大数据学习之路之HBASE
Hadoop之HBASE
一、HBASE简介
HBase是一个开源的、分布式的,多版本的,面向列的,半结构化的NoSql数据库,提供高性能的随机读写结构化数据的能力。它可以直接使用本地文件系统,也可以使用Hadoop的HDFS文件存储系统。不过,为了提高数据的可靠性和系统的健壮性,并且发挥HBase处理大数据的能力,使用HDFS作为文件存储系统才更为稳妥。
HBase存储的数据从逻辑上来看就像一张很大的表,并且它的数据列可以根据需要动态地增加。除此之外,每个单元(cell,由行和列所确定的位置)中的数据又可以具有多个版本(通过时间戳来区别)。从下图可以看出,HBase还具有这样的特点:它向下提供了存储,向上提供了运算。另外,在HBase之上还可以使用Hadoop的MapReduce计算模型来并行处理大规模数据,这也是它具有强大性能的核心所在。它将数据存储与并行计算完美地结合在一起。
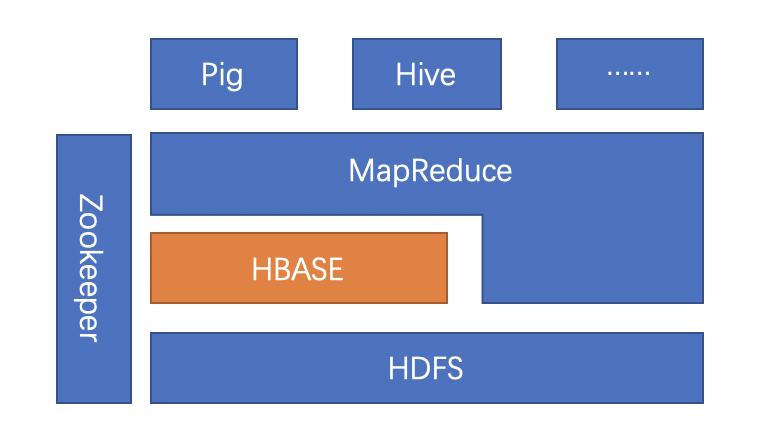
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找。 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
二、HBASE表结构
HBASE表具有以下特点:
大:一个表可以有上亿行,上百万列
面向列:面向列(族)的存储和权限控制,列(族)独立检索。
稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)。下面是HBASE表的逻辑视图:
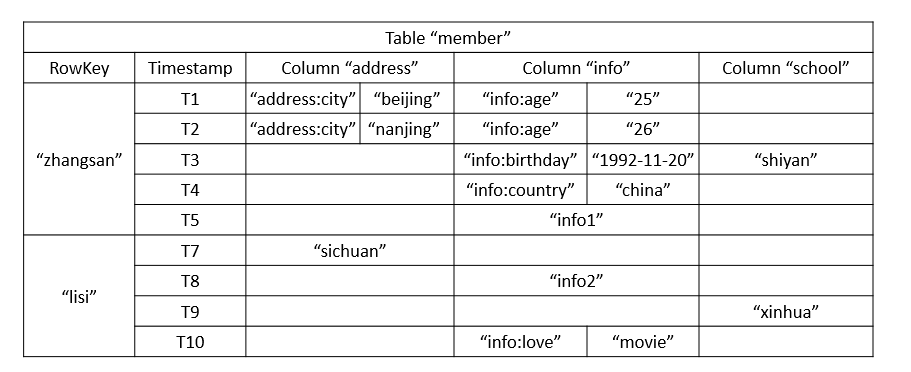
在shell客户端展示:
> scan 'member'
ROW COLUMN+CELL lisi column=address:, timestamp=1567757931802, value=sichuan lisi column=info:, timestamp=1567757982455, value=info2
lisi column=info:love, timestamp=1567758039091, value=movie lisi column=school:, timestamp=1567758005941, value=xinhua zhangsan column=address:city, timestamp=1567755403595, value=beijing zhangsan column=info:, timestamp=1567755827530, value=info1 zhangsan column=info:age, timestamp=1567756662127, value=26
zhangsan column=info:birthday, timestamp=1567755398376, value=1993-11-20 zhangsan column=info:country, timestamp=1567755402535, value=china zhangsan column=school:, timestamp=1567757294341, value=shiyan 2 row(s)
Took 0.0945 seconds
下面依次介绍这些结构:
- Row key:用来检索记录的主键,类似key-value结构的key。访问hbase table的行,只有三种方式:
- 通过单个row key访问;
- 通过row key的range;
- 全表扫描;
- 列族:hbase表中的每个列,都属于某个列族,列族属于表结构(必须在使用表之前定义),列不属于(插入数据的时候可以随时添加列),比如上面的info,address,school这些属于列族,info:age,info:love这些属于列。
- Cell:row key和列以及时间戳唯一确定的单元,用来存储真实的数据,cell中的数据没有类型,全部是字节码形式存储。
- 时间戳:每个cell中保存着同一份数据的多个版本,版本通过时间戳来索引。为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
三、安装运行HBASE
wget http://apache.01link.hk/hbase/2.2.0/hbase-2.2.0-bin.tar.gz
tar -zxvf hbase-2.2.0-bin.tar.gz
cd hbase-2.2.0
vim conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///tmp/hbase-${user.name}/hbase</value>
</property>
</configuration>
# 单机模式运行,使用的是本次文件存储。不依赖Hadoop
./bin/start-hbase.sh
# 查看进程
jps
9758 HMaster
# 启动成功后可以在 http://localhost:16010 访问hbase的web页面
# 停止Hbase服务
./bin/stop-hbase.sh
# 进入HBASE shell
./bin/hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.0, rUnknown, Tue Jun 11 04:30:30 UTC 2019
Took 0.0128 seconds
hbase(main):001:0>
四、shell DDL操作
# 建表
> create 'member','member_id','address','info'
Created table member
Took 1.6592 seconds
=> Hbase::Table - member
# 列出所有表
> list
TABLE
member
1 row(s)
Took 0.1501 seconds
=> ["member"]
# 列出表描述
> describe 'member'
Table member is ENABLED member COLUMN FAMILIES DESCRIPTION {NAME => 'address', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NO
NE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLO
CKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'info', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE'
, TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS
_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'member_id', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => '
NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_B
LOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
3 row(s)
QUOTAS
0 row(s)
Took 0.6478 seconds
# 删除一个列族,alter,disable,enable
> alter 'member',{NAME=>'member_id',METHOD=>'delete'}
# 在用describe 查看表会发现只有两个列族了
# 删除一个表,首先要先disable这个表
> disable 'member'
> drop 'member'
# 表是否存在
> exists 'member'
# 判断表是否enable
> is_enabled 'member'
# 判断表是否disable
> is_disabled 'member'
五、shell DML操作
# 插入数据
put'member','zhangsan','info:age','24'
put'member','zhangsan','info:birthday','1993-11-20'
put'member','zhangsan','info:country','china'
put'member','zhangsan','address:city','beijing'
put'member','lisi','info:birthday','1998-09-09'
put'member','lisi','info:favotite','movie'
put'member','lisi','address:city','beijing'
# 获取一个id的所有数据
> get'member','zhangsan'
COLUMN CELL address:city timestamp=1567754003312, value=beijing info:age timestamp=1567753903167, value=24 info:birthday timestamp=1567753950339, value=1993-11-20 info:country timestamp=1567753964169, value=china 1 row(s)
Took 0.1351 seconds
# 获取一个id,一个列族的所有数据
> get'member','zhangsan','info'
COLUMN CELL info:age timestamp=1567753903167, value=24 info:birthday timestamp=1567753950339, value=1993-11-20 info:country timestamp=1567753964169, value=china 1 row(s)
Took 0.0455 seconds
# 获取一个id,一个列族中一个列的所有数据
> get'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567753903167, value=24 1 row(s)
Took 0.0364 seconds
# 更新一条记录
> put'member','zhangsan','info:age','25'
> get'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567754315161, value=25 1 row(s)
Took 0.0491 seconds
# 通过timestamp来获取指定版本的数据
> get'member','zhangsan',{COLUMN=>'info:age',TIMESTAMP=>1567753903167}
COLUMN CELL info:age timestamp=1567753903167, value=24 1 row(s)
Took 0.0342 seconds
# 全表扫描
> scan 'member'
ROW COLUMN+CELL
lisi column=address:city, timestamp=1567754078391, value=beijing lisi column=info:birthday, timestamp=1567754038812, value=1998-09-09 lisi column=info:favotite, timestamp=1567754057750, value=movie zhangsan column=address:city, timestamp=1567754003312, value=beijing zhangsan column=info:age, timestamp=1567754315161, value=25 zhangsan column=info:birthday, timestamp=1567753950339, value=1993-11-20 zhangsan column=info:country, timestamp=1567753964169, value=china 2 row(s)
Took 0.1000 seconds
# 删除指定字段
> delete'member','zhangsan','info:age'
# 这个很有意思,如果有两个版本的数据,那么只会删除最新的一个版本,当再次查询的时候结果就是上一个版本的
> get'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567753903167, value=24 1 row(s)
Took 0.0454 seconds
# 再次执行delete就能把当前版本删除
> delete'member','zhangsan','info:age'
> get'member','zhangsan','info:age'
COLUMN CELL 0 row(s)
Took 0.0166 seconds
# 删除整行
> deleteall'member','lisi'
