hadoop大数据平台安全基础知识入门
概述
以 Hortonworks Data Platform (HDP) 平台为例 ,hadoop大数据平台的安全机制包括以下两个方面:
- 身份认证 即核实一个使用者的真实身份,一个使用者来使用大数据引擎平台,这个使用者需要表明自己是谁,即提供自己的身份证明,大数据平台需要检验这个证明,确定这个证明是有效的,且不是伪造的。否则,就拒绝这个使用者进入大数据引擎。
- 授权管理 这个使用者的真实身份核实之后,需要对这个使用者的使用权限进行界定,即这个使用者在大数据平台中能够使用什么组件,能够获取哪些资源,能够对资源进行哪些操作进行管理.
身份认证
大数据平台一般使用基于 Kerberos 的身份认证机制
概述
简单来说,大数据平台中有一个专门的认证服务器KDC,可以把它看作是户籍派出所,可事先给所有的平台使用者(人用户以及机器和程序用户)发放户籍证明,即keytab(密钥)。之后每个用户要使用大数据平台,就要拿着这个证明先去KDC认证,认证无误之后,才能够使用大数据平台引擎。操作示例
首先要对整个平台进行 kerberos 化,hdp ambari 提供了傻瓜式操作,另附文章介绍.
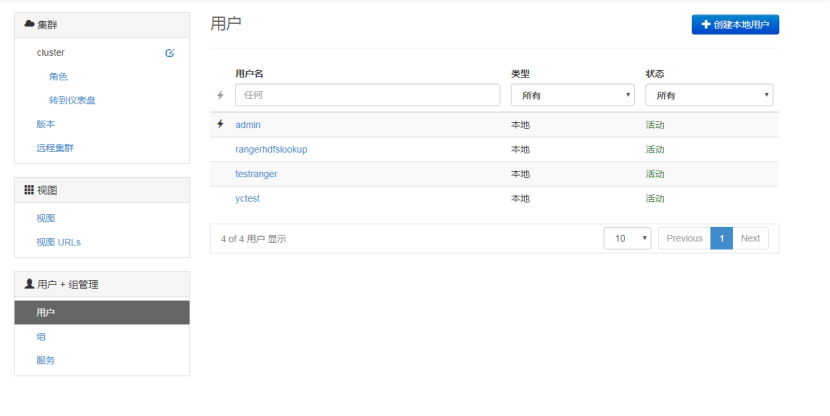
如上图,kerberos化后,我们对 ambari 管理界面进行了二次开发.在这里创建本地用户的时候,已经同步向KDC服务器注册了该用户的相关信息,同时生成了该用户的keytab,点击用户,进入详情页可下载密钥。之后该用户来使用大数据平台(无论是命令行还是API调用还是其他什么方式),必须先携带keytab去KDC进行认证。这里以命令行的方式举例,例如某个用户需要使用hadoop去读取hdfs上面的文件。他需要先亮明自己的身份,即执行命令:
kinit -k -t keytab路径 用户名 这样之后再去执行hdfs等命令的时候才能够认证通过,而不会报错:
Exception encountered while connecting to the server : javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
授权管理
大数据平台使用基于apache ranger的授权管理。授权管理是应该是建立在身份认证之上的,试想以下,如果连身份都无法确认的话,那你的任何授权都是不可靠的(你确定你授权的这个用户就是这个用户吗),你的授权管理其实是空中阁楼.
概述
ranger提供了基于资源的授权管理机制,所谓资源就是大数据平台中的各组件(例如hdfs,hive,hbase等),以及组件内的具体资源(例如hdfs的某个路径,hive,hbase中的某个表)。某个组件资源对应于ranger中的service(服务),在单个service中创建策略就可以对这个组件的具体资源进行用户的权限管理了.操作指南
我们对 ambari 界面进行了二次开发,将 ranger 原生界面移植过来
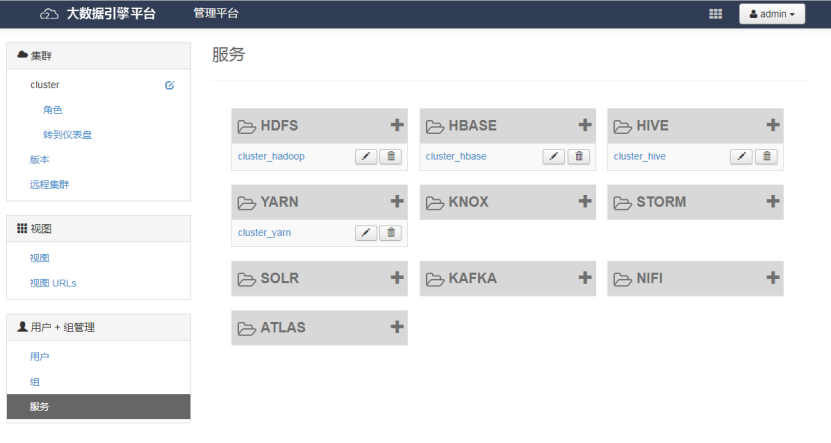
如图,以此为例, ranger 自动探测并生成平台中各个组件服务,点击进入服务详情

增加或者编辑策略即可对具体资源进行授权管理了。如上图,我们授予了testranger用户对hbase所有表的所有列的所有操作权限。如果编辑这个策略,删除testranger这个用户,那么这个用户在hbase做查询等操作的时候就会出错:
ERROR: org.apache.hadoop.hbase.security.AccessDeniedException: Insufficient permissions for user ‘testranger@EXAMPLE.COM',action: scannerOpen, tableName:test, family:f1
另外也可以新建新的策略来管理,策略提供了细粒度的权限管理方式,详细可参考 ranger 官网.
