BERT模型
BERT模型是什么
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
1.1 模型结构
由于模型的构成元素Transformer已经解析过,就不多说了,BERT模型的结构如下图最左:
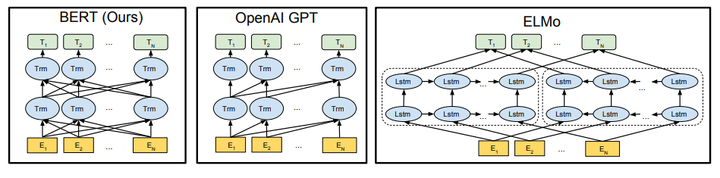
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
1.2 Embedding
这里的Embedding由三种Embedding求和而成:
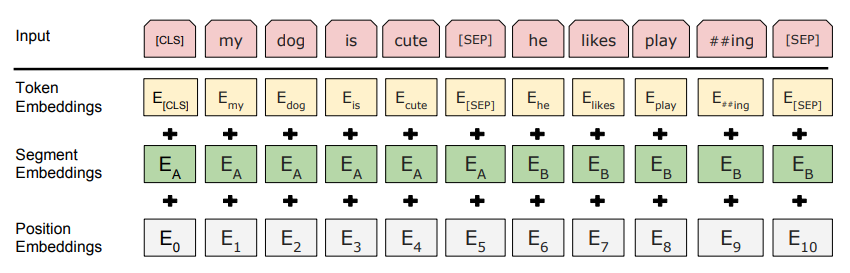
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
1.3 Pre-training Task 1#: Masked LM
第一步预训练的目标就是做语言模型,从上文模型结构中看到了这个模型的不同,即bidirectional。关于为什么要如此的bidirectional,作者在reddit上做了解释,意思就是如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。而考虑到这点的模型ELMo只是将left-to-right和right-to-left分别训练拼接起来。直觉上来讲我们其实想要一个deeply bidirectional的模型,但是普通的LM又无法做到,因为在训练时可能会“穿越”(关于这点我不是很认同,之后会发文章讲一下如何做bidirectional LM)。所以作者用了一个加mask的trick。
在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。具体为什么这么分配,作者没有说。。。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
1.4 Pre-training Task 2#: Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。
注意:作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
1.5 Fine-tunning
分类:对于sequence-level的分类任务,BERT直接取第一个[CLS]token的final hidden state ,加一层权重
后softmax预测label proba:
其他预测任务需要进行一些调整,如图:
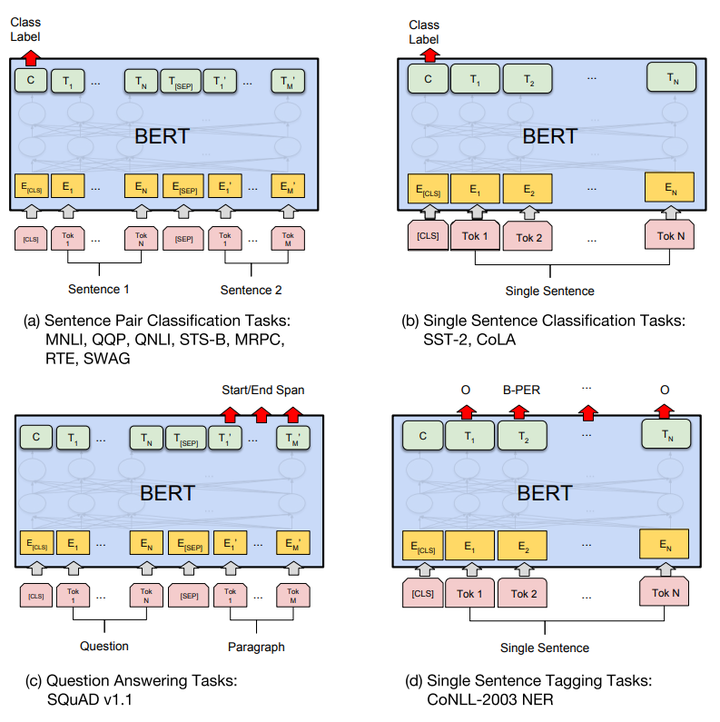
可以调整的参数和取值范围有:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
因为大部分参数都和预训练时一样,精调会快一些,所以作者推荐多试一些参数。
2. 优缺点
2.1 优点
BERT是截至2018年10月的最新state of the art模型,通过预训练和精调横扫了11项NLP任务,这首先就是最大的优点了。而且它还用的是Transformer,也就是相对rnn更加高效、能捕捉更长距离的依赖。对比起之前的预训练模型,它捕捉到的是真正意义上的bidirectional context信息。
2.2 缺点
作者在文中主要提到的就是MLM预训练时的mask问题:
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
3. 总结
一遍读下来,感觉用到的都是现有的东西,可没想到效果会这么好,而别人又没想到。不过文章中没有具体解释的很多点可以看出这样出色的结果也是通过不断地实验得出的,而且训练的数据也比差不多结构的OpenAI GPT多,所以数据、模型结构,都是不可或缺的东西。
以上。
转载自:Google BERT详解
BERT模型的更多相关文章
- BERT模型在多类别文本分类时的precision, recall, f1值的计算
BERT预训练模型在诸多NLP任务中都取得最优的结果.在处理文本分类问题时,即可以直接用BERT模型作为文本分类的模型,也可以将BERT模型的最后层输出的结果作为word embedding导入到我们 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- BERT模型介绍
前不久,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步.BERT模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 图示详解BERT模型的输入与输出
一.BERT整体结构 BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务.整体架 ...
