Ranger安装部署 - solr安装
1. 概述
Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库;
Solr是以Lucene为基础实现的文本检索应用服务。Solr部署方式有单机方式、Cloud方式。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案。当索引越来越大,一个单一的系统无法满足磁盘需求,查询速度缓慢,此时就需要分布式索引。在分布式索引中,原来的大索引,将会分成多个小索引,solr可以将这些小索引返回的结果合并,然后返回给客户端。
solr安装,目前是作为Ranger审计日志的存储,故这里使用的是Ranger-admin里面存在的solr便捷安装方式,可以通过配置文件来直接配置,一键部署。
ranger solr的便捷式安装来源,首先需要编译ranger,可以参考https://www.cnblogs.com/swordfall/p/11887317.html
2. 单机Standalone安装
2.1 修改install.properties文件
# pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin/contrib/solr_for_audit_setup
# vim install.properties
配置java home路径
JAVA_HOME=/usr/lib/java/jdk1..0_151
审计日志保存的最大天数,默认为90天
MAX_AUDIT_RETENTION_DAYS=90
false改为true
SOLR_INSTALL=true solr线上下载路径
SOLR_DOWNLOAD_URL=http://archive.apache.org/dist/lucene/solr/8.3.0/solr-8.3.0.tgz solr安装目录
SOLR_INSTALL_FOLDER=/opt/app/ranger-solr-8.3.-simple
solr对接ranger的服务
SOLR_RANGER_HOME=/opt/app/ranger-solr-8.3.0-simple/ranger_audit_server
solr连接ranger的端口
SOLR_RANGER_PORT= solr部署模式
SOLR_DEPLOYMENT=standalone solr数据存储目录
SOLR_RANGER_DATA_FOLDER=/opt/app/ranger-solr-8.3.-simple/ranger_audit_server/data solr单机部署,故为空
SOLR_ZK=
2.2 初始化solr安装脚本
# pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin/contrib/solr_for_audit_setup
# ./setup.sh
初始化结果如下,表明成功:

启动单机版solr
# pwd
/opt/app/ranger-solr-8.3.-simple/ranger_audit_server/scripts
# ./start_solr.sh
启动结果如下,则表明成功:

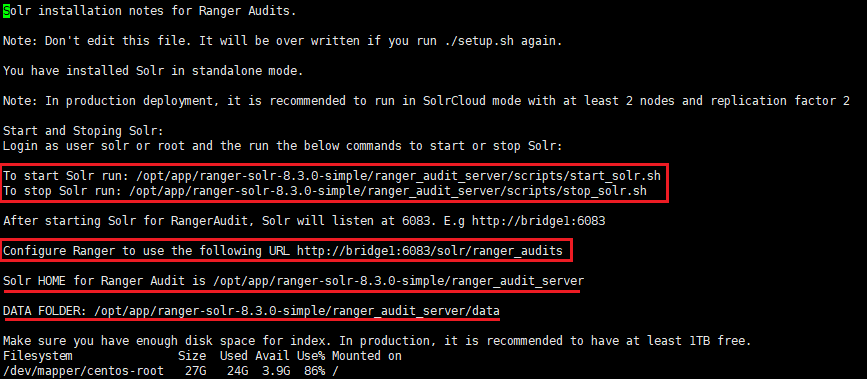
注:具体操作可以查看如下文件
# pwd
/opt/app/ranger-solr-8.3.-simple/ranger_audit_server
# vim install_notes.txt
2.3 修改ranger-admin install.properties文件
# pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin
# vim install.properties
审计日志存储为solr
audit_store=solr audit_solr_urls=http://bridge1:6083/solr/ranger_audits
audit_solr_user=
audit_solr_password=
audit_solr_zookeepers=
重新初始化ranger-admin,并重启
# ranger-admin stop
Getting pid from /var/run/ranger/rangeradmin.pid ..
Found Apache Ranger Admin Service with pid , Stopping it...
Apache Ranger Admin Service with pid has been stopped. # pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin
# ./setup.sh # ranger-admin start
Starting Apache Ranger Admin Service
Apache Ranger Admin Service with pid has started.
