分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗
介绍Snowflake算法
SnowFlake算法是国际大公司Twitter的采用的一种生成分布式自增id的策略,这个算法产生的分布式id是足够我们我们中小公司在日常里面的使用了。我也是比较推荐这一种算法产生的分布式id的。
算法snowflake的生成的分布式id结构组成部分
算法snowflake生成id的结果是一个64bit大小的整数,它的结构如下图,
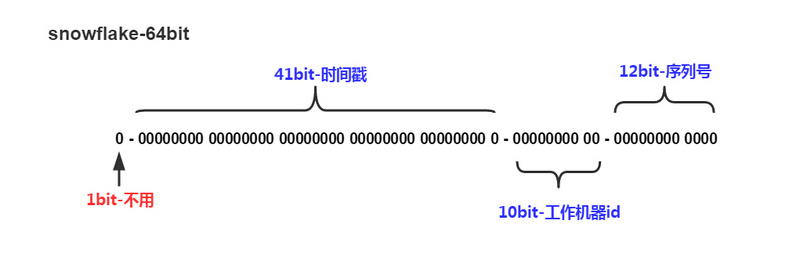
这里我么来讲一下这个结构:首先因为window是64位的,然后整数的时候第一位必须是0,所以最大的数值就是63位的111111111111111111111111111111111111111111111111111111111111111,然后呢Snowflake算法分出来41位作为毫秒值,然后10位作为redis节点的数量,然后12位做成redis节点在每一毫秒的自增序列值
41位的二进制11111111111111111111111111111111111111111转换成10进制的毫秒就是2199023255551,然后我们把 2199023255551转换成时间就是2039-09-07,也就是说可以用20年的(这里在网上会有很多说是可以使用69年的,他们说69年的也对,因为1970年+69年的结果就是2039年,但是如果从今年2019年来说,也就只能用20年了)
然后10位作为节点,所以最多就是12位的1111111111,也就是最多可以支持1023个节点,
然后10位表示每一个节点自增序列值,这里最多就是10位的111111111111,也就是说每一个节点可以每一毫秒可以最多生成4059个不重复id值
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
Java实现Snowflake算法的源码
Snowflake算法的源码如下所示(这个是我从网上找到的),这里我进行了测试了一波,结果如下所示
package com.hello;import java.text.SimpleDateFormat;import java.util.Date;public class Test {/*** 开始时间截 (1970-01-01)*/private final long twepoch = 0L;/*** 机器id所占的位数*/private final long workerIdBits = 5L;/*** 数据标识id所占的位数*/private final long datacenterIdBits = 5L;/*** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)*/private final long maxWorkerId = -1L ^ (-1L << workerIdBits);/*** 支持的最大数据标识id,结果是31*/private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);/*** 序列在id中占的位数*/private final long sequenceBits = 12L;/*** 机器ID向左移12位*/private final long workerIdShift = sequenceBits;/*** 数据标识id向左移17位(12+5)*/private final long datacenterIdShift = sequenceBits + workerIdBits;/*** 时间截向左移22位(5+5+12)*/private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;/*** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)*/private final long sequenceMask = -1L ^ (-1L << sequenceBits);/*** 工作机器ID(0~31)*/private long workerId;/*** 数据中心ID(0~31)*/private long datacenterId;/*** 毫秒内序列(0~4095)*/private long sequence = 0L;/*** 上次生成ID的时间截*/private long lastTimestamp = -1L;public Test(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}/*** 获得下一个ID (该方法是线程安全的)** @return SnowflakeId*/public synchronized long nextId() {long timestamp = timeGen();//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}//如果是同一时间生成的,则进行毫秒内序列if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;//毫秒内序列溢出if (sequence == 0) {//阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}//时间戳改变,毫秒内序列重置else {sequence = 0L;}//上次生成ID的时间截lastTimestamp = timestamp;//移位并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift) //| (datacenterId << datacenterIdShift) //| (workerId << workerIdShift) //| sequence;}/*** 阻塞到下一个毫秒,直到获得新的时间戳** @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以毫秒为单位的当前时间** @return 