Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一、MapReduce概述
Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集。
MapReduce作业通过将输入的数据集拆分为独立的块,这些块由map以并行的方式处理,框架对map的输出进行排序,然后输入到reduce中。MapReduce框架专门用于<key,value>键值对处理,它将作业的输入视为一组<key,value>对,并生成一组<key,value>对作为输出。输出和输出的key和value都必须实现Writable 接口。
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
二、MapReduce编程模型简述
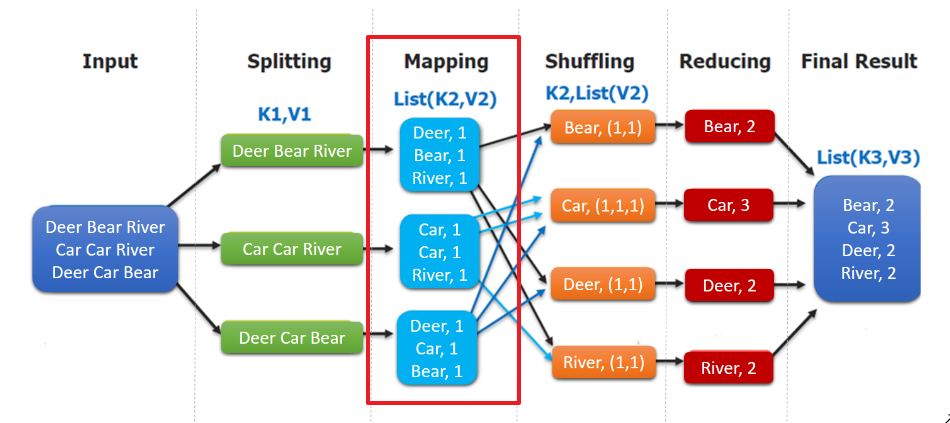
这里以词频统计为例进行说明,MapReduce处理的流程如下:
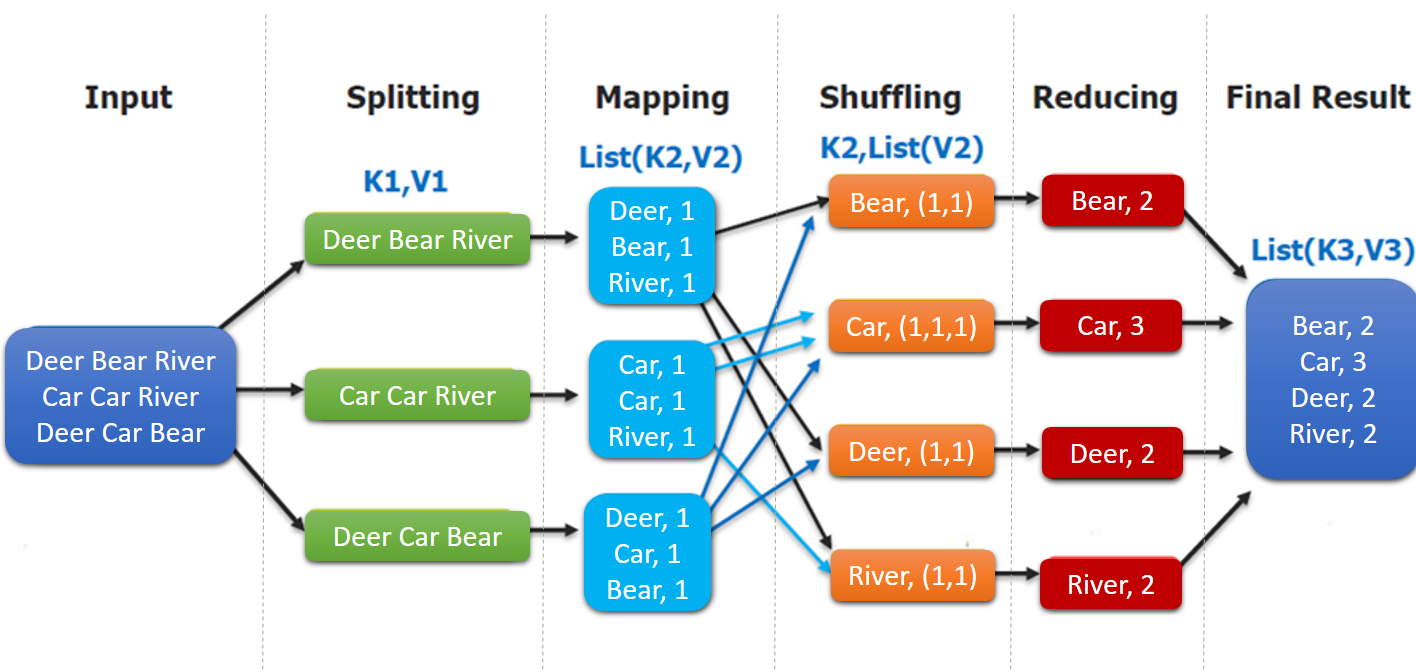
- input : 读取文本文件;
- splitting : 将文件按照行进行拆分,此时得到的
K1行数,V1表示对应行的文本内容; - mapping : 并行将每一行按照空格进行拆分,拆分得到的