查看单机版solr是否已经集成到ranger-admin里面,右上角没报错,则已经集成到ranger-admin。

3. SolrCloud安装
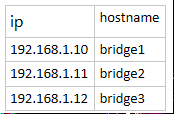
3.1 机器准备
solrcloud至少需要三台机器
3.2 修改install.properties文件
# pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin/contrib/solr_for_audit_setup
# vim install.properties
配置java home路径
JAVA_HOME=/usr/lib/java/jdk1..0_151
审计日志保存的最大天数,默认为90天
MAX_AUDIT_RETENTION_DAYS=90
false改为true
SOLR_INSTALL=true solr线上下载路径
SOLR_DOWNLOAD_URL=http://archive.apache.org/dist/lucene/solr/8.3.0/solr-8.3.0.tgz solr安装目录
SOLR_INSTALL_FOLDER=/opt/app/ranger-solr-8.3.-cloud solr对接ranger的服务
SOLR_RANGER_HOME=/opt/app/ranger-solr-8.3.-cloud/ranger_audit_server solr连接ranger的端口
SOLR_RANGER_PORT= solr部署模式
SOLR_DEPLOYMENT=solrcloud solr数据存储目录
SOLR_RANGER_DATA_FOLDER=/opt/app/ranger-solr-8.3.-cloud/ranger_audit_server/data solrcloud在zookeeper上的路径
SOLR_ZK=bridge1:,bridge2:,bridge3:/ranger_audits ranger连接solr的路径,${SOLR_RANGER_PORT}需要改为6083,与上面的SOLR_RANGER_PORT值一样
SOLR_HOST_URL=http://`hostname -f`:6083
3.3 初始化solr安装脚本
# pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin/contrib/solr_for_audit_setup
# ./setup.sh
初始化结果如下,表明成功:

3.4 solr审计日志保存时间配置
审计日志保存时间,可以根据3.2 修改install.properties文件的MAX_AUDIT_RETENTION_DAYS,进行保存时间的调整。
最终审计日志保存时间是保存在solrconfig.xml文件,文件路径为/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server/conf,并把sorlconfig.xml文件更新到zookeeper上。solrconfig.xml配置文件内容为:
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema">
<processor class="solr.DefaultValueUpdateProcessorFactory">
<str name="fieldName">_ttl_</str>
<str name="value">+90DAYS</str>
</processor>
<processor class="solr.processor.DocExpirationUpdateProcessorFactory">
<int name="autoDeletePeriodSeconds">86400</int>
<str name="ttlFieldName">_ttl_</str>
<str name="expirationFieldName">_expire_at_</str>
</processor>
<processor class="solr.FirstFieldValueUpdateProcessorFactory">
<str name="fieldName">_expire_at_</str>
</processor> <processor class="solr.RemoveBlankFieldUpdateProcessorFactory"/>
<processor class="solr.ParseBooleanFieldUpdateProcessorFactory"/>
<processor class="solr.ParseLongFieldUpdateProcessorFactory"/>
<processor class="solr.ParseDoubleFieldUpdateProcessorFactory"/>
<processor class="solr.ParseDateFieldUpdateProcessorFactory">
<arr name="format">
<str>yyyy-MM-dd'T'HH:mm:ss.SSSZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss,SSSZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss.SSS</str>
<str>yyyy-MM-dd'T'HH:mm:ss,SSS</str>
<str>yyyy-MM-dd'T'HH:mm:ssZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss</str>
<str>yyyy-MM-dd'T'HH:mmZ</str>
<str>yyyy-MM-dd'T'HH:mm</str>
<str>yyyy-MM-dd HH:mm:ss.SSSZ</str>
<str>yyyy-MM-dd HH:mm:ss,SSSZ</str>
<str>yyyy-MM-dd HH:mm:ss.SSS</str>
<str>yyyy-MM-dd HH:mm:ss,SSS</str>
<str>yyyy-MM-dd HH:mm:ssZ</str>
<str>yyyy-MM-dd HH:mm:ss</str>
<str>yyyy-MM-dd HH:mmZ</str>
<str>yyyy-MM-dd HH:mm</str>
<str>yyyy-MM-dd</str>
</arr>
</processor>
<processor class="solr.AddSchemaFieldsUpdateProcessorFactory">
<str name="defaultFieldType">key_lower_case</str>
