转载:点云上实时三维目标检测的欧拉区域方案 ----Complex-YOLO
感觉是机器翻译,好多地方不通顺,凑合看看
原文名称:Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds
原文地址:http://www.sohu.com/a/285118205_715754
代码位置:https://github.com/Mandylove1993/complex-yolo(值得复现一下)
摘要。基于激光雷达的三维目标检测是自动驾驶的必然选择,因为它直接关系到对环境的理解,从而为预测和运动规划奠定了基础。实时推断高度稀疏的3D数据的能力对于除自动化车辆外的许多其他应用领域(例如增强现实、个人机器人或工业自动化)来说是一个不适的问题。我们介绍了复杂的Yolo,一个仅在点云上的实时3D物体检测网络。在这项工作中,我们描述了一个网络,它通过一个特定的复杂回归策略来估计笛卡尔空间中的多类3d盒子,扩展了一个用于RGB图像的快速二维标准目标探测器yolov2。因此,我们提出一个特定的欧拉区域建议网络(E-RPN),通过在回归网络中添加一个虚分数和一个实分数来估计物体的姿态。这将结束于一个封闭的复杂空间,并避免奇点,这是由单角度估计发生的。E-RPN支持在培训期间很好地概括。我们在Kitti基准套件上的实验表明,在效率方面,我们优于当前领先的3D物体检测方法。我们比最快的竞争者快五倍以上,从而为汽车、行人和骑自行车的人取得了最先进的成绩。此外,我们的模型能够以高精度同时估计所有八个小型货车,包括货车、卡车或坐着的行人。
关键词:三维物体检测、点云处理、激光雷达、自主驾驶
1引言
近年来,随着汽车激光雷达传感器的不断完善,点云处理对汽车自主驾驶越来越重要。供应商的传感器能够实时提供周围环境的三维点。其优点是直接测量被包围物体的距离[1]。这使我们能够开发用于自动驾驶的目标检测算法,在3D[2][3][4][5][6][7][8][9]中准确估计不同目标的位置和方向。与图像相比,激光雷达点云稀疏,密度分布在整个测量区域。这些点是无序的,它们在本地相互作用,主要不能孤立地进行分析。点云处理应该始终对基本转换保持不变[10][11]。

通用对象的检测和分类,基于深学习是众所周知的广泛的任务和既定的在线回归2D bounding盒for Images〔12〕〔13〕〔14〕〔15〕〔16〕〔17〕〔18〕〔19〕〔20〕〔21〕。研究的主要焦点是在tradeoff between精度和效率。在自动驾驶的效率下,更多的是多的重要。therefore对象探测器,最好是使用一个区域网络(rpn)〔3〕〔22〕〔15〕或相似的基于网格的方法rpn - [ 13 ]。这些网络是非常准确和高效,甚至capable of running on a dedicated嵌入式硬件或设备。对象的点云detections仍然是在线和黑莓黑莓rarely,but important。这些应用可以预测capable need to be of 3D bounding盒。当前,there exist主要使用三不同深的学习方法:[ 3 ]
1。直接利用点云处理多层感知器层〔5〕〔10〕〔11〕〔23〕〔24〕
2。translation of点云图像像素或在堆叠模式使用卷积神经网络(CNN)〔2〕〔3〕〔4〕〔6〕〔8〕〔9〕〔25〕〔26〕
3。联合融合的方法〔2〕〔7〕
1.1相关工作
最近,基于截锥体的网络[5]在Kitti基准套件上显示出高性能。该模型被列为第二位,用于三维物体检测,如基于汽车、行人和骑自行车的鸟瞰图检测。这是唯一的方法,它直接使用点网络[10]处理点云,而不在激光雷达数据和体素创建上使用CNN。然而,它需要一个预处理,因此它也必须使用摄像机传感器。基于另一个CNN处理校准后的摄像机图像,它使用这些检测将全局点云最小化为基于截锥体的还原点云。这种方法有两个缺点:i)。模型的准确性很大程度上取决于摄像机图像及其相关的CNN。因此,仅对激光雷达数据应用该方法是不可能的;ii)。整个管道必须连续运行两个深度学习方法,最终导致更高的推理时间和更低的效率。参考模型在Nvidia GTX 1080i GPU上以约7fps的帧速率运行[1]。
相比之下,周等人[3]提出了一种仅在激光雷达数据上运行的模型。在这方面,它是kitti的最佳排名模型,用于仅使用激光雷达数据的3D和鸟类视力检测。基本思想是一种端到端的学习,它在网格单元上运行,而不使用手工制作的特性。在使用点网方法进行培训期间,将学习网格单元内部的特性[10]。最重要的是建立一个CNN来预测3D边界框。尽管精度很高,但该模型在TitanxGPU上的推断时间却很短,为4fps[3]。
