spark 源码分析之十九 -- Stage的提交
引言
上篇 spark 源码分析之十九 -- DAG的生成和Stage的划分 中,主要介绍了下图中的前两个阶段DAG的构建和Stage的划分。
本篇文章主要剖析,Stage是如何提交的。
rdd的依赖关系构成了DAG,DAGScheduler根据shuffle依赖关系将DAG图划分为一个一个小的stage。具体可以看 spark 源码分析之十九 -- DAG的生成和Stage的划分 做进一步了解。

紧接上篇文章
上篇文章中,DAGScheduler的handleJobSubmitted方法我们只剖析了stage的生成部分,下面我们看一下stage的提交部分源码。
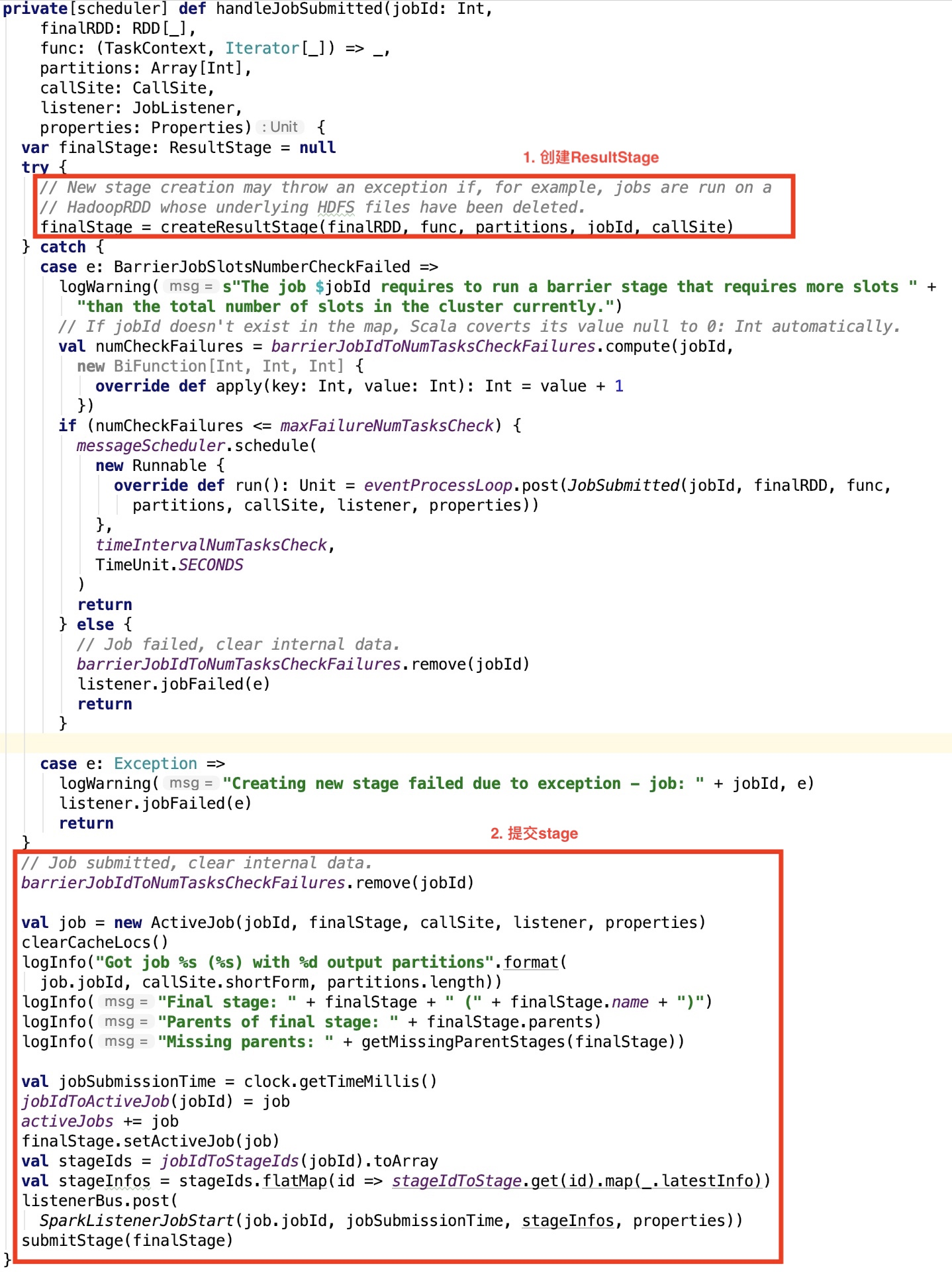
提交Stage的思路
首先构造ActiveJob对象,其次清除缓存的block location信息,然后记录jobId和job对象的映射关系到jobIdToActiveJob map集合中,并且将该jobId记录到活动的job集合中。
获取到Job所有的stage的唯一标识,并且根据唯一标识来获取stage对象,并且调用其lastestInfo方法获取其StageInfo对象。
然后进一步封装成 SparkListenerJobStart 事件对象,并post到 listenerBus中,listenerBus 是一个 LiveListenerBus 对象,其内部封装了四个消息队列组成的集合,具体可以看 spark 源码分析之三 -- LiveListenerBus介绍 文章做进一步了解。
最后调用submitStage 方法执行Stage的提交。
先来看一下ActiveJob的说明。
ActiveJob
类说明
A running job in the DAGScheduler. Jobs can be of two types: a result job, which computes a ResultStage to execute an action, or a map-stage job, which computes the map outputs for a ShuffleMapStage before any downstream stages are submitted. The latter is used for adaptive query planning, to look at map output statistics before submitting later stages. We distinguish between these two types of jobs using the finalStage field of this class. Jobs are only tracked for "leaf" stages that clients directly submitted, through DAGScheduler's submitJob or submitMapStage methods. However, either type of job may cause the execution of other earlier stages (for RDDs in the DAG it depends on), and multiple jobs may share some of these previous stages. These dependencies are managed inside DAGScheduler.
它代表了正运行在DAGScheduler中的一个job,job有两种类型:result job,其通过计算一个ResultStage来执行一个action操作;map-stage job,它在下游的stage提交之前,为ShuffleMapStage计算map的输出。
构造方法

