564_0002 running in uber mode : false17/02/28 02:12:18 INFO mapreduce.Job: map 0% reduce 0%17/02/28 02:12:22 INFO mapreduce.Job: map 100% reduce 0%17/02/28 02:12:28 INFO mapreduce.Job: map 100% reduce 100%17/02/28 02:12:28 INFO mapreduce.Job: Job job_1488216892564_0002 completed successfully17/02/28 02:12:28 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=326931 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=510 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=22713 Total time spent by all reduces in occupied slots (ms)=3213 Total time spent by all map tasks (ms)=22713 Total time spent by all reduce tasks (ms)=3213 Total vcore-seconds taken by all map tasks=22713 Total vcore-seconds taken by all reduce tasks=3213 Total megabyte-seconds taken by all map tasks=23258112 Total megabyte-seconds taken by all reduce tasks=3290112 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=274 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=233 CPU time spent (ms)=12680 Physical memory (bytes) snapshot=517484544 Virtual memory (bytes) snapshot=2548441088 Total committed heap usage (bytes)=260186112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97Job Finished in 76.447 secondsEstimated value of Pi is 3.17000000000000000000[hadoop@dn-2 hadoop]$
7、安装Spark
规划, 在现有的Hadoop集群安装spark集群:
master节点: nn-1
worker节点: nn-2、dn-1、dn-2、dn-3。
7.1 安装配置Scala
上传安装包到nn-1的/hadoop目录下面,解压:
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
环境变量后面统一配置。
7.2 安装spark
上传安装包spark-1.6.0-bin-hadoop2.6.tgz到nn-1的目录/hadoop下面, 解压
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
进入目录:/hadoop/spark-1.6.0-bin-hadoop2.6/conf
复制生成文件spark-env.sh和slaves:
[hadoop@nn-1 conf]$ pwd/hadoop/spark-1.6.0-bin-hadoop2.6/conf[hadoop@nn-1 conf]$ cp spark-env.sh.template spark-env.sh[hadoop@nn-1 conf]$ cp slaves.template slaves
编辑spark-env.sh, 加入如下内容:
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export SPARK_MASTER_IP=nn-1export SPARK_WORKER_MEMORY=2gexport HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop
SPARK_WORKER_MEMORY根据实际情况配置。
编辑spark-env.sh, 加入如下内容:slaves
nn-2dn-1dn-2dn-3
slaves指定的是worker节点。
7.3 配置环境变量
[hadoop@nn-1 ~]$ vim .bash_profile
追加如下内容:
export HADOOP_HOME=/hadoop/hadoopexport SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
7.4 分发上面配置好的scala和spark目录到其他节点
[hadoop@nn-1 bin]$ cd /hadoop[hadoop@nn-1 ~]$ scp -rp spark-1.6.0-bin-hadoop2.6 hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp scala-2.11.7 hadoop@dn-1:/hadoop
7.5 启动Spark集群
[hadoop@nn-1 ~]$ /hadoop/spark-1.6.0-bin-hadoop2.6/sbin/start-all.sh
在nn-1和其他slaves节点查看进程:
在nn-1节点, 可以看到Master进程:
[hadoop@nn-1 ~]$ jps2473 JournalNode2541 NameNode4401 Jps2399 DFSZKFailoverController2687 JobHistoryServer2775 Master2351 QuorumPeerMain
在slaves节点可以看到Worker进程:
[hadoop@dn-1 ~]$ jps2522 NodeManager3449 Jps2007 QuorumPeerMain2141 DataNode2688 Worker2061 JournalNode2258 ResourceManager
查看spark页面:
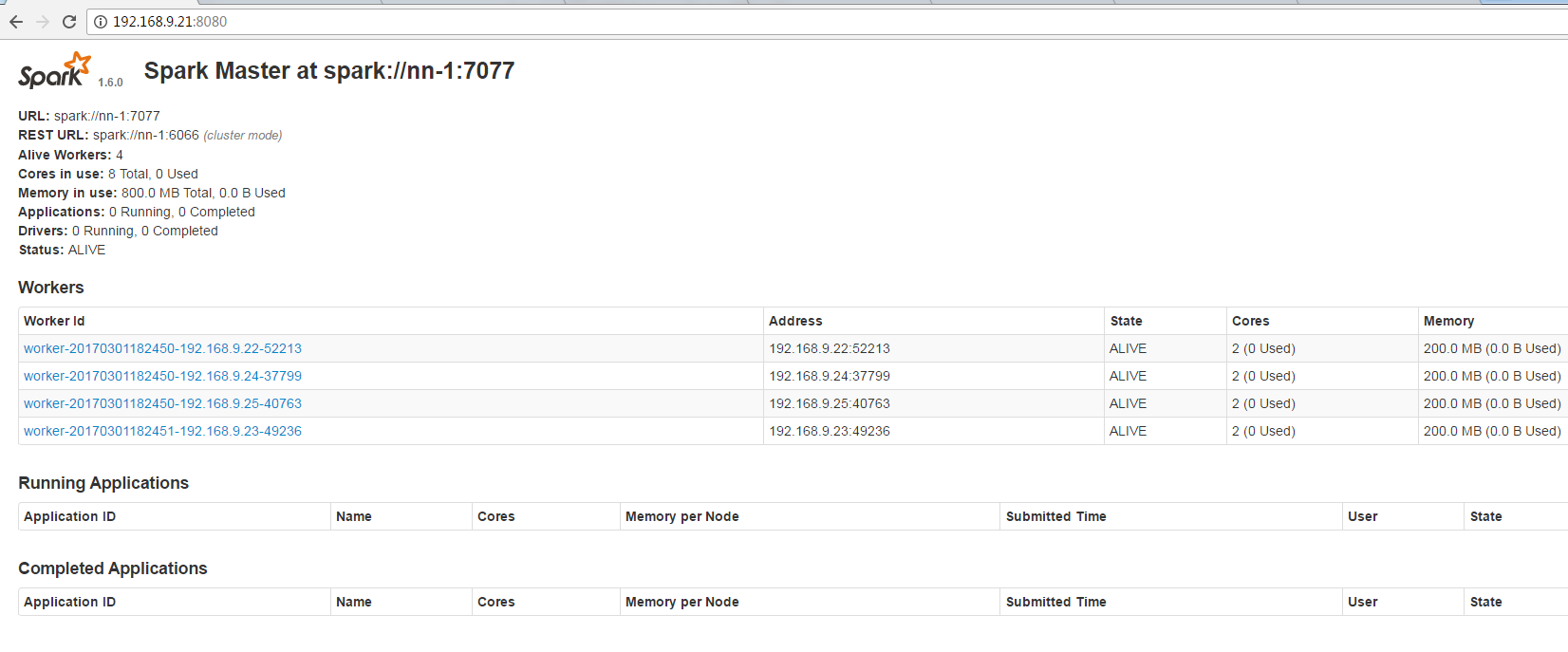
7.6 运行测试案例
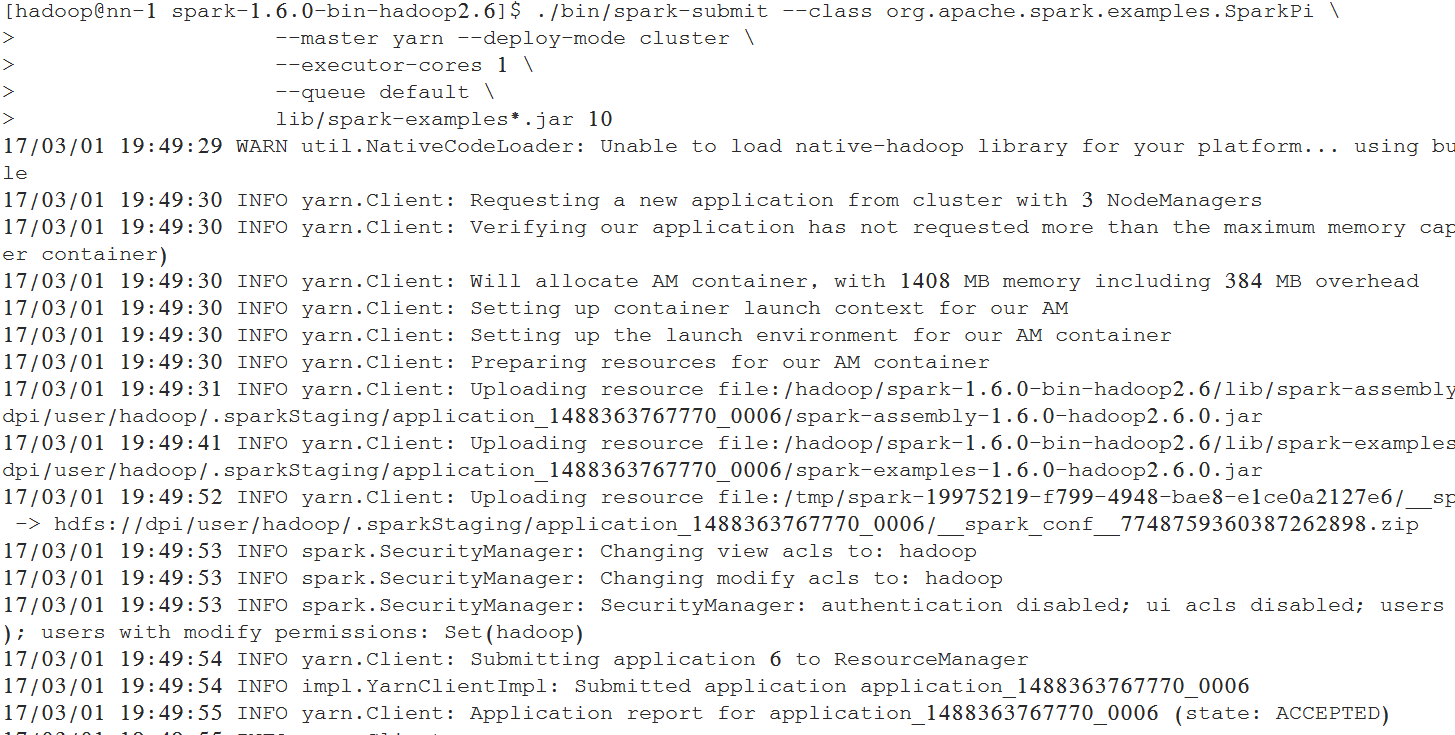
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--driver-memory 100M \
--executor-memory 200M \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
或者:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
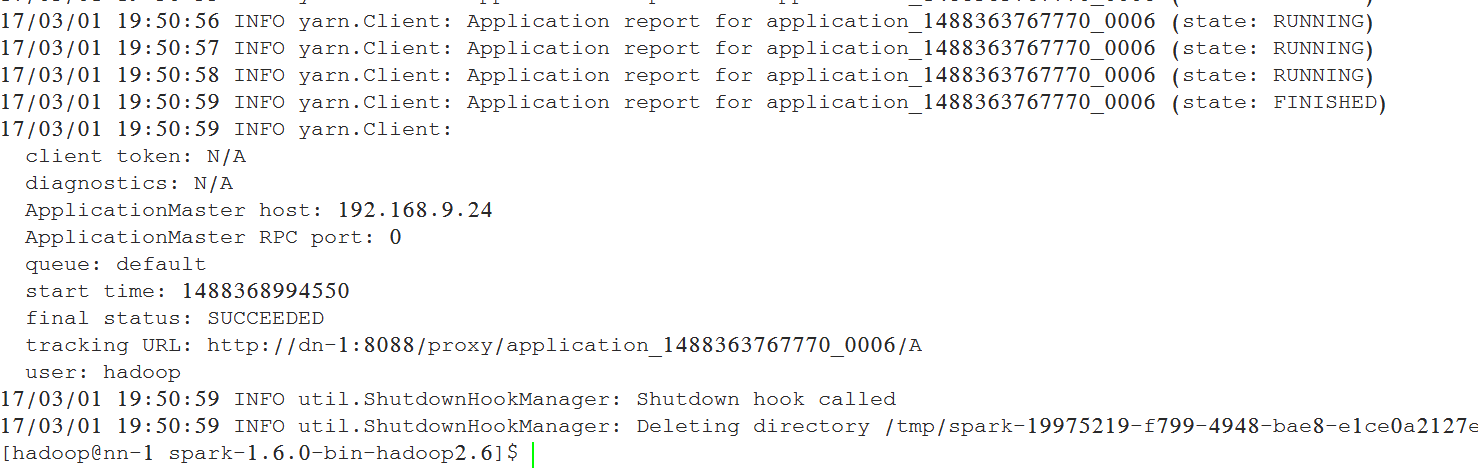
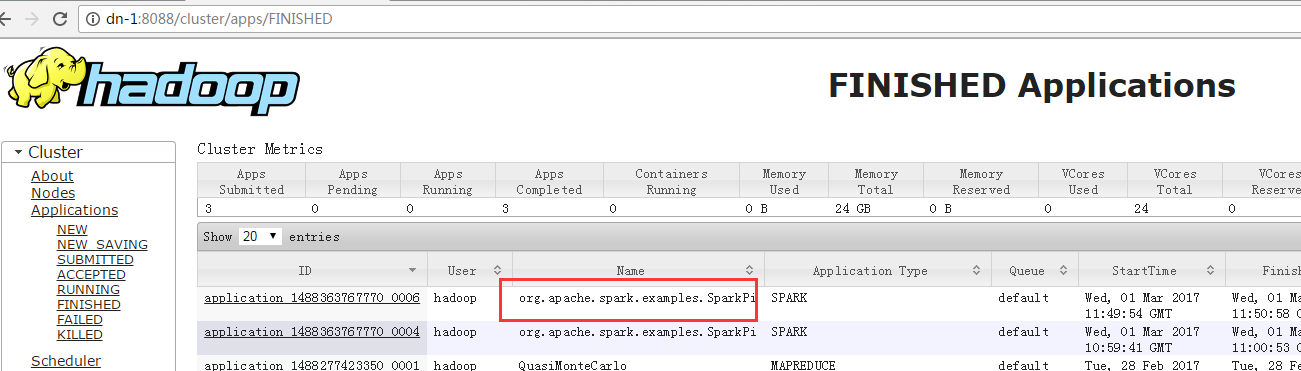
8、配置机架感知
在nn-1和nn-2节点的配置文件/hadoop/hadoop/etc/hadoop/core-site.xml加入如下配置:
<property> <name>topology.script.file.name</name> <value>/hadoop/hadoop/etc/hadoop/RackAware.py</value> </property>
新增文件:/hadoop/hadoop/etc/hadoop/RackAware.py,内容如下:
#!/usr/bin/python#-*-coding:UTF-8 -*-import sysrack = {"dn-1":"rack2", "dn-2":"rack1", "dn-3":"rack1", "192.168.9.23":"rack2", "192.168.9.24":"rack1", "192.168.9.25":"rack1",}if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
设置权限:
[root@nn-1 hadoop]# chmod +x RackAware.py [root@nn-1 hadoop]# ll RackAware.py-rwxr-xr-x 1 hadoop hadoop 294 3月 1 21:24 RackAware.py
重启nn-1和nn-2上的NameNode服务:
[hadoop@nn-1 ~]$ hadoop-daemon.sh stop namenodestopping namenode[hadoop@nn-1 ~]$ hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
查看日志:
[root@nn-1 logs]# pwd/hadoop/hadoop/logs[root@nn-1 logs]# vim hadoop-hadoop-namenode-nn-1.log
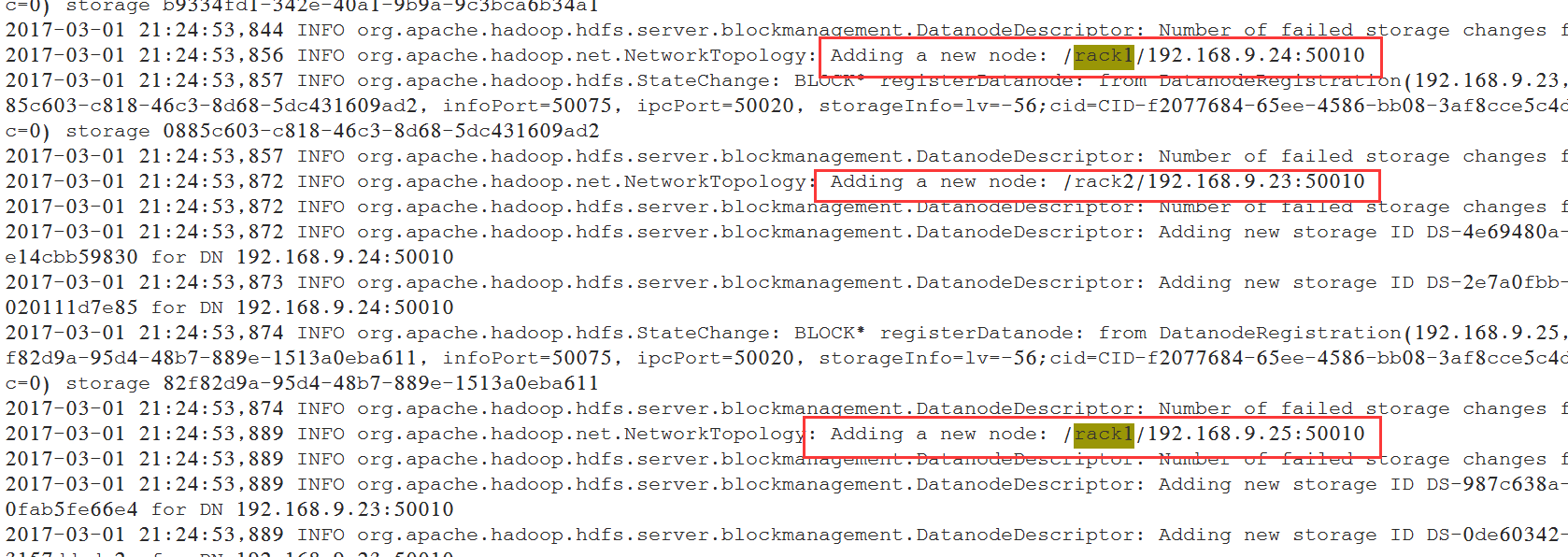
使用命令查看拓扑:
[hadoop@dn-3 ~]$ hdfs dfsadmin -printTopology17/03/02 00:21:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableRack: /rack1 192.168.9.24:50010 (dn-2) 192.168.9.25:50010 (dn-3)Rack: /rack2 192.168.9.23:50010 (dn-1)
| 序号 | 主机名 | IP地址 | 角色 |
| 1 | nn-1 | 192.168.9.21 | NameNode、mr-jobhistory、zookeeper、JournalNode |
| 2 | nn-2 | 192.168.9.22 | Secondary NameNode、JournalNode |
| 3 | dn-1 | 192.168.9.23 | DataNode、JournalNode、zookeeper、ResourceManager、NodeManager |
| 4 | dn-2 | 192.168.9.24 | DataNode、zookeeper、ResourceManager、NodeManager |
| 5 | dn-3 | 192.168.9.25 | DataNode、NodeManager |
2.1 配置JDK
--查看java版本[root@dtgr ~]# java -versionjava version "1.7.0_45"OpenJDK Runtime Environment (rhel-2.4.3.3.el6-x86_64 u45-b15)OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)--查看安装源[root@dtgr ~]# rpm -qa | grep javajava-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64-- 卸载[root@dtgr ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64- --验证是否卸载成功
[root@dtgr ~]# rpm -qa | grep java[root@dtgr ~]# java -version-bash: /usr/bin/java: 没有那个文件或目录
-- 下载并解压java源码包[root@dtgr java]# mkdir /usr/local/java[root@dtgr java]# mv jdk-7u79-linux-x64.tar.gz /usr/local/java[root@dtgr java]# cd /usr/local/java[root@dtgr java]# tar xvf jdk-7u79-linux-x64.tar.gz[root@dtgr java]# lsjdk1.7.0_79 jdk-7u79-linux-x64.tar.gz[root@dtgr java]#--- 添加环境变量[root@dtgr java]# vim /etc/profile[root@dtgr java]# tail /etc/profileexport JAVA_HOME=/usr/local/java/jdk1.7.0_79export JRE_HOME=/usr/local/java/jdk1.7.0_79/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATHexport PATH=$JAVA_HOME/bin:$PATH-- 生效环境变量[root@dtgr ~]# source /etc/profile-- 验证[root@dtgr ~]# java -versionjava version "1.7.0_79"Java(TM) SE Runtime Environment (build 1.7.0_79-b15)Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)[root@dtgr ~]# javac -versionjavac 1.7.0_79
2.2 修改主机名和配置主机名解析
[root@dn-3 ~]# cat /etc/sysconfig/networkNETWORKING=yesHOSTNAME=dn-3[root@dn-3 ~]# hostname dn-3
[root@dn-3 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.9.21 nn-1192.168.9.22 nn-2192.168.9.23 dn-1192.168.9.24 dn-2192.168.9.25 dn-3
2.3 新建hadoop账户
[root@dn-3 ~]# useradd -d /hadoop hadoop
2.4 配置ntp时钟同步
2.5 关闭防火墙iptables和selinux
[root@dn-3 ~]# service iptables stop[root@dn-3 ~]# chkconfig iptables off[root@dn-3 ~]# chkconfig --list | grep iptablesiptables 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭[root@dn-3 ~]#
[root@dn-3 ~]# setenforce 0setenforce: SELinux is disabled[root@dn-3 ~]# vim /etc/sysconfig/selinuxSELINUX=disabled
2.6 设置ssh无密码登陆
[hadoop@nn-1 ~]$ ssh-keygen -t rsa
[hadoop@nn-1 ~]$ ssh nn-1 'cat ./.ssh/id_rsa.pub' >> authorized_keyshadoop@nn-1's password:
[hadoop@nn-1 .ssh]$ chmod 644 authorized_keys
[hadoop@nn-1 .ssh]$ scp authorized_keys hadoop@nn-2:/hadoop/.ssh/
3、安装配置Hadoop
说明: 先在nn-1上面修改配置, 配置完毕批量分发到其他节点。
3.1 上传hadoop、zookeeper安装包
复制安装包到/hadoop目录下。
解压安装包: [hadoop@nn-1 ~]$ tar -xzvf hadoop2-js-0121.tar.gz
3.2 修改hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export HADOOP_HEAPSIZE=2000export HADOOP_NAMENODE_INIT_HEAPSIZE=10000export HADOOP_OPTS="-server $HADOOP_OPTS -Djava.net.preferIPv4Stack=true"export HADOOP_NAMENODE_OPTS="-Xmx15000m -Xms15000m -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
3.3 修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://dpi</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/hadoop/hdfs/temp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.hduser.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hduser.groups</name> <value>*</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>dn-1:2181,dn-2:2181,dn-3:2181</value> </property></configuration>
3.4 修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>nn-1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/hdfs/data,file:/hadoopdata/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.nameservices</name> <value>dpi</value> </property> <property> <name>dfs.ha.namenodes.dpi</name> <value>nn-1,nn-2</value> </property> <property> <name>dfs.namenode.rpc-address.dpi.nn-1</name> <value>nn-1:9000</value> </property> <property> <name>dfs.namenode.http-address.dpi.nn-1</name> <value>nn-1:50070</value> </property> <property> <name>dfs.namenode.rpc-address.dpi.nn-2</name> <value>nn-2:9000</value> </property> <property> <name>dfs.namenode.http-address.dpi.nn-2</name> <value>nn-2:50070</value> </property> <property> <name>dfs.namenode.servicerpc-address.dpi.nn-1</name> <value>nn-1:53310</value> </property> <property> <name>dfs.namenode.servicerpc-address.dpi.nn-2</name> <value>nn-2:53310</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://nn-1:8485;nn-2:8485;dn-1:8485/dpi</value> </property> <property> <name>dfs.client.failover.proxy.provider.dpi</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/hadoop/hdfs/journal</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/hadoop/.ssh/id_rsa</value> </property></configuration>