Took 0.0235 seconds
# 查询表中有多少行
> count'member'
1 row(s)
Took 0.3753 seconds => 1
# 给"zhangsan"这个id增加'info:age'字段,并使用counter实现递增
> incr 'member','zhangsan','info:age'
COUNTER VALUE = 1
Took 0.0948 seconds
> get 'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567755056584, value=\x00\x00\x00\x00\x00\x00\x00\x01 1 row(s)
Took 0.0504 seconds
> incr 'member','zhangsan','info:age'
COUNTER VALUE = 2
Took 0.0211 seconds
> get 'member','zhangsan','info:age'
COLUMN CELL info:age timestamp=1567755133527, value=\x00\x00\x00\x00\x00\x00\x00\x02 1 row(s)
Took 0.0479 seconds
# 获取当前count的值
> get_counter'member','zhangsan','info:age'
COUNTER VALUE = 2
Took 0.0145 seconds
# 清空整张表
> truncate 'member'
Truncating 'member' table (it may take a while):
Disabling table...
Truncating table...
Took 2.1687 seconds
# 如何查看多个版本的数据,首先需要更新表结构,因为默认只保存一个版本数据,我们将保存的版本数设置为3
> alter'member',{NAME=>'info',VERSIONS=>3}
> put'member','zhangsan','info:age','26'
> scan 'member',{COLUMN=>'info:age',VERSIONS=>3}
ROW COLUMN+CELL zhangsan column=info:age, timestamp=1567756662127, value=26 zhangsan column=info:age, timestamp=1567756297089, value=25 1 row(s)
Took 0.0361 seconds
> get 'member','zhangsan',{COLUMN=>'info',VERSIONS=>3}
COLUMN CELL info: timestamp=1567755827530, value=info1 info:age timestamp=1567756662127, value=26 info:age timestamp=1567756297089, value=25 info:birthday timestamp=1567755398376, value=1993-11-20 info:country timestamp=1567755402535, value=china 1 row(s)
Took 0.0622 seconds
六、遇到的问题
问题1:
运行hbase shell时报错:
./bin/hbase shell
2019-09-06 11:03:21,079 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.0, rUnknown, Tue Jun 11 04:30:30 UTC 2019
Took 0.0080 seconds
NotImplementedError: fstat unimplemented unsupported or native support failed to load; see http://wiki.jruby.org/Native-Libraries
initialize at org/jruby/RubyIO.java:1013
open at org/jruby/RubyIO.java:1154
initialize at uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/irb/input-method.rb:141
initialize at uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/irb/context.rb:70
initialize at uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/irb.rb:426
initialize at /home/wangjun/software/hbase-2.2.0/lib/ruby/irb/hirb.rb:47
start at /home/wangjun/software/hbase-2.2.0/bin/../bin/hirb.rb:207
<main> at /home/wangjun/software/hbase-2.2.0/bin/../bin/hirb.rb:219
解决方案:
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable这个问题只需要修改conf/hbase-env.sh,加入:
export LD_LIBRARY_PATH=${hadoop_home}/lib/native:$LD_LIBRARY_PATH
${hadoop_home}为你的hadoop的安装路径。
NotImplementedError: fstat unimplemented unsupported or native support failed to load这个问题的解决方案:
sudo apt-get install jruby -y
sudo apt-get install asciidoctor -y
参考:
大数据学习之路之HBASE的更多相关文章
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习之路又之从小白到用sqoop导出数据
写这篇文章的目的是总结自己学习大数据的经验,以为自己走了很多弯路,从迷茫到清晰,真的花费了很多时间,希望这篇文章能帮助到后面学习的人. 一.配置思路 安装linux虚拟机--->创建三台虚拟机- ...