当前时间(毫秒)*/protected long timeGen() {return System.currentTimeMillis();}public static void parseId(long id) {long miliSecond = id >>> 22;long shardId = (id & (0xFFF << 10)) >> 10;System.err.println("分布式id-"+id+"生成的时间是:"+new SimpleDateFormat("yyyy-MM-dd").format(new Date(miliSecond)));}public static void main(String[] args) {Test idWorker = new Test(0, 0);for (int i = 0; i < 10; i++) {long id = idWorker.nextId();System.out.println(id);parseId(id);}}}
执行结果如下所示,此时我们可以看到,不仅可以可以把分布式id给创建处理,而且可以把这个创建的时间也打印出来,此时就可以满足我们的分布式id的创建了
6566884785623400448分布式id-6566884785623400448生成的时间是:2019-08-136566884785812144128分布式id-6566884785812144128生成的时间是:2019-08-136566884785812144129分布式id-6566884785812144129生成的时间是:2019-08-136566884785812144130分布式id-6566884785812144130生成的时间是:2019-08-136566884785812144131分布式id-6566884785812144131生成的时间是:2019-08-136566884785812144132分布式id-6566884785812144132生成的时间是:2019-08-136566884785816338432分布式id-6566884785816338432生成的时间是:2019-08-136566884785816338433分布式id-6566884785816338433生成的时间是:2019-08-136566884785816338434分布式id-6566884785816338434生成的时间是:2019-08-136566884785816338435分布式id-6566884785816338435生成的时间是:2019-08-13
缩小版Snowflake算法生成分布式id
因为Snowflake算法的极限是每毫秒的每一个节点生成4059个id值,也就是说每毫秒的极限是生成023*4059=4 152 357个id值,这样生成id值的速度对于twitter公司来说是很符合标准的(毕竟人家公司大嘛),但是对于咱们中小公司来说是不需要的,所以我们可以根据Snowflake算法来修改一下分布式id的创建,让每秒创建的id少一些,但是把可以使用的时间扩大一些
这里我看廖雪峰老师的文章之后,采用了53位作为分布式id值的位数,因为如果后端和前端的JavaScript打交道的话,由于JavaScript支持的最大整型就是53位,超过这个位数,JavaScript将丢失精度。因此,使用53位整数可以直接由JavaScript读取,而超过53位时,就必须转换成字符串才能保证JavaScript处理正确,所以我们的分布式id就用53位来生成
这53位里面,第一位还是0,然后剩下的52位,33位作为秒数,4位作为节点数,15位作为每一个节点在每一秒的生成序列值
33位的二进制111111111111111111111111111111111转换成10进制的秒就是8589934591,然后我们把 8589934591转换成时间就是2242-03-16,也就是说可以用220年的,足够我们的使用了
然后4位节点,所以最多就是4位的1111,也就是最多可以支持15个节点,
然后15位表示每一个节点每一秒自增序列值,这里最多就是10位的11111111111111111,也就是说每一个节点可以每一秒可以最多生成131071个不重复id值
这样算起来,就是说每一秒每一个节点生成131071个不重复的节点,所以极限就是每秒生成15*131071=1 966 065个分布式id,够我们在开发里面的日常使用了
所以代码就可以变成下面这样,这里主要讲一下下面的nextId()方法,
首先蓝色代码是获取当前秒,然后进行校验,就是把当前时间和上一个时间戳进行比较,如果当前时间比上一个时间戳要小,那就说明系统时钟回退,所以此时应该抛出异常
然后是下面的红色代码,首先如果是同一秒生成的,那么就把这一秒的生成序列id值一直增加,一直增加到131071个,如果在增加,那么下面的红色代码里面的sequence = (sequence + 1) & sequenceMask;的值就会是0,那么就会执行红色代码里面的tilNextMillis()方法进行阻塞,直到获取到下一秒继续执行
然后下面的绿色代码表示每一秒过去之后,都要把这个生成序列的id值都变成0,这样在新的一秒里面就可以在继续生成1到131071个分布式id值了
然后下面的黄色代码就是把咱们的秒,节点值,节点每秒生成序列id值加起来组成一个分布式id返回
