58、Spark Streaming: DStream的output操作以及foreachRDD详解
一、output操作
1、output操作
DStream中的所有计算,都是由output操作触发的,比如print()。如果没有任何output操作,那么,压根儿就不会执行定义的计算逻辑。 此外,即使你使用了foreachRDD output操作,也必须在里面对RDD执行action操作,才能触发对每一个batch的计算逻辑。否则,光有
foreachRDD output操作,在里面没有对RDD执行action操作,也不会触发任何逻辑。
2、output操作概览
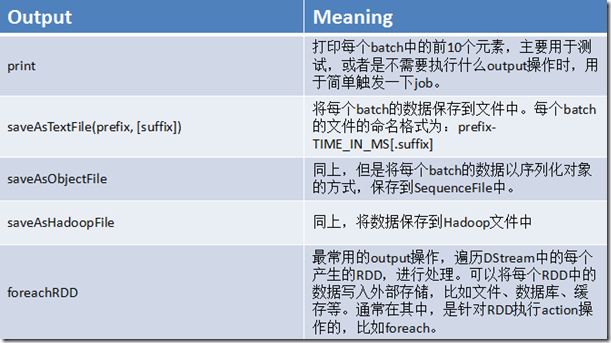
二、foreachRDD
1、foreachRDD详解
通常在foreachRDD中,都会创建一个Connection,比如JDBC Connection,然后通过Connection将数据写入外部存储。
误区一:在RDD的foreach操作外部,创建Connection
这种方式是错误的,因为它会导致Connection对象被序列化后传输到每个Task中。而这种Connection对象,实际上一般是不支持序列化的,也就无法被传输。
dstream.foreachRDD { rdd =>
val connection = createNewConnection()
rdd.foreach { record => connection.send(record)
}
}
误区二:在RDD的foreach操作内部,创建Connection
这种方式是可以的,但是效率低下。因为它会导致对于RDD中的每一条数据,都创建一个Connection对象。而通常来说,Connection的创建,是很消耗性能的。
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
合理方式一:使用RDD的foreachPartition操作,并且在该操作内部,创建Connection对象,这样就相当于是,为RDD的每个partition创建一个Connection对象,节省资源的多了。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
合理方式二:自己手动封装一个静态连接池,使用RDD的foreachPartition操作,并且在该操作内部,从静态连接池中,通过静态方法,获取到一个连接,
使用之后再还回去。这样的话,甚至在多个RDD的partition之间,也可以复用连接了。而且可以让连接池采取懒创建的策略,并且空闲一段时间后,将其释放掉。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection)
}
}
案例:改写UpdateStateByKeyWordCount,将每次统计出来的全局的单词计数,写入一份,到MySQL数据库中。
2、java案例
创建mysql表
mysql> use testdb;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A Database changed
mysql> create table wordcount (
-> id integer auto_increment primary key,
-> updated_time timestamp NOT NULL default CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP,
-> word varchar(255),
-> count integer
-> );
Query OK, 0 rows affected (0.05 sec)
java代码
###ConnectionPool package cn.spark.study.streaming; import java.sql.Connection;
import java.sql.DriverManager;
import java.util.LinkedList; /**
* 简易版的连接池
* @author Administrator
*
*/
public class ConnectionPool { // 静态的Connection队列
private static LinkedList<Connection> connectionQueue; /**
* 加载驱动
*/
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
} /**
* 获取连接,多线程访问并发控制
* @return
*/
public synchronized static Connection getConnection() {
try {
if(connectionQueue == null) {
connectionQueue = new LinkedList<Connection>();
for(int i = 0; i < 10; i++) {
Connection conn = DriverManager.getConnection(
"jdbc:mysql://spark1:3306/testdb",
"",
"");
connectionQueue.push(conn);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return connectionQueue.poll();
} /**
* 还回去一个连接
*/
public static void returnConnection(Connection conn) {
connectionQueue.push(conn);
} } ###PersistWordCount package cn.spark.study.streaming; import java.sql.Connection;
import java.sql.Statement;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext; import com.google.common.base.Optional; import scala.Tuple2; /**
* 基于持久化机制的实时wordcount程序
* @author Administrator
*
*/
public class PersistWordCount { public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("PersistWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5)); jssc.checkpoint("hdfs://spark1:9000/wordcount_checkpoint"); JavaReceiverInputDStream<String> lines = jssc.socketTextStream("spark1", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
} }); JavaPairDStream<String, Integer> pairs = words.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String word)
throws Exception {
return new Tuple2<String, Integer>(word, 1);
