Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行。
我们编写网络爬虫最主要的目的是爬取想要的数据还有通过爬虫去自动完成我们想在网站中做的一些事情。
从今天开始我会从基础开始讲解如何通过网络爬虫去完成你想要做的事。
先来看一段简单的代码。
import requests #导入requests包
url = 'https://www.cnblogs.com/LexMoon/'
strhtml = requests.get(url) #get方式获取网页数据
print(strhtml.text)
首先是import requests来导入网络请求相关的包,然后定义一个字符串url也就是目标网页,之后我们就要用导入的requests包来请求这个网页的内容。
这里用了requests.get(url),这个get并不是拿取的那个get,而是一种关于网络请求的方法。
网络请求的方法有很多,最常见的有get,post,其它如put,delete你几乎不会见到。
requests.get(url)就是向url这个网页发送get请求(request),然后会返回一个结果,也就是这次请求的响应信息。
响应信息中分为响应头和响应内容。
响应头就是你这次访问是不是成功了,返回给你的是什么类型的数据,还有很多一些。
响应内容中就是你获得的网页源码了。
好了,这样你就算是入门Python爬虫了,但是还是有很多问题。
1. get和post请求有什么区别?
2. 为什么有些网页我爬取到了,里面却没有我想要的数据?
3. 为什么有些网站我爬下来的内容和我真实看到的网站内容不一样?
get和post请求有什么区别?
get和post的区别主要在于参数的位置,比如说有一个需要登录用户的网站,当我们点击登录之后,账号密码应该放在哪里。
get请求最直观的体现就是请求的参数就放在了URL中。
比如说你百度Python这个关键字,就可以发现它的URL如下:
https://www.baidu.com/s?wd=Python&rsv_spt=1
这里面的dw=Python就是参数之一了,get请求的参数用?开始,用&分隔。
如果我们需要输入密码的网站用了get请求,我们的个人信息不是很容易暴露吗,所以就需要post请求了。
在post请求中,参数会放在请求体内。
比如说下面是我登录W3C网站时的请求,可以看到Request Method是post方式。
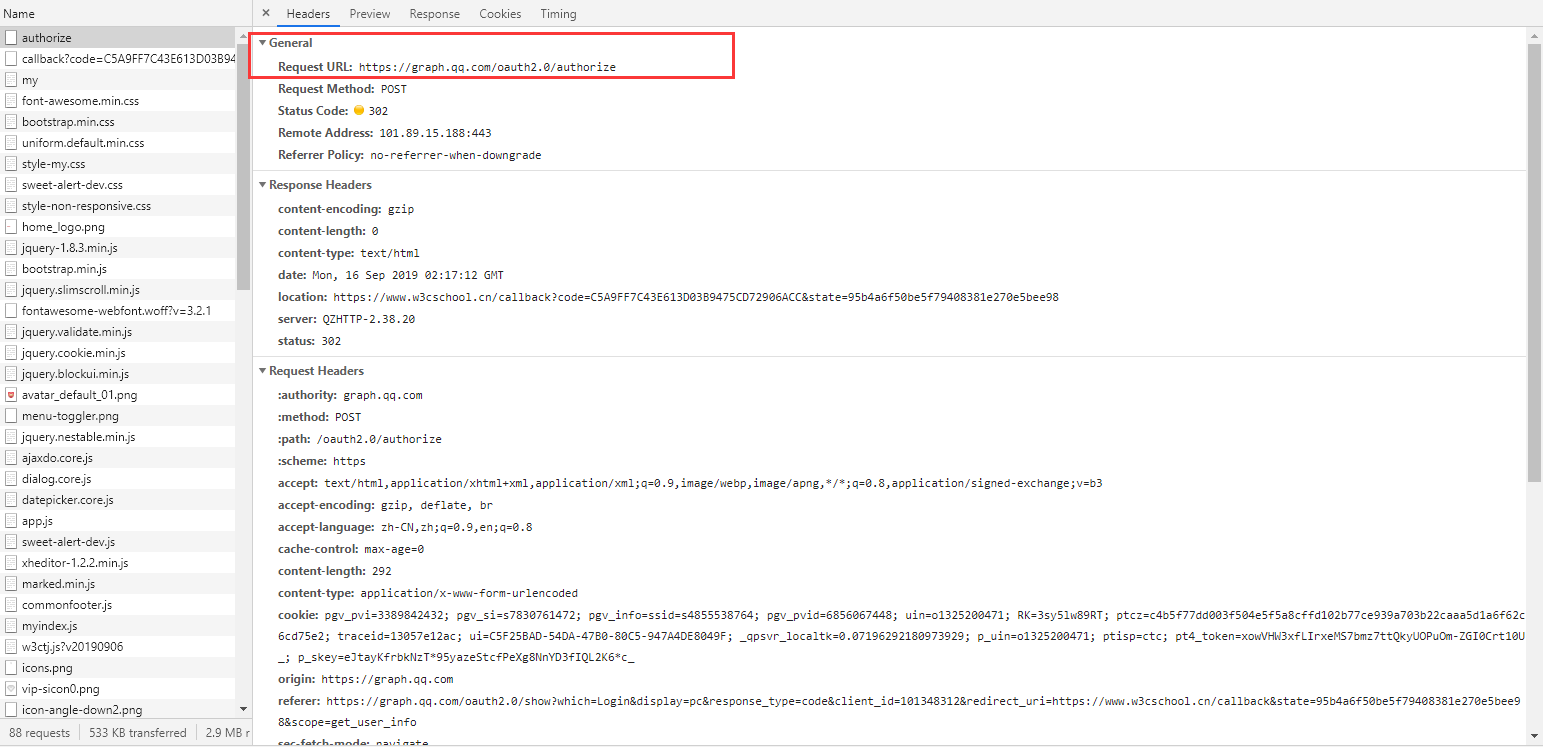
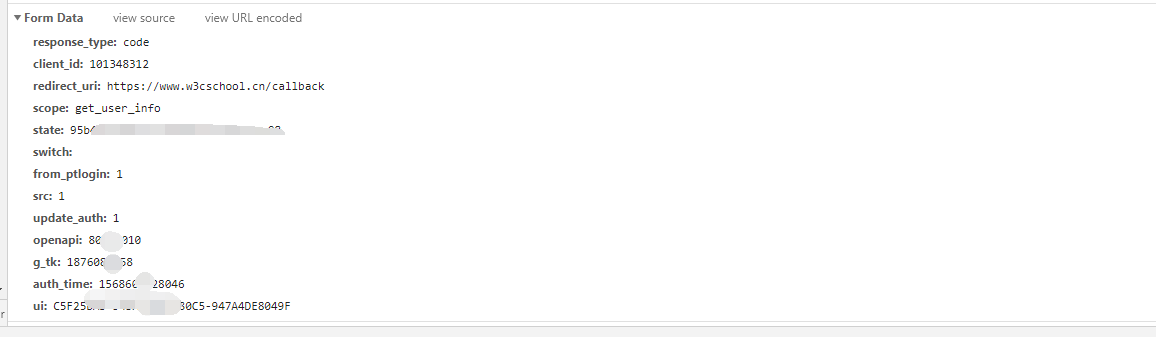
在请求的下面还有我们发送的登录信息,里面就是加密过后的账号密码,发送给对方服务器来检验的。
为什么有些网页我爬取到了,里面却没有我想要的数据?
