sharding-jdbc 分布式数据库中间件
小编今天在做Sharding-jdbc时出现了一些问题,就上网百一百,发现网上的sharding-jdbc的参考是挺少的,唉还是要继续学习看文档。
Sharding-jdbc介绍
Sharding-JDBC是当当应用框架ddframe中,关系型数据库模块dd-rdb中分离出来的数据库水平扩展框架,即透明化数据库分库分表访问。
在互联网高并发的时代,为了应付DB的高并发读写,我们会采用读写分离技术。读写分离指的是利用数据库主从技术(把数据复制到多个节点中),分散读多个库以支持高并发的读,而写只在master库上。DB的主从技术只负责对数据进行复制和同步,而读写分离技术需要业务应用自身去实现。sharding-jdbc通过简单的开发,可以方便的实现读写分离技术。
读写分离实现
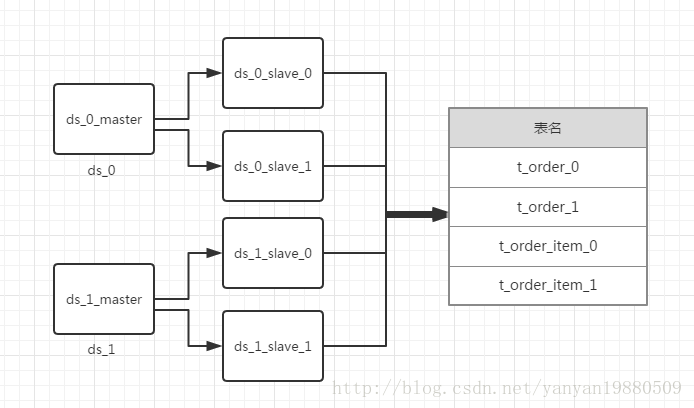
库和表结构设计图:
代码示例
这里我采用了SSH来做的测试(Spring+Struts2+Hibernate)配置请参考: http://www.cnblogs.com/niechen/p/8619713.html
这里我们采用yml的方式进行分库分表,这里只演示了分表,分库的原理是一样的 首先创建sharding-jdbc-core.yml文件
dataSources:
ds: !!com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/数据库
username: root
password: shardingRule:
tables:
class:
actualDataNodes: ds.class_${0..3}
tableStrategy:
inline:
shardingColumn: id
algorithmExpression: class_${id % 4}
keyGeneratorColumnName: id defaultKeyGeneratorClass: com.bdqn.lyrk.ssh.study.generator.MyKeyGenerator
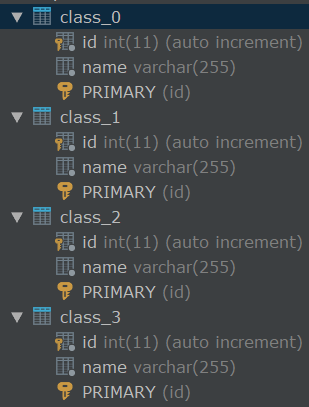
采用了4张表为例子
这里简单介绍一下上面是数据的拆分这里只做了一个 数据源 !!后面跟的是我们使用的那种数据源有很多dbcp等等..这里用的阿里的druid,后面的不用多说了吧
下面是对表的拆分
class:代表的是逻辑表名
actualDataNodes:数据源名.class_${0..3} 也就是class_0,class_1,class_2,class_3对应的这三张表 ,如果是多个数据源的话就是:数据源名_${....}.class_${0..3}
tableStategy下面的参数是设置拆表的规范
shardingColumn:根据哪一列来约定拆表,一般我们都根据主键 所以这里是id
algorithmExpression:约定了拆表的规则,这里是4张表对应0,1,2,3,那么如果对4求余那么值肯定在0~3之间,那么所以是class_${id % 4}
keyGeneratorColumnName:这里指定的是id的生成器
defaultKeyGenerotorClass:指定对应我们自己的生成器
package com.bdqn.lyrk.ssh.study.generator; import io.shardingjdbc.core.keygen.KeyGenerator;
import org.springframework.context.annotation.Configuration; import java.util.Random; /**
* @author 杨天乐
* @date 2018/4/16 21:10
*/
@Configuration
public class MyKeyGenerator implements KeyGenerator {
@Override
public Number generateKey() {