Chen等人报道了另一种高排名方法。〔5〕。其基本思想是使用手工制作的特征,如点密度、最大高度和代表性点强度,将激光雷达点云投影到基于体素的RGB地图中[9]。为了获得高精度的结果,他们使用基于激光雷达鸟瞰图、基于激光雷达的前视图图和基于相机的前视图图像的多视图方法。这种融合最终导致处理时间很长,Nvidia GTX 1080i GPU上只有4fps。另一个缺点是需要辅助传感器输入(摄像头)。
1.2贡献
令我们惊讶的是,到目前为止,还没有人能够在自动驾驶方面实现实时效率。因此,我们引入了第一个超薄和准确的模型,能够在Nvidia Titanx GPU上运行速度超过50fps。我们使用多视图思想(MV3D)[5]进行点云预处理和特征提取。然而,我们忽略了多视图融合,只生成一张基于激光雷达的单鸟瞰图RGB图(见图1),以确保效率。
此外,我们还介绍了复杂的Yolo,一种Yolov2的3D版本,它是最先进的图像对象检测器之一[13]。复杂的yolo由我们的特定e-rpn支持,该e-rpn估计由每个框的虚部和实部编码的对象的方向。其思想是建立一个不带奇异点的封闭数学空间,实现精确的角度泛化。我们的模型能够实时预测精确的三维框,包括定位和对象的精确方向,即使对象基于几个点(如行人)。
因此,我们设计了特殊的锚箱。此外,它还能够通过仅使用激光雷达输入数据预测所有8个kitti类。我们在Kitti基准套件上评估了我们的模型。在准确性方面,我们在汽车、行人和骑自行车的人身上取得了相同的成绩,在效率方面,我们的表现至少超过了当前的领导者5倍。本文的主要贡献是:
1。本文采用一种新的E-RPN方法对复杂的蛋黄进行了可靠的三维盒估计角度回归。
2。我们在Kitti Benchmark套件上以比当前领先车型快五倍的速度提供实时性能和高精度评估。
3。我们估计了由e-rpn支持的每个3D盒子的精确方向,该模型可以预测周围物体的轨迹。
4。与其他基于激光雷达的方法(如[3])相比,我们的模型可以有效地在一条正向路径上同时估计所有类。
2 Complex-YOLO
本节描述了基于网格的点云预处理、特定的网络结构、用于培训的衍生损失函数以及确保实时性能的效率设计。
2.1点云预处理
由Velodyne HDL64激光扫描仪[1]采集的单帧三维点云被转换为单鸟瞰RGB图,覆盖传感器原点正前方80米x 40米的区域(见图4)。灵感来源于Chen等人。(mv3d)[5]根据高度、强度和密度对RGB地图进行编码。网格图的大小定义为n=1024,m=512。因此,我们将三维点云投影并离散成分辨率约为g=8cm的二维网格。与MV3D相比,我们略微减小了单元尺寸,以实现更小的量化误差,同时具有更高的输入分辨率。由于效率和性能的原因,我们只使用一个而不是多个高度图。因此,所有三个特征信道(ZR;ZG;ZB,带ZR;G;B 2 Rm×N)都是针对覆盖区域Ω内的点云P 2 R3进行计算的。我们将Velodyne视为PΩ的起源,并定义:
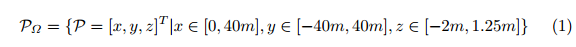

考虑到激光雷达Z位置为1.73m[1],我们选择Z 2[-2m;1:25m]覆盖地面以上约3m高的区域,预计卡车将成为最高目标。借助于校准[1],我们定义了一个映射函数sj=fps(pΩi;g),用s 2 rm×n将每个具有索引i的点映射到我们的RGB映射的特定网格单元sj中。集合描述映射到特定网格单元的所有点:
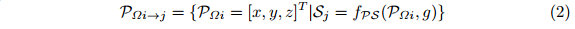
因此,我们可以计算每个像素的通道,考虑到速度强度为i(pΩ):
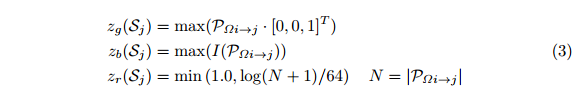
这里,n描述了从pΩi映射到sj的点数,g是网格单元大小的参数。因此,ZG编码最大高度,ZB编码最大强度,ZR编码所有映射到SJ的点的归一化密度(见图2)。
2.2结构
复杂的Yolo网络以鸟瞰RGB图(见第2.1节)作为输入。它使用一个简化的Yolov2[13]CNN架构(见表1)通过复角回归和E-RPN进行扩展,在实时运行的情况下检测出精确的面向多类的三维对象。
欧拉地区提案。我们的e-rpn解析三维位置bx;y、对象尺寸(宽度bw和长度bl)以及概率p0,类得分p1:::pn,最后从输入的特征图中分析其方向bφ。为了获得正确的方向,我们修改了常用的网格RPN方法,在其上添加了一个复杂角度arg(jzjeibφ):
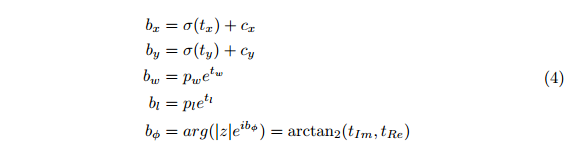