- bert模型参数简化
我们下载下来的预训练的bert模型的大小大概是400M左右,但是我们自己预训练的bert模型,或者是我们在开源的bert模型上fine-tuning之后的模型的大小大约是1.1G,我们来看看到底是什么 ...
- 使用BERT模型生成句子序列向量
之前我写过一篇文章,利用bert来生成token级向量(对于中文语料来说就是字级别向量),参考我的文章:<使用BERT模型生成token级向量>.但是这样做有一个致命的缺点就是字符序列长度 ...
随机推荐
- MybatisGenerator生成SSM的dao层
官网下载 mybatis generator 下载generator的release版本mybatis-generator-core-1.4.0-bundle.zip https://github.c ...
- JavaScript 之 navigator 对象
navigator 对象可以查看用户所使用的浏览器类型和系统平台类型. 1.userAgent 通过 userAgent 可以判断用户浏览器的类型. Chrome 浏览器效果: 2.platform ...
- HTML-Parser
背景:需求需要把 html 字符串转成 DOM 对象树或者 js 对象树,然后进行一些处理/操作.htmlparser 这个库还行,但是对 attribute 上一些特殊属性值转换不行,同时看了看`开 ...
- Spring cloud架构中利用zuul网关实现灰度发布功能
蓝绿发布.金丝雀发布(灰度发布).AB测试 首先,了解下这几种发布方式的基础概念. 目前常见的发布策略有蓝绿发布.金丝雀发布(灰度发布).AB测试这几种,在国内的开发者中,对这几个概念有独立的理解.蓝 ...
- 数据结构中的堆(Heap)
堆排序总结 这是排序,不是查找!!!查找去找二叉排序树等. 满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树. 构建顶堆: a.构造初始堆 b.从最后一层非叶节点开始调整,一直到根节点 c.如果 ...
- ANDROID - 打包和引用本地的AAR
打包方法: 打开Gradle面板 Gradle Projects: 选择Library对应的Gradle Task,比如:":testsdk": 依次 Tasks > ...
- Java8的Stream API使用
前言 这次想介绍一下Java Stream的API使用,最近在做一个新的项目,然后终于可以从老项目的祖传代码坑里跳出来了.项目用公司自己的框架搭建完成后,我就想着把JDK版本也升级一下吧(之前的项目, ...
- 《剑指Offer》-006 - Java版快速幂 -解决n的m次方的问题
#### 如题 (总结要点) 原文链接 : 1.主题 package blank; /** * 类的详细说明 给定一个double类型的浮点数base和int类型的整数exponent.求base的e ...
- web渗透—xss攻击如何防御
1.基于特征的防御 XSS漏洞和著名的SQL注入漏洞一样,都是利用了Web页面的编写不完善,所以每一个漏洞所利用和针对的弱点都不尽相同.这就给XSS漏洞防御带来了困难:不可能以单一特征来概括所有XSS ...
- Gradle 学习资料
Gradle 学习资料 网址 Gradle 使用指南 http://wiki.jikexueyuan.com/project/gradle/ 寄Android开发Gradle你需要知道的知识 http ...