新建配置文件中的目录:
mkdir -p /hadoop/hdfs/namemkdir -p /hadoop/hdfs/datamkdir -p /hadoop/hdfs/tempmkdir -p /hadoop/hdfs/journal授权:chmod 755 /hadoop/hdfsmkdir -p /hadoopdata/hdfs/datachmod 755 /hadoopdata/hdfs
属主和属组修改为:hadoop:hadoop
3.5 修改mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>nn-1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>nn-1:19888</value> </property></configuration>
3.6 修改yarn-site.xml
启用yarn ha功能, 根据规划, dn-1和dn-2为ResourceManager节点
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>dn-1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>dn-2</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>dn-1:2181,dn-2:2181,dn-3:2181</value> <description>For multiple zk services, separate them with comma</description> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property></configuration>
3.7 修改slaves
将所有的DataNode节点加入到slaves文件中:
dn-1dn-2dn-3
3.8 修改yarn-env.sh
# some Java parameters# export JAVA_HOME=/home/y/libexec/jdk1.6.0/if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=/usr/local/java/jdk1.7.0_79fiJAVA_HEAP_MAX=-Xmx15000mYARN_HEAPSIZE=15000export YARN_RESOURCEMANAGER_HEAPSIZE=5000export YARN_TIMELINESERVER_HEAPSIZE=10000export YARN_NODEMANAGER_HEAPSIZE=10000
3.9 分发配置好的hadoop目录到所有节点
[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@nn-2:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-2:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-3:/hadoop
4 安装配置zookeeper
切换到hadoop目录下面, 根据规划, 三台zookeeper节点为:nn-1, dn-1, dn-2。
先在nn-1节点配置zookeeper, 然后分发至三个zookeeper节点:
4.1 在nn-1上传并解压zookeeper
4.2 修改配置文件/hadoop/zookeeper/conf/zoo.cfg
dataDir=/hadoop/zookeeper/data/dataLogDir=/hadoop/zookeeper/log/# the port at which the clients will connectclientPort=2181server.1=nn-1:2887:3887server.2=dn-1:2888:3888server.3=dn-2:2889:3889
4.3 从nn-1分发配置的zookeeper目录到其他节点
[hadoop@nn-1 ~]$ scp -rp zookeeper hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp zookeeper hadoop@dn-2:/hadoop
4.4 在所有zk节点创建目录
[hadoop@dn-1 ~]$ mkdir /hadoop/zookeeper/data/[hadoop@dn-1 ~]$ mkdir /hadoop/zookeeper/log/
4.5 修改myid
在所有zk节点, 切换到目录/hadoop/zookeeper/data,创建myid文件:
注意:myid文件的内容为zoo.cfg文件中配置的server.后面的数字(即nn-1为1,dn-1为2,dn-2为3)。
在nn-1节点的myid内容为:
[hadoop@nn-1 data]$ echo 1 > /hadoop/zookeeper/data/myid
其他zk节点也安要求创建myid文件。
4.6 设置环境变量
$ echo "export ZOOKEEPER_HOME=/hadoop/zookeeper" >> $HOME/.bash_profile$ echo "export PATH=$ZOOKEEPER_HOME/bin:\$PATH" >> $HOME/.bash_profile$ source $HOME/.bash_profile
5 集群启动
5.1 启动zookeeper
根据规划, zk的节点为nn-1、dn-1和dn-2, 在这三台节点分别启动zk:
启动命令:
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh startJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgStarting zookeeper ... STARTED
查看进程, 可以看到QuorumPeerMain:
[hadoop@nn-1 ~]$ jps9382 QuorumPeerMain9407 Jps
查看状态, 可以看到Mode: follower, 说明这是zk的从节点:
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: follower
查看状态, 可以看到Mode: leader, 说明这是zk的leader节点:
[hadoop@dn-1 data]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: leader
5.2 格式化zookeeper集群(只做一次)(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hdfs zkfc -formatZK
中间有个交互的步骤, 输入Y:
进入zk, 查看是否创建成功:
[hadoop@nn-1 bin]$ ./zkCli.sh
5.3 启动zkfc(机器nn-1,nn-2上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start zkfcstarting zkfc, logging to /hadoop/hadoop/logs/hadoop-hadoop-zkfc-nn-1.out
使用jps, 可以看到进程DFSZKFailoverController:
[hadoop@nn-1 ~]$ jps9681 Jps9638 DFSZKFailoverController9382 QuorumPeerMain
5.4 启动journalnode
根据规划, 启动journalnode节点为nn-1、nn-2和dn-1, 在这三个节点分别使用如下的命令启动服务:
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /hadoop/hadoop/logs/hadoop-hadoop-journalnode-nn-1.out
使用jps命令可以看到进程JournalNode:
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain9762 Jps
5.5 格式化namenode(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hadoop namenode -format
查看日志信息:
5.6 启动namenode(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
使用jps命令可以看到进程NameNode:
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain10157 NameNode10269 Jps
5.7 格式化secondnamnode(机器nn-2上执行)
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs namenode -bootstrapStandby
部分日志如下:
5.8 启动namenode(机器nn-2上执行)
[hadoop@nn-2 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-2.out
使用jps命令可以看到进程NameNode:
[hadoop@nn-2 ~]$ jps53990 NameNode54083 Jps53824 JournalNode53708 DFSZKFailoverController
5.9 启动datanode(机器dn-1到dn-3上执行)
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start datanode
使用jps可以看到DataNode进程:
[hadoop@dn-1 temp]$ jps57007 Jps56927 DataNode56223 QuorumPeerMain
5.10 启动resourcemanager
根据规划,resourcemanager做了HA, 服务在节点dn-1和dn-2上面, 在dn-1和dn-2上面启动resourcemanager:
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-resourcemanager-dn-1.out
使用jps, 可以看到进程ResourceManager:
[hadoop@dn-1 ~]$ jps57173 QuorumPeerMain58317 Jps57283 JournalNode58270 ResourceManager58149 DataNode
5.11 启动jobhistory
根据规划, jobhistory服务在nn-1上面, 使用如下命令启动:
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /hadoop/hadoop/logs/mapred-hadoop-historyserver-nn-1.out
使用jps, 可以看到进程JobHistoryServer:
[hadoop@nn-1 ~]$ jps11210 JobHistoryServer9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain11039 NameNode11303 Jps
5.12 启动NodeManager
根据规划, dn-1、dn-2和dn-3是nodemanager, 在这三个节点启动NodeManager:
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start nodemanagerstarting nodemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-nodemanager-dn-1.out
使用jps可以看到进程NodeManager:
[hadoop@dn-1 ~]$ jps58559 NodeManager57173 QuorumPeerMain58668 Jps57283 JournalNode58270 ResourceManager58149 DataNode
6、安装后查看和验证
6.1 HDFS相关操作命令
查看NameNode状态的命令
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -getServiceState nn-1
手工切换,将active的NameNode从nn-1切换到nn-2 。
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -DfSHAadmin -failover nn-1 nn-2
NameNode健康检查:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-1
将其中一台NameNode给kill后, 查看健康状态:
查看所有的DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report | more
查看正常DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -live17/03/01 22:49:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableConfigured Capacity: 224954695680 (209.51 GB)Present Capacity: 180557139968 (168.16 GB)DFS Remaining: 179963428864 (167.60 GB)DFS Used: 593711104 (566.21 MB)DFS Used%: 0.33%Under replicated blocks: 2Blocks with corrupt replicas: 0Missing blocks: 0-------------------------------------------------Live datanodes (3):Name: 192.168.9.23:50010 (dn-1)Hostname: dn-1Rack: /rack2Decommission Status : NormalConfigured Capacity: 74984898560 (69.84 GB)DFS Used: 197902336 (188.73 MB)Non DFS Used: 14869356544 (13.85 GB)DFS Remaining: 59917639680 (55.80 GB)DFS Used%: 0.26%DFS Remaining%: 79.91%Configured Cache Capacity: 0 (0 B)Cache Used: 0 (0 B)Cache Remaining: 0 (0 B)Cache Used%: 100.00%Cache Remaining%: 0.00%Xceivers: 1Last contact: Wed Mar 01 22:49:42 CST 2017
查看异常DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -dead
获取指定DataNode信息(运行时间及版本等):
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-217/03/01 22:55:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-117/03/01 22:55:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
6.2 YARN相关的命令
查看resourceManager状态的命令:
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm1- active
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm2- standby
查看所有的yarn节点:
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -all -list17/03/01 23:06:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers dn-2:55506 RUNNING dn-2:8042 0 dn-1:56447 RUNNING dn-1:8042 0 dn-3:37533 RUNNING dn-3:8042 0
查看正常的yarn节点:
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -list17/03/01 23:07:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers dn-2:55506 RUNNING dn-2:8042 0 dn-1:56447 RUNNING dn-1:8042 0 dn-3:37533 RUNNING dn-3:8042 0
查看指定节点的信息:
/hadoop/hadoop/bin/yarn node -status <NodeId>
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -status dn-2:5550617/03/01 23:08:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableNode Report : Node-Id : dn-2:55506 Rack : /default-rack Node-State : RUNNING Node-Http-Address : dn-2:8042 Last-Health-Update : 星期三 01/三月/17 11:06:21:373CST Health-Report : Containers : 0 Memory-Used : 0MB Memory-Capacity : 8192MB CPU-Used : 0 vcores CPU-Capacity : 8 vcores Node-Labels :