我们的爬虫有时候可能爬下来一个网站,在查看里面数据的时候会发现,爬下来的是目标网页,但是里面我们想要的数据却没有。
这个问题大多数发生在目标数据是那些列表型的网页,比如说前几天班上一个同学问了我一个问题,他在爬携程的航班信息时,爬下来的网页除了获得不了航班的信息,其他地方都可以拿到。
网页地址:https://flights.ctrip.com/itinerary/oneway/cgq-bjs?date=2019-09-14
如下图:
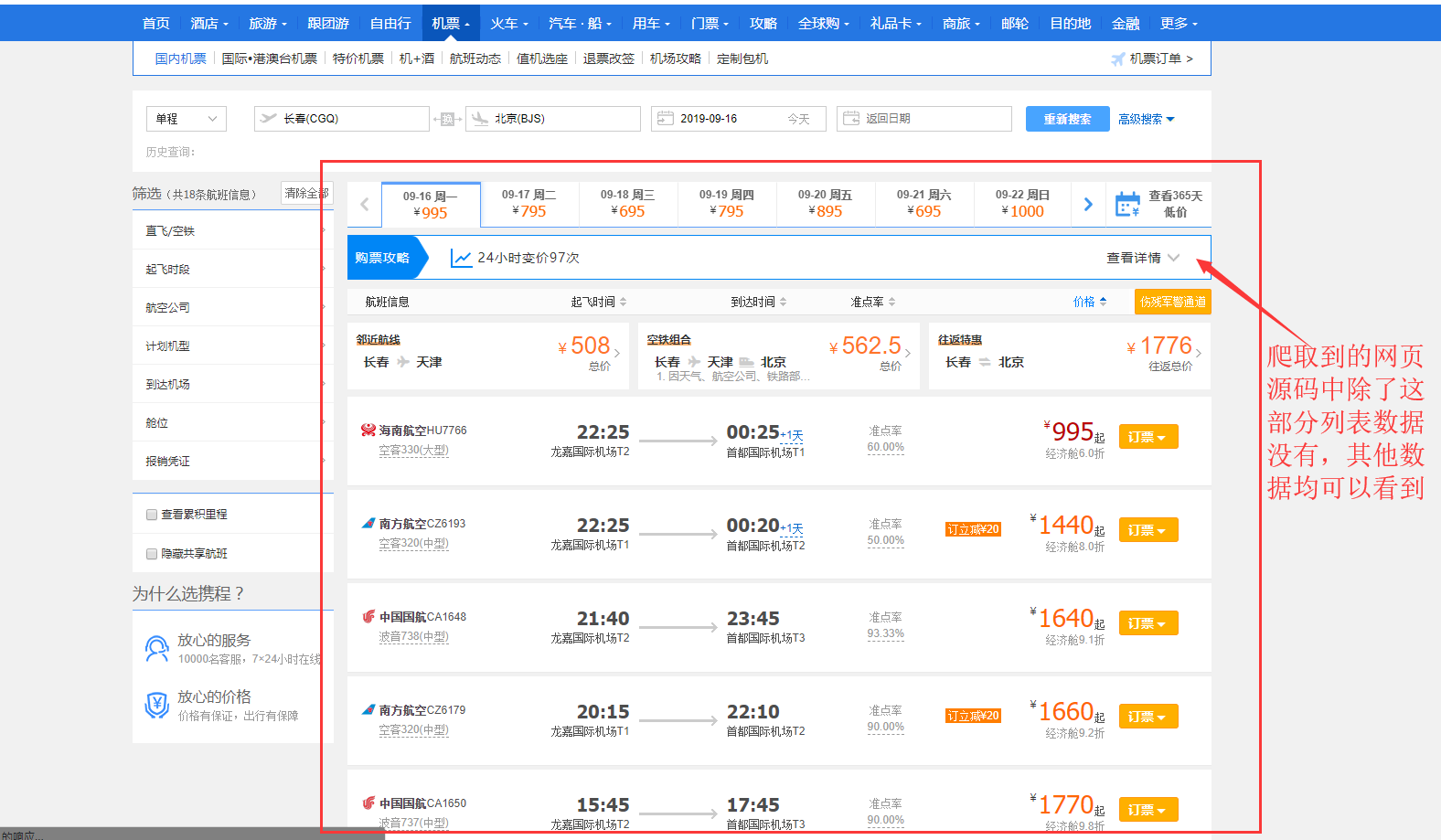
这是一个很常见的问题,因为他requests.get的时候,是去get的上面我放的那个URL地址,但是这个网页虽然是这个地址,但是他里面的数据却不是这个地址。