finalStages是这个job的最后一个stage。
提交Stage前的准备
直接先来看submitStage方法,如下:
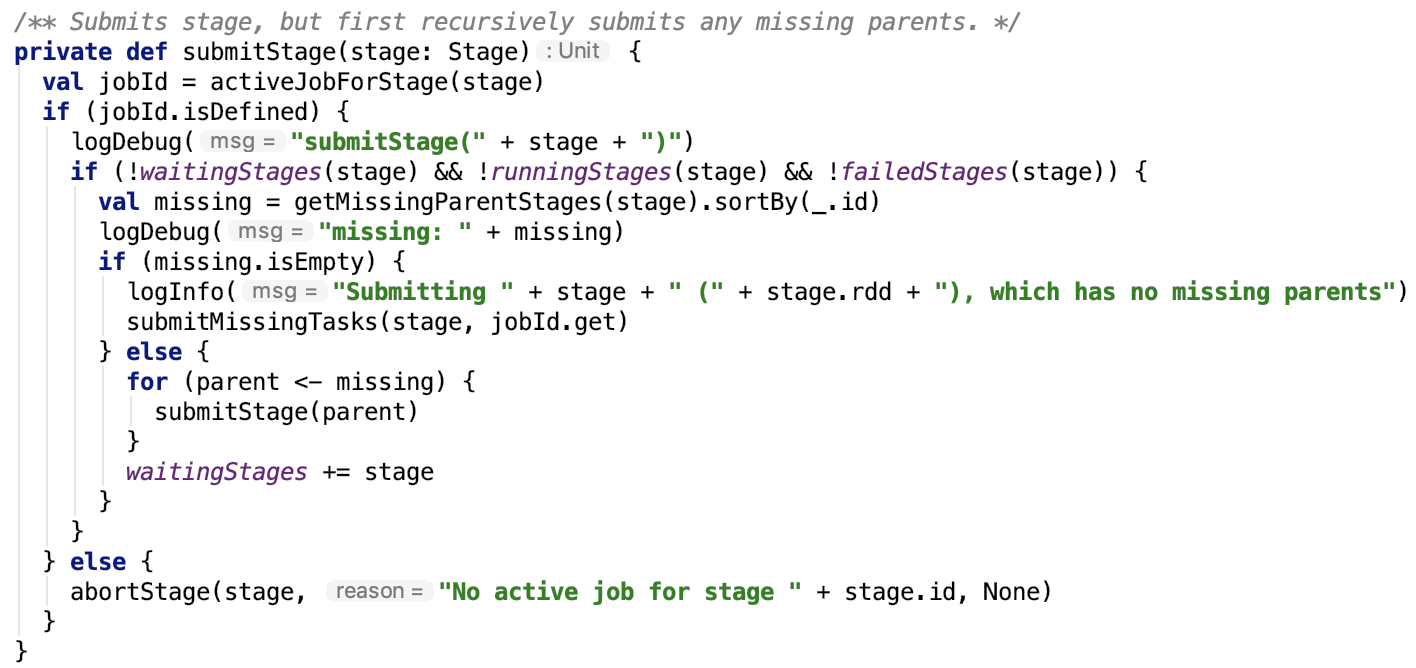
思路: 首先先获取可能丢失的父stage信息,如果该stage的父stage被遗漏了,则递归调用查看其爷爷stage是否被遗漏。
查找遗漏父Stage
getMissingParentStages方法如下:
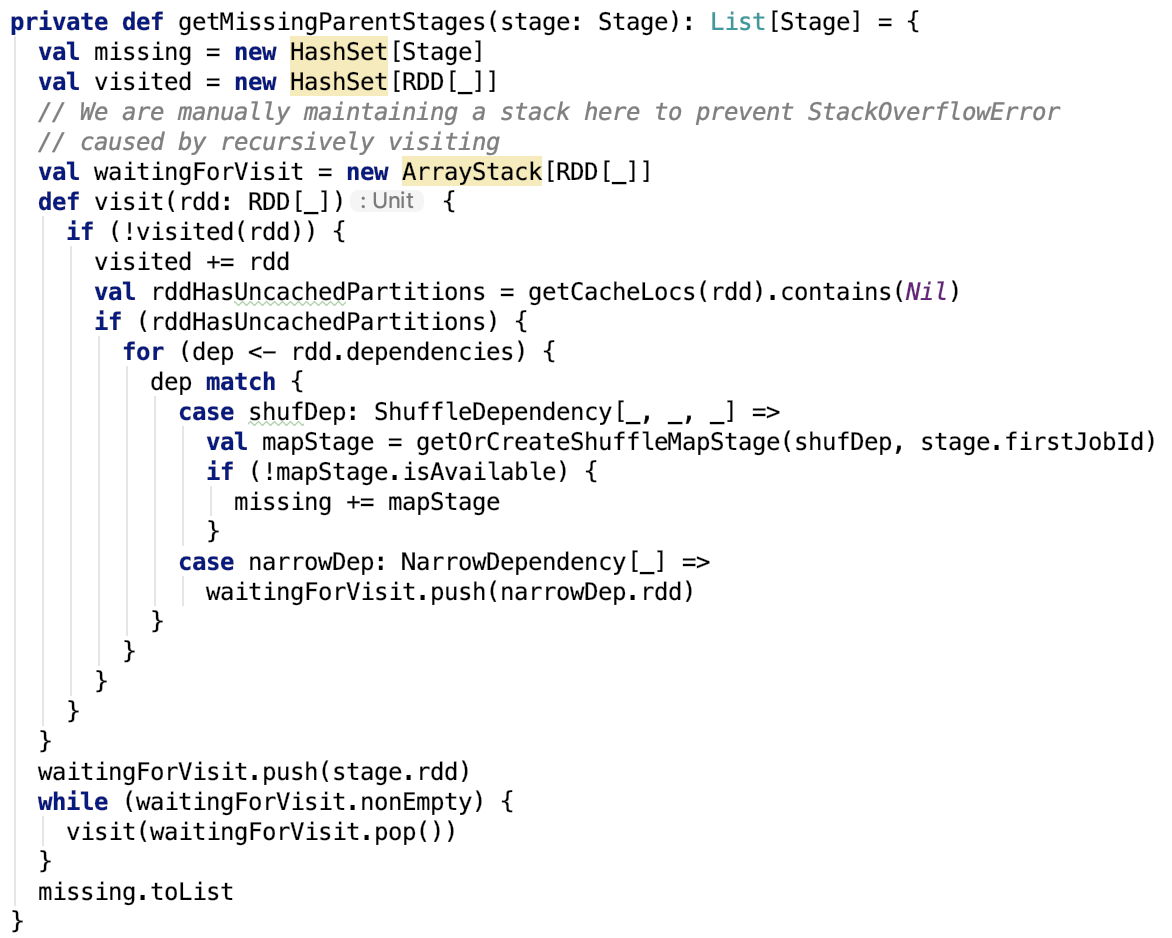
思路:不断创建父stage,可以看上篇文章 spark 源码分析之十九 -- DAG的生成和Stage的划分 做进一步了解。
提交Stage
submitMissingTasks方法过于长,为方便分析,按功能大致分为如下部分:
获取Stage需要计算的partition信息