查看当前运行的MapReduce任务:
[hadoop@dn-2 ~]$ /hadoop/hadoop/bin/yarn application -list17/03/01 23:10:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1 Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URLapplication_1488375590901_0004 QuasiMonteCarlo MAPREDUCE hadoop default RUNNING UNDEFINED
6.3 使用自带的例子测试
[hadoop@dn-1 ~]$ cd hadoop/[hadoop@dn-1 hadoop]$ [hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
[hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 01:51:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 01:51:15 INFO input.FileInputFormat: Total input paths to process : 217/02/28 01:51:15 INFO mapreduce.JobSubmitter: number of splits:217/02/28 01:51:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000117/02/28 01:51:16 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000117/02/28 01:51:16 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0001/17/02/28 01:51:16 INFO mapreduce.Job: Running job: job_1488216892564_000117/02/28 01:51:24 INFO mapreduce.Job: Job job_1488216892564_0001 running in uber mode : false17/02/28 01:51:24 INFO mapreduce.Job: map 0% reduce 0%17/02/28 01:51:38 INFO mapreduce.Job: map 100% reduce 0%17/02/28 01:51:49 INFO mapreduce.Job: map 100% reduce 100%17/02/28 01:51:49 INFO mapreduce.Job: Job job_1488216892564_0001 completed successfully17/02/28 01:51:50 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=326922 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=510 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=25604 Total time spent by all reduces in occupied slots (ms)=7267 Total time spent by all map tasks (ms)=25604 Total time spent by all reduce tasks (ms)=7267 Total vcore-seconds taken by all map tasks=25604 Total vcore-seconds taken by all reduce tasks=7267 Total megabyte-seconds taken by all map tasks=26218496 Total megabyte-seconds taken by all reduce tasks=7441408 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=274 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=419 CPU time spent (ms)=6940 Physical memory (bytes) snapshot=525877248 Virtual memory (bytes) snapshot=2535231488 Total committed heap usage (bytes)=260186112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97Job Finished in 35.466 secondsEstimated value of Pi is 3.17000000000000000000
6.4 查看NameNode
链接分别为:
192.168.9.21和192.168.9.22分别为NameNode和Secondary NameNode的地址。
6.5 查看NameNode 的HA切换是否正常
将nn-1上状态为active的NameNode进程kill, 查看nn-2上的NameNode能否从standby切换为active:
6.6 查看RM页面
查看节点信息, 192.168.9.23为Resource服务所在的active节点。
运行测试任务, 查看YARN HA能否自动切换:
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
运行到中间的时候, 将rm1上的rm给kill掉, 查看切换是否正常:
查看standby的HA state变成了active:
查看下面的日志, 程序运行期间由于rm1被kill, 程序报错, 然后Trying to fail over immediately, 最终程序运行成功。
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 02:11:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 02:11:12 INFO input.FileInputFormat: Total input paths to process : 217/02/28 02:11:12 INFO mapreduce.JobSubmitter: number of splits:217/02/28 02:11:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000217/02/28 02:11:13 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000217/02/28 02:11:13 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0002/17/02/28 02:11:13 INFO mapreduce.Job: Running job: job_1488216892564_000217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1. Trying to fail over immediately.java.io.EOFException: End of File Exception between local host is: "dn-2/192.168.9.24"; destination host is: "dn-1":8032; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1071) at org.apache.hadoop.ipc.Client$Connection.run(Client.java:966)17/02/28 02:11:18 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm2 after 1 fail over attempts. Trying to fail over after sleeping for 40859ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-2:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 43 more17/02/28 02:11:59 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm117/02/28 02:11:59 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1 after 2 fail over attempts. Trying to fail over after sleeping for 17213ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-1:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 42 more17/02/28 02:12:16 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:12:18 INFO mapreduce.Job: Job job_1488216892564_0002 running in uber mode : false17/02/28 02:12:18 INFO mapreduce.Job: map 0% reduce 0%17/02/28 02:12:22 INFO mapreduce.Job: map 100% reduce 0%17/02/28 02:12:28 INFO mapreduce.Job: map 100% reduce 100%17/02/28 02:12:28 INFO mapreduce.Job: Job job_1488216892564_0002 completed successfully17/02/28 02:12:28 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=326931 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=510 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=22713 Total time spent by all reduces in occupied slots (ms)=3213 Total time spent by all map tasks (ms)=22713 Total time spent by all reduce tasks (ms)=3213 Total vcore-seconds taken by all map tasks=22713 Total vcore-seconds taken by all reduce tasks=3213 Total megabyte-seconds taken by all map tasks=23258112 Total megabyte-seconds taken by all reduce tasks=3290112 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=274 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=233 CPU time spent (ms)=12680 Physical memory (bytes) snapshot=517484544 Virtual memory (bytes) snapshot=2548441088 Total committed heap usage (bytes)=260186112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97Job Finished in 76.447 secondsEstimated value of Pi is 3.17000000000000000000[hadoop@dn-2 hadoop]$
7、安装Spark
规划, 在现有的Hadoop集群安装spark集群:
master节点: nn-1
worker节点: nn-2、dn-1、dn-2、dn-3。
7.1 安装配置Scala
上传安装包到nn-1的/hadoop目录下面,解压:
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
环境变量后面统一配置。
7.2 安装spark
上传安装包spark-1.6.0-bin-hadoop2.6.tgz到nn-1的目录/hadoop下面, 解压
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
进入目录:/hadoop/spark-1.6.0-bin-hadoop2.6/conf
复制生成文件spark-env.sh和slaves:
[hadoop@nn-1 conf]$ pwd/hadoop/spark-1.6.0-bin-hadoop2.6/conf[hadoop@nn-1 conf]$ cp spark-env.sh.template spark-env.sh[hadoop@nn-1 conf]$ cp slaves.template slaves
编辑spark-env.sh, 加入如下内容:
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export SPARK_MASTER_IP=nn-1export SPARK_WORKER_MEMORY=2gexport HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop
SPARK_WORKER_MEMORY根据实际情况配置。
编辑spark-env.sh, 加入如下内容:slaves
nn-2dn-1dn-2dn-3
slaves指定的是worker节点。
7.3 配置环境变量
[hadoop@nn-1 ~]$ vim .bash_profile
追加如下内容:
export HADOOP_HOME=/hadoop/hadoopexport SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
7.4 分发上面配置好的scala和spark目录到其他节点
[hadoop@nn-1 bin]$ cd /hadoop[hadoop@nn-1 ~]$ scp -rp spark-1.6.0-bin-hadoop2.6 hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp scala-2.11.7 hadoop@dn-1:/hadoop
7.5 启动Spark集群
[hadoop@nn-1 ~]$ /hadoop/spark-1.6.0-bin-hadoop2.6/sbin/start-all.sh
在nn-1和其他slaves节点查看进程:
在nn-1节点, 可以看到Master进程:
[hadoop@nn-1 ~]$ jps2473 JournalNode2541 NameNode4401 Jps2399 DFSZKFailoverController2687 JobHistoryServer2775 Master2351 QuorumPeerMain
在slaves节点可以看到Worker进程:
[hadoop@dn-1 ~]$ jps2522 NodeManager3449 Jps2007 QuorumPeerMain2141 DataNode2688 Worker2061 JournalNode2258 ResourceManager
查看spark页面:
7.6 运行测试案例
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--driver-memory 100M \
--executor-memory 200M \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
或者:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
8、配置机架感知
在nn-1和nn-2节点的配置文件/hadoop/hadoop/etc/hadoop/core-site.xml加入如下配置:
<property> <name>topology.script.file.name</name> <value>/hadoop/hadoop/etc/hadoop/RackAware.py</value> </property>
新增文件:/hadoop/hadoop/etc/hadoop/RackAware.py,内容如下:
#!/usr/bin/python#-*-coding:UTF-8 -*-import sysrack = {"dn-1":"rack2", "dn-2":"rack1", "dn-3":"rack1", "192.168.9.23":"rack2", "192.168.9.24":"rack1", "192.168.9.25":"rack1",}if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
设置权限:
[root@nn-1 hadoop]# chmod +x RackAware.py [root@nn-1 hadoop]# ll RackAware.py-rwxr-xr-x 1 hadoop hadoop 294 3月 1 21:24 RackAware.py
重启nn-1和nn-2上的NameNode服务:
[hadoop@nn-1 ~]$ hadoop-daemon.sh stop namenodestopping namenode[hadoop@nn-1 ~]$ hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
查看日志:
[root@nn-1 logs]# pwd/hadoop/hadoop/logs[root@nn-1 logs]# vim hadoop-hadoop-namenode-nn-1.log
使用命令查看拓扑:
[hadoop@dn-3 ~]$ hdfs dfsadmin -printTopology17/03/02 00:21:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableRack: /rack1 192.168.9.24:50010 (dn-2) 192.168.9.25:50010 (dn-3)Rack: /rack2 192.168.9.23:50010 (dn-1)
