HashMap、Hash Table、ConcurrentHashMap
这个这个。。。本王最近由于开始找实习工作了,所以就在牛客网上刷一些公司的面试题,大多都是一些java,前端HTML,js,jquery,以及一些好久没有碰的算法题,说实话,有点难受,其实在我不知道的很多是地方还有很多很多的知识漏洞,就像这一次写的这个,也是我在刷题的时候感觉到真的是我空缺的地方,为什么呢?因为,做多了,错多了。然而很尴尬的又是因为这个只是也是很多公司的面试题,所以索性直接写下来整理一遍。
在这里我也建议各位,牛客网不仅仅是一个找工作的station也是一个可以锻炼我们的地方,没事刷刷题啊,逛逛论坛啊,说不定就能找到很多你意想不到的东西。
在面试的过程中,有几个问题是比较常见的。
- HashTable、HashMap、ConcurrentHashMap的区别?
- HashMap线程不安全的出现场景?
- HashMap put方法存放数据时是怎么判断是否重复的?
- JDK7和JDK8 中HashMap的实现有什么区别?
- HashMap的长度为什么是2的幂次方?
只要把这几个问题过一遍之后,大致了解了他们各自的作用与互相之间的区别再!!去敲一遍其实就可以掌握了。
放一张珍贵的图给大家学习学习!
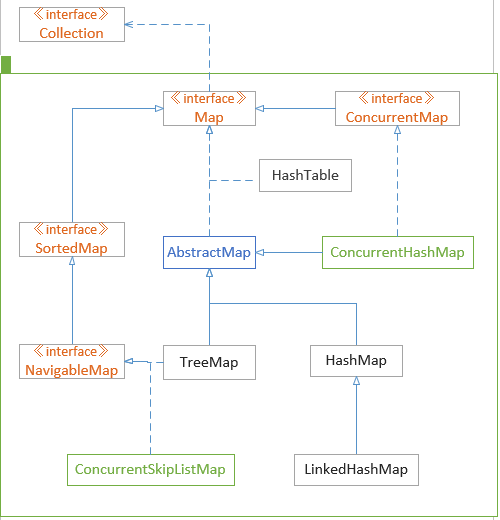
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = oldsize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
HashMap
- 在底层数组+链表中实现,线程不安全,可存储null键和null值
- 初始size为16,可扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容的时候,原来数组中的元素依次重新计算存放的位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
*HashMap的初始值还要考虑加载因子:
哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap与HashTable的区别(面试题常考~)
1.两者所继承的父类不同
HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
在这里原本是截取了JDK API1.6 中文版里面的,但实在是太丑了,就在别人的博客,呵呵,悄咪咪的拿了过来借鉴了一下
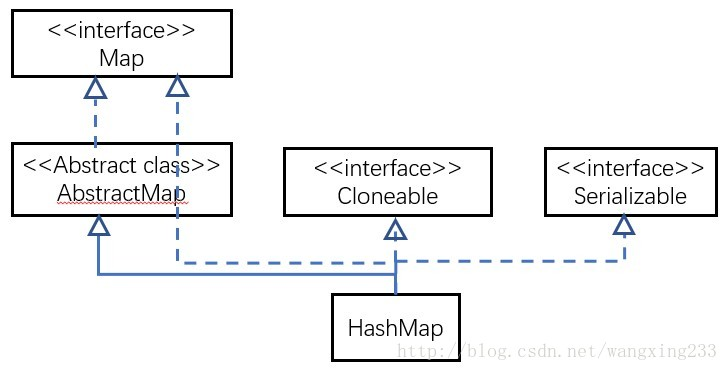
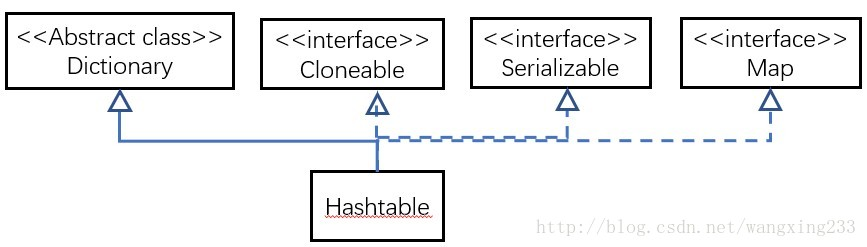
2.两者对外接口是不同的
HashTable比HashMap多提供了elements()和contains()两个方法。
elements()方法继承自HashTable的父类Doctionnary。elements()方法用于返回此时HashTable中的值的枚举。
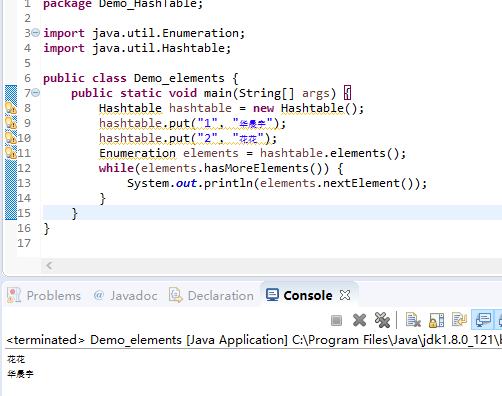
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法,是判断哈希表中是否包含指定的值。如图是contains的源码:
public virtual bool Contains(object key)
{
return this.ContainsKey(key);
}
3.对Null key 和Null value的支持不同
Hashtable既不支持Null key也不支持Null value。
HashMap中,key-value都是存在Entry中的。null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null,不保证元素的顺序恒久不变,它的底层使用的是数组和链表,用过HashCode()方法和equal()方法来保证键的唯一性。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
4.线程安全的不同性
Hashtable是线程安全的,它的每个方法中都加入了Synchronize方法。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步。
HashMap不是线程安全的,在多线程并发的环境下,可能会产生死锁等问题。所以使用HashMap时就必须要自己增加同步处理,
虽然HashMap不是线程安全的,但是它的效率会比Hashtable要好很多。这样设计是合理的。在我们的日常使用当中,大部分时间是单线程操作的。HashMap把这部分操作解放出来了。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。
5.Hash值的计算方法不同
为了求得元素的位置,需要根据元素的Key计算出一个哈希值,然后再用这个哈希值来计算出崔忠的位置。

Hashtable直接使用对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数发来获得最终的位置。
Hashtable在计算元素的位置时需要进行一次除法运算,而除法运算是比较耗时的。
HashMap为了提高计算效率,将哈希表的大小固定为了2的幂,这样在取模预算时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。
HashMap的效率虽然提高了,但是hash冲突却也增加了。因为它得出的hash值的低位相同的概率比较高,而计算位运算
为了解决这个问题,HashMap重新根据hashcode计算hash值后,又对hash值做了一些运算来打散数据。使得取得的位置更加分散,从而减少了hash冲突。当然了,为了高效,HashMap只做了一些简单的位处理。从而不至于把使用2 的幂次方带来的效率提升给抵消掉。
ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全。
- key和value都不能为null。
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
这个就很棒了,上面总结的源于某猿大神,Java5提供的ConcurrentHashMap就像是HashTable的升级版,扩容性更强。
在HashMap中,通过get()返回的null值,既可以表示返回该Key所对应过的Value是null值,也可以表示为没有该Key,在这种情况下就应该采用ConcurrentHashMap。
来看一张简单的类图:
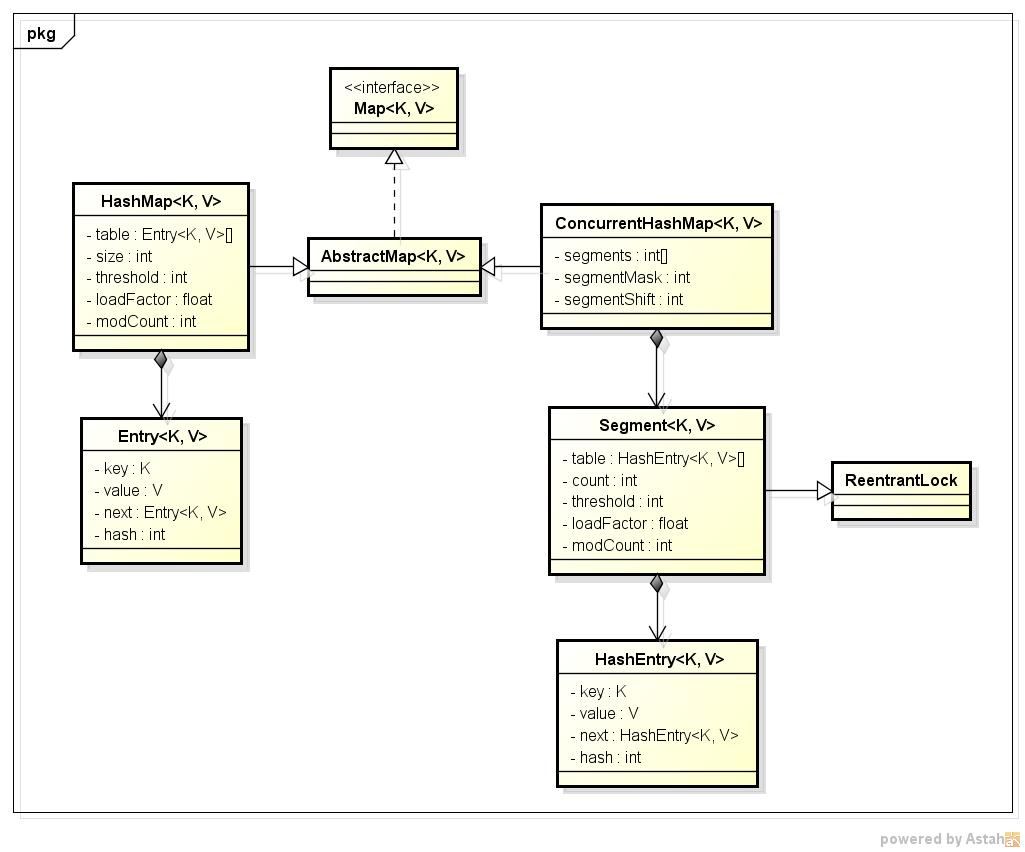
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一个可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素。当对HashEntry数组的数据进行修改时,必须首先获得与它对应的segment锁。
Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
简单理解就是,ConcurrentHashMap是一个Segment数组,Segment通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个Segment,只要保证每个Segment是线程安全的,也就实现了全局的线程安全。重申一下,Segment数组不能扩容,扩容是Segment数组某个位置内部的数组HashEntry<K,V>[]进行扩容,扩容后,容量为原来的2倍。可以回顾下出发扩容的地方,put的时候,如果判断该值的插入会导致该Segment的元素个数超过阈值,那么先进行扩容,再插值。
TreeMap
- TreeMap实现了NavigableMap接口,而Navigable接口继承着继承着SortedMap接口,致使我们的TreeMap是有序的!
- TreeMap底层是红黑树,它方法时间复杂度都不会太高:log(n)~
- 非同步
- 使用Comparator或者Comparable来比较key是否相等与排序的问题~
- key不可以为null,会报NullPointerException异常,value可以为null。
TreeMap中的元素默认按照keys的自然排序排列。(对Integer来说,其自然排序就是数字的升序;对String来说,其自然排序就是按照字母表排序)
HashMap、Hash Table、ConcurrentHashMap的更多相关文章
- Java 总结 数据底层原理 【包括 ArrayList、LinkedList、hash table、HashMap、Hashtable、ConcurrentHashMap、hash code、HashSet、LinkedHashMap、LinkedHashSet】
1.ArrayList (1)底层是由动态数组实现的[使用了List接口]. (2)动态数组是长度不固定,随着数据的增多而变长. (3)如果不指定,默认长度为10,当添加的元素超过当前数组的长度时,会 ...
- 探究公钥、私钥、对称加密、非对称加密、hash加密、数字签名、数字证书、CA认证、https它们究竟是什么,它们分别解决了通信过程的哪些问题。
一.准备 1. 角色:小白.美美.小黑. 2. 剧情:小白和美美在谈恋爱:小黑对美美求而不得.心生怨念,所以从中作梗. 3. 需求:小白要与美美需通过网络进行通信,联络感情,所以必须保证通信的安全性. ...
- Nested loops、Hash join、Sort merge join(三种连接类型原理、使用要点)
nested loop 嵌套循环(原理):oracle从较小结果集(驱动表.也可以被称为outer)中读取一行,然后和较大结果集(被侦查表,也可以叫做inner)中的所有数据逐条进行比较(也是等值连接 ...