借助这一扩展,E-RPN可以根据直接嵌入网络中的虚分数和实分数来估计精确的对象方向。对于每个网格单元(32x16,请参见选项卡。1)我们预测了五个对象,包括概率分数和类分数,每个对象产生75个特征,如图2所示。

锚箱设计。 Yolov2物体探测器[13]预测每个网格单元有五个盒子。所有这些都是用有益的先验,即锚箱初始化的,以便在训练期间更好地融合。由于角度回归,自由度,即可能的先验次数增加了,但由于效率原因,我们没有扩大预测次数。
因此,我们根据Kitti数据集内的方框分布,仅预先定义了三种不同的尺寸和两个角度方向:i)车辆尺寸(朝上);i i)车辆尺寸(朝下);i i i)自行车尺寸(朝上);i v)自行车尺寸(朝下);v)行人尺寸(朝左)。
复角回归。每个物体的方向角bφ可以通过相应的回归参数tim和tre计算得出,它们对应于复数的相位,类似于[27]。角度只需使用arctan2(tim;tre)。一方面,这避免了奇异性,另一方面,这导致了一个封闭的数学空间,从而对模型的推广产生了有利的影响。
我们可以将回归参数直接链接到损失函数(7)中。

2.3损失函数
我们的网络优化损失函数L基于Yolo[12]和Yolov2[13]的概念,他们使用引入的多部分损失将Lyolo定义为平方误差之和。我们将此方法推广到欧拉回归部分Leuler,以利用复数,复数具有封闭的数学空间用于角度比较。这忽略了单角度估计中常见的奇点:
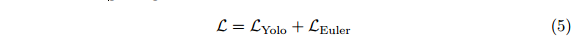
损失函数的欧拉回归部分借助欧拉区域建议进行定义(见图3)。假设预测复数与地面真值(即jz j e i bφ和jz^j e i^bφ)之间的差总是位于单位圆上,jz j=1,jz^j=1,我们将平方误差的绝对值最小化,得到实际损失:
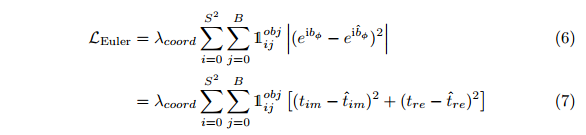
其中,λcoord是确保早期阶段稳定收敛的比例因子,1obj ij表示,与该预测的地面真值相比,单元i中的jth边界框预测器在联合(iou)上具有最高的交叉点。此外,还比较了预测框PJ和地面真值G与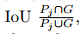 ,其中
,其中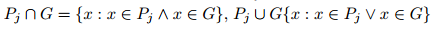 也调整处理旋转框。这是通过两个二维多边形几何图形的交集和并集理论实现的,分别由相应的框参数bx、by、bw、bl和bφ生成。
也调整处理旋转框。这是通过两个二维多边形几何图形的交集和并集理论实现的,分别由相应的框参数bx、by、bw、bl和bφ生成。
2.4效率设计
所用网络设计的主要优点是预测一个推理过程中的所有边界框。e-rpn是网络的一部分,使用最后一个卷积层的输出来预测所有边界框。因此,我们只有一个网络,可以在没有特定培训方法的情况下以端到端的方式进行培训。因此,我们的模型比其他以滑动窗口方式生成区域建议的模型运行时间更低[22],预测每个建议的偏移量和类别(例如,更快的R-CNN[15])。在图5中,我们将我们的架构与Kitti基准上的一些主要模型进行了比较。我们的方法实现了一个更高的帧速率,同时仍然保持可比的地图(平均精度)。这些帧速率是直接从各自的论文中获得的,并且都在TitanX或TitanXP上进行了测试。我们在Titan X和Nvidia TX2板上测试了我们的模型,以强调实时功能(见图5)。
3培训与实验
我们在具有挑战性的Kitti物体检测基准[1]上评估了复杂的Yolo,该基准分为三个子类别:汽车、行人和自行车的二维、三维和鸟瞰物体检测。每个类的评估基于三个难度级别:容易、中等和难考虑对象大小、距离、遮挡和截断。这一公共数据集提供了7481个训练样本,包括注释地面实况和7518个测试样本,这些样本的点云取自一台Velodyne激光扫描仪,其中注释数据是私有的。请注意,我们关注的是鸟瞰图,并没有运行二维物体检测基准,因为我们的输入仅基于激光雷达。
3.1培训详情
我们从零开始通过随机梯度下降训练我们的模型,重量衰减为0.0005,动量为0.9。我们的实现基于修改版的Darknet神经网络框架[28]。首先,我们应用了我们的预处理(见第2.1节),从Velodyne样本中生成鸟瞰RGB图。根据[2][3][29]中的原则,我们对训练集进行了细分,使其具有公共可用的地面真实性,但使用85%的比率进行训练,15%的比率进行验证,因为我们从零开始训练,旨在建立一个能够进行多类预测的模型。相比之下,例如,体素网[3]对不同类别的模型进行了修改和优化。我们遭受了可用的地面真实数据,因为它是为了摄像机检测第一。75%以上的汽车、4%以下的自行车和15%以下的行人的阶级分布是不利的。此外,超过90%的注释对象都面向汽车方向、面向录音车或具有类似方向。在顶部,图4显示了从鸟瞰图角度看的空间物体位置的二维柱状图,其中密集点表示在这个位置的更多物体。它继承了鸟类视野图的两个盲点。然而,我们看到了验证集和其他记录的未标记Kitti序列的令人惊讶的好结果,这些序列涵盖了几个用例场景,如城市、公路或市中心。