org.apache.spark.scheduler.ResultStage#findMissingPartitions 方法如下:

org.apache.spark.scheduler.ShuffleMapStage#findMissingPartitions 方法如下:

org.apache.spark.MapOutputTrackerMaster#findMissingPartitions 方法如下:

将stage和分区记录到OutputCommitCoordinator中
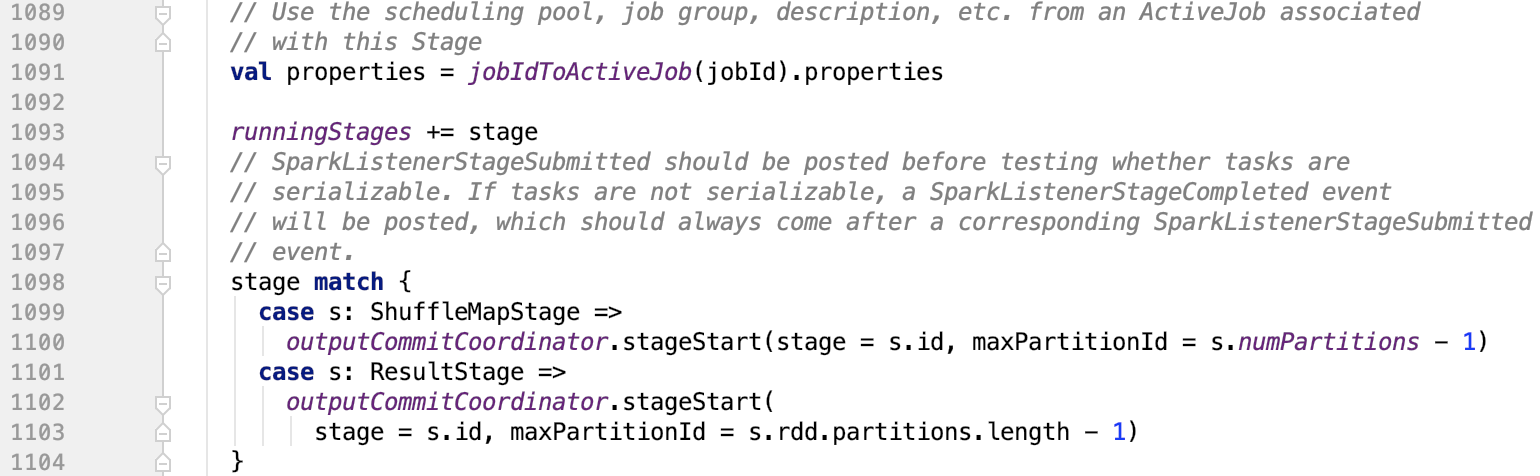
OutputCommitCoordinator 的 stageStart实现如下:

本质上就是把它放入到一个map中了。
获取分区的优先位置
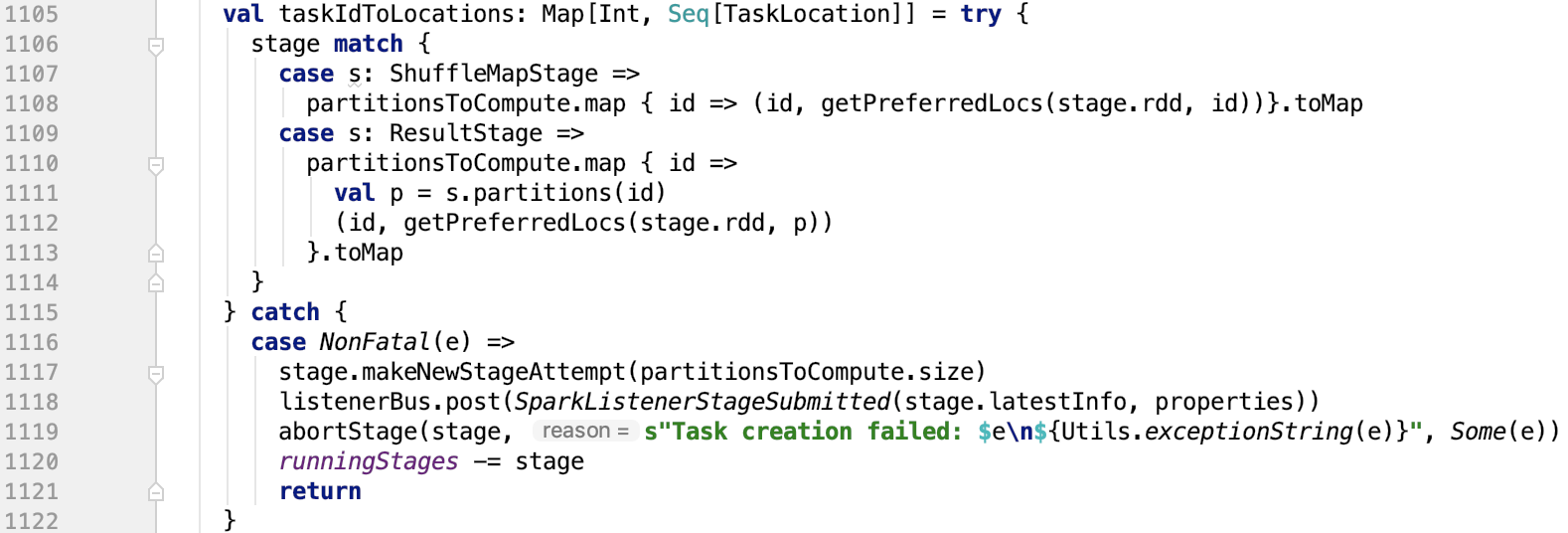
思路:根据stage的RDD和分区id获取到其rdd中的分区的优先位置。
下面看一下 getPreferredLocs 方法:

注释中说到,它是线程安全的,下面看一下,它是如何实现的,即 getPrefferredLocsInternal 方法。

这个方法中提到四种情况:
1. 如果之前获取到过,那么直接返回Nil即可。
2. 如果之前已经缓存在内存中,直接从缓存的内存句柄中取出返回即可。
3. 如果RDD对应的是HDFS输入的文件等,则使用RDD记录的优先位置。
4. 如果上述三种情况都不满足,且是narrowDependency,则调用该方法,获取子RDDpartition对应的父RDD的partition的优先位置。
下面仔细说一下中间两种情况。
从缓存中取
getCacheLocs 方法如下:

思路:先查看rdd的存储级别,如果没有存储级别,则直接返回Nil,否则根据RDD和分区id组成BlockId集合,请求存储系统中的BlockManager来获取block的位置,然后转换为TaskLocation信息返回。
获取RDD的优先位置
RDD的 preferredLocations 方法如下:

思路:先从checkpoint中找,如果checkpoint中没有,则返回默认的为Nil。
返回对象是TaskLocation对象,做一下简单的说明。
TaskLocation
类说明
A location where a task should run. This can either be a host or a (host, executorID) pair. In the latter case, we will prefer to launch the task on that executorID, but our next level of preference will be executors on the same host if this is not possible.
它有三个子类,如下:

这三个类定义如下:

很简单,不做过多说明。
TaskLocation伴随对象如下,现在用的方法是第二种 apply 方法:
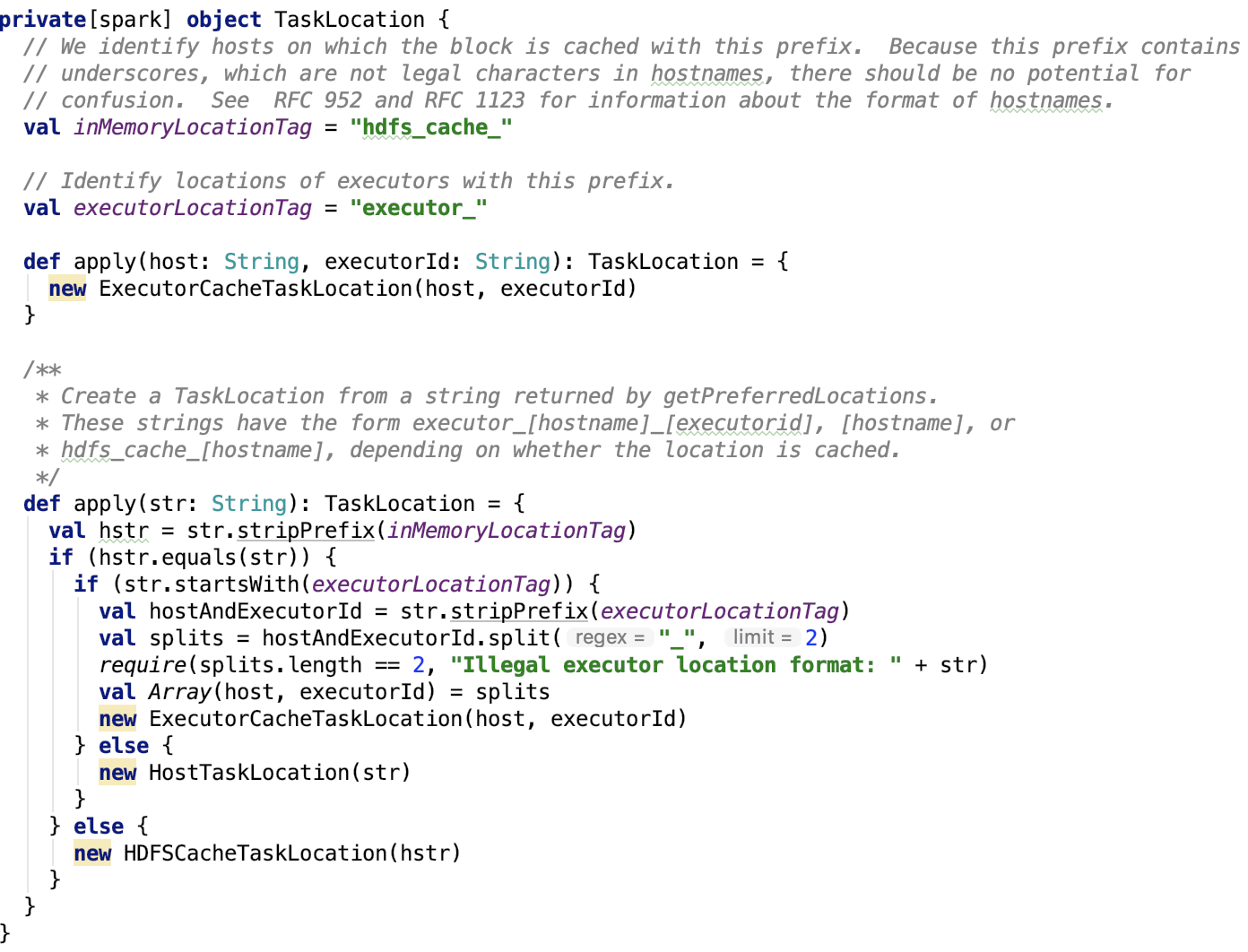
创建新的StageInfo
对应方法如下:

org.apache.spark.scheduler.Stage#makeNewStageAttempt 方法如下:

很简单,主要是调用了StageInfo的fromStage方法。
先来看Stage类。
StageInfo
StageInfo封装了关于Stage的一些信息,用于调度和SparkListener传递stage信息。
其伴生对象如下:

广播要执行task函数
对应源码如下:
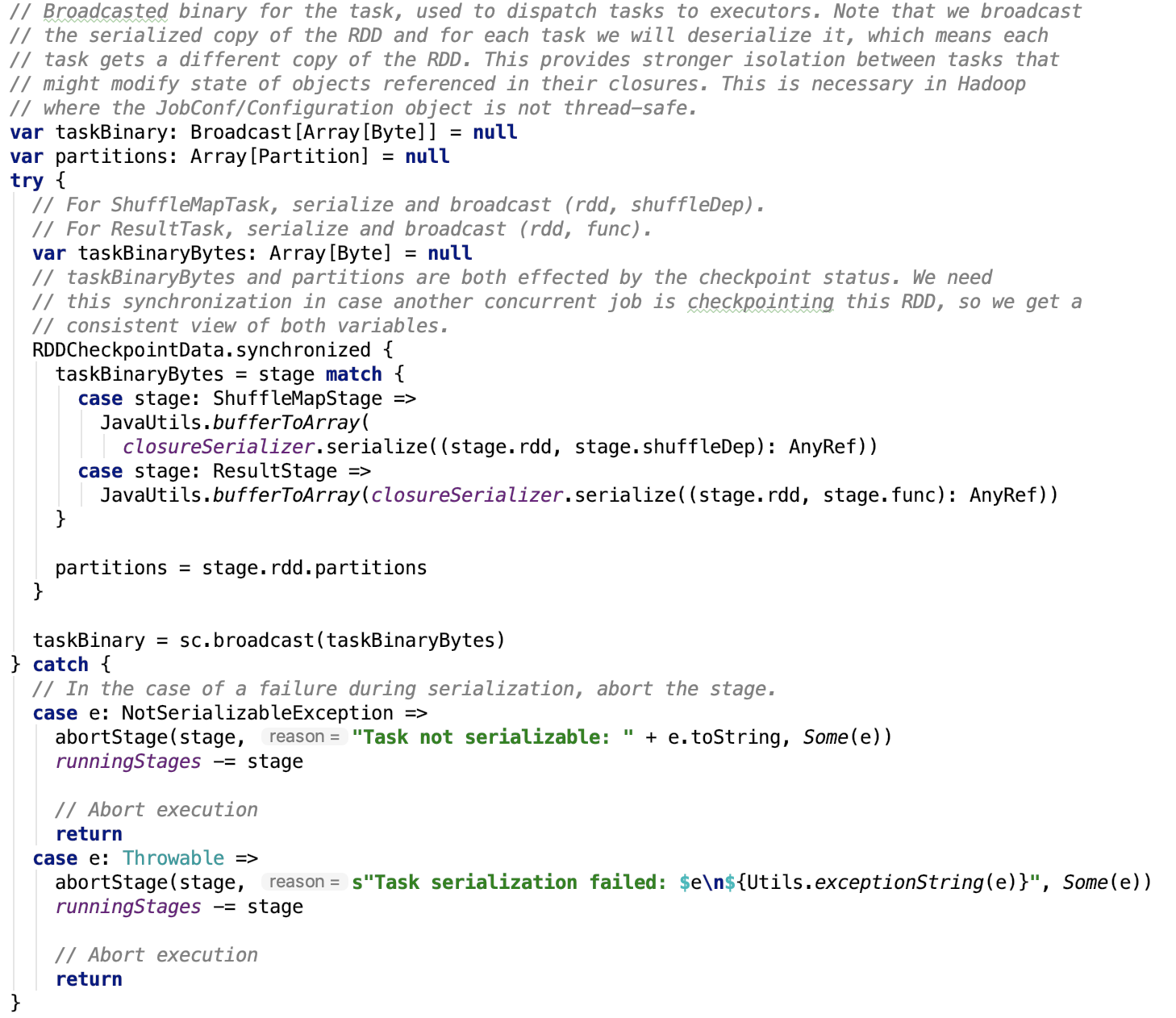
通过broadcast机制,将数据广播到spark集群中的driver和各个executor中。关于broadcast的实现细节,可以查看 spark 源码分析之十四 -- broadcast 是如何实现的?做进一步了解。
生成Task集合
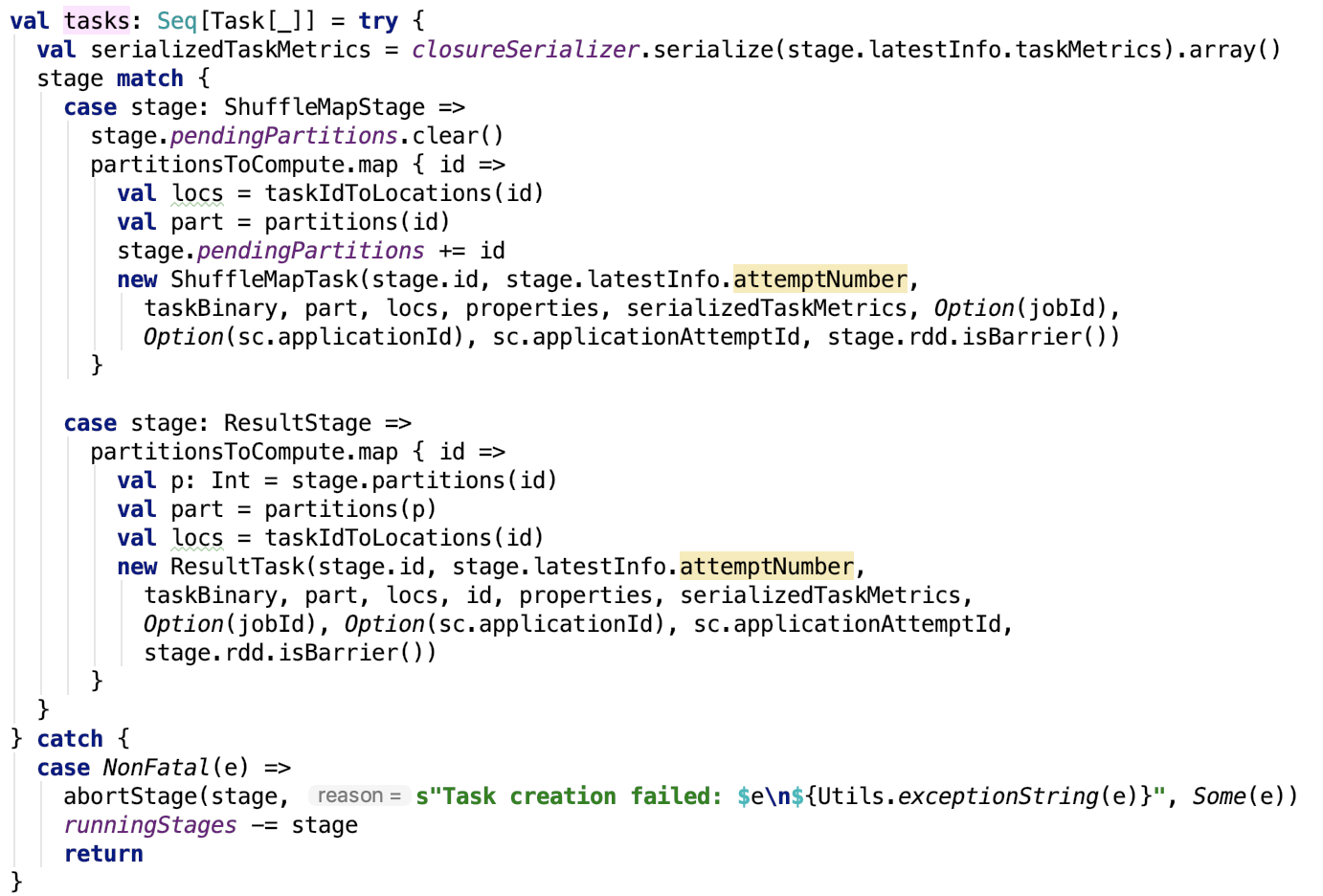
根据stage的类型生成不同的类型Task。关于过多Task 的内容,在阶段四进行剖析。
TaskScheduler提交TaskSet
对应代码如下:
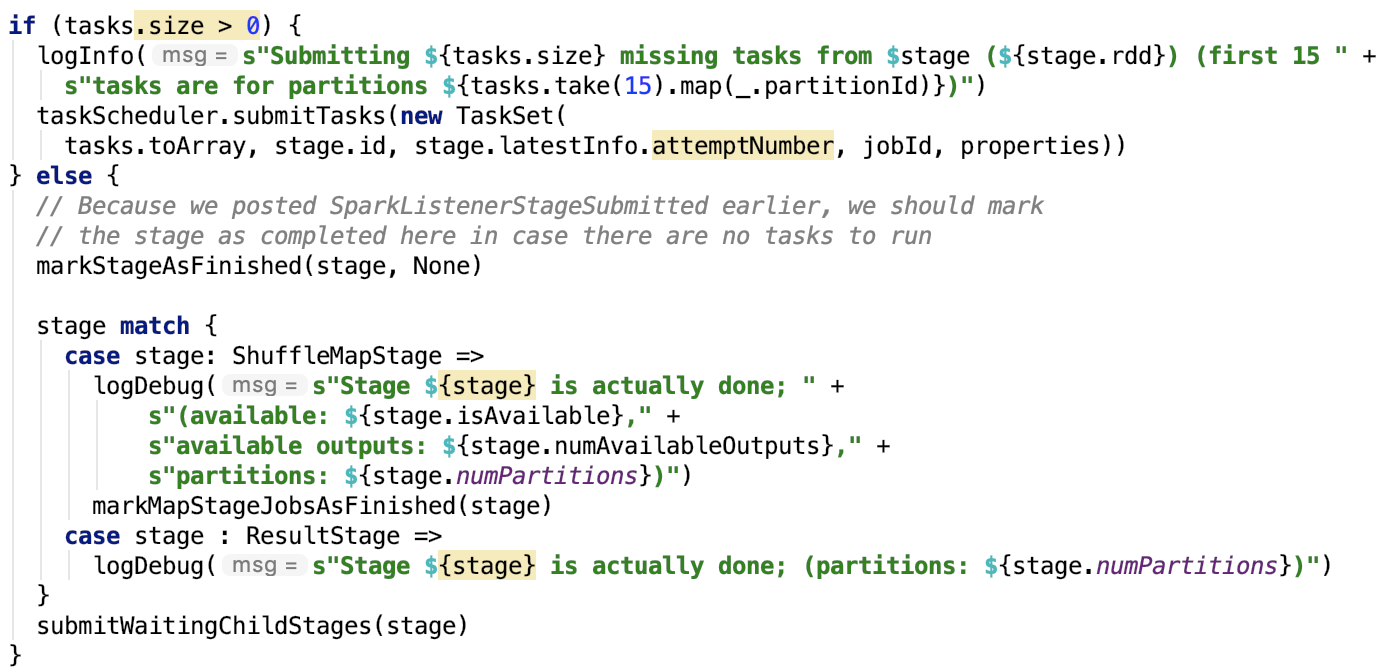
其中taskScheduler是 TaskSchedulerImpl,它是TaskScheduler的唯一子类实现。它负责task的调度。
org.apache.spark.scheduler.TaskSchedulerImpl#submitTasks方法实现如下:

其中 createTaskSetManager 方法如下:

关于更多TaskSetManager的内容,将在阶段四进行剖析。
backend是一个 SchedulerBackend 实例。在SparkContetx的初始化过程中调用 createTaskScheduler 初始化 backend,具体可以看 spark 源码分析之四 -- TaskScheduler的创建和启动过程 做深入了解。
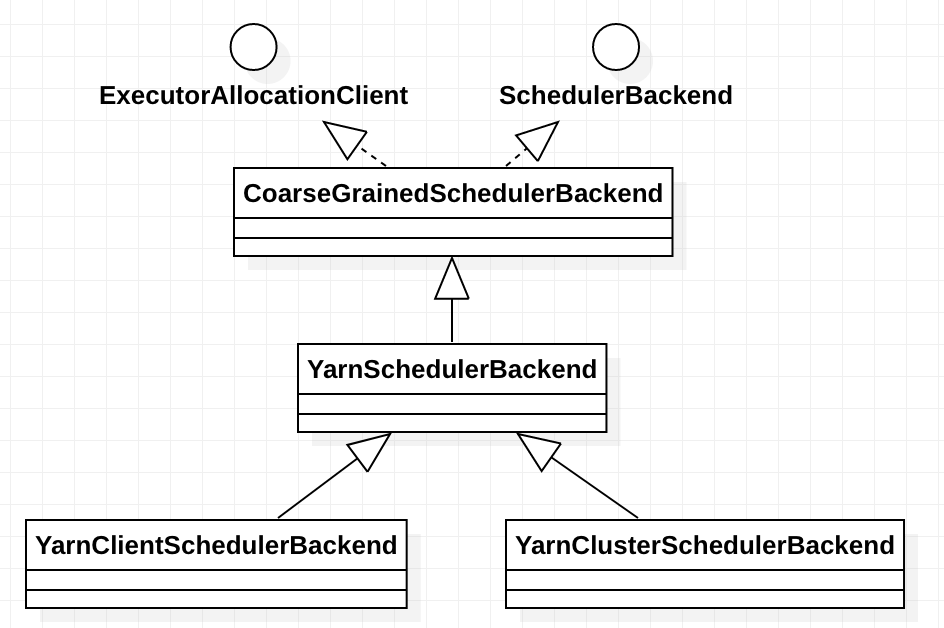
在yarn 模式下,它有两个实现yarn-client 模式下的 org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend实现 和 yarn-cluster 模式下的 org.apache.spark.scheduler.cluster.YarnClusterSchedulerBackend 实现。
这两个类在spark 项目的 resource-managers 目录下的 yarn 目录下定义实现,当然它也支持 kubernetes 和 mesos,不做过多说明。
这两个类的继承关系如下:
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#reviveOffers 实现如下:

发送ReviveOffers 请求给driver。
driver端的 CoarseGrainedSchedulerBackend 的 receive 方法有如下事件处理分支:

其内部经过一系列RPC过程,关于 RPC 可以看 spark 源码分析之十二--Spark RPC剖析之Spark RPC总结 做进一步了解。
即会调用driver端的makeOffsers方法,如下:

总结
本篇文章剖析了从DAGScheduler生成的Stage是如何被提交给TaskScheduler,以及TaskScheduler是如何把TaskSet提交给ResourceManager的。
下面就是task的运行部分了,下篇文章对其做详细介绍。跟task执行关系很密切的TaskSchedulerBackend、Task等内容,也将在下篇文章做更详细的说明。
spark 源码分析之十九 -- Stage的提交的更多相关文章
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析
spark 源码分析之十--Spark RPC剖析之TransportResponseHandler.TransportRequestHandler和TransportChannelHandler剖析 ...
- ABP源码分析二十九:ABP.MongoDb
这个Module通过建立一个MongoDbRepositoryBase<TEntity> 基类,封装了对MongoDb数据库的操作. 这个module通过引用MongoDB.Driver, ...
- ABP源码分析三十九:ABP.Hangfire
ABP对HangFire的集成主要是通过实现IBackgroundJobManager接口的HangfireBackgroundJobManager类完成的. HangfireBackgroundJo ...
- Vue.js 源码分析(二十九) 高级应用 transition-group组件 详解
对于过度动画如果要同时渲染整个列表时,可以使用transition-group组件. transition-group组件的props和transition组件类似,不同点是transition-gr ...
随机推荐
- Django预备知识
http协议 url: 协议://域名(IP)+端口(80)/路径?参数(a=1&b=2) 示例:https://www.baidu.com/s/?wd=aaa MVC M:mdoel 与数据 ...
- shell多线程之进程间通信(2)
工作中往往遇到这种情况,有许多任务,依次执行比较浪费时间,由于任务之间有依赖关系,简单的并发执行又不行. 就如同下面这种情况,任务new和dvidUser是可以并发执行的,fact任务依赖于new任务 ...
- 写在Logg SAP项目上线之际
根据大环境大行业的惯用做法,公司建立Logg品牌是在意料之中.毫无意外的,Logg也要上到SAP系统中. 其实按它的业务模式来说上SAP系统并不困难,早在几年前就已经有做过了.无非就是接单不生产,外包 ...
- centos 5.5版本中添加ext4格式
1.我在使用centos 5.5版本做练习的时候发现默认是不支持ext4文件格式. 在添加硬盘后,用fdisk -l 查看到信息如下: 分区完后,使用命令:mkfs -t ext4 /dev/sdb会 ...
- PWN菜鸡入门之栈溢出(1)
栈溢出 一.基本概念: 函数调用栈情况见链接 基本准备: bss段可执行检测: gef➤ b main Breakpoint at . gef➤ r Starting program: /mnt/ ...
- 给 Windows 的终端配置代理
初衷 由于项目开发使用go,所以经常要用到go get,但是吧,terminal下根本没办法下载啊,经常下载三个小时包,写代码一个小时 迫于无奈,只好找个方式可以在terminal下使用ss cmd下 ...
- 基于STM32F429和Cube的主从定时器多通道输出固定个数的PWM波形
主从定时器的原理已在上篇博文: 基于STM32F429+HAL库编写的定时器主从门控模式级联输出固定个数PWM脉冲的程序 讲解了,这篇重点就讲如何实现多通道的PWM级联输出. 1.软件环境 Keil5 ...
- php实现redis锁机制
<?php class Redis_lock { public static function getRedis() { $redis = new redis(); $redis->con ...
- Mac上PyCharm运行多进程报错的解决方案
Mac上PyCharm运行多进程报错的解决方案 运行时报错 may have been in progress in another thread when fork() was called. We ...
- Java并发之Semaphore和Exchanger工具类简单介绍
一.Semaphore介绍 Semaphore意思为信号量,是用来控制同时访问特定资源的线程数数量.它的本质上其实也是一个共享锁.Semaphore可以用于做流量控制,特别是公用资源有限的应用场景.例 ...