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export HADOOP_HEAPSIZE=2000export HADOOP_NAMENODE_INIT_HEAPSIZE=10000export HADOOP_OPTS="-server $HADOOP_OPTS -Djava.net.preferIPv4Stack=true"export HADOOP_NAMENODE_OPTS="-Xmx15000m -Xms15000m -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
<configuration><property><name>fs.defaultFS</name><value>hdfs://dpi</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/hadoop/hdfs/temp</value><description>Abase for other temporary directories.</description></property><property><name>hadoop.proxyuser.hduser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hduser.groups</name><value>*</value></property><property><name>ha.zookeeper.quorum</name><value>dn-1:2181,dn-2:2181,dn-3:2181</value></property></configuration>
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>nn-1:9001</value></property><property><name>dfs.namenode.name.dir</name><value>file:/hadoop/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/hadoop/hdfs/data,file:/hadoopdata/hdfs/data</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.nameservices</name><value>dpi</value></property><property><name>dfs.ha.namenodes.dpi</name><value>nn-1,nn-2</value></property><property><name>dfs.namenode.rpc-address.dpi.nn-1</name><value>nn-1:9000</value></property><property><name>dfs.namenode.http-address.dpi.nn-1</name><value>nn-1:50070</value></property><property><name>dfs.namenode.rpc-address.dpi.nn-2</name><value>nn-2:9000</value></property><property><name>dfs.namenode.http-address.dpi.nn-2</name><value>nn-2:50070</value></property><property><name>dfs.namenode.servicerpc-address.dpi.nn-1</name><value>nn-1:53310</value></property><property><name>dfs.namenode.servicerpc-address.dpi.nn-2</name><value>nn-2:53310</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://nn-1:8485;nn-2:8485;dn-1:8485/dpi</value></property><property><name>dfs.client.failover.proxy.provider.dpi</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.journalnode.edits.dir</name><value>/hadoop/hdfs/journal</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/hadoop/.ssh/id_rsa</value></property></configuration>
mkdir -p /hadoop/hdfs/namemkdir -p /hadoop/hdfs/datamkdir -p /hadoop/hdfs/tempmkdir -p /hadoop/hdfs/journal授权:chmod 755 /hadoop/hdfsmkdir -p /hadoopdata/hdfs/datachmod 755 /hadoopdata/hdfs
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>nn-1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>nn-1:19888</value></property></configuration>
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>dn-1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>dn-2</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.resourcemanager.zk-address</name><value>dn-1:2181,dn-2:2181,dn-3:2181</value><description>For multiple zk services, separate them with comma</description></property><property><name>yarn.resourcemanager.cluster-id</name><value>yarn-ha</value></property></configuration>
dn-1dn-2dn-3
# some Java parameters# export JAVA_HOME=/home/y/libexec/jdk1.6.0/if [ "$JAVA_HOME" != "" ]; then#echo "run java in $JAVA_HOME"JAVA_HOME=/usr/local/java/jdk1.7.0_79fiJAVA_HEAP_MAX=-Xmx15000mYARN_HEAPSIZE=15000export YARN_RESOURCEMANAGER_HEAPSIZE=5000export YARN_TIMELINESERVER_HEAPSIZE=10000export YARN_NODEMANAGER_HEAPSIZE=10000
[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@nn-2:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-2:/hadoop[hadoop@nn-1 ~]$ scp -rp hadoop hadoop@dn-3:/hadoop
4.1 在nn-1上传并解压zookeeper
4.2 修改配置文件/hadoop/zookeeper/conf/zoo.cfg
dataDir=/hadoop/zookeeper/data/dataLogDir=/hadoop/zookeeper/log/# the port at which the clients will connectclientPort=2181server.1=nn-1:2887:3887server.2=dn-1:2888:3888server.3=dn-2:2889:3889
4.3 从nn-1分发配置的zookeeper目录到其他节点
[hadoop@nn-1 ~]$ scp -rp zookeeper hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp zookeeper hadoop@dn-2:/hadoop
4.4 在所有zk节点创建目录
[hadoop@dn-1 ~]$ mkdir /hadoop/zookeeper/data/[hadoop@dn-1 ~]$ mkdir /hadoop/zookeeper/log/
4.5 修改myid
[hadoop@nn-1 data]$ echo 1 > /hadoop/zookeeper/data/myid
4.6 设置环境变量
$ echo "export ZOOKEEPER_HOME=/hadoop/zookeeper" >> $HOME/.bash_profile$ echo "export PATH=$ZOOKEEPER_HOME/bin:\$PATH" >> $HOME/.bash_profile$ source $HOME/.bash_profile
5 集群启动
5.1 启动zookeeper
根据规划, zk的节点为nn-1、dn-1和dn-2, 在这三台节点分别启动zk:
启动命令:
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh startJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgStarting zookeeper ... STARTED
查看进程, 可以看到QuorumPeerMain:
[hadoop@nn-1 ~]$ jps9382 QuorumPeerMain9407 Jps
查看状态, 可以看到Mode: follower, 说明这是zk的从节点:
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: follower
查看状态, 可以看到Mode: leader, 说明这是zk的leader节点:
[hadoop@dn-1 data]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: leader
5.2 格式化zookeeper集群(只做一次)(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hdfs zkfc -formatZK
中间有个交互的步骤, 输入Y:
进入zk, 查看是否创建成功:
[hadoop@nn-1 bin]$ ./zkCli.sh
5.3 启动zkfc(机器nn-1,nn-2上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start zkfcstarting zkfc, logging to /hadoop/hadoop/logs/hadoop-hadoop-zkfc-nn-1.out
使用jps, 可以看到进程DFSZKFailoverController:
[hadoop@nn-1 ~]$ jps9681 Jps9638 DFSZKFailoverController9382 QuorumPeerMain
5.4 启动journalnode
根据规划, 启动journalnode节点为nn-1、nn-2和dn-1, 在这三个节点分别使用如下的命令启动服务:
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /hadoop/hadoop/logs/hadoop-hadoop-journalnode-nn-1.out
使用jps命令可以看到进程JournalNode:
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain9762 Jps
5.5 格式化namenode(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hadoop namenode -format
查看日志信息:
5.6 启动namenode(机器nn-1上执行)
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
使用jps命令可以看到进程NameNode:
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain10157 NameNode10269 Jps
5.7 格式化secondnamnode(机器nn-2上执行)
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs namenode -bootstrapStandby
部分日志如下:
5.8 启动namenode(机器nn-2上执行)
[hadoop@nn-2 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-2.out
使用jps命令可以看到进程NameNode:
[hadoop@nn-2 ~]$ jps53990 NameNode54083 Jps53824 JournalNode53708 DFSZKFailoverController
5.9 启动datanode(机器dn-1到dn-3上执行)
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start datanode
使用jps可以看到DataNode进程:
[hadoop@dn-1 temp]$ jps57007 Jps56927 DataNode56223 QuorumPeerMain
5.10 启动resourcemanager
根据规划,resourcemanager做了HA, 服务在节点dn-1和dn-2上面, 在dn-1和dn-2上面启动resourcemanager:
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-resourcemanager-dn-1.out
使用jps, 可以看到进程ResourceManager:
[hadoop@dn-1 ~]$ jps57173 QuorumPeerMain58317 Jps57283 JournalNode58270 ResourceManager58149 DataNode
5.11 启动jobhistory
根据规划, jobhistory服务在nn-1上面, 使用如下命令启动:
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /hadoop/hadoop/logs/mapred-hadoop-historyserver-nn-1.out
使用jps, 可以看到进程JobHistoryServer:
[hadoop@nn-1 ~]$ jps11210 JobHistoryServer9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain11039 NameNode11303 Jps
5.12 启动NodeManager
根据规划, dn-1、dn-2和dn-3是nodemanager, 在这三个节点启动NodeManager:
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start nodemanagerstarting nodemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-nodemanager-dn-1.out
使用jps可以看到进程NodeManager:
[hadoop@dn-1 ~]$ jps58559 NodeManager57173 QuorumPeerMain58668 Jps57283 JournalNode58270 ResourceManager58149 DataNode
6、安装后查看和验证
6.1 HDFS相关操作命令
查看NameNode状态的命令
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -getServiceState nn-1
手工切换,将active的NameNode从nn-1切换到nn-2 。
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -DfSHAadmin -failover nn-1 nn-2
NameNode健康检查:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-1
将其中一台NameNode给kill后, 查看健康状态:
查看所有的DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report | more
查看正常DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -live17/03/01 22:49:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableConfigured Capacity: 224954695680 (209.51 GB)Present Capacity: 180557139968 (168.16 GB)DFS Remaining: 179963428864 (167.60 GB)DFS Used: 593711104 (566.21 MB)DFS Used%: 0.33%Under replicated blocks: 2Blocks with corrupt replicas: 0Missing blocks: 0-------------------------------------------------Live datanodes (3):Name: 192.168.9.23:50010 (dn-1)Hostname: dn-1Rack: /rack2Decommission Status : NormalConfigured Capacity: 74984898560 (69.84 GB)DFS Used: 197902336 (188.73 MB)Non DFS Used: 14869356544 (13.85 GB)DFS Remaining: 59917639680 (55.80 GB)DFS Used%: 0.26%DFS Remaining%: 79.91%Configured Cache Capacity: 0 (0 B)Cache Used: 0 (0 B)Cache Remaining: 0 (0 B)Cache Used%: 100.00%Cache Remaining%: 0.00%Xceivers: 1Last contact: Wed Mar 01 22:49:42 CST 2017
查看异常DataNode列表:
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -dead
获取指定DataNode信息(运行时间及版本等):