听起来很像很难,但是从携程这个网站的设计人的角度来说,加载的这部分航班列表信息可能很庞大,如果你是直接放在这个网页里面,我们用户打开这个网页可能需要很久,以至于认为网页挂了然后关闭,所以设计者在这个URL请求中只放了主体框架,让用户很快进入网页中,而主要的航班数据则是之后再加载,这样用户就不会因为等待很长时间而退出了。
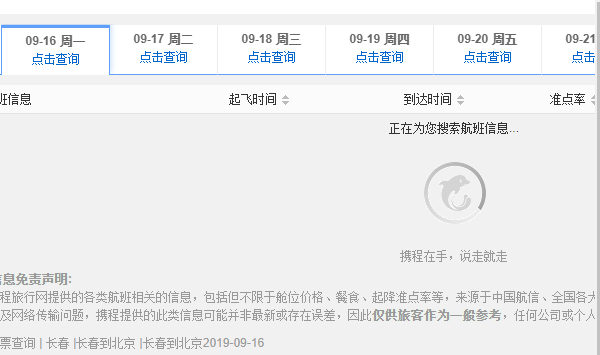
说到底怎么做是为了用户体验,那么我们应该怎么解决这个问题呢?
如果你学过前端,你应该知道Ajax异步请求,不知道也没事,毕竟我们这里不是在说前端技术。
我们只需要知道我们最开始请求的https://flights.ctrip.com/itinerary/oneway/cgq-bjs?date=2019