package com.hello;import java.text.SimpleDateFormat;import java.util.Date;public class Test {/*** 开始时间截 (1970-01-01)*/private final long twepoch = 0L;/*** 机器id,范围是1到15*/private final long workerId;/*** 机器id所占的位数,占4位*/private final long workerIdBits = 4L;/*** 支持的最大机器id,结果是15*/private final long maxWorkerId = ~(-1L << workerIdBits);/*** 生成序列占的位数*/private final long sequenceBits = 15L;/*** 机器ID向左移15位*/private final long workerIdShift = sequenceBits;/*** 生成序列的掩码,这里为最大是32767 (1111111111111=32767)*/private final long sequenceMask = ~(-1L << sequenceBits);/*** 时间截向左移19位(4+15)*/private final long timestampLeftShift = 19L;/*** 秒内序列(0~32767)*/private long sequence = 0L;/*** 上次生成ID的时间截*/private long lastTimestamp = -1L;public Test(long workerId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}this.workerId = workerId;}/*** 获得下一个ID (该方法是线程安全的)** @return SnowflakeId*/public synchronized long nextId() {//蓝色代码注释开始long timestamp = timeGen();//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}//蓝色代码注释结束//红色代码注释开始//如果是同一时间生成的,则进行秒内序列if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;//秒内序列溢出if (sequence == 0) {//阻塞到下一个秒,获得新的秒值timestamp = tilNextMillis(lastTimestamp);}//时间戳改变,秒内序列重置}//红色代码注释结束//绿色代码注释开始else {sequence = 0L;}//绿色代码注释结束//上次生成ID的时间截lastTimestamp = timestamp;//黄色代码注释开始//移位并通过或运算拼到一起组成53 位的IDreturn ((timestamp - twepoch) << timestampLeftShift)| (workerId << workerIdShift)| sequence;//黄色代码注释结束}/*** 阻塞到下一个秒,直到获得新的时间戳** @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以秒为单位的当前时间** @return 当前时间(秒)*/protected long timeGen() {return System.currentTimeMillis()/1000L;}public static void parseId(long id) {long second = id >>> 19;System.err.println("分布式id-"+id+"生成的时间是:"+new SimpleDateFormat("yyyy-MM-dd").format(new Date(second*1000)));}public static void main(String[] args) {Test idWorker = new Test(0);for (int i = 0; i < 10; i++) {long id = idWorker.nextId();System.out.println(id);parseId(id);}}}
此时结果如下所示,都是ok的,؏؏☝ᖗ乛◡乛ᖘ☝؏؏
820870564020224分布式id-820870564020224生成的时间是:2019-08-13820870564020225分布式id-820870564020225生成的时间是:2019-08-13820870564020226分布式id-820870564020226生成的时间是:2019-08-13820870564020227分布式id-820870564020227生成的时间是:2019-08-13820870564020228分布式id-820870564020228生成的时间是:2019-08-13820870564020229分布式id-820870564020229生成的时间是:2019-08-13820870564020230分布式id-820870564020230生成的时间是:2019-08-13820870564020231分布式id-820870564020231生成的时间是:2019-08-13820870564020232分布式id-820870564020232生成的时间是:2019-08-13820870564020233分布式id-820870564020233生成的时间是:2019-08-13
时间回拨问题的解决
这里找了好多,终于找出来两个方法:想看的点击这个链接吧:分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗
雪法算法Snowflake适合做分布式ID吗
根据一系列的分布式id讲解,雪法算法Snowflake是目前网上最适合做分布式Id的了,大家如果想用的话,可以根据我上面的缩小版的Snowflake算法来作为我们开发中的使用。؏؏☝ᖗ乛◡乛ᖘ☝؏؏
其他分布式ID系列快捷键:
分布式ID系列(1)——为什么需要分布式ID以及分布式ID的业务需求
分布式ID系列(2)——UUID适合做分布式ID吗
分布式ID系列(3)——数据库自增ID机制适合做分布式ID吗
分布式ID系列(4)——Redis集群实现的分布式ID适合做分布式ID吗
分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗
分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗的更多相关文章
- 分布式ID系列(2)——UUID适合做分布式ID吗
UUID的生成策略: UUID的方式能生成一串唯一随机32位长度数据,它是无序的一串数据,按照开放软件基金会(OSF)制定的标准计算,UUID的生成用到了以太网卡地址.纳秒级时间.芯片ID码和许多可能 ...