} }); JavaPairDStream<String, Integer> wordCounts = pairs.updateStateByKey( new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() { private static final long serialVersionUID = 1L; @Override
public Optional<Integer> call(List<Integer> values,
Optional<Integer> state) throws Exception {
Integer newValue = 0; if(state.isPresent()) {
newValue = state.get();
} for(Integer value : values) {
newValue += value;
} return Optional.of(newValue);
} }); // 每次得到当前所有单词的统计次数之后,将其写入mysql存储,进行持久化,以便于后续的J2EE应用程序
// 进行显示
wordCounts.foreachRDD(new Function<JavaPairRDD<String,Integer>, Void>() { private static final long serialVersionUID = 1L; @Override
public Void call(JavaPairRDD<String, Integer> wordCountsRDD) throws Exception {
// 调用RDD的foreachPartition()方法
wordCountsRDD.foreachPartition(new VoidFunction<Iterator<Tuple2<String,Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Iterator<Tuple2<String, Integer>> wordCounts) throws Exception {
// 给每个partition,获取一个连接
Connection conn = ConnectionPool.getConnection(); // 遍历partition中的数据,使用一个连接,插入数据库
Tuple2<String, Integer> wordCount = null;
while(wordCounts.hasNext()) {
wordCount = wordCounts.next(); String sql = "insert into wordcount(word,count) "
+ "values('" + wordCount._1 + "'," + wordCount._2 + ")"; Statement stmt = conn.createStatement();
stmt.executeUpdate(sql);
} // 用完以后,将连接还回去
ConnectionPool.returnConnection(conn);
}
}); return null;
} }); jssc.start();
jssc.awaitTermination();
jssc.close();
} } ##运行脚本
[root@spark1 streaming]# cat persistWordCount.sh
/usr/local/spark-1.5.1-bin-hadoop2.4/bin/spark-submit \
--class cn.spark.study.streaming.PersistWordCount \
--num-executors 3 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 3 \
--files /usr/local/hive/conf/hive-site.xml \
--driver-class-path /usr/local/hive/lib/mysql-connector-java-5.1.17.jar \
/usr/local/spark-study/java/streaming/saprk-study-java-0.0.1-SNAPSHOT-jar-with-dependencies.jar \ ##运行nc
[root@spark1 ~]# nc -lk 9999
hello word
hello word
hello java ##结果
mysql> use testdb;
mysql> select * from wordcount;
+----+---------------------+-------+-------+
| id | updated_time | word | count |
+----+---------------------+-------+-------+
| 1 | 2019-08-19 14:52:45 | hello | 1 |
| 2 | 2019-08-19 14:52:45 | word | 1 |
| 3 | 2019-08-19 14:52:50 | hello | 2 |
| 4 | 2019-08-19 14:52:50 | word | 2 |
| 5 | 2019-08-19 14:52:55 | hello | 2 |
| 6 | 2019-08-19 14:52:55 | word | 2 |
| 7 | 2019-08-19 14:53:00 | hello | 2 |
| 8 | 2019-08-19 14:53:00 | word | 2 |
| 9 | 2019-08-19 14:53:05 | hello | 2 |
| 10 | 2019-08-19 14:53:05 | word | 2 |
| 11 | 2019-08-19 14:53:10 | hello | 2 |
| 12 | 2019-08-19 14:53:10 | word | 2 |
| 13 | 2019-08-19 14:53:15 | hello | 3 |
| 14 | 2019-08-19 14:53:15 | word | 2 |
| 15 | 2019-08-19 14:53:15 | java | 1 |
| 16 | 2019-08-19 14:53:20 | hello | 3 |
| 17 | 2019-08-19 14:53:20 | word | 2 |
| 18 | 2019-08-19 14:53:20 | java | 1 |
| 19 | 2019-08-19 14:53:25 | hello | 3 |
| 20 | 2019-08-19 14:53:25 | word | 2 |
| 21 | 2019-08-19 14:53:25 | java | 1 |
+----+---------------------+-------+-------+
21 rows in set (0.00 sec)
58、Spark Streaming: DStream的output操作以及foreachRDD详解的更多相关文章
- 54、Spark Streaming:DStream的transformation操作概览
一. transformation操作概览 Transformation Meaning map 对传入的每个元素,返回一个新的元素 flatMap 对传入的每个元素,返回一个或多个元素 filter ...