在第一个阶段,我们从一个小的学习速度开始,以确保收敛。经过一段时期后,我们提高了学习率,并继续逐渐降低,达到1000个时期。由于细粒度要求,当使用鸟瞰方法时,预测特征的微小变化将对结果框预测产生强烈影响。除了漏校正线性激活外,我们对CNN的最后一层使用了批处理规范化和线性激活f(x)=x:
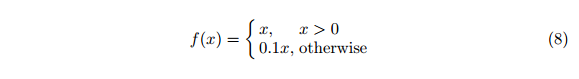
3.2kitti评价
我们已经调整了我们的实验设置,并遵循了官方的Kitti评估协议,其中IOU阈值为0.7级汽车,0.5级行人和骑自行车者。对图像平面上不可见的检测进行过滤,因为地面真值仅适用于也出现在摄像机记录图像平面[1]上的对象(见图4)。我们使用平均精度(AP)度量来比较结果。请注意,我们忽略了少数在鸟瞰图边界外的物体,这些物体的正面距离超过40米,以保持输入尺寸尽可能小,以提高效率。

鸟瞰图。我们对鸟瞰图检测的评估结果显示在表中。2。此基准使用边界框重叠进行比较。为了更好地概述和对结果进行排序,也列出了类似的当前主要方法,但在正式的Kitti测试集上执行。在运行时间和效率方面,复杂的Yolo始终优于所有竞争对手,但仍能达到相当的准确性。在TitanxGPU上运行大约0.02s,考虑到它们使用了更强大的GPU(Titanxp),我们比Avod[7]快5倍。与仅基于激光雷达的体素网[3]相比,我们的速度要快10倍多,而最慢的竞争对手MV3D[2]的速度要长18倍。

三维物体检测。Tab。3显示了我们对三维边界框重叠的实现结果。由于我们没有直接用回归估计高度信息,因此我们使用从地面实况中提取的固定空间高度位置来运行该基准,类似于MV3D[2]。此外,如前所述,我们只需根据每个对象的类为其注入一个预定义的高度,该高度是根据每个类的所有地面真值对象的平均值计算得出的。这降低了所有类的精度,但它证实了在鸟瞰基准上测量的良好结果。

4结论
本文提出了第一个基于激光雷达点云的三维目标检测实时高效深度学习模型。我们在Kitti Benchmark套件上以精确度(见图5)突出显示了我们的最新成果,其卓越的效率超过50 fps(Nvidia Titan X)。我们不需要额外的传感器,例如摄像头,就像大多数主要的方法一样。这一突破是通过引入新的E-RPN实现的,E-RPN是一种借助复数估计方向的欧拉回归方法。没有奇点的封闭数学空间允许稳健的角度预测。
我们的方法能够在一条前方道路上同时检测多个等级的物体(例如汽车、货车、行人、骑自行车的人、卡车、有轨电车、坐着的行人、其他)。这一新颖性使部署真正用于自驾汽车,并明显区别于其他车型。我们甚至在专用嵌入式平台Nvidia TX2(4 fps)上显示了实时功能。在未来的工作中,计划将高度信息添加到回归中,从而在空间中实现真正独立的三维对象检测,并在点云预处理中使用时间-空间相关性,以更好地区分类和提高精度。

Acknowledgement
首先,我们要感谢我们的主要雇主Valeo,特别是J?org Schrepfer和Johannes Petzold,他们给了我们做基础研究的可能性。此外,我们还要感谢我们的同事马克西米利安·贾里茨对体素一代的重要贡献。最后,我们要感谢我们的学术伙伴图伊曼努,他与我们有着卓有成效的合作关系。
References
1. Geiger, A.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). CVPR ’12, Washington, DC, USA, IEEE Computer Society (2012) 3354{3361
2. Chen, X., Ma, H., Wan, J., Li, B., Xia, T.: Multi-view 3d object detection network for autonomous driving. CoRR abs/1611.07759 (2016)
3. Zhou, Y., Tuzel, O.: Voxelnet: End-to-end learning for point cloud based 3d object detection. CoRR abs/1711.06396 (2017)
