Python高级笔记(九)Python使用MySQL
1. MySQL基本使用
1.1 数据库简介
- Mysql: 关系型数据库,做网站
- redis:当作缓存
- mongodb:非关系型数据库,做爬虫
- SQL语句:
- DQL:数据查询语言,用于对数据进行查询,如select
- DML:数据操作语言,对数据进行增加、修改、删除,如insert、update、delete
- TPL:事务处理语言,对事务进行处理,包括begin transaction、commit、rollback
- DCL:数据控制语言,进行授权与权限的回收,如grant、revoke
- DDL:数据定义语音,进行数据库、表的管理等,如create、drop
- CCL:指针控制语言,通过控制指针完成表的操作,如declare cursor
- MySQL安装
- 安装服务器段,输入:sudo apt-get install mysql-server (ubuntu里已经安装好了mysql服务器端,无须再安装,并且设置成了开机启动
- 服务器用于接收客户端的请求,执行sql语句,管理数据库
- 服务器端一般以服务方式管理,名称mysql
- 启动服务器: sudo service mysql start
- 查看进程中是否存在mysql服务: ps -aux |grep mysql
- 停止服务: sudo service mysql stop
- 重启服务: sudo service mysql restart
- 配置
- 配置文件目录为:/etc/mysql/mysql.cnf
- 进入conf.d目录,打开mysql.cnf,发现没有配置
- 进入mysql.conf.d目录,打开mysql.cnf,可以看到配置项
- 主配置项如下:
- 配置文件目录为:/etc/mysql/mysql.cnf



#
# Instead of skip-networking the default is now to listen only on
# localhost which is more compatible and is not less secure.
bind-address = 127.0.0.1
#
# * Fine Tuning
#
key_buffer_size = 16M
max_allowed_packet = 16M
thread_stack = 192K
thread_cache_size =
