【转帖】Storm基本原理概念及基本使用
Storm基本原理概念及基本使用
https://www.cnblogs.com/swordfall/p/8821453.html
1. 背景介绍
1.1 离线计算是什么
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示;
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据
1.2 流式计算是什么
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果
1.3 Storm是什么
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
1.4 Storm与Hadoop的区别
1. Storm用于实时计算,Hadoop用于离线计算;
2. Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批;
3. Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中;
4. Storm与Hadoop的编程模型相似;
2. Storm核心组件
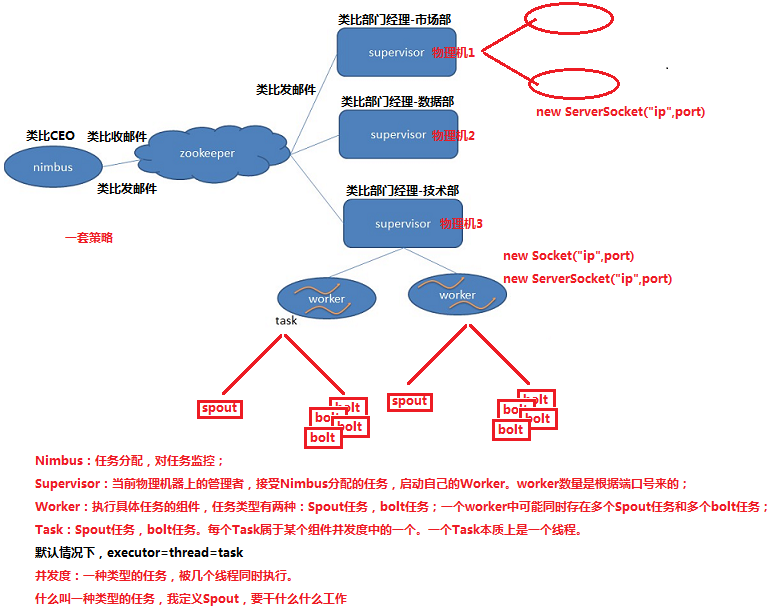
组件说明补充:
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程(其实就是一个JVM)。Worker运行的任务类型只用两种,一种是Spout任务,一种是Bolt任务。
Task:worker中每一个spout/bolt的线程称为一个task。在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
Zookeeper:保存任务分配信息、心跳信息、元数据信息。
并发度:用户指定的一个任务,可以被多个线程执行,并发度的数量等于线程的数量。一个任务的多个线程,会被运行在多个Worker(JVM)上,有一种类似于平均算法的负载均衡策略。尽可能减少网络IO,和Hadoop中的MapReduce中的本地计算的道理一样。
3. Storm编程模型

组件说明补充:
DataSource:外部数据源。
Spout:接收外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt。
Bolt:接收Spout发送的数据,或上游的Bolt发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是Redis,可以是Mysql,或者其他。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略。7种,shuffleGrouping(Random函数)、Non Grouping(Random函数)、FieldGrouping(Hash取模)、Local or ShuffleGrouping、本地或随机、优先本地。
Worker与Topology
一个worker只属于一个topology,每个worker中运行的task只能属于这个topology。反之,一个topology包含多个worker,其实就是这个topology运行在多个worker上。一个topology要求的worker数量如果不被满足,集群在任务分配时,根据现有的worker先运行topology。如果当前集群中worker数量为0,那么最新提交的topology将只会被标识active,不会运行。只有当集群有了空闲资源之后,才会被运行。
4. Storm常用操作命令
storm有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。
4.1 提交任务命令
storm jar 【jar路径】【拓扑包名.拓扑类名】【拓扑名称】
storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
4.2 杀死任务命令
storm kill 【拓扑名称】 -w 10 (执行kill命令时可以通过-w [等待秒数] 指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
4.3 停用任务命令
storm deactivte 【拓扑名称】
storm deactivte topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
4.4 启用任务命令
storm activate 【拓扑名称】
storm activate topology-name
4.5 重新部署任务命令
storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重新分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重新分配工人,并重启拓扑。
【转帖】Storm基本原理概念及基本使用的更多相关文章
- Storm基本原理概念及基本使用
1. 背景介绍 1.1 离线计算是什么 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示: 代表技术:Sqoop批量导入数据.HDFS批量存储数据.MapReduce批量计算数据.H ...