List(K2,V2),其中K2代表每一个单词,由于是做词频统计,所以V2的值为1,代表出现1次; - shuffling:由于
Mapping操作可能是在不同的机器上并行处理的,所以需要通过shuffling将相同key值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到K2为每一个单词,List(V2)为可迭代集合,V2就是Mapping中的V2; - Reducing : 这里的案例是统计单词出现的总次数,所以
Reducing对List(V2)进行归约求和操作,最终输出。
MapReduce编程模型中splitting 和shuffing操作都是由框架实现的,需要我们自己编程实现的只有mapping和reducing,这也就是MapReduce这个称呼的来源。
三、combiner & partitioner
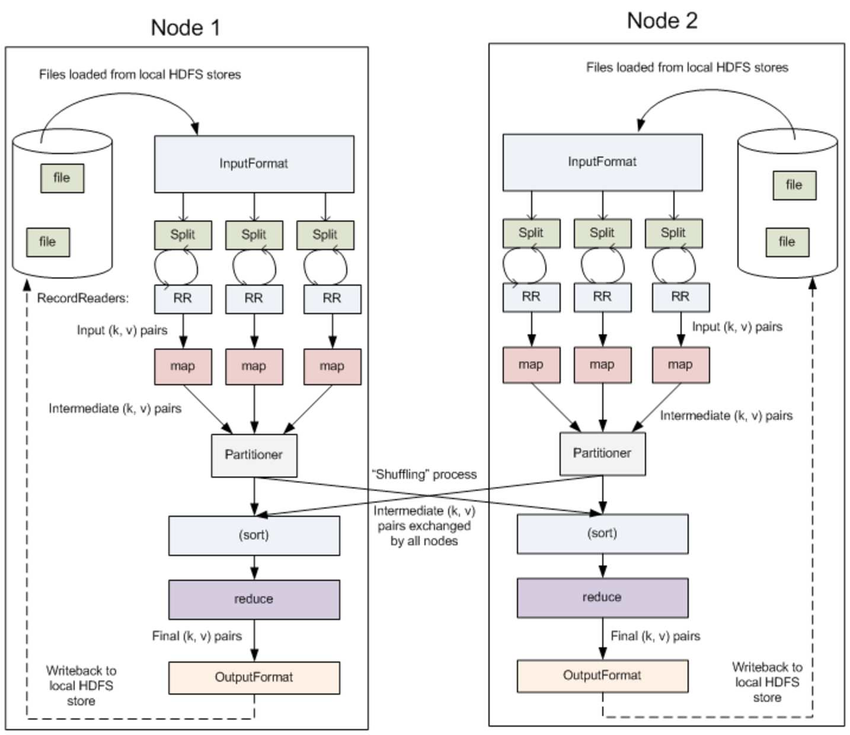
3.1 InputFormat & RecordReaders
InputFormat将输出文件拆分为多个InputSplit,并由RecordReaders将InputSplit转换为标准的<key,value>键值对,作为map的输出。这一步的意义在于只有先进行逻辑拆分并转为标准的键值对格式后,才能为多个map提供输入,以便进行并行处理。
3.2 Combiner