# This replaces the startup script and checks MyISAM tables if needed
# the first time they are touched
myisam-recover-options = BACKUP
#max_connections =
#table_open_cache =
#thread_concurrency =
#
# * Query Cache Configuration
#
query_cache_limit = 1M
query_cache_size = 16M
#
# * Logging and Replication
#
# Both location gets rotated by the cronjob.
# Be aware that this log type is a performance killer.
# As of 5.1 you can enable the log at runtime!
#general_log_file = /var/log/mysql/mysql.log
#general_log =
#
# Error log - should be very few entries.
#
log_error = /var/log/mysql/error.log
- 客户端
- 安装:sudo apt-get install mysql-client
- 帮助:mysql --help
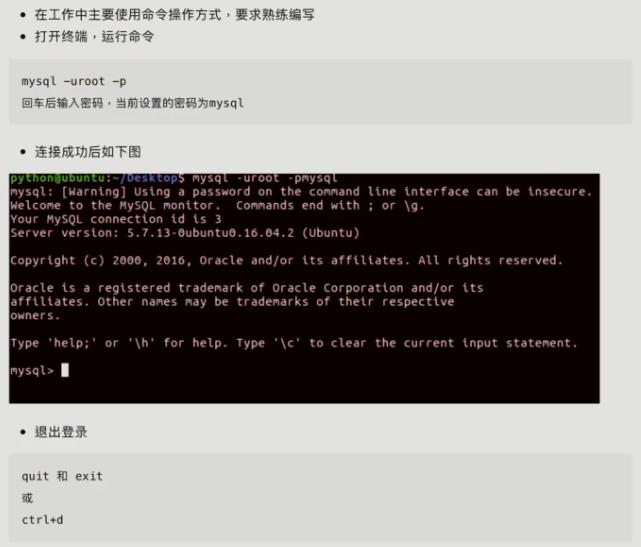
- 最基本的连接命令如下:sudo mysql -u root -p

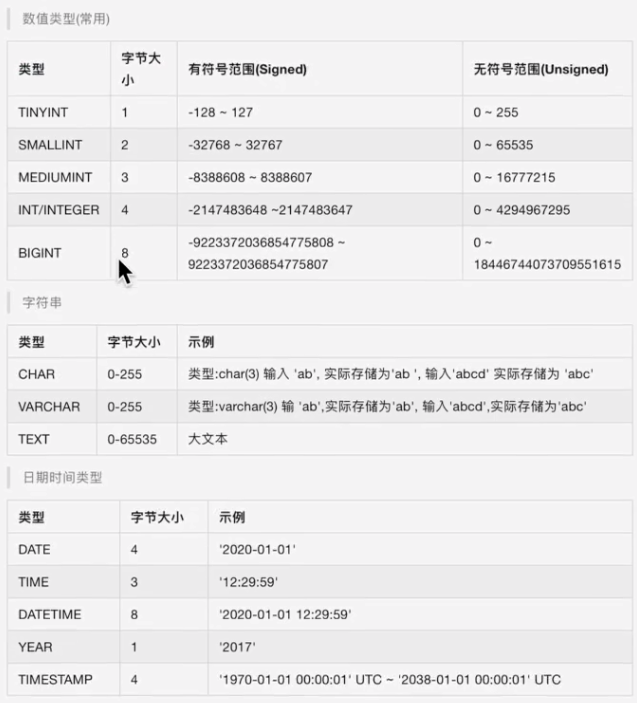
1.2 数据完整性


1.3 命令行脚本
1.3.1 命令行连接
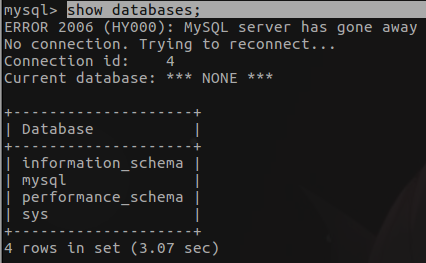
1.3.2 数据库操作
- 查看所有数据库
show databases;
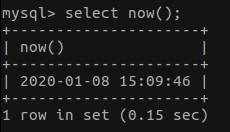
- 显示时间
select now();
- 创建数据库
默认是latin编码(不推荐)
create database python01;


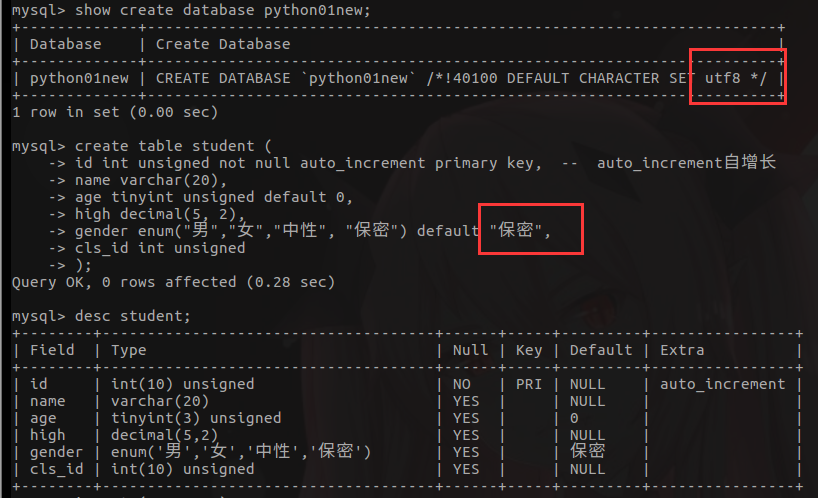
用utf8编码创建