4. Engelcke, M., Rao, D., Wang, D.Z., Tong, C.H., Posner, I.: Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. CoRR abs/1609.06666 (2016)
5. Qi, C.R., Liu, W., Wu, C., Su, H., Guibas, L.J.: Frustum pointnets for 3d object detection from RGB-D data. CoRR abs/1711.08488 (2017)
6. Wang, D.Z., Posner, I.: Voting for voting in online point cloud object detection. In: Proceedings of Robotics: Science and Systems, Rome, Italy (July 2015)
7. Ku, J., Mozifian, M., Lee, J., Harakeh, A., Waslander, S.: Joint 3d proposal generation and object detection from view aggregation. arXiv preprint arXiv:1712.02294 (2017)
8. Li, B., Zhang, T., Xia, T.: Vehicle detection from 3d lidar using fully convolutional network. CoRR abs/1608.07916 (2016)
9. Li, B.: 3d fully convolutional network for vehicle detection in point cloud. CoRR abs/1611.08069 (2016)
10. Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. CoRR abs/1612.00593 (2016)
11. Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. CoRR abs/1706.02413 (2017)
12. Redmon, J., Divvala, S.K., Girshick, R.B., Farhadi, A.: You only look once: Unified, real-time object detection. CoRR abs/1506.02640 (2015)
13. Redmon, J., Farhadi, A.: YOLO9000: better, faster, stronger. CoRR abs/1612.08242 (2016)
14. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.E., Fu, C., Berg, A.C.: SSD: single shot multibox detector. CoRR abs/1512.02325 (2015)
15. Ren, S., He, K., Girshick, R.B., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. CoRR abs/1506.01497 (2015)
16. Cai, Z., Fan, Q., Feris, R.S., Vasconcelos, N.: A unified multi-scale deep convolutional neural network for fast object detection. CoRR abs/1607.07155 (2016)
17. Ren, J.S.J., Chen, X., Liu, J., Sun, W., Pang, J., Yan, Q., Tai, Y., Xu, L.: Accurate single stage detector using recurrent rolling convolution. CoRR abs/1704.05776 (2017)
18. Chen, X., Kundu, K., Zhang, Z., Ma, H., Fidler, S., Urtasun, R.: Monocular 3d object detection for autonomous driving. In: IEEE CVPR. (2016)