- 文本表征:SoW、BoW、TF-IDF、Hash Trick、doc2vec、DBoW、DM
原文地址:https://www.jianshu.com/p/2f2d5d5e03f8 一.文本特征 (一)基本文本特征提取 词语数量 常,负面情绪评论含有的词语数量比正面情绪评论更多. 字符数量 常 ...
- B+索引、Hash索引、数据类型长度
1.为什么在数据库中要用B树索引而不是Hash索引? Mysql Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这 ...
- 词向量:part 1 WordNet、SoW、BoW、TF-IDF、Hash Trick、共现矩阵、SVD
1.基于知识的表征 如WordNet(图1-1),包含同义词集(synonym sets)和上位词(hypernyms,is a关系). 存在的问题: 作为资源来说是好的,但是它失去了词间的细微差别, ...
- ( 转 ) 数据库BTree索引、Hash索引、Bitmap位图索引的优缺点
测试于:MySQL 5.5.25 当前测试的版本是Mysql 5.5.25只有BTree和Hash两种索引类型,默认为BTree.Oracle或其他类型数据库中会有Bitmap索引(位图索引),这里作 ...
- HASH、HASH函数、HASH算法的通俗理解
之前经常遇到hash函数或者经常用到hash函数,但是hash到底是什么?或者hash函数到底是什么?却很少去考虑.最近同学去面试被问到这个问题,自己看文章也看到hash的问题.遂较为细致的追究了一番 ...
- 元祖、hash了解、字典、集合
元祖: 元组跟列表差不多,也是存一组数,只是它一旦创建,便不能再修改,所以又叫只读列表. 创建: names = ('neo', 'mike', 'eric') 特性: # 1.可存放多个值 # 2. ...
随机推荐
- Programming In Lua 第四章
1, 2, 3, 4, 5, 6, 7,
- K8s集群部署(四)------ Flannel网络部署
所有节点都要部署Flannel网络,在所有节点操作. 1.为Flannel生成证书 [root@k8s-master ssl]# pwd /usr/local/src/ssl [root@k8s-ma ...
- 一文学会Java死锁和CPU 100% 问题的排查技巧
做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开 工欲善其事,必先利其器 00 本文简介 作为一名搞技术的程序猿或者是攻城狮,想必你应该是对下面这两个问题有所了解,说不定你在 ...
- RobotFramework + HTTP接口自动化实现
一. 什么是自动化测试? 1. 定义 自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程,也可以说是软件测试的一种技术手段. 2. 常见工具 Appium ...
- 005-python-字典操作
1. 字典 dict 用{}来表示 键值对数据 {key:value} 唯一性 键 都必须是可哈希的 不可变的数据类型就可以当做字典中的键 值 没有任何限制 dic = {'name':'alex', ...
- 如何搭建一个vue项目(完整步骤)
参考资料 一.安装node环境 1.下载地址为:https://nodejs.org/en/ 2.检查是否安装成功:如果输出版本号,说明我们安装node环境成功 3.为了提高我们的效率,可以使用淘宝的 ...
- Azkaban Condition Flow (条件工作流) 使用简介
本文上接<Azkaban Flow 2.0 使用简介>,对Azkaban Condition Flow (条件工作流) 做简单介绍 目录 目录 条件工作流 介绍 作用 使用方式 支持的运算 ...
- Java学习笔记之---集合
Java学习笔记之---集合 (一)集合框架的体系结构 (二)List(列表) (1)特性 1.List中的元素是有序并且可以重复的,成为序列 2.List可以精确的控制每个元素的插入位置,并且可以删 ...
- STM32F072从零配置工程-串口USART配置
也是使用HAL库进行配置,通过STMCube生成代码,可以通过这个简单的配置过程看到STMCube生成代码的一种规范: 从main函数入手观察其外设配置结构: 首先是HAL_Init()进行所有外设的 ...
- Centos6.5安装Redis3.2.8
1 - Redis安装 redis安装 在网上一搜一大把,但是还是在这里想要能够统一吧,所以这个安装步骤是在Centos6.5 Minimal 上安装redis3.4.8,本次安装是在root 用户下 ...