create database python01new charset=utf8;
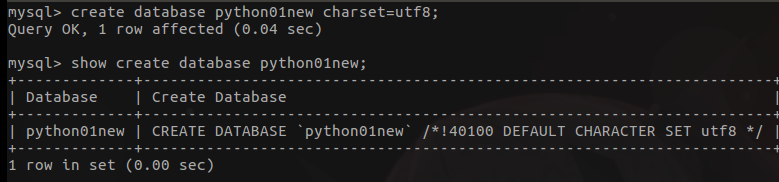
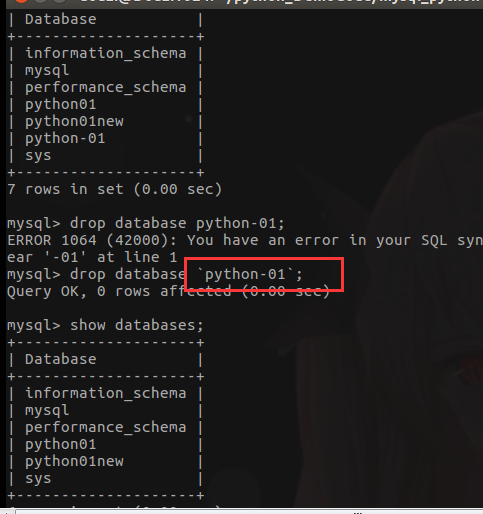
- 删除数据库
drop database python01;
注意:
1.3.3 数据表操作
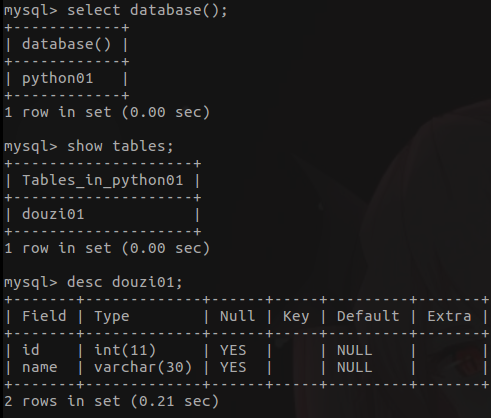
- use databaseName;
- select database();
- show tables;
- desc tablename; (显示表的属性)
- 创建表
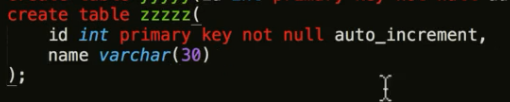
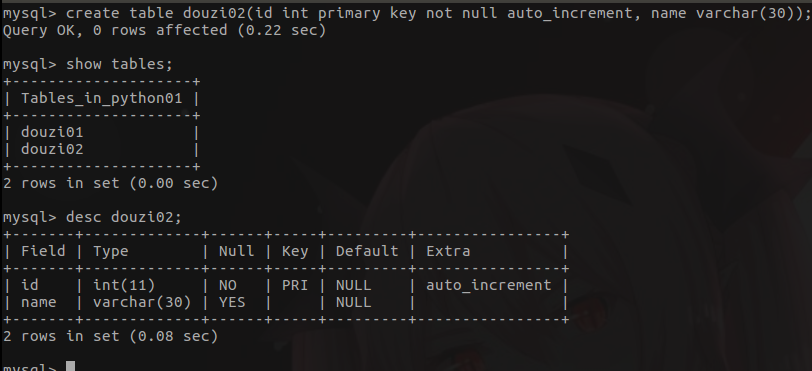
create table student (
id int unsigned not null auto_increment primary key, -- auto_increment自增长
name varchar(20),
age tinyint unsigned default 0,
high decimal(5, 2),
gender enum("男","女","中性", "保密") default "保密",
cls_id int unsigned
);
注意:表数据有中文,需要设置数据库编码为utf8
- 插入数据
insert into student values(0, "老王", 18, 188.88, "男", 0);
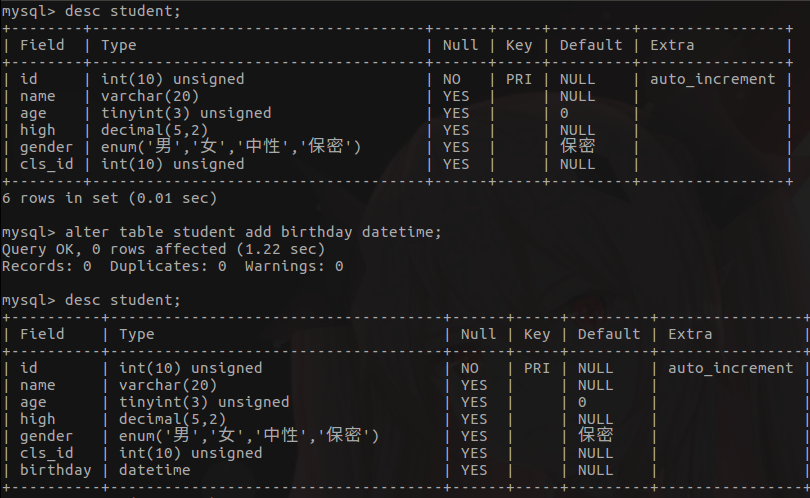
- 修改表结构 - 添加字段
alter table student add birthday datetime;
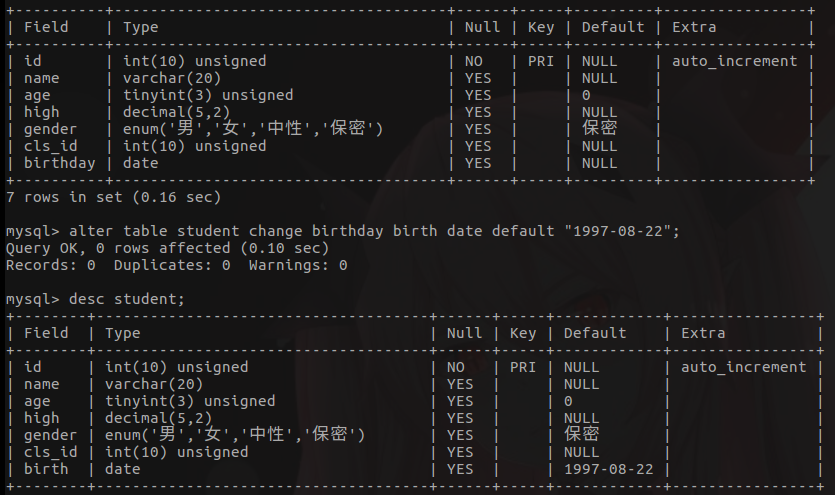
- 修改表结构 - 修改字段:不重命名版(修改列名类型及约束)
alter table 表名 modify 列名 类型及约束;
alter table student modify birthday date;

- 修改表结构 - 修改字段:重命名版(重命名列名)
alter table student change birthday birth date default "1997-08-22";
- 修改表结构 - 删除字段(少用)