- 【原】Storm基本概念
Storm入门教程 1. Storm基础 Storm Storm主要特点 Storm基本概念 Topologies Streams Spouts Bolts Stream groupings Reli ...
- Storm基础概念与单词统计示例
Storm基本概念 Storm是一个分布式的.可靠地.容错的数据流处理系统.Storm分布式计算结构称为Topology(拓扑)结构,顾名思义,与拓扑图十分类似.该拓扑图主要由数据流Stream.数据 ...
- Storm 01之 Storm基本概念及第一个demo
2.1 Storm基本概念 在运行一个Storm任务之前,需要了解一些概念: Topologies :[tə'pɑ:lədʒɪ]拓扑结构 Streams Spouts:[spaʊt]喷出; 喷射; 滔 ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- Storm 系列(二)—— Storm 核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑).它是一个是由 Spouts 和 Bolts 通过 Stre ...
- apache storm基本原理及使用总结
什么是Apache Storm Apache Storm是一个分布式实时大数据处理系统.Storm设计用于在容错和水平可扩展方法中处理大量数据.它是一个流数据框架,具有最高的摄取率.虽然Storm是无 ...
- 对CLR基本原理概念&垃圾回收机制的简单理解
前言,之前有说过C语言的函数&变量的一些基本概念,说得可能不是很好,先也把C#的.里相关的也说下,已成一统. 而说函数变量,其实主要就是GC,而GC又是CLR的主要内容,故就有了此文. CLR ...
- storm - 基础概念整理
理论 Hadoop的出现虽然为大数据计算提供了一条捷径,但其仍然存在自身难以克服的缺点:实时性不足.Hadoop的一轮计算的启动需要较长时间,因此其满足不了对实时性有较高要求的场景. Storm由此应 ...
随机推荐
- this(this的4种指向和改变this指向的方式)
this是Javascript语言的一个关键字. 随着函数使用场合的不同,this的值会发生变化.但是有一个总的原则,那就是this指的是,调用函数的那个对象. 1.this指向的形式4种 a.如果是 ...
- MYSQL的修改表结构SQL语句
更多java学习资料>>> 1.背景 使用sql语句对表结构进行修改 2.案例演示 案例:表结构 CREATE TABLE `login_user` ( `id` ) NOT NUL ...
- navicat mysql 书写存储过程并导出成sql
navicat创建存储过程: 选中该数据库 然后完成,保存的时候出错: 需要为字段类型添加类型的大小.下面加一下. 然后就在这里面写相关的业务代码了. 语句结尾需要加上分号; .否则会报错. 这边展 ...
- Reactive-MongoDB 异步 Java Driver 解读
一.关于 异步驱动 从3.0 版本开始,MongoDB 开始提供异步方式的驱动(Java Async Driver),这为应用提供了一种更高性能的选择.但实质上,使用同步驱动(Java Sync Dr ...
- sqlldr导入数据取消回显记录条数
之前在脚本中使用sqlldr导入数据时,如果表的数据量较大的话,会使日志文件变得极大,之后在网上查找了很久,才在一个偶然的机会找到这个参数 silent=all 但是最近发现这样写有个问题,就是加了这 ...
- PCI_PCIe_miniPCIe规格说明
PCI PCI是一种本地总线(并行),规格书名称:PCI Local Bus Specification.并行总线,插槽规格统一. PCI stands for Peripheral Componen ...
- Sigmoid函数与Softmax函数的理解
1. Sigmod 函数 1.1 函数性质以及优点 其实logistic函数也就是经常说的sigmoid函数,它的几何形状也就是一条sigmoid曲线(S型曲线). 其中z ...
- 使用 python set 去重 速度到底是多快呢???
这次去测试一下 python 的set去重,速度怎么样? 我们要做的是把文件一次性读取到内存中,然后去重,输出去重的长度. 第一步:对 121w 条数据去重,看去重话费的时间 上证据: 第二步:对 1 ...
- 洛谷P1192-台阶问题(线性递推 扩展斐波那契)
占坑 先贴上AC代码 回头来补坑 #include <iostream> using namespace std; int n, k; const int mod = 100003; lo ...
- js 浮点数计算精度不准确问题
或许很多人都遇到过,js 对小数的加.减.乘.除时经常得到一些奇怪的结果! 比如 :0.1 + 0.2 = 0.3 ? 这么一个简单的计算,当你用js 计算时会发现结果是:0.30000000000 ...