combiner是map运算后的可选操作,它实际上是一个本地化的reduce操作,它主要是在map计算出中间文件后做一个简单的合并重复key值的操作。这里以词频统计为例:
map在遇到一个hadoop的单词时就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么需要传输的数据量就会减少,传输效率就可以得到提升。
但并非所有场景都适合使用combiner,使用它的原则是combiner的输出不会影响到reduce计算的最终输入,例如:求总数,最大值,最小值时都可以使用combiner,但是做平均值计算则不能使用combiner。
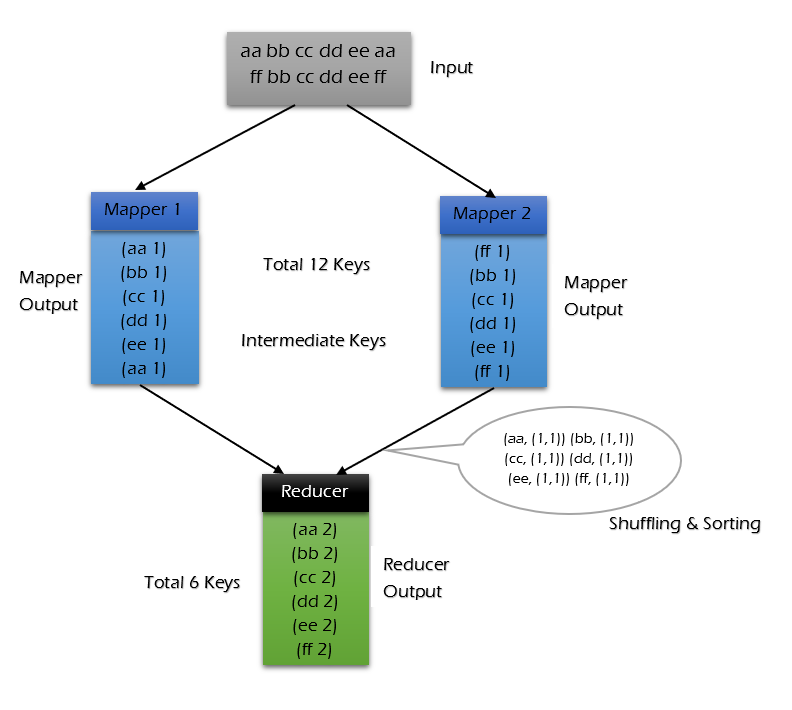
不使用combiner的情况:
使用combiner的情况:
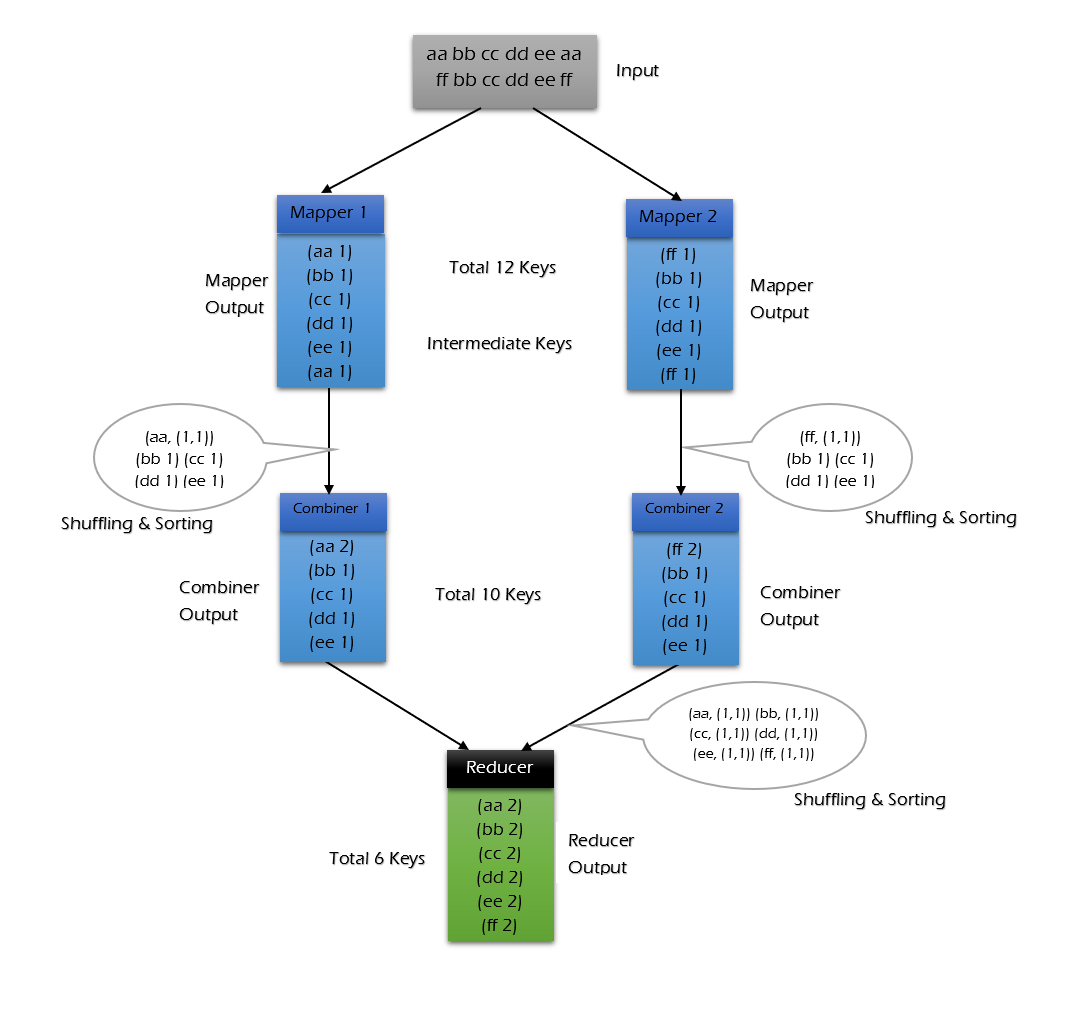
可以看到使用combiner的时候,需要传输到reducer中的数据由12keys,降低到10keys。降低的幅度取决于你keys的重复率,下文词频统计案例会演示用combiner降低数百倍的传输量。
3.3 Partitioner
partitioner可以理解成分类器,将map的输出按照key值的不同分别分给对应的reducer,支持自定义实现,下文案例会给出演示。
四、MapReduce词频统计案例
4.1 项目简介
这里给出一个经典的词频统计的案例:统计如下样本数据中每个单词出现的次数。
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
为方便大家开发,我在项目源码中放置了一个工具类WordCountDataUtils,用于模拟产生词频统计的样本,生成的文件支持输出到本地或者直接写到HDFS上。
项目完整源码下载地址:hadoop-word-count
4.2 项目依赖
想要进行MapReduce编程,需要导入hadoop-client依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
4.3 WordCountMapper
将每行数据按照指定分隔符进行拆分。这里需要注意在MapReduce中必须使用Hadoop定义的类型,因为Hadoop预定义的类型都是可序列化,可比较的,所有类型均实现了WritableComparable接口。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
WordCountMapper对应下图的Mapping操作:
WordCountMapper继承自Mappe类,这是一个泛型类,定义如下:
WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
......
