图数据库PageRank算法
目录:
定义:
假设对象A具有指向它的对象T1 ... Tn。参数d是阻尼系数,取值范围在0和1之间,通常将d设置为0.85。C(A)被定义为从对象A出去的连接数。
对象A的PageRank计算公式如下:
PR(A)=(−d)+d(PR(T1)/C(T1)+...+PR(Tn)/C(Tn))
当一个节点只有输出,没有输入的时候,因为d一般设置为0.85,所以:
PR(A)=(-d)+ d *()= 0.15
计算原理:
每个对象的PR取决于指向它的对象的PR。在指向一个对象的所有对象都计算出了PR,才能够计算出该页面的PR值。
当所有对象形成闭环时,PR(A)可以使用简单的迭代算法计算,并且对应于web的规范化链接矩阵的主特征向量。
基本上,每次计算都会对各对象的最终值进行更接近的估计。通过对这些对象进行大量重复的计算,直到结果变化很小为止。
示例1:
每个页面都有一个输出链接(输出计数为1,即C(A)= 1,C(B)= 1)

假设A的PR(A)初始值为1
d = 0.85 //默认值 PR(A)=( - d)+ d(PR(B)/ ) PR(B)=( - d)+ d(PR(A)/ ) //即 PR(A)= 0.15 + 0.85 * = PR(B)= 0.15 + 0.85 * =
假设A的PR(A)初始值为0
PR(A)= 0.15 + 0.85 * = 0.15 PR(B)= 0.15 + 0.85 * 0.15 = 0.2775 //完成一次迭代,继续第二次迭代 PR(A)= 0.15 + 0.85 * 0.2775 = 0.385875 PR(B)= 0.15 + 0.85 * 0.385875 = 0.47799375 //第三次迭代 PR(A)= 0.15 + 0.85 * 0.47799375 = 0.5562946875 PR(B)= 0.15 + 0.85 * 0.5562946875 = 0.622850484375 //结果数值不断上升,但当达到1.0时,停止增加。
假设A的PR(A)初始值为40,B的PR(B)初始值为40
//初始值
PR(A)=
PR(B)= //第一次迭代 PR(A)= 0.15 + 0.85 * = 34.25 PR(B)= 0.15 + 0.85 * 0.385875 = 29.1775 //第二次迭代 PR(A)= 0.15 + 0.85 * 29.1775 = 24.950875 PR(B)= 0.15 + 0.85 * 24.950875 = 21.35824375 //结果数值不断下降,但当达到1.0时,停止下降。
性质:
当没有节点只进不出时,PageRank计算结果符合“ 归一化概率分布 ”,所有节点的PageRank平均值为1.0。
示例2:

该实例不满足只进不出条件,第三列的节点只有输入,没有输出,所以PR的平均值不等于1.0
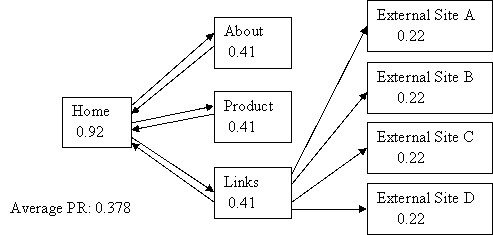
参考资料:
http://www.cs.princeton.edu/~chazelle/courses/BIB/pagerank.htm
图数据库PageRank算法的更多相关文章
- 数值分析:幂迭代和PageRank算法
1. 幂迭代算法(简称幂法) (1) 占优特征值和占优特征向量 已知方阵\(\bm{A} \in \R^{n \times n}\), \(\bm{A}\)的占优特征值是量级比\(\bm{A}\)所有 ...
- 数值分析:幂迭代和PageRank算法(Numpy实现)
1. 幂迭代算法(简称幂法) (1) 占优特征值和占优特征向量 已知方阵\(\bm{A} \in \R^{n \times n}\), \(\bm{A}\)的占优特征值是比\(\bm{A}\)的其他特 ...