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">boolean</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.util.Date</str>
<str name="fieldType">tdate</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Long</str>
<str name="valueClass">java.lang.Integer</str>
<str name="fieldType">tlong</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Number</str>
<str name="fieldType">tdouble</str>
</lst>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>
解析:
- solr.DefaultValueUpdateProcessorFactory 属性_ttl_的value,可以控制审计日志的过期时间,当前默认是90天后过期;该配置项支持配置的参数可以是+10DAYS, +2WEEKS,+4HOURS,+1MINUTE等等。
- autoDeletePeriodSeconds ,是执行扫描过期数据的定时任务的运行周期,当前默认是86400s,即1天运行一次定时任务,该参数的时间应该小于参数DefaultValueUpdateProcessorFactory配置的时间,从而保证过期的数据能够被及时删除。
- FirstFieldValueUpdateProcessorFactory 的属性_expire_at_是数据的过期时间字段名称。
3.5 远程拷贝ranger-solr-8.3.0-cloud到其他机器
# pwd
/opt/app
# scp -r ranger-solr-8.3.-cloud/ root@bridge2:/opt/app/
# scp -r ranger-solr-8.3.-cloud/ root@bridge3:/opt/app/
3.6 启动ranger-solr-8.3.0-cloud
首先,分别在三台机器启动zookeeper,zookeeper安装,参考https://www.cnblogs.com/swordfall/p/8667409.html
# pwd
/opt/app/zookeeper-3.4./bin
# ./zkServer.sh start
然后,在三台机器分别执行如下命令,创建/var/log/solr/ranger_audits,并赋予solr/solr 用户名、用户组,否则启动solrcloud会报错。紧接着,在其中一台机器执行add_ranger_audits_conf_to_zk.sh文件,使solrcloud与zookeeper关联上。
# mkdir -p /var/log/solr/ranger_audits
# chown solr:solr /var/log/solr/ranger_audits # pwd
/opt/app/ranger-solr-8.3.-cloud/ranger_audit_server/scripts
# ./add_ranger_audits_conf_to_zk.sh
再接着,在三台机器下分别启动solrcloud
pwd
/opt/app/ranger-solr-8.3.-cloud/ranger_audit_server/scripts
# ./start_solr.sh
最后,在其中一台机器执行create_ranger_audits_collection.sh文件,在zookeeper上创建ranger_audits集合
# pwd
/opt/app/ranger-solr-8.3.-cloud/ranger_audit_server/scripts
# ./create_ranger_audits_collection.sh

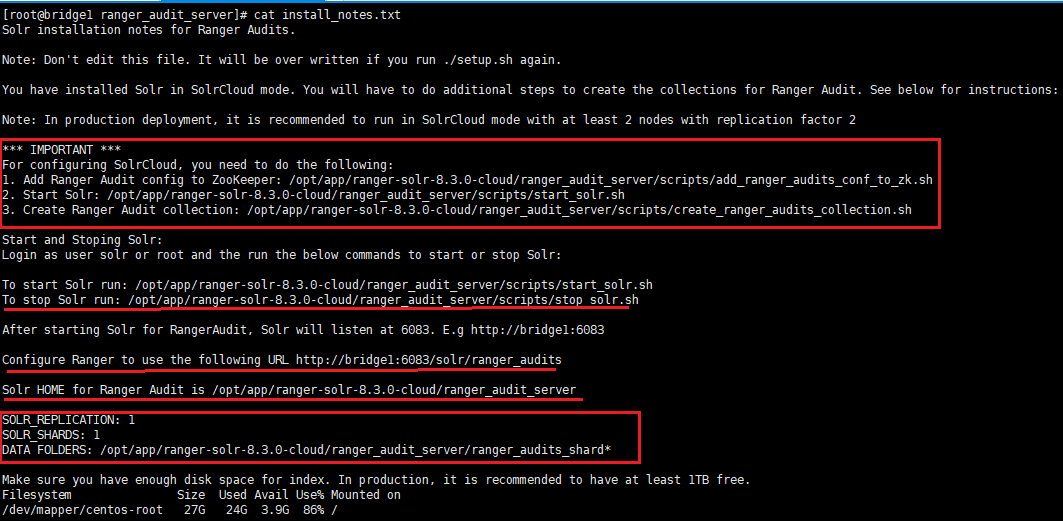
最后的最后,启动结果如下,则表明成功:
注:具体操作可以查看如下文件
# pwd
/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server
# vim install_notes.txt
3.7 修改ranger-admin install.properties文件
# pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin
# vim install.properties
审计日志存储为solr
audit_store=solr audit_solr_urls=http://bridge1:6083/solr/ranger_audits
audit_solr_user=
audit_solr_password=
audit_solr_zookeepers=bridge1:,bridge2:,bridge3:/ranger_audits
重新初始化ranger-admin,并重启
# ranger-admin stop
Apache Ranger Admin Service is not running # pwd
/opt/app/apache-ranger-2.0./target/ranger-2.0.-admin
# ./setup.sh # ranger-admin start
Starting Apache Ranger Admin Service
Apache Ranger Admin Service with pid has started
查看集群版solrcloud是否已经集成到ranger-admin里面,右上角没报错,则已经集成到ranger-admin。
总结
【参考资料】
https://segmentfault.com/a/1190000010836061#item-1
https://www.cnblogs.com/hellxz/p/7434588.html
https://www.cnblogs.com/yjt1993/p/11837398.html
http://blog.sina.com.cn/s/blog_167a8c6480102xrax.html Ranger-solr安装及审计日志配置(Standalone和SolrCloud模式)
https://blog.csdn.net/qq_39056805/article/details/80739659 SolrCloud的搭建以及在Java中的使用(solr集群)
Ranger安装部署 - solr安装的更多相关文章
- VS2013没有安装部署,安装图解
自vs2012后就已经没有安装向导了,VS2013安装是不带安装部署的,用 InstallShield Limited Edition for Visual Studio 解决安装部署问题 第一步:“ ...