Random random = new Random();
int rom= random.nextInt(100);
return rom;
}
}
注意这里用Random生成不要用Math来生成,不然会有小数,那么一定找不到对应的表,这是小编今天遇到坑爹的问题之一。
接下来我们要加载刚才配置的yml,我们创建一个ShardingJdbcConfig.java
package com.bdqn.lyrk.ssh.study.config; import io.shardingjdbc.core.api.ShardingDataSourceFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration; import javax.sql.DataSource;
import java.io.File;
import java.io.IOException;
import java.sql.SQLException; /**
* @author 杨天乐
* @date 2018/4/16 17:10
*/
@Configuration
public class ShardingJdbcConfig { @Bean
public DataSource dataSource() throws IOException, SQLException {
DataSource dataSource = ShardingDataSourceFactory.createDataSource(new File(
ShardingJdbcConfig.class.getClassLoader().getResource("sharding-jdbc-core.yml").getFile()));
return dataSource;
}
}
加载我们yml配置。这里一定要从ClassLoader里才能拿到配置
接下来我们来测试一下添加操作(业务层我就不写了,就一个hibernate的save方法),插入5条数据看他们分别都插入到了哪?(表的数据我都清空了)

这是我插入的5条数据按顺序0~3
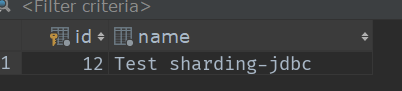
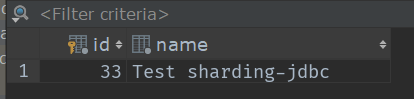
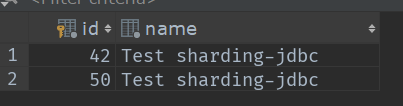
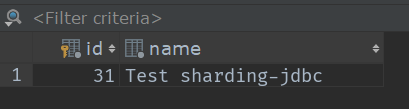
大家也可以根据这些id来求一下余,看对应表吗?
参考sharding官方文档和官方demo,SSH集成例子 http://www.cnblogs.com/niechen/p/8619713.html
sharding-jdbc 分布式数据库中间件的更多相关文章
- Apache ShardingSphere:由开源驱动的分布式数据库中间件生态
2021 年 7 月 21 日 2021 亚马逊云科技中国峰会现场,SphereEx 联合创始人.Apache ShardingSphere PMC 潘娟受邀参与此次峰会,以<Apache Sh ...
- 分布式数据库中间件TDDL、Amoeba、Cobar、MyCAT架构比较分
比较了业界流行的MySQL分布式数据库中间件,关于每个产品的介绍,网上的资料比较多,本文只是对几款产品的架构进行比较,从中可以看出中间件发展和演进路线 框架比较 TDDL Amoeba Cobar M ...
- 分布式数据库中间件Mycat百亿级数据存储(转)
此文转自: https://www.jianshu.com/p/9f1347ef75dd 2013年阿里的Cobar在社区使用过程中发现存在一些比较严重的问题,如高并发下的假死,心跳连接的故障,只实现 ...
- 从零开发分布式数据库中间件 二、构建MyBatis的读写分离数据库中间件
在上一节 从零开发分布式数据库中间件 一.读写分离的数据库中间件 中,我们讲了如何通过ThreadLocal来指定每次访问的数据源,并通过jdbc的连接方式来切换数据源,那么这一节我们使用我们常用的数 ...