-09-14这个网页中有一段js脚本,在这个网页请求到之后会去执行,而这段脚本的目的就是去请求我们要爬的航班信息。
这时候我们可以打开浏览器的控制台,推荐使用谷歌或者火狐浏览器,按F进入坦克,不,按F12进入浏览器控制台,然后点击NetWork。
在这里我们就可以看到这个网页中发生的所有网络请求和响应了。
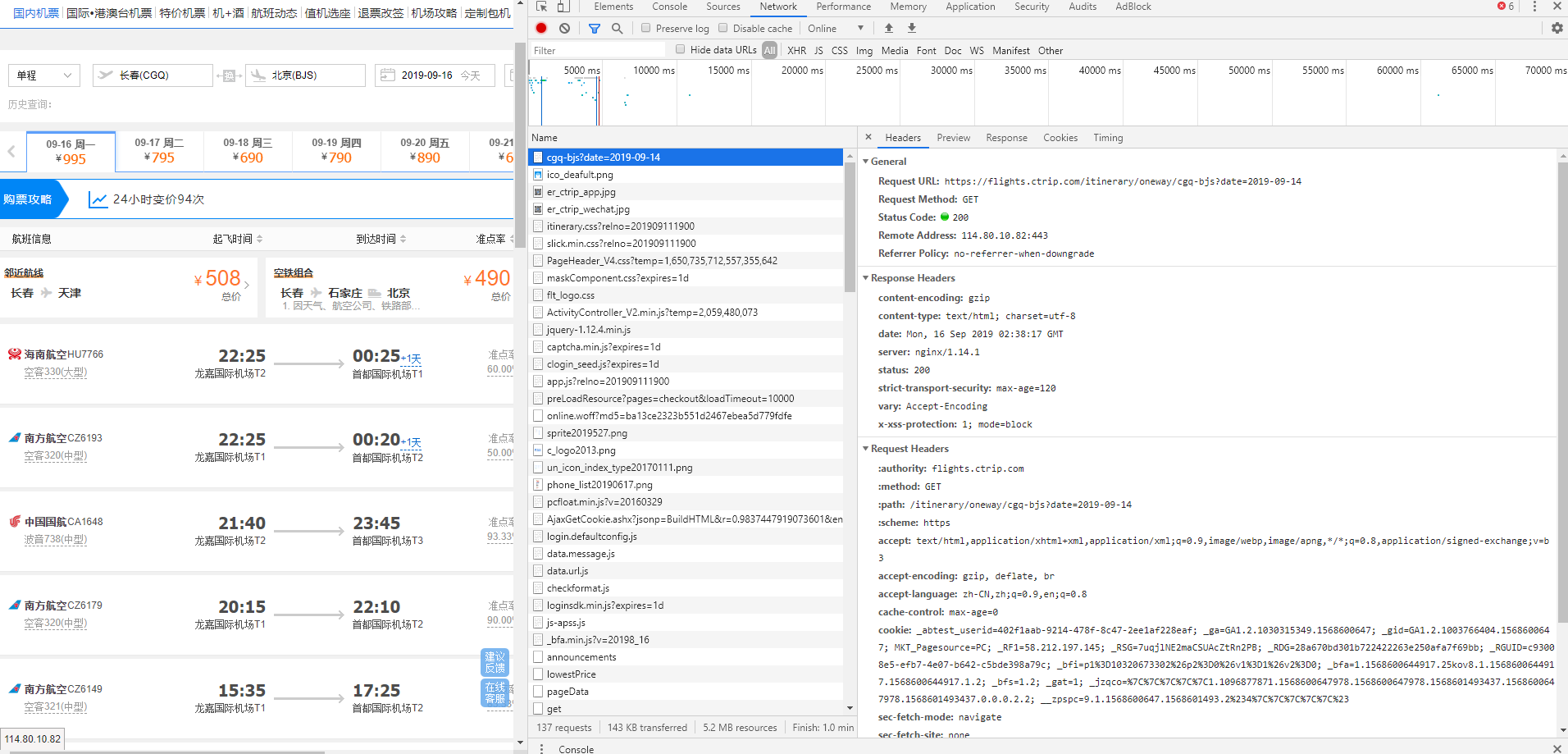
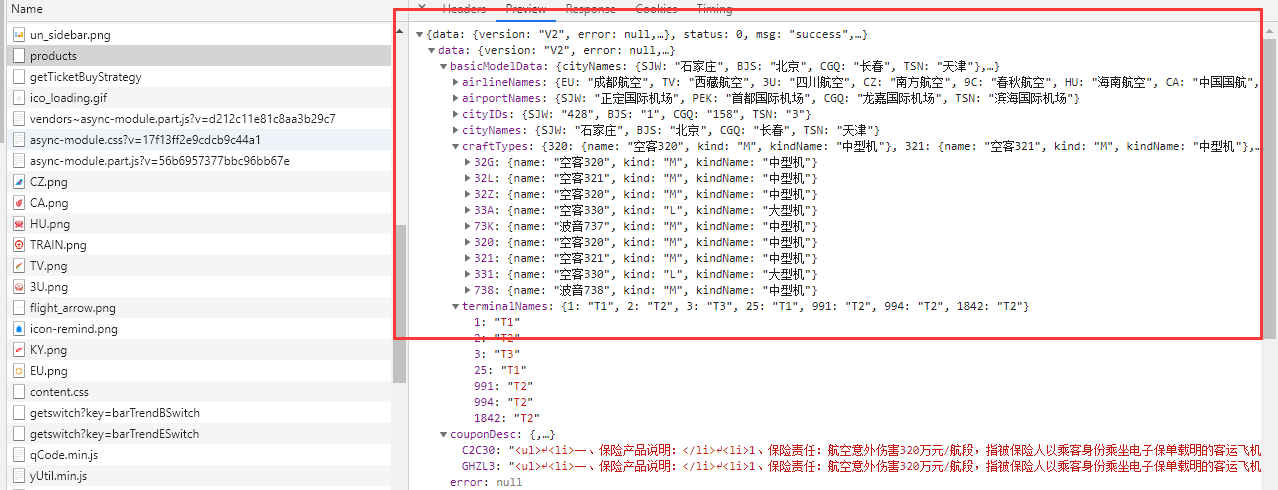
在这里面我们可以找到请求航班信息的其实是https://flights.ctrip.com/itinerary/api/12808/products这个URL。
为什么有些网站我爬下来的内容和我真实看到的网站内容不一样?