hadoop大数据平台安全基础知识入门的更多相关文章
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- 数据仓库和Hadoop大数据平台有什么差别?
广义上来说,Hadoop大数据平台也可以看做是新一代的数据仓库系统, 它也具有很多现代数据仓库的特征,也被企业所广泛使用.因为MPP架构的可扩展性,基于MPP的数据仓库系统有时候也被划分到大数据平台类 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
- Hadoop大数据平台入门——HDFS和MapReduce
随着硬件水平的不断提高,需要处理数据的大小也越来越大.大家都知道,现在大数据有多火爆,都认为21世纪是大数据的世纪.当然我也想打上时代的便车.所以今天来学习一下大数据存储和处理. 随着数据的不断变大, ...
- Hadoop大数据平台构建
基础:linux常用命令.Java编程基础大数据:科学数据.金融数据.物联网数据.交通数据.社交网络数据.零售数据等等. Hadoop: 一个开源的分布式存储.分布式计算平台.(基于Apache) H ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- 【大数据】Clickhouse基础知识
第1章 ClickHouse概述 1.1 什么是ClickHouse ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能 ...
- Hadoop大数据平台搭建之前期配置(2)
环境:CentOS 7.4 (1708 DVD) 工具:VMware.MobaXterm 一. 克隆大数据集群 1. 选中已经进行了基本配置的虚拟机,进行克隆. 2. 此处改为"创建完整克 ...
随机推荐
- 怎么用Hostwinds搭建Wordpress博客网站(超详细图文教程)
Hostwinds 成立于 2010 年,在主机托管行业算是一个比较新的品牌,但是,凭借丰富的产品线.卓越的服务器性能.良好的客户支持,以及低廉实惠的价格,他们受到了广大客户的喜爱,并多次获得行业重要 ...
- Centos7下安装Mysql8.0
突然发现mysql都有8.0了,且性能提升比较明显,就自己装来玩玩. centos的yum源中默认是没有mysql的,所以我们需要先去官网下载mysql的repo源并安装: 官网:http://dev ...
- Python笔记【7】_反射getattr&hasattr&setattr&delattr
Lesson0402_GetatrrWebsite.py #!/usr/bin/env/python #-*-coding:utf-8-*- #Author:LingChongShi #查看源码Ctr ...
- C++学习笔记 之 运算符
用来执行特定的数字或逻辑操作,C++主要提供的运算符如下: 算数运算符 关系运算符 逻辑运算符 位运算符 赋值运算符 杂项运算符 算数运算符: 主要运算符:+(加).-(减) .*(乘) ./(除) ...
- mysql的数据存储
# pycharm 连接mysql import pymysql username = input("输入用户名:") pwd = input("输入密码:") ...
- pycharm在服务器上远程调试 mac版本
1. 首先要配置tools 2.点 +,选择SFTP, 填写 New server name:随便填写 3.然后填写 connection 和 Mapping Host:填写远程连接的ip地址 Use ...
- Java第二次作业——数组和String类
Java第二次作业--数组和String类 学习总结 1.学习使用Eclipse关联jdk源代码,查看String类的equals()方法,截图,并学习其实现方法.举例说明equals方法和==的区别 ...
- pdfminer获取每页的layout
#! python2 # coding: utf-8 import sys from pdfminer import pdfparser from pdfminer import pdfdocumen ...
- mybatis-generator生成数据表中注释
0.git clone https://github.com/backkoms/mybatis-generator-comments.git,编译打包,install到本地或delopy私服库中均可. ...
- shell_umask用法
我曾经用touch命令创建一个文件script,默认的权限是"rw-r- -r- -",有的朋友就有可能问为什么是这种组合?其实,这正是umask命令捣的鬼.在linux上输入:u ...