19. Girshick, R.B., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR abs/1311.2524 (2013)
20. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. CoRR abs/1512.03385 (2015)
21. Chen, X., Kundu, K., Zhu, Y., Ma, H., Fidler, S., Urtasun, R.: 3d object proposals using stereo imagery for accurate object class detection. CoRR abs/1608.07711 (2016)
22. Girshick, R.B.: Fast R-CNN. CoRR abs/1504.08083 (2015)
23. Li, Y., Bu, R., Sun, M., Chen, B.: Pointcnn (2018)
24. Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M., Solomon, J.M.: Dynamic graph cnn for learning on point clouds (2018)
25. Xiang, Y., Choi, W., Lin, Y., Savarese, S.: Data-driven 3d voxel patterns for object category recognition. In: Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition. (2015)
26. Wu, Z., Song, S., Khosla, A., Tang, X., Xiao, J.: 3d shapenets for 2.5d object recognition and next-best-view prediction. CoRR abs/1406.5670 (2014)
27. Beyer, L., Hermans, A., Leibe, B.: Biternion nets: Continuous head pose regression from discrete training labels. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)
9358 (2015) 157{168
28. Redmon, J.: Darknet: Open source neural networks in c. http://pjreddie.com/ darknet/ (2013{2016)
29. Chen, X., Kundu, K., Zhu, Y., Berneshawi, A., Ma, H., Fidler, S., Urtasun, R.: 3d object proposals for accurate object class detection. In: NIPS. (2015)
转自https://blog.csdn.net/weixin_36662031/article/details/86237800
转载:点云上实时三维目标检测的欧拉区域方案 ----Complex-YOLO的更多相关文章
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
- CVPR2020:利用图像投票增强点云中的三维目标检测(ImVoteNet)
CVPR2020:利用图像投票增强点云中的三维目标检测(ImVoteNet) ImVoteNet: Boosting 3D Object Detection in Point Clouds With ...
- ICCV2019论文点评:3D Object Detect疏密度点云三维目标检测
ICCV2019论文点评:3D Object Detect疏密度点云三维目标检测 STD: Sparse-to-Dense 3D Object Detector for Point Cloud 论文链 ...
- [OpenCV]基于特征匹配的实时平面目标检测算法
一直想基于传统图像匹配方式做一个融合Demo,也算是对上个阶段学习的一个总结. 由此,便采购了一个摄像头,在此基础上做了实时检测平面目标的特征匹配算法. 代码如下: # coding: utf-8 ' ...