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-217/03/01 22:55:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-117/03/01 22:55:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
6.2 YARN相关的命令
查看resourceManager状态的命令:
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm1- active
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm2- standby
查看所有的yarn节点:
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -all -list17/03/01 23:06:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers dn-2:55506 RUNNING dn-2:8042 0 dn-1:56447 RUNNING dn-1:8042 0 dn-3:37533 RUNNING dn-3:8042 0
查看正常的yarn节点:
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -list17/03/01 23:07:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers dn-2:55506 RUNNING dn-2:8042 0 dn-1:56447 RUNNING dn-1:8042 0 dn-3:37533 RUNNING dn-3:8042 0
查看指定节点的信息:
/hadoop/hadoop/bin/yarn node -status <NodeId>
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -status dn-2:5550617/03/01 23:08:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableNode Report : Node-Id : dn-2:55506 Rack : /default-rack Node-State : RUNNING Node-Http-Address : dn-2:8042 Last-Health-Update : 星期三 01/三月/17 11:06:21:373CST Health-Report : Containers : 0 Memory-Used : 0MB Memory-Capacity : 8192MB CPU-Used : 0 vcores CPU-Capacity : 8 vcores Node-Labels :
查看当前运行的MapReduce任务:
[hadoop@dn-2 ~]$ /hadoop/hadoop/bin/yarn application -list17/03/01 23:10:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1 Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URLapplication_1488375590901_0004 QuasiMonteCarlo MAPREDUCE hadoop default RUNNING UNDEFINED
6.3 使用自带的例子测试
[hadoop@dn-1 ~]$ cd hadoop/[hadoop@dn-1 hadoop]$ [hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
[hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 01:51:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 01:51:15 INFO input.FileInputFormat: Total input paths to process : 217/02/28 01:51:15 INFO mapreduce.JobSubmitter: number of splits:217/02/28 01:51:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000117/02/28 01:51:16 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000117/02/28 01:51:16 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0001/17/02/28 01:51:16 INFO mapreduce.Job: Running job: job_1488216892564_000117/02/28 01:51:24 INFO mapreduce.Job: Job job_1488216892564_0001 running in uber mode : false17/02/28 01:51:24 INFO mapreduce.Job: map 0% reduce 0%17/02/28 01:51:38 INFO mapreduce.Job: map 100% reduce 0%17/02/28 01:51:49 INFO mapreduce.Job: map 100% reduce 100%17/02/28 01:51:49 INFO mapreduce.Job: Job job_1488216892564_0001 completed successfully17/02/28 01:51:50 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=326922 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=510 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=25604 Total time spent by all reduces in occupied slots (ms)=7267 Total time spent by all map tasks (ms)=25604 Total time spent by all reduce tasks (ms)=7267 Total vcore-seconds taken by all map tasks=25604 Total vcore-seconds taken by all reduce tasks=7267 Total megabyte-seconds taken by all map tasks=26218496 Total megabyte-seconds taken by all reduce tasks=7441408 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=274 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=419 CPU time spent (ms)=6940 Physical memory (bytes) snapshot=525877248 Virtual memory (bytes) snapshot=2535231488 Total committed heap usage (bytes)=260186112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97Job Finished in 35.466 secondsEstimated value of Pi is 3.17000000000000000000
6.4 查看NameNode
链接分别为:
192.168.9.21和192.168.9.22分别为NameNode和Secondary NameNode的地址。
6.5 查看NameNode 的HA切换是否正常
将nn-1上状态为active的NameNode进程kill, 查看nn-2上的NameNode能否从standby切换为active:
6.6 查看RM页面
查看节点信息, 192.168.9.23为Resource服务所在的active节点。
运行测试任务, 查看YARN HA能否自动切换:
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
运行到中间的时候, 将rm1上的rm给kill掉, 查看切换是否正常:
查看standby的HA state变成了active:
查看下面的日志, 程序运行期间由于rm1被kill, 程序报错, 然后Trying to fail over immediately, 最终程序运行成功。
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 02:11:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 02:11:12 INFO input.FileInputFormat: Total input paths to process : 217/02/28 02:11:12 INFO mapreduce.JobSubmitter: number of splits:217/02/28 02:11:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000217/02/28 02:11:13 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000217/02/28 02:11:13 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0002/17/02/28 02:11:13 INFO mapreduce.Job: Running job: job_1488216892564_000217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1. Trying to fail over immediately.java.io.EOFException: End of File Exception between local host is: "dn-2/192.168.9.24"; destination host is: "dn-1":8032; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1071) at org.apache.hadoop.ipc.Client$Connection.run(Client.java:966)17/02/28 02:11:18 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm2 after 1 fail over attempts. Trying to fail over after sleeping for 40859ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-2:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 43 more17/02/28 02:11:59 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm117/02/28 02:11:59 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1 after 2 fail over attempts. Trying to fail over after sleeping for 17213ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-1:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232) at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187) at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399) at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302) at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153) at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322) at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422) at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325) at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322) at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610) at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317) at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306) at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 42 more17/02/28 02:12:16 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:12:18 INFO mapreduce.Job: Job job_1488216892564_0002 running in uber mode : false17/02/28 02:12:18 INFO mapreduce.Job: map 0% reduce 0%17/02/28 02:12:22 INFO mapreduce.Job: map 100% reduce 0%17/02/28 02:12:28 INFO mapreduce.Job: map 100% reduce 100%17/02/28 02:12:28 INFO mapreduce.Job: Job job_1488216892564_0002 completed successfully17/02/28 02:12:28 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=326931 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=510 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=22713 Total time spent by all reduces in occupied slots (ms)=3213 Total time spent by all map tasks (ms)=22713 Total time spent by all reduce tasks (ms)=3213 Total vcore-seconds taken by all map tasks=22713 Total vcore-seconds taken by all reduce tasks=3213 Total megabyte-seconds taken by all map tasks=23258112 Total megabyte-seconds taken by all reduce tasks=3290112 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=274 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=233 CPU time spent (ms)=12680 Physical memory (bytes) snapshot=517484544 Virtual memory (bytes) snapshot=2548441088 Total committed heap usage (bytes)=260186112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97Job Finished in 76.447 secondsEstimated value of Pi is 3.17000000000000000000[hadoop@dn-2 hadoop]$
7、安装Spark
规划, 在现有的Hadoop集群安装spark集群:
master节点: nn-1
worker节点: nn-2、dn-1、dn-2、dn-3。
7.1 安装配置Scala
上传安装包到nn-1的/hadoop目录下面,解压:
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
环境变量后面统一配置。
7.2 安装spark
上传安装包spark-1.6.0-bin-hadoop2.6.tgz到nn-1的目录/hadoop下面, 解压
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
进入目录:/hadoop/spark-1.6.0-bin-hadoop2.6/conf
复制生成文件spark-env.sh和slaves:
[hadoop@nn-1 conf]$ pwd/hadoop/spark-1.6.0-bin-hadoop2.6/conf[hadoop@nn-1 conf]$ cp spark-env.sh.template spark-env.sh[hadoop@nn-1 conf]$ cp slaves.template slaves
编辑spark-env.sh, 加入如下内容:
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export SPARK_MASTER_IP=nn-1export SPARK_WORKER_MEMORY=2gexport HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop
SPARK_WORKER_MEMORY根据实际情况配置。
编辑spark-env.sh, 加入如下内容:slaves
nn-2dn-1dn-2dn-3
slaves指定的是worker节点。
7.3 配置环境变量
[hadoop@nn-1 ~]$ vim .bash_profile
追加如下内容:
export HADOOP_HOME=/hadoop/hadoopexport SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