alter table student drop high;
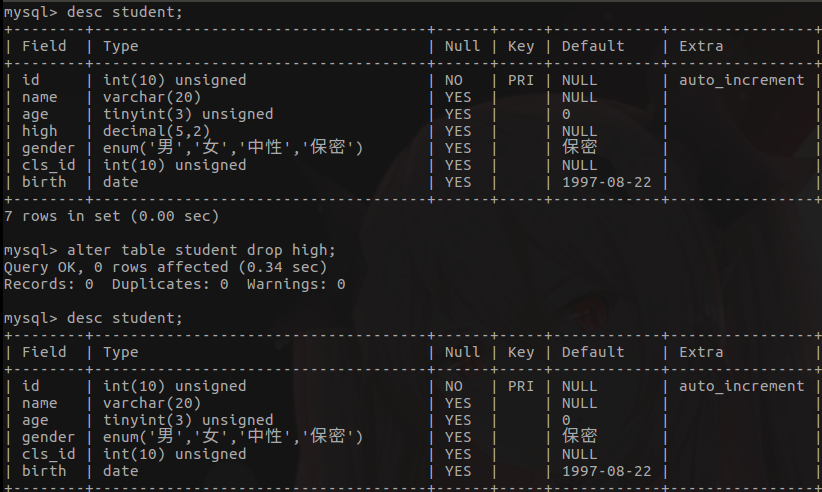
- 删除表
drop table xxxx;
- 查看表的创建语句
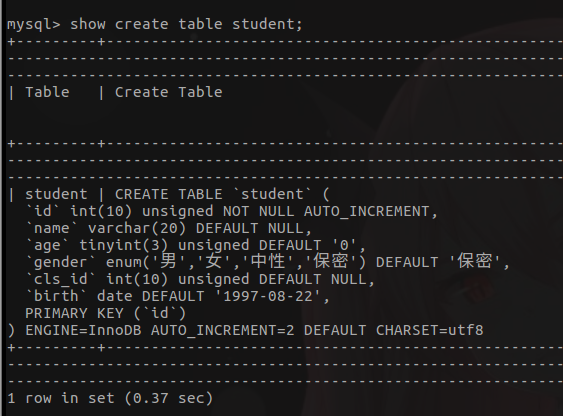
1.3.4 数据增删改查
- 增加
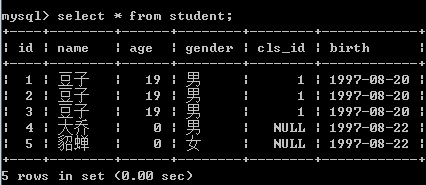
insert into student values(0, "豆子", 19, "男", 1, "1997-8-20");
insert into student values(null, "豆子", 19, "男", 1, "1997-8-20");
insert into student values(default, "豆子", 19, "男", 1, "1997-8-20"),(default, "彦", 19, "女", 1, "1997-8-20");
insert into student(name, gender) values("大乔", "男");
insert into student(name, gender) values("大乔", "女"), ("貂蝉", "女");
- 删除(建议逻辑删除)
alter table student add is_delete bit default 0;
update student set is_delete=1 where name="大乔";
- 修改
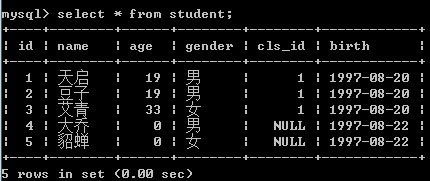
update student set gender=2 where name="大乔";
update student set name="天启" where id=1;
update student set name="艾青", age=33, gender=2 where id=3;
- 查询
select * from student where id>3;
select id as 学号, gender as 性别 ,name as 姓名 from student;
1.3.5 数据备份&恢复
1.4 数据库设计


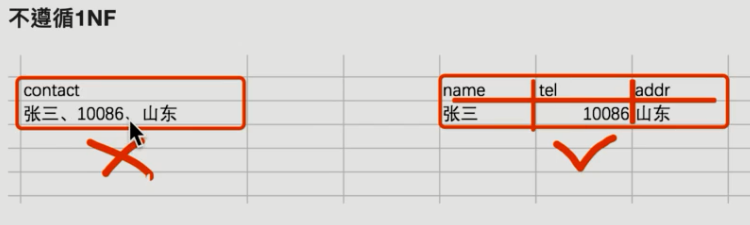
(第一范式:不能再拆)
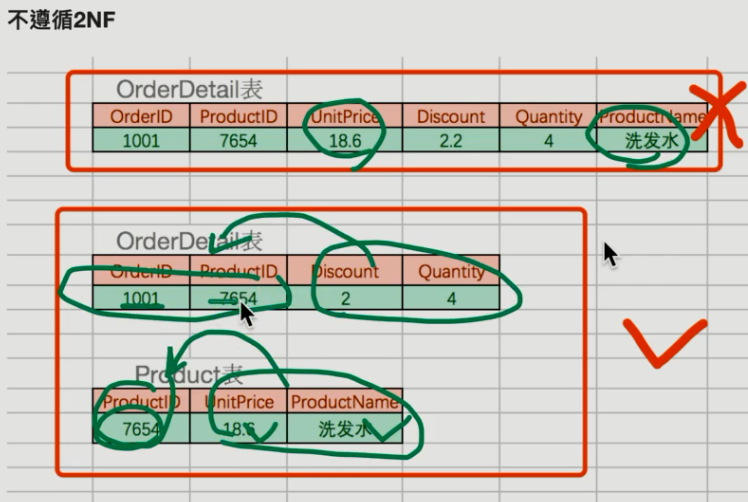