- CVPR2020:点云弱监督三维语义分割的多路径区域挖掘
CVPR2020:点云弱监督三维语义分割的多路径区域挖掘 Multi-Path Region Mining for Weakly Supervised 3D Semantic Segmentation ...
- 三维目标检测论文阅读:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
题目:Deep Continuous Fusion for Multi-Sensor 3D Object Detection 来自:Uber: Ming Liang Note: 没有代码,主要看思想吧 ...
- You Only Look Once Unified, Real-Time Object Detection(你只需要看一次统一的,实时的目标检测)
我们提出了一种新的目标检测方法YOLO.先前的目标检测工作重新利用分类器来执行检测.相反,我们将目标检测作为一个回归问题来处理空间分离的边界框和相关的类概率.单个神经网络在一次评估中直接从完整图像预测 ...
- [DeeplearningAI笔记]卷积神经网络3.1-3.5目标定位/特征点检测/目标检测/滑动窗口的卷积神经网络实现/YOLO算法
4.3目标检测 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.1目标定位 对象定位localization和目标检测detection 判断图像中的对象是不是汽车--Image clas ...
- 目标检测应用化之web页面(YOLO、SSD等)
在caffe源码目录下的examples下面有个web_demo演示代码,其使用python搭建了Flask web服务器进行ImageNet图像分类的演示. 首先安装python的依赖库:pip i ...
随机推荐
- 西北师大-2108Java】第十三次作业成绩汇总
[西北师大-2108Java]第十三次作业成绩汇总 作业题目 面向对象程序设计(JAVA) 第15周学习指导及要求 实验目的与要求 (1)掌握菜单组件用途及常用API: (2)掌握对话框组件用途及常用 ...
- MyBatis中@MapKey使用详解
MyBatis中@MapKey使用详解我们在上一篇文章中讲到在Select返回类型中是返回Map时,是对方法中是否存在注解@MapKey,这个注解我也是第一次看到,当时我也以为是纯粹的返回单个数据对象 ...
- Tyvj 1953 Normal:多项式,点分治
Decription: 某天WJMZBMR学习了一个神奇的算法:树的点分治! 这个算法的核心是这样的: 消耗时间=0 Solve(树 a) 消耗时间 += a 的 大小 如果 a 中 只有 1 个点, ...
- SpringBoot运行异常时捕获
一.目录展示 二.FirstController 三.ExceptionHandler 捕获异常类 四.效果展示
- kubernetes haproxy+keepalive实现master集群高可用
前言 master的HA,实际是apiserver的HA.Master的其他组件controller-manager.scheduler都是可以通过etcd做选举(--leader-elect),而A ...
- Java中间消息件——ActiveMQ入门级运用
先来说一说我们为什么要用这个东西啊! 比如,我们现在有这样了个问题要解决: 这样,我们就要用到中间消息间了 然后我们就说一下什么是中间消息间吧. 采用消息传送机制/消息队列 的中间件技术,进行数据交流 ...
- 【HTML】---常用标签(1)
Html常用标签(1) 重新整理学习下前端知识从Html标签开始.我们先看HTML 骨架格式: <!DOCTYPE html> <!--这句话就是告诉我们使用哪个html版本--&g ...
- 周会材料:高并发程序设计<一>
第一章 几个概念 同步:一次方法调用须等到其返回后才能有后续 异步:一次方法调用后在另一线程执行,调用者可不必等其返回就可进行后续 并发:任务以极短的时间交替进行 并行:任务同时进行 临界区:公共资源 ...
- Eclipse:批量将Java源代码文件的编码从GBK转为UTF-8
很简单的几行代码,就可以批量将GBK格式的java文件转为UTF-8格式. 基本上所有文本文件的编码转换都可以采用这种方式. import java.io.File; import java.io.I ...
- 漫谈golang设计模式 简易工厂模式
目前学习golang的主要需求是为了看懂TiDB的源码,下面我们复习一下简易工厂模式的思想 工厂类型分为三种,创建型模式,结构型模式,行为型模式. 简单工厂 使用场景:考虑一个简单的API设计,一个模 ...