最后一个问题就是为什么有些网站我爬下来的内容和我真实看到的网站内容不一样?
这个的主要原因是,你的爬虫没有登录。
就像我们平常浏览网页,有些信息需要登录才能访问,爬虫也是如此。
这就涉及到了一个很重要的概念,我们的平常观看网页是基于Http请求的,而Http是一种无状态的请求。
什么是无状态? 你可以理解为它不认人,也就是说你的请求到了对方服务器那里,对方服务器是不知道你到底是谁。
既然如此,我们登录之后为什么还可以长时间继续访问这个网页呢?
这是因为Http虽然是无状态的,但是对方服务器却给我们安排了身份证,也就是cookie。
在我们第一次进入这个网页时,如果之前没有访问过,服务器就会给我们一个cookie,之后我们在这个网页上的任何请求操作,都要把cookie放进去。这样服务器就可以根据cookie来辨识我们是谁了。
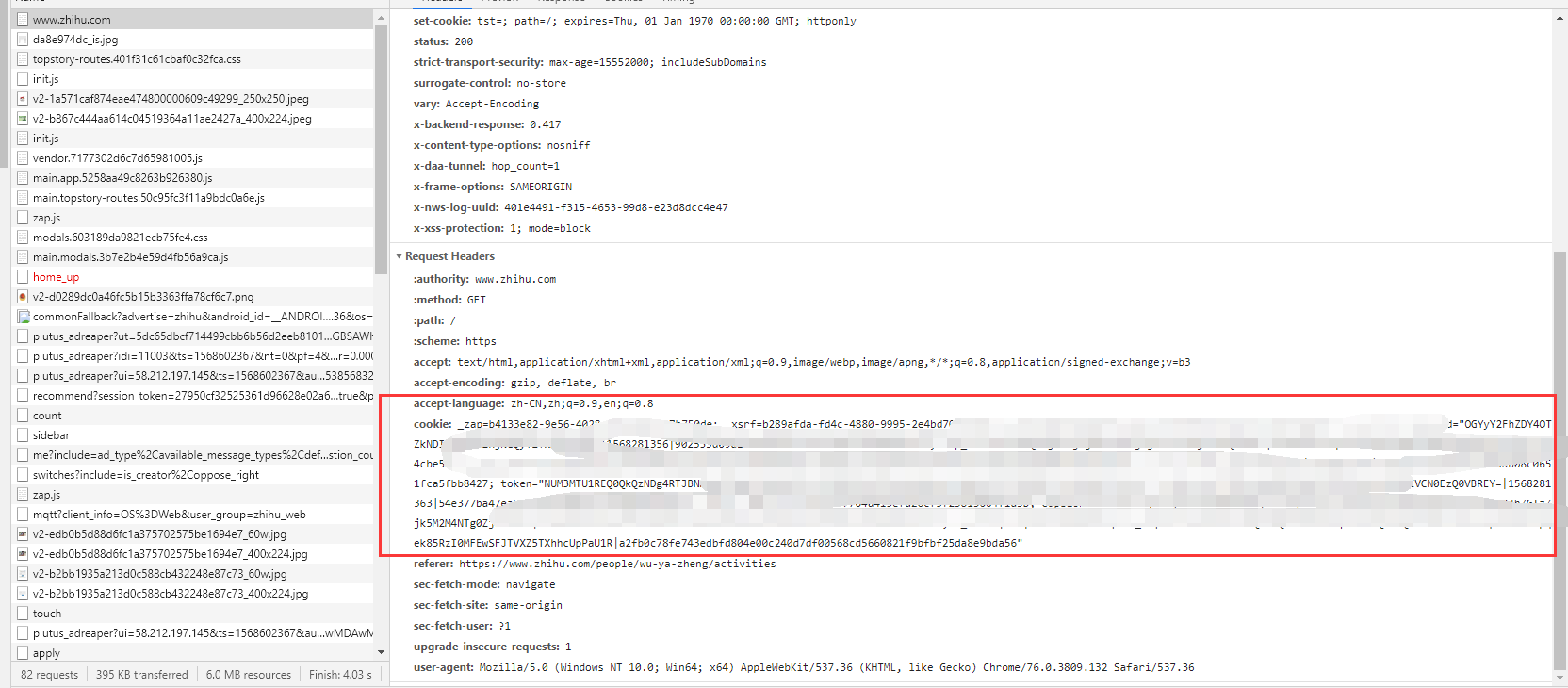
比如知乎里面就可以找到相关的cookie。
对于这类网站,我们直接从浏览器中拿到已有的cookie放进代码中使用,requests.get(url,cookies="aidnwinfawinf"),也可以让爬虫去模拟登录这个网站来拿到cookie。
Python网络爬虫实战(一)快速入门的更多相关文章
- python网络爬虫实战之快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- Python网络爬虫实战入门
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序. 爬虫的基本流程: 发起请求: 通过HTTP库向目标站点发起请求,也就是发送一个Request ...
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的.是网络爬虫和数据分析的综合应用项目.本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过S ...
- Python网络爬虫实战(三)照片定位与B站弹幕
之前两篇已经说完了如何爬取网页以及如何解析其中的数据,那么今天我们就可以开始第一次实战了. 这篇实战包含两个内容. * 利用爬虫调用Api来解析照片的拍摄位置 * 利用爬虫爬取Bilibili视频中的 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- Python网络爬虫实战(四)模拟登录
对于一个网站的首页来说,它可能需要你进行登录,比如知乎,同一个URL下,你登录与未登录当然在右上角个人信息那里是不一样的. (登录过) (未登录) 那么你在用爬虫爬取的时候获得的页面究竟是哪个呢? 肯 ...
随机推荐