7.4 分发上面配置好的scala和spark目录到其他节点
[hadoop@nn-1 bin]$ cd /hadoop[hadoop@nn-1 ~]$ scp -rp spark-1.6.0-bin-hadoop2.6 hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp scala-2.11.7 hadoop@dn-1:/hadoop
7.5 启动Spark集群
[hadoop@nn-1 ~]$ /hadoop/spark-1.6.0-bin-hadoop2.6/sbin/start-all.sh
在nn-1和其他slaves节点查看进程:
在nn-1节点, 可以看到Master进程:
[hadoop@nn-1 ~]$ jps2473 JournalNode2541 NameNode4401 Jps2399 DFSZKFailoverController2687 JobHistoryServer2775 Master2351 QuorumPeerMain
在slaves节点可以看到Worker进程:
[hadoop@dn-1 ~]$ jps2522 NodeManager3449 Jps2007 QuorumPeerMain2141 DataNode2688 Worker2061 JournalNode2258 ResourceManager
查看spark页面:
7.6 运行测试案例
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--driver-memory 100M \
--executor-memory 200M \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
或者:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
8、配置机架感知
在nn-1和nn-2节点的配置文件/hadoop/hadoop/etc/hadoop/core-site.xml加入如下配置:
<property> <name>topology.script.file.name</name> <value>/hadoop/hadoop/etc/hadoop/RackAware.py</value> </property>
新增文件:/hadoop/hadoop/etc/hadoop/RackAware.py,内容如下:
#!/usr/bin/python#-*-coding:UTF-8 -*-import sysrack = {"dn-1":"rack2", "dn-2":"rack1", "dn-3":"rack1", "192.168.9.23":"rack2", "192.168.9.24":"rack1", "192.168.9.25":"rack1",}if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
设置权限:
[root@nn-1 hadoop]# chmod +x RackAware.py [root@nn-1 hadoop]# ll RackAware.py-rwxr-xr-x 1 hadoop hadoop 294 3月 1 21:24 RackAware.py
重启nn-1和nn-2上的NameNode服务:
[hadoop@nn-1 ~]$ hadoop-daemon.sh stop namenodestopping namenode[hadoop@nn-1 ~]$ hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
查看日志:
[root@nn-1 logs]# pwd/hadoop/hadoop/logs[root@nn-1 logs]# vim hadoop-hadoop-namenode-nn-1.log
使用命令查看拓扑:
[hadoop@dn-3 ~]$ hdfs dfsadmin -printTopology17/03/02 00:21:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableRack: /rack1 192.168.9.24:50010 (dn-2) 192.168.9.25:50010 (dn-3)Rack: /rack2 192.168.9.23:50010 (dn-1)
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh startJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgStarting zookeeper ... STARTED
[hadoop@nn-1 ~]$ jps9382 QuorumPeerMain9407 Jps
[hadoop@nn-1 ~]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: follower
[hadoop@dn-1 data]$ /hadoop/zookeeper/bin/zkServer.sh statusJMX enabled by defaultUsing config: /hadoop/zookeeper/bin/../conf/zoo.cfgMode: leader
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hdfs zkfc -formatZK
[hadoop@nn-1 bin]$ ./zkCli.sh
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start zkfcstarting zkfc, logging to /hadoop/hadoop/logs/hadoop-hadoop-zkfc-nn-1.out
[hadoop@nn-1 ~]$ jps9681 Jps9638 DFSZKFailoverController9382 QuorumPeerMain
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /hadoop/hadoop/logs/hadoop-hadoop-journalnode-nn-1.out
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain9762 Jps
[hadoop@nn-1 ~]$ /hadoop/hadoop/bin/hadoop namenode -format
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
[hadoop@nn-1 ~]$ jps9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain10157 NameNode10269 Jps
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs namenode -bootstrapStandby
[hadoop@nn-2 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-2.out
[hadoop@nn-2 ~]$ jps53990 NameNode54083 Jps53824 JournalNode53708 DFSZKFailoverController
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/hadoop-daemon.sh start datanode
[hadoop@dn-1 temp]$ jps57007 Jps56927 DataNode56223 QuorumPeerMain
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-resourcemanager-dn-1.out
[hadoop@dn-1 ~]$ jps57173 QuorumPeerMain58317 Jps57283 JournalNode58270 ResourceManager58149 DataNode
[hadoop@nn-1 ~]$ /hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /hadoop/hadoop/logs/mapred-hadoop-historyserver-nn-1.out
[hadoop@nn-1 ~]$ jps11210 JobHistoryServer9714 JournalNode9638 DFSZKFailoverController9382 QuorumPeerMain11039 NameNode11303 Jps
[hadoop@dn-1 ~]$ /hadoop/hadoop/sbin/yarn-daemon.sh start nodemanagerstarting nodemanager, logging to /hadoop/hadoop/logs/yarn-hadoop-nodemanager-dn-1.out
[hadoop@dn-1 ~]$ jps58559 NodeManager57173 QuorumPeerMain58668 Jps57283 JournalNode58270 ResourceManager58149 DataNode
6.1 HDFS相关操作命令
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -getServiceState nn-1
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -DfSHAadmin -failover nn-1 nn-2
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-1
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report | more
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -live17/03/01 22:49:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableConfigured Capacity: 224954695680 (209.51 GB)Present Capacity: 180557139968 (168.16 GB)DFS Remaining: 179963428864 (167.60 GB)DFS Used: 593711104 (566.21 MB)DFS Used%: 0.33%Under replicated blocks: 2Blocks with corrupt replicas: 0Missing blocks: 0-------------------------------------------------Live datanodes (3):Name: 192.168.9.23:50010 (dn-1)Hostname: dn-1Rack: /rack2Decommission Status : NormalConfigured Capacity: 74984898560 (69.84 GB)DFS Used: 197902336 (188.73 MB)Non DFS Used: 14869356544 (13.85 GB)DFS Remaining: 59917639680 (55.80 GB)DFS Used%: 0.26%DFS Remaining%: 79.91%Configured Cache Capacity: 0 (0 B)Cache Used: 0 (0 B)Cache Remaining: 0 (0 B)Cache Used%: 100.00%Cache Remaining%: 0.00%Xceivers: 1Last contact: Wed Mar 01 22:49:42 CST 2017
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs dfsadmin -report -dead
[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-217/03/01 22:55:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[hadoop@nn-2 ~]$ /hadoop/hadoop/bin/hdfs haadmin -checkHealth nn-117/03/01 22:55:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
6.2 YARN相关的命令
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm1- active
[hadoop@dn-1 hadoop]$ yarn rmadmin -getServiceState rm2- standby
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -all -list17/03/01 23:06:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3Node-Id Node-State Node-Http-Address Number-of-Running-Containersdn-2:55506 RUNNING dn-2:8042 0dn-1:56447 RUNNING dn-1:8042 0dn-3:37533 RUNNING dn-3:8042 0
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -list17/03/01 23:07:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal Nodes:3Node-Id Node-State Node-Http-Address Number-of-Running-Containersdn-2:55506 RUNNING dn-2:8042 0dn-1:56447 RUNNING dn-1:8042 0dn-3:37533 RUNNING dn-3:8042 0
[hadoop@dn-1 hadoop]$ /hadoop/hadoop/bin/yarn node -status dn-2:5550617/03/01 23:08:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableNode Report :Node-Id : dn-2:55506Rack : /default-rackNode-State : RUNNINGNode-Http-Address : dn-2:8042Last-Health-Update : 星期三 01/三月/17 11:06:21:373CSTHealth-Report :Containers : 0Memory-Used : 0MBMemory-Capacity : 8192MBCPU-Used : 0 vcoresCPU-Capacity : 8 vcoresNode-Labels :
[hadoop@dn-2 ~]$ /hadoop/hadoop/bin/yarn application -list17/03/01 23:10:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableTotal number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URLapplication_1488375590901_0004 QuasiMonteCarlo MAPREDUCE hadoop default RUNNING UNDEFINED
6.3 使用自带的例子测试
[hadoop@dn-1 ~]$ cd hadoop/[hadoop@dn-1 hadoop]$[hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
[hadoop@dn-1 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 01:51:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 01:51:15 INFO input.FileInputFormat: Total input paths to process : 217/02/28 01:51:15 INFO mapreduce.JobSubmitter: number of splits:217/02/28 01:51:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000117/02/28 01:51:16 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000117/02/28 01:51:16 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0001/17/02/28 01:51:16 INFO mapreduce.Job: Running job: job_1488216892564_000117/02/28 01:51:24 INFO mapreduce.Job: Job job_1488216892564_0001 running in uber mode : false17/02/28 01:51:24 INFO mapreduce.Job: map 0% reduce 0%17/02/28 01:51:38 INFO mapreduce.Job: map 100% reduce 0%17/02/28 01:51:49 INFO mapreduce.Job: map 100% reduce 100%17/02/28 01:51:49 INFO mapreduce.Job: Job job_1488216892564_0001 completed successfully17/02/28 01:51:50 INFO mapreduce.Job: Counters: 49File System CountersFILE: Number of bytes read=50FILE: Number of bytes written=326922FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=510HDFS: Number of bytes written=215HDFS: Number of read operations=11HDFS: Number of large read operations=0HDFS: Number of write operations=3Job CountersLaunched map tasks=2Launched reduce tasks=1Data-local map tasks=2Total time spent by all maps in occupied slots (ms)=25604Total time spent by all reduces in occupied slots (ms)=7267Total time spent by all map tasks (ms)=25604Total time spent by all reduce tasks (ms)=7267Total vcore-seconds taken by all map tasks=25604Total vcore-seconds taken by all reduce tasks=7267Total megabyte-seconds taken by all map tasks=26218496Total megabyte-seconds taken by all reduce tasks=7441408Map-Reduce FrameworkMap input records=2Map output records=4Map output bytes=36Map output materialized bytes=56Input split bytes=274Combine input records=0Combine output records=0Reduce input groups=2Reduce shuffle bytes=56Reduce input records=4Reduce output records=0Spilled Records=8Shuffled Maps =2Failed Shuffles=0Merged Map outputs=2GC time elapsed (ms)=419CPU time spent (ms)=6940Physical memory (bytes) snapshot=525877248Virtual memory (bytes) snapshot=2535231488Total committed heap usage (bytes)=260186112Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=236File Output Format CountersBytes Written=97Job Finished in 35.466 secondsEstimated value of Pi is 3.17000000000000000000