- 分布式ID系列(3)——数据库自增ID机制适合做分布式ID吗
数据库自增ID机制原理介绍 在分布式里面,数据库的自增ID机制的主要原理是:数据库自增ID和mysql数据库的replace_into()函数实现的.这里的replace数据库自增ID和mysql数据 ...
- 分布式ID系列(4)——Redis集群实现的分布式ID适合做分布式ID吗
首先是项目地址: https://github.com/maqiankun/distributed-id-redis-generator 关于Redis集群生成分布式ID,这里要先了解redis使用l ...
- Twitter的分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
- Twitter分布式自增ID算法snowflake原理解析
以JAVA为例 Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个 ...
- Twitter的分布式自增ID算法snowflake(雪花算法) - C#版
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的.有些时候我们希望能使用一种简 ...
- Twitter分布式自增ID算法snowflake原理解析(Long类型)
Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个Long类型的6 ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- 分布式ID系列之为什么需要分布式ID以及生成分布式ID的业务需求
为什么需要分布式id生成系统 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识.如在美团点评的金融.支付.餐饮.酒店.猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID ...
随机推荐
- Oracle数据库----函数
--大小写控制函数--upperselect * from emp where job = upper('salesman'); --lowerselect * from emp where lowe ...
- VS2010 winform开发笔记---combox的SelectedIndexChanged事件及级联问题
DisplayMember绑定需要显示的数据表字段, 而ValueMember绑定需要获取选择的项的值. 然后通过 combo.SelectedValue就可以取得选中项的值了. DisplayMem ...
- springboot快速入门02--Controller编写和测试
02springboot快速入门--Controller编写和测试 1.新建一个HelloController import org.springframework.boot.SpringApplic ...
- Ubuntu搭建hugo博客
自己搭建了一个博客用hugo,后因自己搭建的博客上传文章,搞一些东西不方便,就创建了现在这个博客,不过还是把如何搭建hugo的过程记录以下. Ubuntu下的操作 1. 下载Git 打开终端 Ctrl ...
- STM32-I2C_CheckEvent-标志位自动清除理解
STM32里I2C_CheckEvent函数我们应该是相当熟悉了,在每次发送数据后我们都需要检验相应的EVx(x = 0,1,2,,,)事件是否有发送. 函数定义如下: ErrorStatus I2C ...
- Excel催化剂开源第6波-Clickonce部署之自动升级瘦身之术
Clickonce无痛自动更新是我最喜欢使用VSTO开发并Clickonce部署的特性之一,但这个自动更新,通常会更新整个程序文件,包含所有的引用dll和一些资源文件等. 一般来说,我们更新的都是主程 ...
- 微信小程序post 服务端无法获得参数问题
header中需要改为 "Content-Type": "application/x-www-form-urlencoded"
- [leetcode] #112 Path Sum (easy)
原题链接 题意: 给定一个值,求出从树顶到某个叶(没有子节点)有没有一条路径等于该值. 思路: DFS Runtime: 4 ms, faster than 100.00% of C++ class ...
- 微信小程序开发--页面之间的跳转
一.navigator--完成页面之间的跳转 1.新建一个页面文件夹 2.在app.json文件中引入页面 "pages": [ "pages/index/index&q ...
- sqlserver2014创建数据库时,错误提示如下:尝试打开或创建物理‘c:\数据库\db.mdf’时,Create File遇到操作系统错误5(拒绝访问)
CREATE DATABASE test1 ON PRIMARY ( NAME =test1, FILENAME='C:\Program Files\test1.mdf',SIZE=10240K ...