- 图数据库-Neo4j-常用算法
本次主要学习图数据库中常用到的一些算法,以及如何在Neo4j中调用,所以这一篇偏实战,每个算法的原理就简单的提一下. 1. 图数据库中常用的算法 PathFinding & Search 一般 ...
- MapReduce实现PageRank算法(稀疏图法)
前言 本文用Python编写代码,并通过hadoop streaming框架运行. 算法思想 下图是一个网络: 考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个 ...
- pagerank算法在数学模型中的运用(有向无环图中节点排序)
一.模型介绍 pagerank算法主要是根据网页中被链接数用来给网页进行重要性排名. 1.1模型解释 模型核心: a. 如果多个网页指向某个网页A,则网页A的排名较高. b. 如果排名高A的网页指向某 ...
- 图数据库|基于 Nebula Graph 的 BetweennessCentrality 算法
本文首发于 Nebula Graph Community 公众号 在图论中,介数(Betweenness)反应节点在整个网络中的作用和影响力.而本文主要介绍如何基于 Nebula Graph 图数据 ...
- 同步图计算实现pageRank算法
pageRank算法是Google对网页重要性的打分算法. 一个用户浏览一个网页时,有85%的可能性点击网页中的超链接,有15%的可能性转向任意的网页.pageRank算法就是模拟这种行为. Rv:定 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- 浅析PageRank算法
很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看了一些相关的资料(PS:在动车上看看书真是一种享受),趁热打铁,将所看 ...
随机推荐
- zookeeper 都有哪些使用场景?
面试题 zookeeper 都有哪些使用场景? 面试官心理分析 现在聊的 topic 是分布式系统,面试官跟你聊完了 dubbo 相关的一些问题之后,已经确认你对分布式服务框架/RPC框架基本都有一些 ...
- 并发编程之多线程(Java)
一.线程与进程区别 每个正在系统上运行的程序都是一个进程.每个进程包含一到多个线程.线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行.也可以把它理解为代码运行的上下文.所以线程基本上是 ...
- ORM增删改查
目录 orm django 连接mysql顺序 1 settings配置文件中 2 项目文件夹下的init文件中写上下面内容, 补充 3 models文件中创建一个类(类名就是表名) 4.执行数据库同 ...
- apache中通过mod_rewrite实现伪静态页面的方法
rewrite规则学习 我们新建一个.htaccess文件之后,就在里面写入以下内容: RewriteEngine on #rewriteengine为重写引擎开关on为开启off为关闭 Rewrit ...
- 快学Scala 第一课 (变量,类型,操作符)
Scala 用val定义常量,用var定义变量. 常量重新赋值就会报错. 变量没有问题. 注意:我们不需要给出值或者变量的类型,scala初始化表达式会自己推断出来.当然我们也可以指定类型. 多个值和 ...
- C# WinForm 跨线程访问控件(实用简洁写法)
C# WinForm 跨线程访问控件(实用简洁写法) 1.<C# WinForm 跨线程访问控件(实用简洁写法)> 2.<基于.NET环境,C#语言 实现 TCP NAT ...
- 服务网关Spring Cloud Zuul
Spring Cloud Zuul 开发环境 idea 2019.1.2 jdk1.8.0_201 Spring Boot 2.1.9.RELEASE Spring Cloud Greenwich S ...
- JDBC访问数据库的基本步骤
加载驱动 通过DriverManager对象获取连接对象Connection 通过连接对象获取会话 通过会话进行数据的增删改查,封装对象 关闭资源
- Python小游戏——猜数字教程(random库教程)
今天来开发一个简单的数字逻辑游戏,猜数字(数字炸弹) 首先开发游戏第一件事,了解需求. 猜数字游戏规则: 计算机随机生成一个指定范围的数字,由玩家来猜测, 之后计算机会根据玩家提供数字来与自己生成的数 ...
- Python历史+优缺点+应用领域+网站职位简介
一.Python的历史 1. 1989年圣诞节:Guido von Rossum开始写Python语言的编译器.2. 1991年2月:第一个Python编译器(同时也是解释器)诞生,它是用C语言实现的 ...