- 【Solr】Solr的安装部署
目录 Solr安装部署 Solr Web界面分析 回到顶部 solr安装和部署 solr下载 http://lucene.apache.org/ 安装solr,就是去部署它的war包,war包所在的位 ...
- Apache Solr 初级教程(介绍、安装部署、Java接口、中文分词)
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- zabbix的安装部署及自定义监控的实现
此篇感谢我的小师傅. 1. Zabbix主要功能和优劣势说明 1. Zabbix主要功能和优劣势说明 1.1 Zabbix主要功能: 1)Application monitoring 应用监控 数据库 ...
- Zookeeper介绍及安装部署
本节内容: Zookeeper介绍 Zookeeper特点 Zookeeper应用场景 用到了Zookeeper的一些系统 Zookeeper集群安装部署 一.Zookeeper介绍 是一个针对大型分 ...
- dubbo 安装部署
dubbo 安装部署 1 安装zookeeper 2 安装dubbo 1 下载源码 https://github.com/alibaba/dubbo 2 编译 mvn clean packa ...
- 【Thrift一】Thrift安装部署
Thrift安装部署 Thrift安装部署 下载源码包 安装g++ 解压Thrift安装包 安装boost开发工具 测试(python版) 下载源码包 wget http://apache.fayea ...
- 微服务监控神器Prometheus的安装部署
本文涉及:如何在k8s下搭建Prometheus+grafana的监控环境 基本概念 Prometheus提供了容器和云原生领域数据搜集.存储.处理.可视化和告警一套完整的解决方案,最初时是由Soun ...
随机推荐
- bridge和原生交互的简单用法
首先获取当前环境是ios还是Android var u = navigator.userAgent; var isAndroid = u.indexOf('Android') > -1 || u ...
- 初识IO流
输入输出流,用来进行设备之间的数据传输. 是我们IO传输的数据是以文件的形式体现的,所以Java给我们提供了一个类,Flie用来描文件和目录 File(File parent, String chil ...
- Java之static作用的深度总结
1.深度总结 引用一位网友的话,说的非常好,如果别人问你static的作用:如果你说静态修饰 类的属性 和 类的方法 别人认为你是合格的:如果是说 可以构成 静态代码块,那别人认为你还可以: 如果你说 ...
- Python Number(数字)
Python Number 数据类型用于存储数值. 数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间. 以下实例在变量赋值时 Number 对象将被创建: A ...
- Docker容器安装配置SQLServer服务(Linux)
一:前言 随着不断的对Docker容器的实践和学习,越来越觉得容器的强大,把 SQL Server 数据库服务放在docker容器中,比你自己在宿主服务器上面安装配置一个SQL Server服务器是要 ...
- 手撕面试官系列(九):分布式限流面试专题 Nginx+zookeeper
Nginx专题 (面试题+答案领取方式见侧边栏) 1.请解释一下什么是 Nginx?2.请列举 Nginx 的一些特性.3.请列举 Nginx 和 Apache 之间的不同点4.请解释 Nginx 如 ...
- LeetCode 5215. 黄金矿工(Java)DFS
题目: 5215. 黄金矿工 你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注.每个单元格中的整数就表示这一单元格中的黄金数量:如果该 ...
- spark2.2 从入门到精通全套视频教程(含网盘下载地址)
Spark2.2从入门到精通链接:https://pan.baidu.com/s/1GnPq_p4wOV916REMB_XJ5w 提取码:16zp
- Latex中如何设置字体颜色(三种方式)
1.直接使用定义好的颜色 \usepackage{color} \textcolor{red/blue/green/black/white/cyan/magenta/yellow}{text} 其中t ...
- git学习笔记 ---分支管理
分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN. 如果两个平行宇宙互不干扰,那对现在的你也没啥影响.不过,在某个时间点,两个平行宇宙合并 ...