持续集成高级篇之Jekins参数传入与常见任务
有的童鞋可能已经发现,PipeLine项目与自由式项目相比,可配置的项少了很多,比如说环境变量定义,所有步骤完成后执行动作,拉git代码库等.其实这些功能并没有缺,而是配置的方式不一样了,以前是通过图形化界面配置,虽然直观简便,但是功能不能包罗万像,对于一些复杂的项目显得捉襟见肘,而Jenkins PipeLine使用代码配置功能更加强大.以后的章节中我们会介绍常用的配置如何通过PipeLine里的Groovy脚本来实现.
前面讲参数化构建的时候已经讲到对于复杂的构建把一些重复的,常用的代码做成变量的重要性,这里讲解如何通过PipeLine方式定义项目级别的参数以及环境变量.
首先需要说明的是,节点级别和全局级别以及文件参数变量的配置在PipeLine里依然有效,读取的方式也一样,只是会有一些小坑,这里也会介绍
PipeLine中可以定义变量和环境变量,下面分别介绍如何定义变量和环境变更.
PipeLine中定义变量
PipeLine中定义变量非常简单,只需要使用def 变量名=变量值的形式即可
看如下PipeLine代码(大家自己创建项目)
node {
def hello="world"
stage("echo"){
bat "echo $hello"
}
}
以上脚本中我们先是定义了一个名为hello的变量,然后通过$变量名方式获取到它,然后把它打印到控制台.
有些童鞋对以上代码可能有点懵圈,bat执行的字符串怎么能包含
$变量名这样的内容呢,bat不是只能解析%变量名%类型的变量吗.实际上是$变量名是groovy脚本插值语法,执行到这行文本的时候groovy就会去尝试解析$变量名,对于本实例,groovy会解析$hello,上面已经定义过,它的值是world,因此 groovy会把echo $hello先解析为'echo world'这样纯字符串,然后再传给bat执行.
需要注意的是以上定义的变量并非环境变量,对于bat脚本,不能通过
%变量名%的形式被解析,因为环境变量中不存在这样一个环境变量名,因此bat无法解析它.当然对于定义的节点级别的或者全局的变量bat脚本仍然可以通过%变量名%形式被解析.大家不要迷糊.
PipeLine中定义环境变量
上面定义变量的方式是定义了一个groovy变量,我们也说过它不能被传入到脚本内部被解析(比如bat 通过%变量名%形式解析),它必须通过groovy脚本解析成普通字符串然后传给相应的脚本执行程序.实际上PipeLine中也提供了一种创建环境变量的方法.这里我们就介绍一下.
我们还是通过一段demo来讲解
node {
withEnv(['build=Production',
'DB_ENGINE=sqlite']) {
stage('Build') {
bat "echo $build"
}
}
}
以上通过WithEnv来定义环境变量,值放在中括号里,大家注意写法是"变量名=变量值",也就是变量名和赋值都放在一个引号内(单引号和双引号都可以),而不是"变量名"="变量值"这种形式,一定要注意.
bat命令里的解析方法是通过$变量名形式,我们讲过,它是groovy的插件方式,通过这里我们可以看到,在PipeLine里,环境变量也被当作了普通变量(即可以通过$变量名形式解析).当然我们说了这里定义的是环境变量,环境变量是可以传入脚本内部被解析的,我们把bat这段代码改为如下
bat "echo %build%"
控制台仍然能够输出world.
对于powershell脚本可以通过
$env:变量名方式获取.但是对于powershell脚本有一个坑必须注意,那就是Powershell获取环境变量名使用$开头,同时groovy脚本插值变量也是以$开头,这就会导致Groovy会尝试解析 powershell的变量,这样显然无法获取正确结果.如何解决这一问题呢?答案是执行powershell脚本的时候使用powershell '要执行的脚本',也即把双引号改为单引号,如果双引号改单引号,则groovy不再进行插值计算.
最佳实践
前面说过,groovy除了可以获取通过
def定义的变量外,也能够获取环境变量,因此建议使用$变量名的方式获取变量的值,这样groovy会提交对它们进行插值计算,这样就弥补了不同脚本使用环境变量方法不一样的问题.同也不必考虑powrshell 引用变量会被插值计算,必须使用单引号包括脚本的问题,减少脑细胞消耗量.通过以上我们可以看到PipeLine里即可以通过
def来定义变量,也可以通过WithEnv来定义,实际使用中发现WithEnv更麻烦,所有使用到它的代码块都必须包含在withEnv代码块内,如果嵌套过深,代码可读性非常差.而def即可以声明为全局的(这里说的全局是对整个当前脚本有效),也可以是块级的,并且不用花括号,可读性也更好.