6.4 查看NameNode
6.5 查看NameNode 的HA切换是否正常
6.6 查看RM页面
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200
[hadoop@dn-2 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 2 200Number of Maps = 2Samples per Map = 20017/02/28 02:11:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWrote input for Map #0Wrote input for Map #1Starting Job17/02/28 02:11:12 INFO input.FileInputFormat: Total input paths to process : 217/02/28 02:11:12 INFO mapreduce.JobSubmitter: number of splits:217/02/28 02:11:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1488216892564_000217/02/28 02:11:13 INFO impl.YarnClientImpl: Submitted application application_1488216892564_000217/02/28 02:11:13 INFO mapreduce.Job: The url to track the job: http://dn-1:8088/proxy/application_1488216892564_0002/17/02/28 02:11:13 INFO mapreduce.Job: Running job: job_1488216892564_000217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1. Trying to fail over immediately.java.io.EOFException: End of File Exception between local host is: "dn-2/192.168.9.24"; destination host is: "dn-1":8032; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFExceptionat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:526)at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764)at org.apache.hadoop.ipc.Client.call(Client.java:1472)at org.apache.hadoop.ipc.Client.call(Client.java:1399)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source)at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source)at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399)at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302)at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153)at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322)at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422)at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575)at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325)at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322)at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610)at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355)at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317)at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306)at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.util.RunJar.run(RunJar.java:221)at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.io.EOFExceptionat java.io.DataInputStream.readInt(DataInputStream.java:392)at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1071)at org.apache.hadoop.ipc.Client$Connection.run(Client.java:966)17/02/28 02:11:18 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:11:18 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm2 after 1 fail over attempts. Trying to fail over after sleeping for 40859ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-2:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefusedat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:526)at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731)at org.apache.hadoop.ipc.Client.call(Client.java:1472)at org.apache.hadoop.ipc.Client.call(Client.java:1399)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source)at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source)at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399)at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302)at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153)at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322)at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422)at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575)at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325)at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322)at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610)at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355)at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317)at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306)at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.util.RunJar.run(RunJar.java:221)at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739)at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530)at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494)at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607)at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705)at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368)at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521)at org.apache.hadoop.ipc.Client.call(Client.java:1438)... 43 more17/02/28 02:11:59 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm117/02/28 02:11:59 INFO retry.RetryInvocationHandler: Exception while invoking getApplicationReport of class ApplicationClientProtocolPBClientImpl over rm1 after 2 fail over attempts. Trying to fail over after sleeping for 17213ms.java.net.ConnectException: Call From dn-2/192.168.9.24 to dn-1:8032 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefusedat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:526)at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731)at org.apache.hadoop.ipc.Client.call(Client.java:1472)at org.apache.hadoop.ipc.Client.call(Client.java:1399)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)at com.sun.proxy.$Proxy14.getApplicationReport(Unknown Source)at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getApplicationReport(ApplicationClientProtocolPBClientImpl.java:187)at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)at com.sun.proxy.$Proxy15.getApplicationReport(Unknown Source)at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getApplicationReport(YarnClientImpl.java:399)at org.apache.hadoop.mapred.ResourceMgrDelegate.getApplicationReport(ResourceMgrDelegate.java:302)at org.apache.hadoop.mapred.ClientServiceDelegate.getProxy(ClientServiceDelegate.java:153)at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:322)at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:422)at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:575)at org.apache.hadoop.mapreduce.Job$1.run(Job.java:325)at org.apache.hadoop.mapreduce.Job$1.run(Job.java:322)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:322)at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:610)at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1355)at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1317)at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306)at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:606)at org.apache.hadoop.util.RunJar.run(RunJar.java:221)at org.apache.hadoop.util.RunJar.main(RunJar.java:136)Caused by: java.net.ConnectException: 拒绝连接at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739)at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530)at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494)at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607)at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705)at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368)at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521)at org.apache.hadoop.ipc.Client.call(Client.java:1438)... 