(第二范式:必须有主键,如果表里的主键是由两个或多个列构成的,那就不能只由一个列判断了,其他字段必须全部依赖主键而不是一部分)
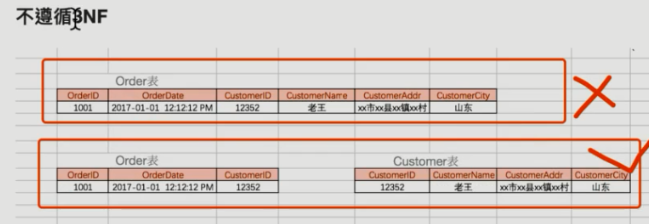
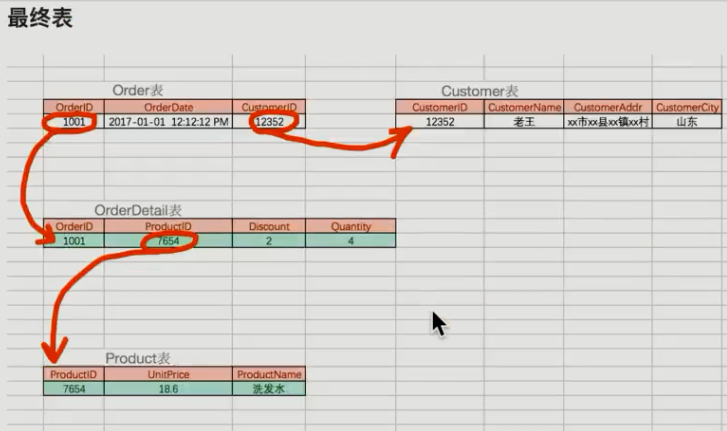
(第三范式:另外非主键列必须直接依赖于主键,不能存在传递依赖,即不能存在:非主键列A依赖非主键列B,非主键B依赖于主键的情况)

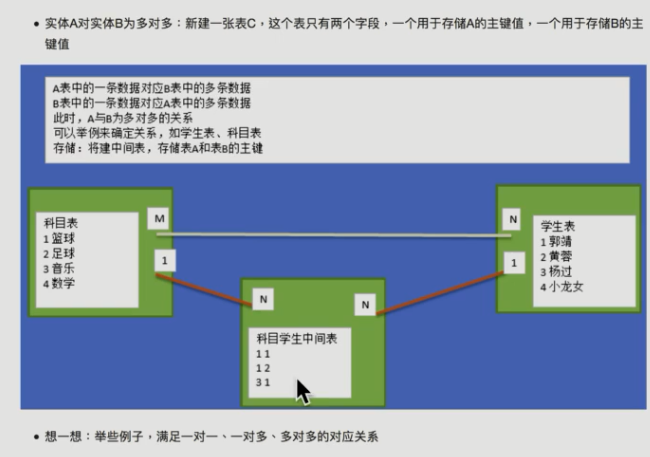
2. MySQL查询
2.1 MySQL查询
2.11 创建数据库、数据表
-- 创建数据库
create database python_test_1 charset=utf8; -- 使用数据库
use python_test_1; -- students表;
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned default 0,
height decimal(5, 2),
gender enum("男","女","中性", "保密") default "保密",
cls_id int unsigned default 0,
is_delete bit default 0
); -- classes表
create table classes (
id int unsigned auto_increment primary key not null,
name varchar(30) not null
);
2.12 准备数据
-- 准备数据
-- 向students表中插入数据
insert into students values
(0, '小明', 18, 180.00, 2, 1, 0),
(0, '小月月', 18, 180.00, 2, 2, 1),
(0, "彭于晏", 29, 185.00, 1, 1, 0),
(0, "刘德华", 50, 175.00, 1, 1, 0),
(0, '黄蓉', 38, 160.00, 2, 1, 0),
(0, '凤姐', 28, 150.00, 4, 2, 1),
(0, '王祖贤', 18, 172.00, 2, 1, 1),
(0, '周杰伦', 36, NULL, 1, 1, 0),
(0, '陈尘', 27, 181.00, 1, 2, 0),