- 大数据学习之路------借助HDP SANDBOX开始学习
一开始... 一开始知道大数据这个概念的时候,只是感觉很高大上,引起了我的兴趣.当时也不知道,这个东西是做什么的,有什么用,当然现在看来也是很模糊的样子,但是的确比一开始强了不少. 所以学习的过程可能 ...
- 大数据学习(13)—— HBase入门
从这一篇起,开始介绍HBase相关知识.还是一样,大数据的学习,获取官网知识很重要.官网看这里Apache HBase HBase简介 Apache HBase is the Hadoop datab ...
- 大数据学习之路(1)Hadoop生态体系结构
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN. Hadoop1.x的生态系统: Hadoop2.x引入YARN: HDFS(Hadoop分布式文件系统)源自于Go ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习(14)—— HBase进阶
HBase读写流程 在网上找了一张图,这个画的比较简单,就拿这个图来说吧. 写流程 1.当Client发起一个Put请求时,首先访问Zookeeper获取hbase:meta表. 2.从hbase:m ...
- 大数据学习(17)—— HBase表设计
为啥要把表设计拿出来独立成章?因为我觉得像我这样搞了很多年Java后端开发的技术人员,在学习HBase的时候,会受到关系型数据库3NF.BCNF的影响.事实上,数据库范式在HBase里完全没用,必须转 ...
- 大数据学习系列之二 ----- HBase环境搭建(单机)
引言 在上一篇中搭建了Hadoop的单机环境,这一篇则搭建HBase的单机环境 环境准备 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内 ...
随机推荐
- iOS 关键词assign、strong、copy、weak、unsafe_unretained
关键词assign.strong.copy.weak.unsafe_unretained 影响: 是否开辟新的内存 是否有引用计数增加 strong 指向并拥有该对象.其修饰的对象引用计数会 +1,该 ...
- FastDFS+Nginx搭建Java分布式文件系统
一.FastDFS FastDFS是用c语言编写的一款开源的分布式文件系统.FastDFS为互联网量身定制,充分考虑了冗余备份.负载均衡.线性扩容等机制,并注重高可用.高性能等指标,使用FastDFS ...
- 关于SqlServer数据库数据备份失败的问题
当备份的失败,出现说什么应该支持多少个介质簇,但实际出现了多少介质簇,这个时候就要考虑备份的地址是不是出现问题. 首先,检查备份地址,是不是多于两个以上,那么在备份的时候应该注意,备份地址最好留一个, ...
- MySQL Index--CREATE INDEX在各版本的优化
FIC(Fast index creation)特性在MySQL 5.5版本中引入FIC(Fast index creation)特性,创建索引时无需再拷贝整表数据,以提升索引的创建速度. FCI 操 ...
- mac 下enable mysql的load data in file
1)使用root用户登录mysql 2)将 local_infile 变量设置为true SET GLOBAL local_infile = true; 3)重启数据库 在系统偏好设置中找到MySql ...
- 为群晖加把锁:使用ssh密钥保障数据安全
对每一个使用群晖nas的人而言,能保证群晖里保存的数据不被未经授权的人访问下载甚至破坏可能是最重要的事情.但数据只要上网,就免不了担心密码被破解,群晖被侵入.现在网络上,要破解密码可能是最简单不过的事 ...
- Web前端面试图
文章:记一次腾讯微信面试 先是看简历上写的项目经验,问一上些项目上的问题,比如如何编写 js-sdk, 如何去修改 weui 库,遇到最大的难题是什么及如何去解决的. 数组去重的方法有哪些? 如何判断 ...
- 《你说对就队》第九次团队作业:【Beta】Scrum meeting 2
<你说对就队>第九次团队作业:[Beta]Scrum meeting 2 项目 内容 这个作业属于哪个课程 [教师博客主页链接] 这个作业的要求在哪里 [作业链接地址] 团队名称 < ...
- Follow My Heart
看到这个题目,能够让我不断跟随自己的心去奋斗,当然在这之中也有过彷徨,有过偷懒,但最终还是依然坚强,依然保持着一种积极向上的心情去迎接每一天. 这一年从大三升到大四,瞬间觉得自己成长了很多,身上的责任 ...
- Redis 中的高级数据类型
5个基础数据类型 高级功能 ① HyperLogLog (参考) 供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV > PFADD visitors alice bob ...