42 more17/02/28 02:12:16 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm217/02/28 02:12:18 INFO mapreduce.Job: Job job_1488216892564_0002 running in uber mode : false17/02/28 02:12:18 INFO mapreduce.Job: map 0% reduce 0%17/02/28 02:12:22 INFO mapreduce.Job: map 100% reduce 0%17/02/28 02:12:28 INFO mapreduce.Job: map 100% reduce 100%17/02/28 02:12:28 INFO mapreduce.Job: Job job_1488216892564_0002 completed successfully17/02/28 02:12:28 INFO mapreduce.Job: Counters: 49File System CountersFILE: Number of bytes read=50FILE: Number of bytes written=326931FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=510HDFS: Number of bytes written=215HDFS: Number of read operations=11HDFS: Number of large read operations=0HDFS: Number of write operations=3Job CountersLaunched map tasks=2Launched reduce tasks=1Data-local map tasks=2Total time spent by all maps in occupied slots (ms)=22713Total time spent by all reduces in occupied slots (ms)=3213Total time spent by all map tasks (ms)=22713Total time spent by all reduce tasks (ms)=3213Total vcore-seconds taken by all map tasks=22713Total vcore-seconds taken by all reduce tasks=3213Total megabyte-seconds taken by all map tasks=23258112Total megabyte-seconds taken by all reduce tasks=3290112Map-Reduce FrameworkMap input records=2Map output records=4Map output bytes=36Map output materialized bytes=56Input split bytes=274Combine input records=0Combine output records=0Reduce input groups=2Reduce shuffle bytes=56Reduce input records=4Reduce output records=0Spilled Records=8Shuffled Maps =2Failed Shuffles=0Merged Map outputs=2GC time elapsed (ms)=233CPU time spent (ms)=12680Physical memory (bytes) snapshot=517484544Virtual memory (bytes) snapshot=2548441088Total committed heap usage (bytes)=260186112Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=236File Output Format CountersBytes Written=97Job Finished in 76.447 secondsEstimated value of Pi is 3.17000000000000000000[hadoop@dn-2 hadoop]$
7、安装Spark
规划, 在现有的Hadoop集群安装spark集群:
master节点: nn-1
worker节点: nn-2、dn-1、dn-2、dn-3。
7.1 安装配置Scala
上传安装包到nn-1的/hadoop目录下面,解压:
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
环境变量后面统一配置。
7.2 安装spark
上传安装包spark-1.6.0-bin-hadoop2.6.tgz到nn-1的目录/hadoop下面, 解压
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
进入目录:/hadoop/spark-1.6.0-bin-hadoop2.6/conf
复制生成文件spark-env.sh和slaves:
[hadoop@nn-1 conf]$ pwd/hadoop/spark-1.6.0-bin-hadoop2.6/conf[hadoop@nn-1 conf]$ cp spark-env.sh.template spark-env.sh[hadoop@nn-1 conf]$ cp slaves.template slaves
编辑spark-env.sh, 加入如下内容:
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export SPARK_MASTER_IP=nn-1export SPARK_WORKER_MEMORY=2gexport HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop
SPARK_WORKER_MEMORY根据实际情况配置。
编辑spark-env.sh, 加入如下内容:slaves
nn-2dn-1dn-2dn-3
slaves指定的是worker节点。
7.3 配置环境变量
[hadoop@nn-1 ~]$ vim .bash_profile
追加如下内容:
export HADOOP_HOME=/hadoop/hadoopexport SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
7.4 分发上面配置好的scala和spark目录到其他节点
[hadoop@nn-1 bin]$ cd /hadoop[hadoop@nn-1 ~]$ scp -rp spark-1.6.0-bin-hadoop2.6 hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp scala-2.11.7 hadoop@dn-1:/hadoop
7.5 启动Spark集群
[hadoop@nn-1 ~]$ /hadoop/spark-1.6.0-bin-hadoop2.6/sbin/start-all.sh
在nn-1和其他slaves节点查看进程:
在nn-1节点, 可以看到Master进程:
[hadoop@nn-1 ~]$ jps2473 JournalNode2541 NameNode4401 Jps2399 DFSZKFailoverController2687 JobHistoryServer2775 Master2351 QuorumPeerMain
在slaves节点可以看到Worker进程:
[hadoop@dn-1 ~]$ jps2522 NodeManager3449 Jps2007 QuorumPeerMain2141 DataNode2688 Worker2061 JournalNode2258 ResourceManager
查看spark页面:
7.6 运行测试案例
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--driver-memory 100M \
--executor-memory 200M \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
或者:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
8、配置机架感知
在nn-1和nn-2节点的配置文件/hadoop/hadoop/etc/hadoop/core-site.xml加入如下配置:
<property> <name>topology.script.file.name</name> <value>/hadoop/hadoop/etc/hadoop/RackAware.py</value> </property>
新增文件:/hadoop/hadoop/etc/hadoop/RackAware.py,内容如下:
#!/usr/bin/python#-*-coding:UTF-8 -*-import sysrack = {"dn-1":"rack2", "dn-2":"rack1", "dn-3":"rack1", "192.168.9.23":"rack2", "192.168.9.24":"rack1", "192.168.9.25":"rack1",}if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
设置权限:
[root@nn-1 hadoop]# chmod +x RackAware.py [root@nn-1 hadoop]# ll RackAware.py-rwxr-xr-x 1 hadoop hadoop 294 3月 1 21:24 RackAware.py
重启nn-1和nn-2上的NameNode服务:
[hadoop@nn-1 ~]$ hadoop-daemon.sh stop namenodestopping namenode[hadoop@nn-1 ~]$ hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
查看日志:
[root@nn-1 logs]# pwd/hadoop/hadoop/logs[root@nn-1 logs]# vim hadoop-hadoop-namenode-nn-1.log
使用命令查看拓扑:
[hadoop@dn-3 ~]$ hdfs dfsadmin -printTopology17/03/02 00:21:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableRack: /rack1 192.168.9.24:50010 (dn-2) 192.168.9.25:50010 (dn-3)Rack: /rack2 192.168.9.23:50010 (dn-1)
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
[hadoop@nn-1 ~]$ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz
[hadoop@nn-1 conf]$ pwd/hadoop/spark-1.6.0-bin-hadoop2.6/conf[hadoop@nn-1 conf]$ cp spark-env.sh.template spark-env.sh[hadoop@nn-1 conf]$ cp slaves.template slaves
export JAVA_HOME=/usr/local/java/jdk1.7.0_79export SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export SPARK_MASTER_IP=nn-1export SPARK_WORKER_MEMORY=2gexport HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop
nn-2dn-1dn-2dn-3
[hadoop@nn-1 ~]$ vim .bash_profile
export HADOOP_HOME=/hadoop/hadoopexport SCALA_HOME=/hadoop/scala-2.11.7export SPARK_HOME=/hadoop/spark-1.6.0-bin-hadoop2.6export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
[hadoop@nn-1 bin]$ cd /hadoop[hadoop@nn-1 ~]$ scp -rp spark-1.6.0-bin-hadoop2.6 hadoop@dn-1:/hadoop[hadoop@nn-1 ~]$ scp -rp scala-2.11.7 hadoop@dn-1:/hadoop
[hadoop@nn-1 ~]$ /hadoop/spark-1.6.0-bin-hadoop2.6/sbin/start-all.sh
[hadoop@nn-1 ~]$ jps2473 JournalNode2541 NameNode4401 Jps2399 DFSZKFailoverController2687 JobHistoryServer2775 Master2351 QuorumPeerMain
[hadoop@dn-1 ~]$ jps2522 NodeManager3449 Jps2007 QuorumPeerMain2141 DataNode2688 Worker2061 JournalNode2258 ResourceManager
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--driver-memory 100M \
--executor-memory 200M \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
或者:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--executor-cores 1 \
--queue default \
lib/spark-examples*.jar 10
<property><name>topology.script.file.name</name><value>/hadoop/hadoop/etc/hadoop/RackAware.py</value></property>
#!/usr/bin/python#-*-coding:UTF-8 -*-import sysrack = {"dn-1":"rack2","dn-2":"rack1","dn-3":"rack1","192.168.9.23":"rack2","192.168.9.24":"rack1","192.168.9.25":"rack1",}if __name__=="__main__":print "/" + rack.get(sys.argv[1],"rack0")
[root@nn-1 hadoop]# chmod +x RackAware.py[root@nn-1 hadoop]# ll RackAware.py-rwxr-xr-x 1 hadoop hadoop 294 3月 1 21:24 RackAware.py
[hadoop@nn-1 ~]$ hadoop-daemon.sh stop namenodestopping namenode[hadoop@nn-1 ~]$ hadoop-daemon.sh start namenodestarting namenode, logging to /hadoop/hadoop/logs/hadoop-hadoop-namenode-nn-1.out
[root@nn-1 logs]# pwd/hadoop/hadoop/logs[root@nn-1 logs]# vim hadoop-hadoop-namenode-nn-1.log
[hadoop@dn-3 ~]$ hdfs dfsadmin -printTopology17/03/02 00:21:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableRack: /rack1192.168.9.24:50010 (dn-2)192.168.9.25:50010 (dn-3)Rack: /rack2192.168.9.23:50010 (dn-1)
Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)的更多相关文章
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- 最近有安装了一次hadoop集群,NameNode启动失败,及原因
最近有安装了一次hadoop集群,NameNode启动失败,查看日志,找到以下原因: 遇到的异常1: org.apache.hadoop.hdfs.server.common.Inconsistent ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Hadoop集群安装-CDH5(5台服务器集群)
CDH5包下载:http://archive.cloudera.com/cdh5/ 架构设计: 主机规划: IP Host 部署模块 进程 192.168.254.151 Hadoop-NN-01 N ...
随机推荐
- spring-boot-plus V1.2.2 发布,5 Minutes Finish CRUD
更新日志 CHANGELOG [V1.2.2-RELEASE] 2019.08.26
- 使用flask-restful搭建API
最简单的例子 ---~~~~ 访问http://127.0.0.1:5000/ , 返回{"hello": "world"} from flask import ...
- .net打杂工程师的面试感想和总结
上个月26号辞职了,今天开始第一场面试,随便写写感想,后面还会继续分享一些感想 前言 这个时候找工作是不是找死? 开门见山吧,95年的,之前做过两份工作,第一家公司在做了2年2个月,在北京,也就是去年 ...
- unity编辑器扩展_03(在组件中右击创建一个选项,并通过该选项修改该组件下面的字段的值)
在组件中右击创建一个选项代码: [MenuItem("CONTEXT/PlayerHealth/InitHealth")] static void Test5() { ...
- eslint语法规范
规则 缩进使用两个空格. eslint: indent function hello (name) { console.log('hi', name) } 1 2 3 字符串使用单引号,除 ...
- Leetcode之二分法专题-852. 山脉数组的峰顶索引(Peak Index in a Mountain Array)
Leetcode之二分法专题-852. 山脉数组的峰顶索引(Peak Index in a Mountain Array) 我们把符合下列属性的数组 A 称作山脉: A.length >= 3 ...
- MSIL实用指南-给字段、属性、方法、类、程序集加Attribute
C#编程中可以给字段.方法.类以及程序集加特性即继承于Attribute的类.这里讲解怎么在IL中给它们加上特性. 生成字段的对应的类是FieldBuilder,生成属性的对应的类是PropertyB ...
- HDU-4027-Can you answer these queries?线段树+区间根号+剪枝
传送门Can you answer these queries? 题意:线段树,只是区间修改变成 把每个点的值开根号: 思路:对[X,Y]的值开根号,由于最大为 263.可以观察到最多开根号7次即为1 ...
- 牛客小白月赛4 C 病菌感染 dfs
链接:https://www.nowcoder.com/acm/contest/134/C来源:牛客网 题目描述 铁子和顺溜上生物课的时候不小心将几滴超级病菌滴到了培养皿上,这可急坏了他们. 培养皿可 ...
- POJ 1390 Blocks (区间DP) 题解
题意 t组数据,每组数据有n个方块,给出它们的颜色,每次消去的得分为相同颜色块个数的平方(要求连续),求最大得分. 首先看到这题我们发现我们要把大块尽可能放在一起才会有最大收益,我们要将相同颜色块合在 ...