Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述
模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断)。
常见的模型压缩算法有:量化,剪枝,蒸馏,低秩近似以及紧凑模型设计(如mobileNet)等操作。但在这里有些方法只能起到缩减模型大小,而起不到加速的作用,如稀疏化剪枝。而在现代的硬件设备上,其实更关注的是模型推断速度。今天我们就讲一种既能压缩模型大小,又能加速模型推断速度:量化。
量化一般可以分为两种模式:训练后的量化(post training quantizated)和训练中引入量化(quantization aware training)。
训练后的量化理解起来比较简单,将训练后的模型中的权重由float32量化到int8,并以int8的形式保存,但是在实际推断时,还需要反量化为float类型进行计算。这种量化的方法在大模型上表现比较好,因为大模型的抗噪能力很强,但是在小模型上效果就很差。
训练中引入量化是指在训练的过程中引入伪量化操作,即在前向传播时,采用量化后的权重和激活,但是在反向传播时仍是对float类型的权重做梯度更新;在预测时将全部采用int8的方式进行计算。
注:模型除了可以量化到int8之外,还可以量化到float16,int4等,只是在作者看来量化到int8之后,能保证压缩效果和准确率损失最优。
2,quantization aware training
论文:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
quantization aware training技术来源于上面这篇论文,现在在tensorflow和pytorch中都提供了相应的接口。
作者在本文中提供了一种将float32量化到int8的策略,并给出了一个推断框架和训练框架,推断框架让模型可以有效的整数运算硬件上运行,训练框架和推断框架相辅相成,可以降低精度的损失。我们先来看看推断框架:
Quantizated Inference
1, Quantization scheme
首先定义q为量化值,r为真实浮点值。本文抛弃了之前采用查找表的方式将浮点值映射到整数值,而是引入了一个映射关系来表示,公式如下:
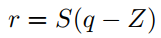
上面式子中S为缩放稀疏,Z为"Zero-Point",其实Z就是真实浮点值0映射到整数时对应的值,这个值的存在是有一定意义的,因为无论是在图像中还是NLP中都会有用0做padding值来补全的,映射到整数后,也应该有这样一个值的存在,这个值就是Z。在这里S和Z可以称为量化参数,对于每个权重矩阵和每个激活数组都有一对这样的值。
用C++中的结构体来表示这个数据结构的话,如下:

在这里QType既可以是int8,也可以是float16,int4等。
2,Integer-arithmetic-only matrix multiplication
对于两个浮点数矩阵之间的运算,可以全部转换成整数运算,公式如下:

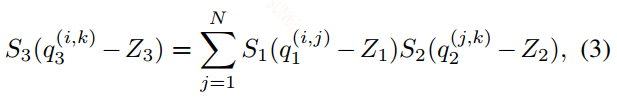


在上面的式子中只有M是一个浮点数,所以这里会有一个浮点运算,作者在这里好像为了避开浮点运算,做了下面一个操作,但没怎么看懂,有兴趣的可以自己。

3,Efficient handling of zero-points
个人理解在上面的式子4中因为两个矩阵都需要减去相应的Z值,减法运算之后得到的值有可能会突破int8的范围,到时候就需要int16来存储,但整个运算为了控制在int8的类型下计算,作者做了下面的变换。至于作者提到的2N^3的计算复杂度,即使转换完之后还是存在的,这个复杂度就是两个矩阵的计算复杂度。
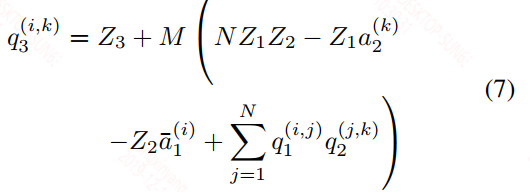

4,Implementation of a typical fused layer
上面的描述了权重的矩阵运算,但除此之外在一个神经网络中还含有bias和激活函数的映射,因为int8类型的矩阵运算完之后的值应该是在int32之内的,所以bias选择int32的类型,这样的选择一是因为bias在整个神经网络中只占据极少的一部分,此外bias的作用其实非常重要,高精度的bias可以降低模型的偏差。因此加上bias之后就变成了int32,我们需要再次转换成int8类型,之后再进入到激活中。具体如下图所示:

Training with simulated quantization
为什么要采用这种量化策略,前面也说了对于大模型采用post training quantizated的方法是可以的,但是小模型容易导致精度损失较大。具体的量化策略如下:
1,weights再输入进行卷积之前就开始量化,如果有bn层,将bn层融入到weights中。
2,激活在激活函数执行完之后再量化。
具体的如下如所示:

具体的量化公式如下:
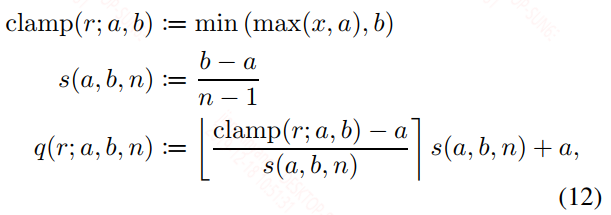
也是min-max的方式,上面式子中(a, b)是针对浮点数的量化范围,n可以理解为对于int8,$n = 2^8$。上面的⌊·⌉ 其实是一个将浮点数转为最近且小于它的整数的符号,该符号内部就是量化函数。
1,Learning quantization ranges
对于上面的量化范围(a, b),weight和activation是不一样的,对于weight来说很简单,就是该权重中最大最小值,但是对于activation是不太一样的, 对于activation采用了EMA(滑动平均)来对输入中的最大最小值计算得到的,但是在训练初期,因为输入的值变化较大,会影响到滑动平均的值,因此在初期不对activation做量化,而是在网络稳定之后再引入。具体量化算法如下:

2,Batch normalization folding
对于bn层,在训练时是一个单独的层存在,但是在推断时为了提升效率是融合到卷积或全连接层的权重和偏置中的,如下图:
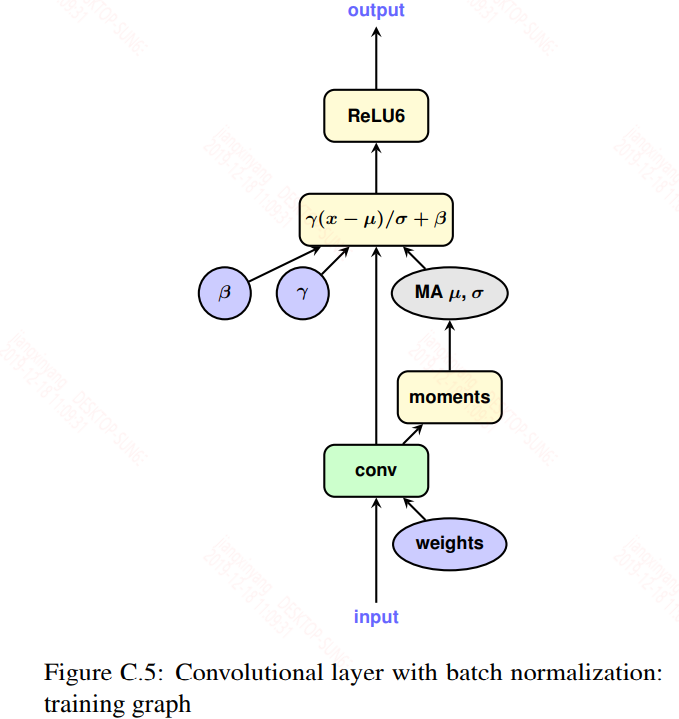

为了模拟推断,训练时需要将bn层考虑进权重,然后再做量化。具体公式如下:


参考文献:
Quantizing deep convolutional networks for efficient inference: A whitepaper
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference的更多相关文章
- JAX-WS:背后的技术JAXB及传递Map
转载:http://www.programgo.com/article/98912703200/ 1.什么是JAX-WS JAX-WS (JavaTM API for XML-Based Web Se ...
- 阿里云全球首次互联网8K直播背后的技术解读
3月28日,云栖大会·深圳峰会现场,阿里云发布并现场演示了阿里视频云最新8K互联网直播解决方案.这是全球发布的首个8K视频云解决方案,也是全球首次8K互联网视频直播. 视频地址:https://v.q ...
- 深度学习(六十九)darknet 实现实验 Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffma
本文主要实验文献文献<Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization ...
- Digg工程师讲述Digg背后的技术
虽然最近业绩有所下滑,也出现了一些技术故障,但Digg作为首屈一指的社会化新闻网站,其背后的技术还是值得一探,Digg工程师 Dave Beckett 在今年4月份写一篇名为<How Digg ...
- 【沙龙报名中】与微信&云开发官方团队零距离互动,揭秘爆款微信小游戏背后的技术!
有人说 微信小程序游戏的百花齐放 活像十几年前的4399小游戏称霸互联网的景象 " 歪,斗地主吗,三缺二, 不用下app,小程序就能玩,我保证不抢地主让你抢!" ...... &q ...
- 全网显示 IP 归属地,这背后的技术你知道吗?
为了进一步规范国内的网络舆论,国家规定了各互联网平台都需要显示 IP 归属地信息.微博.抖音.公众号等多个平台纷纷上线了 IP 归属地功能,这标志着国内言论的进一步规范化.但互联网平台商们是怎么通过 ...
- 阅读笔记 The Impact of Imbalanced Training Data for Convolutional Neural Networks [DegreeProject2015] 数据分析型
The Impact of Imbalanced Training Data for Convolutional Neural Networks Paulina Hensman and David M ...
- [Converge] Training Neural Networks
CS231n Winter 2016: Lecture 5: Neural Networks Part 2 CS231n Winter 2016: Lecture 6: Neural Networks ...
- A Recipe for Training Neural Networks [中文翻译, part 1]
最近拜读大神Karpathy的经验之谈 A Recipe for Training Neural Networks https://karpathy.github.io/2019/04/25/rec ...
随机推荐
- SecureCRT自动断开连接的解决方法
方法一: 在普通用户下,输入重启sshd服务的命令:service sshd restart 这时会提示:管理系统服务或单元需要身份验证.解决的方法:先要切换为root用户,接着重启sshd服务:se ...
- LG2921 [USACO2008DEC]Trick or Treat on the Farm 内向基环树
问题描述 LG2921 题解 发现一共有 \(n\) 个点,每个点只有一条出边,即只有 \(n\) 条边,于是就是一个内向基环树. \(\mathrm{Tarjan}\) 缩点. 但是这个题比较猥琐的 ...
- NOIP模拟赛2(two)
题目描述 Description 很久很久很久以前,方方方造了一台计算机,计算机中开始有一个数 \(0\) .方方方想要让这个数变成 \(a\) ,他打算每次选择一个整数,把计算机中当前的数按位或上这 ...
- Nginx企业级优化
Nginx企业级优化 一.隐藏版本号信息 安装软件前修改,源码包中的版本信息 #切换到源码包目录[root@localhost ~]# cd /usr/src/nginx-1.15.9/[root@l ...
- jQuery与IE兼容性问题处理
jQuery虽然是兼容所有主流的浏览器,但实际应用中也会存在很多兼容性的问题.使用IE11+jquery-3.2.1.min.js遇到的问题如: 对象不支持indexOf 在低版本中,1.8写法如下: ...
- java基础之----java常见异常及代码示例
概述 java中有两种错误类型,一个是Exception,一个是Error,都在java.lang包下,一般来说程序中的try...catch捕获的是Exception类型的异常,而Error类型的错 ...
- 【Linux命令】Linux命令后面所接选项和参数的区别
Linux命令后面所接选项和参数的区别 在使用Linux命令时,有时候后面会跟一些"选项"(options)或"参数"(agruments) 命令格式为: #中 ...
- mysql 实现经纬度排序查找功能
需求如下: 商品有多个门店,用户使用App时需要查找附近门店的商品,商品要进行去重分页. 思路: 1.确认mysql自带经纬度查询函数可以使用. 2.该需求需要利用分组排序,取每个商品最近门店的商品i ...
- 在项目中使用Solr
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi=" ...
- 禁用software reporter tool.exe 解决CPU高占用率的问题
或者 或者 C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\SwReporter\36.184.200 下编辑 manifes ...