}
- KEYIN :
mapping输入key的类型,即每行的偏移量(每行第一个字符在整个文本中的位置),Long类型,对应Hadoop中的LongWritable类型; - VALUEIN :
mapping输入value的类型,即每行数据;String类型,对应Hadoop中Text类型; - KEYOUT :
mapping输出的key的类型,即每个单词;String类型,对应Hadoop中Text类型; - VALUEOUT:
mapping输出value的类型,即每个单词出现的次数;这里用int类型,对应IntWritable类型。
4.4 WordCountReducer
在Reduce中进行单词出现次数的统计:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
如下图,shuffling的输出是reduce的输入。这里的key是每个单词,values是一个可迭代的数据类型,类似(1,1,1,...)。
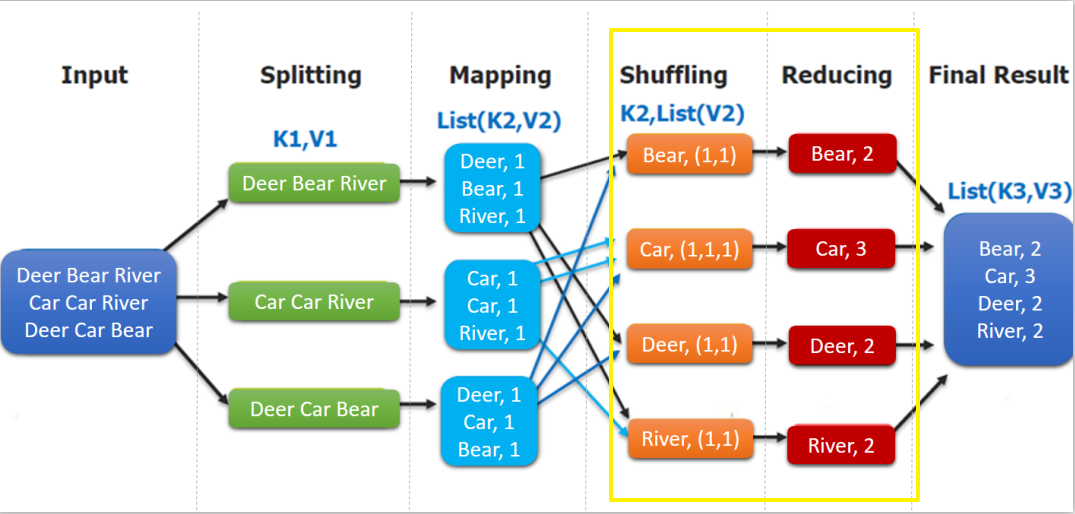
4.4 WordCountApp
组装MapReduce作业,并提交到服务器运行,代码如下:
/**
* 组装作业 并提交到集群运行
*/
public class WordCountApp {
// 这里为了直观显示参数 使用了硬编码,实际开发中可以通过外部传参
private static final String HDFS_URL = "hdfs://192.168.0.107:8020";
private static final String HADOOP_USER_NAME = "root";
public static void main(String[] args) throws Exception {
// 文件输入路径和输出路径由外部传参指定
if (args.length < 2) {
System.out.println("Input and output paths are necessary!");
return;
}
// 需要指明hadoop用户名,否则在HDFS上创建目录时可能会抛出权限不足的异常
System.setProperty("HADOOP_USER_NAME", HADOOP_USER_NAME);
Configuration configuration = new Configuration();
// 指明HDFS的地址
configuration.set("fs.defaultFS", HDFS_URL);
// 创建一个Job
Job job = Job.getInstance(configuration);
// 设置运行的主类
job.setJarByClass(WordCountApp.class);
// 设置Mapper和Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 如果输出目录已经存在,则必须先删除,否则重复运行程序时会抛出异常
FileSystem fileSystem = FileSystem.get(new URI(HDFS_URL), configuration, HADOOP_USER_NAME);
Path outputPath = new Path(args[1]);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
// 设置作业输入文件和输出文件的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outputPath);
// 将作业提交到群集并等待它完成,参数设置为true代表打印显示对应的进度
boolean result = job.waitForCompletion(true);
// 关闭之前创建的fileSystem
fileSystem.close();
// 根据作业结果,终止当前运行的Java虚拟机,退出程序
System.exit(result ? 0 : -1);
}
}
需要注意的是:如果不设置Mapper操作的输出类型,则程序默认它和Reducer操作输出的类型相同。
