12-UA池和代理池
一、UA池和代理池
1、UA池
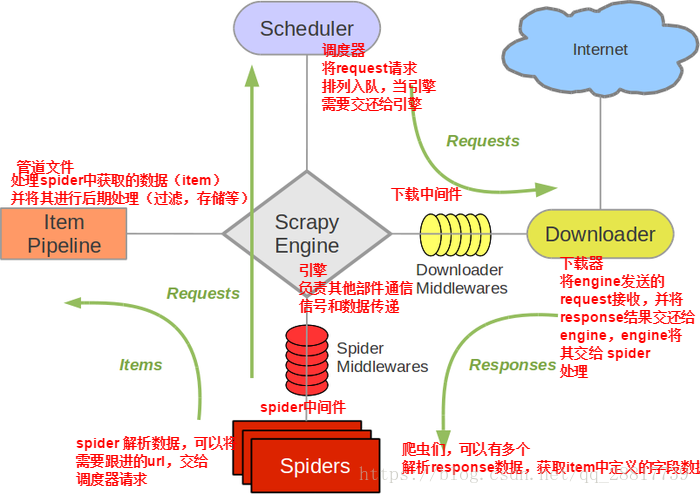
scrapy的下载中间件:
下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件。
作用:
(1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系列处理。比如设置请求的 User-Agent,设置代理等
(2)在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理。比如进行gzip解压等。
我们主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent ,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
UA池作用:尽可能多的将scrapy框架中的请求伪装成不同类型的浏览器以及不同电脑的身份。
- 操作流程:
1.下载中间件中拦截请求
2.将拦截到的请求的请求头信息中的UA进行伪装
3.在配置文件中开启下载中间件
代码展示:(只需要看proccess_request方法)
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from scrapy.http import HtmlResponse
import random
from time import sleep class WangyixinwenDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 代理池
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
] def process_request(self, request, spider):
"""
在这里可以设置UA,如果要设置IP就需要等自己IP出现问题再前去process_exception中设置代理IP
但最后一定要返回request对象
:param request:
:param spider:
:return:
"""
# ua = random.choice(self.user_agent_list)#随机选择一个元素(反爬策略(即不同浏览器和机型))出来
# request.headers["User-Agent"] = ua
#return request#将修正的request对象重新进行发送
return None def process_response(self, request, response, spider):
#刚才响应体缺失,因此从这里我们应该重新返回新的响应体
#这里要用到爬虫程序中的urls,判断url是否在里面,在urls里面的就会出现响应缺失,
# 、因此需要返回新的响应体
if request.url in spider.urls:
#响应缺失是因为是动态加载数据,因此我们配合selenium使用
#在这里实例化selenium的话会被实例化多次,然而selenium只需要实例化一次,
#这个时候我们可以将selenium放在实例化一次的爬虫程序开始的时候,实例化完成引入
sleep(2)
bro = spider.bro.get(url=request.url)#浏览器中发送请求
sleep(1)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(1.5)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(0.7)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(1)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
#发送到请求我们需要获取浏览器当前页面的源码数据 获取数据之前需要翻滚页面
page_text = spider.bro.page_source
#改动返回响应对象 scrapy提供了一个库url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request
new_response = HtmlResponse(url=request.url,body=page_text,encoding="utf-8",request=request)
return new_response
else:
return response
#提交完新的响应体之后,去设置将下载中间件打开 def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
#如果抛出异常,那么就换代理IP
# 代理ip的设定
# if request.url.split(':')[0] == 'http':
# request.meta['proxy'] = random.choice(self.PROXY_http)
# else:
# request.meta['proxy'] = random.choice(self.PROXY_https)
# # 将修正后的请求对象重新进行请求发送
# return request
pass
然后去配置文件开启中间件settings.py:
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'Wangyixinwen.middlewares.WangyixinwenDownloaderMiddleware': 543,
}
2、代理池
作用:尽可能多的将scrapy框架中的请求的IP设置成不同的,当服务器禁止自己电脑的ip的时候将自动调用process_exception中的ip代理设置
操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的IP修改成某一代理IP
3.在配置文件中开启下载中间件
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
#如果抛出异常,那么就换代理IP
# 代理ip的设定
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
# 将修正后的请求对象重新进行请求发送
return request
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'Wangyixinwen.middlewares.WangyixinwenDownloaderMiddleware': 543,
}
拦截请求直接在上面中间件代码的process_exception中,配置文件也在上面。
12-UA池和代理池的更多相关文章
- 10 UA池和代理池
在Scrapy中,引擎和下载器之间有一个组件,叫下载中间件(Downloader Middlewares).因它是介于Scrapy的request/response处理的钩子,所以有2方面作用: (1 ...
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
- 爬虫的UA池和代理池
爬虫的UA池和代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下 ...
- 14.UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - ...
- UA池和代理池
scrapy下载中间件 UA池 代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎 ...
- UA池和代理池在scrapy中的应用
一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系 ...
- 爬虫开发13.UA池和代理池在scrapy中的应用
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: ( ...
- 14,UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 一,下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器 ...
- scrapy的UA池和代理池
一.下载中间件(Downloader Middlewares) 框架图如下 下载中间件(Downloader Middlewares)位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引 ...
随机推荐
- Linux系统学习 十六、VSFTP服务—本地用户访问—基本用户基础配置
缺点,ftp密码是和系统密码是一致的,并不安全 先设置两个测试用户 test1 123123 test2 123123 基本用户基础配置 1.本地用户基本配置 local_enab ...
- 清除Windows系统图标缓存
如果改变程序图标重新编译之后看到的图标并未改变,这可能不windows缓存了之前的图标导致的,需要清除Window的图标缓存来显示正确的图标. 下面是清除Windows系统图标缓存的批处理代码: re ...
- 05-Node.js学习笔记-第三方模块
5.1什么是第三方模块 别人写好的,具有特定功能的,我们能直接使用的模块即第三方模块,由于第三方模块通常都是由多个文件组成并且被放置在一个文件夹中,所以又名包. 第三方模块有两种存在形式 以js文件的 ...
- 计算机网络知识之TCP/IP协议簇
OSI参考模型 OSI的来源 OSI(Open System Interconnect),即开放式系统互联. 一般都叫OSI参考模型,是ISO(国际标准化组织)组织在1985年研究的网 ...
- OpenCV-3.4.3图像通道处理
图像通道处理 图像读取和处理都是按BGR通道顺序进行的 #include <iostream> #include <opencv2/opencv.hpp> #include & ...
- (三十八)c#Winform自定义控件-圆形进度条-HZHControls
官网 http://www.hzhcontrols.com 前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kww ...
- Mybatis1
一.MyBatis介绍 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis ...
- Eclipse中Junit测试中@Before不执行
场景 在使用Junit进行单元测试时,一部分获取JPA的entityManager的代码将其放在了 @Before标注的方法中,这样每次执行@TEST标注的方法时会首先执行@Before标注的方法. ...
- Java面试基础 -- Docker篇
1.什么是Docker? Docker是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保您的应用程序在任何环境中无缝运行. 2.什么是Docker镜像? Docker镜像是 ...
- ie11 SCRIPT5011:不能执行已释放Script的代码
依照我遇到的问题为例: (我的页面结构为:父页面中嵌套有iframe子页面) 1.造成这种情况的原因是:父页面初始化声明变量a为数组(数组对象是引用类型,赋值传递的是地址),创建iframe子页面后给 ...