(0, '刘亦菲', 20, 160, 2, 2, 0),
(0, '金星', 33, 162.00, 3, 3, 1),
(0, '郭靖', 12, 170.00, 1, 4, 0),
(0, '周杰', 34, 176.00, 2, 5, 0); -- 向classes表中插入数据
insert into classes values (0, "python_01期"), (0, "python_02期");
2.13 查询所有字段
select * from students;
2.14 查询指定字段
-- 查询指定字段
select name as 姓名, age as 年龄 from students;
select students.name, students.age from students;
select s.name, s.age from students as s; -- 失败的select students.name, students.age from students as s; -- 去重
select distinct gender from students;
2.2 条件
2.21 比较运算符
-- 比较运算符 >, <, =, >=, <=, !=
-- 查询age>18的信息
select * from students where age > 18;
2.22 逻辑运算符
-- 逻辑运算符 and, or, not
select * from students where age>18 and age<28;
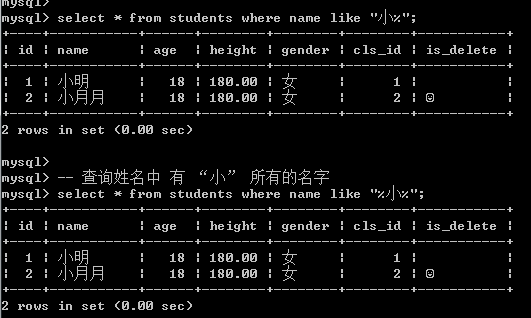
2.23 模糊查询 (like, rlike)
-- 模糊查询 like, % 替换1个或者多个, _ 替换1个
-- 查询姓名中 以"小"开始的名字
select * from students where name like "小%"; -- 查询姓名中 有 “小” 所有的名字
select * from students where name like "%小%"; -- 查询有2个字的名字
select name from students where name like "__"; -- 查询至少有2个字的名字
select name from students where name like "__%"; -- rlike 正则
-- 查询以 周开始的姓名