4.5 提交到服务器运行
在实际开发中,可以在本机配置hadoop开发环境,直接在IDE中启动进行测试。这里主要介绍一下打包提交到服务器运行。由于本项目没有使用除Hadoop外的第三方依赖,直接打包即可:
# mvn clean package
使用以下命令提交作业:
hadoop jar /usr/appjar/hadoop-word-count-1.0.jar \
com.heibaiying.WordCountApp \
/wordcount/input.txt /wordcount/output/WordCountApp
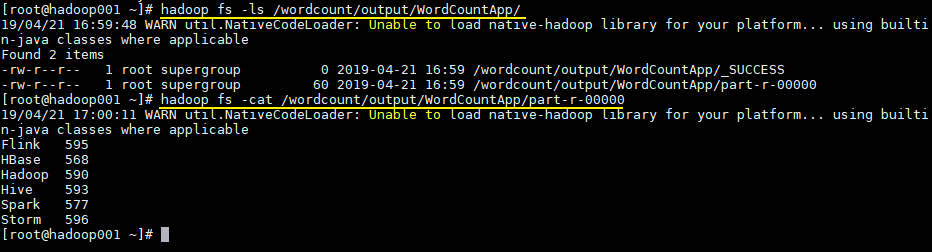
作业完成后查看HDFS上生成目录:
# 查看目录
hadoop fs -ls /wordcount/output/WordCountApp
# 查看统计结果
hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000
五、词频统计案例进阶之Combiner
5.1 代码实现
想要使用combiner功能只要在组装作业时,添加下面一行代码即可:
// 设置Combiner
job.setCombinerClass(WordCountReducer.class);
5.2 执行结果
加入combiner后统计结果是不会有变化的,但是可以从打印的日志看出combiner的效果:
没有加入combiner的打印日志:
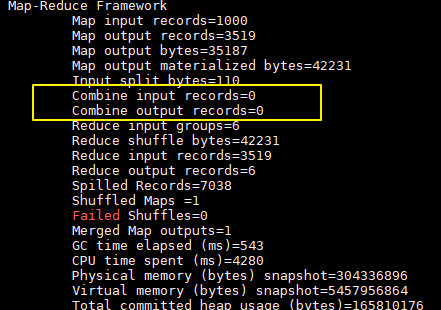
加入combiner后的打印日志如下:
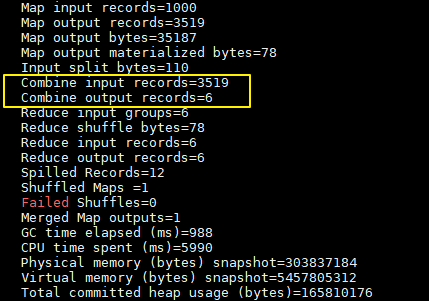
这里我们只有一个输入文件并且小于128M,所以只有一个Map进行处理。可以看到经过combiner后,records由3519降低为6(样本中单词种类就只有6种),在这个用例中combiner就能极大地降低需要传输的数据量。
六、词频统计案例进阶之Partitioner
6.1 默认的Partitioner
这里假设有个需求:将不同单词的统计结果输出到不同文件。这种需求实际上比较常见,比如统计产品的销量时,需要将结果按照产品种类进行拆分。要实现这个功能,就需要用到自定义Partitioner。
这里先介绍下MapReduce默认的分类规则:在构建job时候,如果不指定,默认的使用的是HashPartitioner:对key值进行哈希散列并对numReduceTasks取余。其实现如下:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
6.2 自定义Partitioner
这里我们继承Partitioner自定义分类规则,这里按照单词进行分类:
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
return WordCountDataUtils.WORD_LIST.indexOf(text.toString());
}
}
在构建job时候指定使用我们自己的分类规则,并设置reduce的个数:
// 设置自定义分区规则
job.setPartitionerClass(CustomPartitioner.class);
// 设置reduce个数
job.setNumReduceTasks(WordCountDataUtils.WORD_LIST.size());
6.3 执行结果
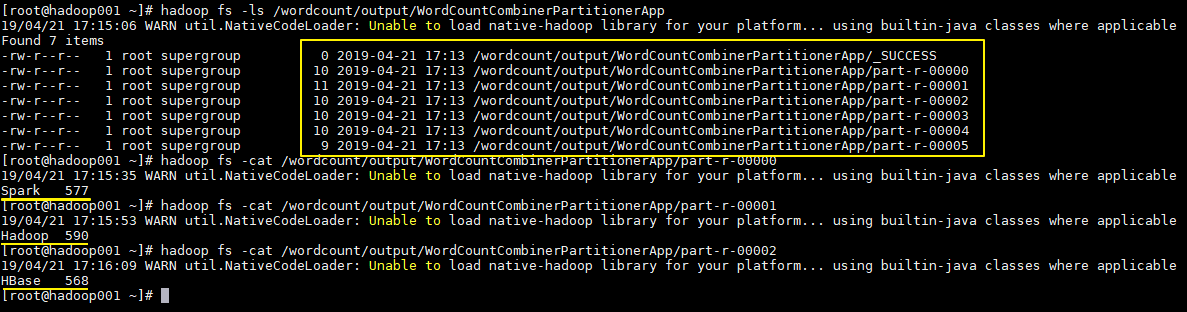
执行结果如下,分别生成6个文件,每个文件中为对应单词的统计结果:
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop 学习之路(三)—— 分布式计算框架 MapReduce的更多相关文章
- Hadoop学习之路(十三)MapReduce的初识
MapReduce是什么 首先让我们来重温一下 hadoop 的四大组件: HDFS:分布式存储系统 MapReduce:分布式计算系统 YARN:hadoop 的资源调度系统 Common:以上三大 ...