常见任务在PipeLine中的处理
保证某一步骤最终一定执行
我们知道PipeLine里可以书写Groovy脚本,脚本如果出错则代码将不会再继续往下走,我们如何保证不论如何最终都会执行某一步动作呢,比如说释放非托管资源,脚本出错时发出邮件通知等,这里其实处理办法非常简单,那就是使用groovy的try finally语法,把最终要执行的代码写在finally里,这对程序员来说应该非常容易理解.
Script代码块
我们前面已经说过,可以在jenkins PipeLine里直接执行groovy脚本,如果仅仅是定义一个变量这样简单的动作无所谓,如果有大量的代码和业务逻辑掺杂在一块,则势必影响代码可读性.此时可以使用script代码块把要执行的大段groovy脚本包在里面
如下图示
node {
def hello="world"
stage("echo"){
script{
for(i=0;i<=3;i++){
println(i)
}
}
bat "echo $version"
}
}
以上我们把循环语句放在代码块里,println可以把内容打印到Jenkins控制台.
逻辑分支
这里仅仅是列出来希望引起大家的注意,在脚本式PipeLine里逻辑分支非常简单,只需要使用if分支语句即可,熟悉groovy脚本的童鞋可以尽情发挥所掌握知识
并行任务
在PipeLine里可以执行并行任务,充分利用并行任务在特定场景下将极大节约构建时间,提升构建效率.比如说我们的项目是一个模块非常多的项目,每个模块存在不同的仓库里,则我们在拉取项目进行编译的时候可以并行拉取这个库,把这些并行任务放在一个步骤里,完成后再执行下一步编译工作.
请看下面示例代码
node{
stage("poll source"){
parallel(
a: {
echo "This is branch a"
},
b: {
echo "This is branch b"
}
)
}
stage("build"){
echo "build successfully"
}
}
以上代码在poll source步骤里,我们通过parallel并行执行了a和b两个任务.这样将极大节约代码拉取时间.
我们保存项目后点击构建,构建完成后打开BlueOcean视图,点击进入本次构建,就会看到如下图
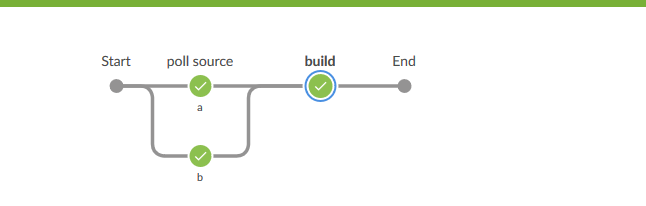
可以从图形界面形象地看到poll source步骤分为a和b两个并行的任务.然后它们汇集到下一步.
使用并行任务时一定要梳理好构建的逻辑,否则将会出现意想不到的结果.如果以上
a b 和build并行执行,则将会导致构建失败,因为构建依赖于以上两个步骤都执行完成.
持续集成高级篇之Jekins参数传入与常见任务的更多相关文章
- 持续集成高级篇之Jekins参数化构建(二)
系列目录 上一节我们讲解了如何使用bat脚本或者powershell脚本自身的机制来达到参数化构建的目的,这在一定程序上增加了灵活性,然而缺点也相当明显:它只能适应一些相对比较固定的参数传入(比如像上 ...
- 持续集成高级篇之Jekins脚本参数化构建
系列目录 本系列已经很久没有更新了,接前面基础篇,本系统主要介绍jenkins构建里的一些高级特性.包括脚本参数化,Jenkins Pipeline与及在PipeLine模式下如何执行常见的传统构建任 ...
- 持续集成高级篇之Jenkins Pipeline 集成sonarqube
系列目录 前面章节中我们讲到了Sonarqube的使用,其实Sonarqube获取msbuild结果主要是执行三个命令,开始标记,执行msbuild,结束标记,这些都是命令,是非常容易集成到我们ci流 ...
- 持续集成高级篇之基于win32-openssh搭建jenkins混合集群(一)
系列目录 前面的demo我们使用的都是只有一个windows主节点的的jenkins,实际生产环境中,一个节点往往是不能满足需求的.比如,.net项目要使用windows节点构建,java项目如果部署 ...