select name from students where name rlike "^周.*"; -- 查询以 周开始,伦结尾的姓名
select name from students where name rlike "^周.*伦$";


2.24 范围查询 (in)
-- 范围查询
-- in (1, 3, 8) 表示在一个非连续的范围内
-- 查询 年龄为18、20, 28, 34的姓名
select name, age from students where age in (18, 20, 28, 34); -- 查询 不是这几个年龄的 名字
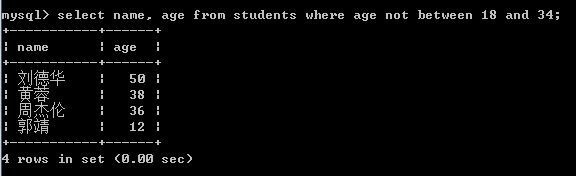
select name, age from students where age not in (18, 20, 28, 34); -- 查询 不在18,34年龄之间的名字
select name, age from students where not age between 18 and 34;
select name, age from students where age not between 18 and 34;
-- 错误select name, age from students where age not (between 18 and 34);
2.25 空判断
-- 空判断
select * from students where height is null;
2.3 排序
-- 排序
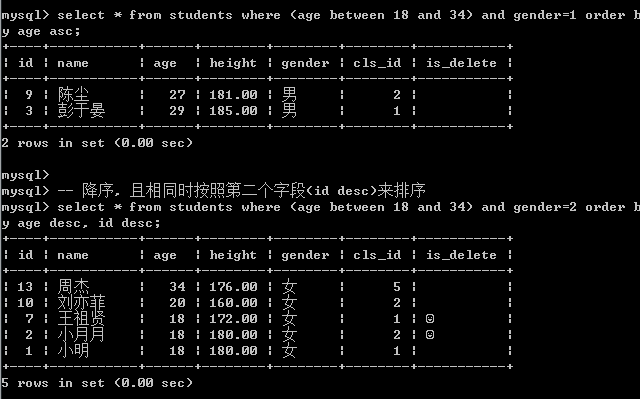
-- 查询年龄在18到34之间的男性,按照年龄从小到大排序
select * from students where (age between 18 and 34) and gender=1 order by age;
select * from students where (age between 18 and 34) and gender=1 order by age asc; -- 降序, 且相同时按照第二个字段(id desc)来排序
select * from students where (age between 18 and 34) and gender=2 order by age desc, id desc;
2.4 聚合函数
-- 聚合函数