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- Python API 操作Hadoop hdfs详解
1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client——创建集群连接 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- IOS数据库操作SQLite3使用详解(转)
iPhone中支持通过sqlite3来访问iPhone本地的数据库.具体使用方法如下1:添加开发包libsqlite3.0.dylib首先是设置项目文件,在项目中添加iPhone版的sqlite3的数 ...
- [转]使用python来操作redis用法详解
转自:使用python来操作redis用法详解 class CommRedisBase(): def __init__(self): REDIS_CONF = {} connection_pool = ...
- C语言对文件的操作函数用法详解2
fopen(打开文件) 相关函数 open,fclose 表头文件 #include<stdio.h> 定义函数 FILE * fopen(const char * path,const ...
- C语言对文件的操作函数用法详解1
在ANSIC中,对文件的操作分为两种方式,即: 流式文件操作 I/O文件操作 一.流式文件操作 这种方式的文件操作有一个重要的结构FILE,FILE在stdio.h中定义如下: typedef str ...
- python操作redis用法详解
python操作redis用法详解 转载地址 1.redis连接 redis提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用 ...
随机推荐
- JAVA调用ORACLE存储过程时间类型参数没有日期
是因为使用cs.setDate()给数据库传参数只会传日期部分.如果改用如下代码就可以: cs.setTimestamp(3, new java.sql.Timestamp(dKssj.getTime ...
- C# IEnumerable接口
问: 集合很好用,而且非常简单,但是我不明白 为什么数组.ArrayList 和 Hasttable 这些集合都能用foreach直接遍历呢?我想自己定义一个集合类,应该怎么做呢? 回答:这个问题问的 ...
- 使用poi调整字体格式、添加单元格注释、自动调整列宽
1 创建新的工作铺 import java.io.FileOutputStream; import org.apache.poi.hssf.usermodel.HSSFCell; import org ...
- Linux 软链接和硬链接简介
在Linux系统中,将文件分为两个部分:用户数据和元数据. 元数据(inode) 元数据即文件的索引节点(inode),用来记录文件的权限(r.w.x).文件的所有者和属组.文件的大小.文件的状态改变 ...
- pandas-02 Series()和DataFrame()的区别与联系
pandas-02 Series()和DataFrame()的区别与联系 区别: series,只是一个一维数据结构,它由index和value组成. dataframe,是一个二维结构,除了拥有in ...
- java自定义注释及其信息提取
转自:https://xuwenjin666.iteye.com/blog/1637247 1. 自定义注解 import java.lang.annotation.Retention; import ...
- Devops Reference
摘自 https://www.cnblogs.com/yibutian/p/9561657.html DevOps 企业实践 实施DevOps的核心目标是加速团队.企业的IT精益运行,从根本上提升IT ...
- es截取指定的字段返回
SearchResponse response = client.prepareSearch(index_name).setTypes("lw_devices") .setFrom ...
- jmeter bodydata参数传递
参见:接口测试, jmeter bodydata 传送的参数,在请求中显示为空 新增http header信息头:
- 【Docker】docker安装mysql
一.下载镜像并运行容器 docker run -p 3306:3306 --name mymysql -v $PWD/conf:/etc/mysql/conf.d -v $PWD/logs:/logs ...