- 持续集成高级篇之Jenkins windows/linux混合集群搭建(二)
系列目录 前面我们说过,要使用ssh方式来配置windows从节点,如果采用ssh方式,则windows和linux配置从节点几乎没有区别,目前发现的惟一的区别在于windows从节点上目录要设置在c ...
- 持续集成高级篇之Jenkins Pipeline git拉取
系列目录 PipeLine中拉取远程git仓库 前面讲自由式任务的时候,我们可以看到通过自由式job里提供的图形界面配置git拉取非常方便的,实际上使用PipeLine也并不复杂.这一节我们展示一下如 ...
- 持续集成高级篇之Jenkins cli与Jenkins ssh
系列目录 Jenkins Cli介绍 Jenkins Cli为Jenkins提供的一个cli工具,此工具功能非常强大,可以完成诸如重启jenkins,创建/删除job,查看job控制台输出,添加/删除 ...
- 持续集成高级篇之Jenkins资源调度
系列目录 之前的示例我们主要关注点在于功能的实现,都是在一个节点的完成了.有了多个节点后,必须涉及到资源的调度问题.本节我们讲解在创建任务时与资源调度的有关选项以及一些平时没有注意到的但在生产环境需要 ...
- .net持续集成cake篇之cake介绍及简单示例
cake介绍 Cake 是.net平台下的一款自动化构建工具,可以完成对.net项目的编译,打包,运行单元测试,集成测试甚至发布项目等等.如果有些特征Cake没有实现,我们还可以很容易地通过扩展Cak ...
随机推荐
- 2017day1
http://www.cnblogs.com/alex3714/articles/5465198.html 四.Python安装 windows 1 2 3 4 5 6 7 1.下载安装包 h ...
- Python_Day1_人人都爱列表
列表由一系列按特定顺序排列的元素组成.你可以创建包含字母表中所有字母.数字0~9或 所有家庭成员姓名的列表;也可以将任何东西加入列表中,其中的元素之间可以没有任何关系. 鉴于列表通常包含多个元素,给列 ...
- 浅谈CMDB
CMDB和运维自动化 一.运维 运维,指的是对已经搭建好的网络,软件,硬件进行维护.运维领域也是细分的,有硬件运维和软件运维 硬件运维主要包括对基础设施的运维,比如机房的设备,主机的硬盘,内存这些物理 ...
- KNN算法实现手写体区分
KNN算法在python里面可以使用pip install指令安装,我在实现之前查看过安装的KNN算法,十分全面,包括了对于手写体数据集的处理.我这里只是实现了基础的识别方法,能力有限,没有数据处理方 ...
- HZOJ 单
两个子任务真的是坑……考试的时候想到了60分的算法,然而只拿到了20分(各种沙雕错,没救了……). 算法1: 对于测试点1,直接n遍dfs即可求出答案,复杂度O(n^2),然而还是有好多同学跑LCA/ ...
- 了解下Java中的Serializable
在项目中也写了不少的JavaBean,也知道大多的JavaBean都实现了Serializable接口,也知道它的作用是序列化,序列化就是保存,反序列化就是读取.主要体现在这两方面: 1.存储.将 ...
- HTTP_4_返回结果的HTTP状态码
状态码:返回请求结果. 状态码种类繁多,以下总结常用的状态码: 类别 信息性状态码 1XX 服务器接受请求,继续处理 成功状态码 200 OK 请求处理成功,并返回资源(响应报文中 ...
- 熟悉软件的生命周期AND测试工程师的工作流程
1.软件的生命周期 *软件生命周期(SDLC)是软件开始研制到最终被废弃不用所经历的各个阶段.在不同阶段里,由不同的组织.个人和资源进行着明确的任务. 2.生命周期的模型 *常见的生命周期模型有:瀑布 ...
- MYSQL 时间轴数据 获取同一天数据的前3条
创建表数据 CREATE TABLE `praise_info` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `pic_id` va ...
- 【Mac】nsurlsessiond 后台下载问题的解决方法
最近在使用 Mac 系统的时候,经常发现 nsurlsessiond 这个进程,一直在后台下载,非常占用网速.解决方案如下: 通过终端执行下面的语句可以停止后台的自动更新: #!/bin/sh lau ...