- Hadoop学习之路(十七)MapReduce框架Partitoner分区
Partitioner分区类的作用是什么? 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中:按照性别划分的话,需要 ...
- Hadoop 系列(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集. MapReduce ...
- Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一.MapReduce概述 二.MapReduce编程模型简述 三.combiner & partitioner 四.MapReduce词频统计案例 4.1 项目简介 ...
- Hadoop学习之路(二)Hadoop发展背景
Hadoop产生的背景 1. HADOOP最早起源于Nutch.Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取.索引.查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题—— ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- 学习之路三十九:新手学习 - Windows API
来到了新公司,一开始就要做个程序去获取另外一个程序里的数据,哇,挑战性很大. 经过两周的学习,终于搞定,主要还是对Windows API有了更多的了解. 文中所有的消息常量,API,结构体都整理出来了 ...
随机推荐
- ocjp(scjp) 的官网样题收录-20130723
官网上给的样题很少,带(*)的为正确答案. OBJECTIVE: 1.5: Given a code example, determine if a method is correctly overr ...
- 给WPF示例图形加上方便查看大小的格子之完善版本
原文:给WPF示例图形加上方便查看大小的格子之完善版本 去年10月份, 我曾写过一篇"给WPF示例图形加上方便查看大小的格子"的BLOG(http://blog.csdn.net/ ...
- 【狼窝乀野狼】Windows Server 2008 R 配置 Microsoft Server 2008 远程登录连接
如果你已经了解了,或者你已经经历了,那么此篇文章对你是毫无用处.因为文笔深处未必有自己亲身体验来的真实有效. 闲话少说,直接上菜. 最近脑子“抽筋”,想安装一个服务器来玩玩,那么怎么选择呢?我的PC是 ...
- 正交函数(orthogonal functions)
a map is a function. 映射即函数: 1. 双线性映射与双线性形式 bilinear map 基于同一定义域,将两个向量空间(V,W)中的向量映射为第三个向量空间(X)的向量的函数: ...
- ASP.NET Core Windows 环境配置 - ASP.NET Core 基础教程 - 简单教程,简单编程
原文:ASP.NET Core Windows 环境配置 - ASP.NET Core 基础教程 - 简单教程,简单编程 ASP.NET Core Windows 环境配置 ASP.NET Core ...
- WPF 实现水纹效果
原文:WPF 实现水纹效果 鼠标滑过产生水纹,效果图如下: XMAL就放置了一个img标签 后台主要代码 窗体加载: private void Window_Loaded(object s ...
- Tab切换效果的实现
<!--引用jquery和bootstrap--> <link rel="stylesheet" href="~/Content/bootstrap.m ...
- VisualSVN-6.0.1Patch just for VS2017补丁原创发布
VisualSVN-6.0.1Patch_justforVS2017补丁原创发布 一切尽在发布中.
- comtextMenu 如何正确的响应MouseLeave事件
今天给菜单加上这个事件,发现弹出菜单后 鼠标怎么动都不会触发 mouseLeave事件 解决方法是 在菜单loaded事件中,利用visualTreeHelper 访问他内部的border控件,把这个 ...
- C#如何将十六进制数字符串转byte[]?
代码: /// <summary> /// 16进制原码字符串转字节数组 /// </summary> /// <param name="hexString&q ...