- 分布式数据库中间件DDM的实现原理
随着数据量不断增大,传统的架构模式难以解决业务量不断增长所带来的问题,特别是在业务成线性.甚至指数级上升的情况.此时我们不得不通过水平扩展,把数据库放到不同服务器上来解决问题,也就是我们说的数据库中间 ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- 开源分布式数据库中间件MyCat源码分析系列
MyCat是当下很火的开源分布式数据库中间件,特意花费了一些精力研究其实现方式与内部机制,在此针对某些较为重要的源码进行粗浅的分析,希望与感兴趣的朋友交流探讨. 本源码分析系列主要针对代码实现,配置. ...
- 分布式数据库中间件–(3) Cobar对简单select命令的处理过程
友情提示:非原文链接可能会影响您的阅读体验,欢迎查看原文.(http://blog.geekcome.com) 原文地址:http://blog.geekcome.com/archives/284 在 ...
- 分布式数据库中间件–(2) Cobar与client握手身份验证
Cobar启动完毕,监听特定端口.整个认证的流程图: NIOAcceptor类继承自Thread类,该类的对象会以线程的方式执行,进行连接的监听. NIOAcceptor启动的初始化步骤例如以下: 1 ...
- 分布式数据库中间件–(1) Cobar初始化过程
Cobar-Server的源代码地址:GitHub 欢迎Fork. 官方文档描写叙述Cobar的网络通信模块见下图. Cobar使用了Java的NIO进行处理读写.NIO是Java中的IO复用.而不须 ...
随机推荐
- Aladdin and the Flying Carpet LightOJ 1341 唯一分解定理
题意:给出a,b,问有多少种长方形满足面积为a,最短边>=b? 首先简单讲一下唯一分解定理. 唯一分解定理:任何一个自然数N,都可以满足:,pi是质数. 且N的正因子个数为(1+a1)*(1+a ...
- 【BZOJ4944】[NOI2017]泳池(线性常系数齐次递推,动态规划)
[BZOJ4944][NOI2017]泳池(线性常系数齐次递推,动态规划) 首先恰好为\(k\)很不好算,变为至少或者至多计算然后考虑容斥. 如果是至少的话,我们依然很难处理最大面积这个东西.所以考虑 ...
- 实测搭建jenkins多环境、多分支demo
一.环境以及工具信息 1. 3台服务器信息 jenkins: 192.168.123.163.serverA:192.168.123.130.serverB :139.198.17.241三台机器都是 ...
- python 学习之 基础篇三 流程控制
前言: 一. python中有严格的格式缩进,因为其在语法中摒弃了“{}”来包含代码块,使用严格的缩进来体现代码层次所以在编写代码的时候项目组要严格的统一器缩进语法,一个tab按键设置为四个空格来缩进 ...
- iis url 重写
1.选择网站-找到有测url 重写 :2:选中它,在右上角有一个打开功能,点击打开 3.依然在右上角,点击添加规则 4:选择第一个,空白规则 名称随便输入,我们通常有这样一个需求,就是.aspx 后缀 ...
- C#中 char、byte、string
var str = "我是中国人";var str1 = "abc"; char[] chars = str.ToCharArray();char[] char ...
- Python常用模块大全(转)
os模块:os.remove() 删除文件 os.unlink() 删除文件 os.rename() 重命名文件 os.listdir() 列出指定目录下所有文件 os.chdir() 改变当前工作目 ...
- Nginx实现防盗链的方式
一.ngx_http_referer_module(阻挡来源非法的域名请求),配置如下: location ~.*\. (gif|jpg|png|flv|swf|rar|zip)$ { valid_r ...
- 软件架构的演进,了解单体架构,垂直架构,SOA架构和微服务架构的变化历程
软件架构演进 软件架构的发展经历了从单体结构.垂直架构.SOA架构到微服务架构的过程,博客里写到了这四种架它们的特点以及优缺点分析,个人学习之用,仅供参考! 1.1.1 单体架构 特点: 1 ...
- mysql 连接数用完,root也无法登陆的处理方法
gdb -p $(pidof mysqld) -ex "set max_connections=1500" -batch 使用 gdb 临时调大 参数 max_connection ...