- RE最全面的正则表达式----数字篇
一.校验数字的表达式 数字:^[0-9]*$n位的数字:^d{n}$至少n位的数字:^d{n,}$m-n位的数字:^d{m,n}$零和非零开头的数字:^(0|[1-9][0-9]*)$非零开头的最多带 ...
- 初识JavaScript和面向对象
1.javascript基本数据类型: number: 数值类型 string: 字符串类型 boolean: 布尔类型 null: 空类型 undefault:未定义类型 object: 基本数据类 ...
- mybatis学习的终极宝典
**********************************************************************************************一:myba ...
- Redis简单梳理及集群配置
**REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统. Redis是一个开源的使用ANSI C语言编写.遵 ...
- intellIJ IDEA学习笔记3
intellij idea 的快捷鍵 https://blog.csdn.net/wei83523408/article/details/60472168 https://www.cnblogs.co ...
- cs224d---词向量表示
1 Word meaning 1. 1 word meaning的两种定义 Definition meaning:单词的含义指代了客观存在的具体事物,如眼镜. Distributional simil ...
- Mysql优化(出自官方文档) - 第八篇(索引优化系列)
目录 Mysql优化(出自官方文档) - 第八篇(索引优化系列) Optimization and Indexes 1 Foreign Key Optimization 2 Column Indexe ...
- Redis----NoSql数据库笔记
介绍:Redis 是一个开源的使用 ANSI C 语言编写.遵守 BSD 协议.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库,并提供多种语言的 API的非关系型数据库. 传统数据 ...
- sql server 怎么查看blocked的线程
select spid ,blocked from master..sysprocesses
- SecureCRT软件的个性化设置
工欲善其事,必先利其器.如果我们能花点时间把每天工作都要用到的SecureCRT软件设置的舒服一些,日后工作起来也是会心情愉悦.事半功倍的. 1.日志文件设置 2.窗口配色和关键字高亮 3.效果展示 ...