-- count(), 查询男性多少人
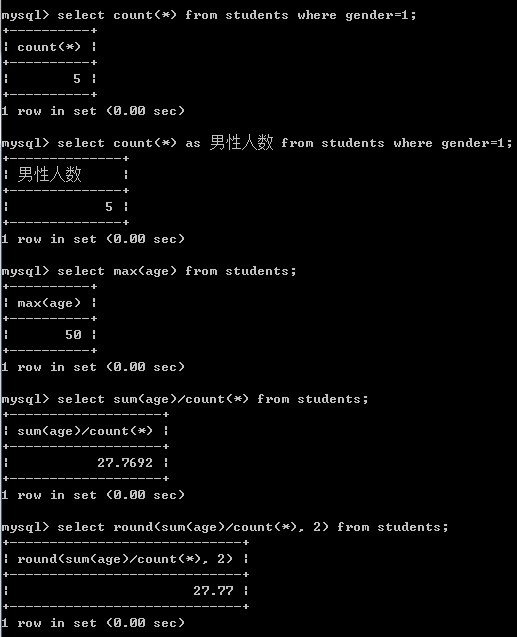
select count(*) as 男性人数 from students where gender=1; -- 最大值max, 平均数ave
-- 查询最大的年龄
select max(age) from students; -- 计算平均年龄
select round(sum(age)/count(*), 2) from students;
2.5 分组(常和聚合函数一起用,可以单独计算组里的数据)
-- 分组
-- 按照性别分组,查询所有的性别, select后面要取,唯一能标记组的东西
select gender from students group by gender;

-- 计算每种性别的人数
select gender, count(*) from students group by gender;

-- 计算每种性别最大年龄
select gender, max(age) from students group by gender;

-- 查看组里的信息
-- 查看组里的信息
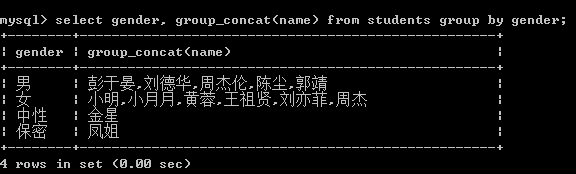
select gender, group_concat(name) from students group by gender;
2.51 设置需要分组数据的条件(where需要放在group前面)
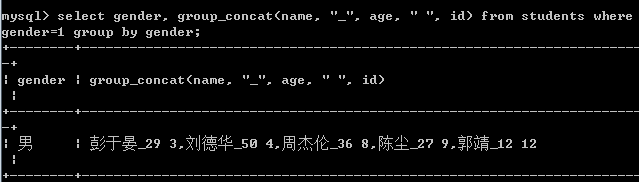
select gender, group_concat(name, "_", age, " ", id) from students where gender=1 group by gender;
2.52 设置分组结果的条件(having在group后面)
select gender, group_concat(name), avg(age) from students group by gender having avg(age) > 30;

2.5 分页(limit在最后)
2.51 limit (第N页-1)*每页的个数, 每页的个数
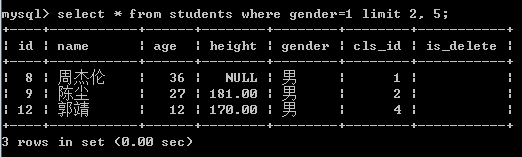
select * from students where gender=1 limit 2, 5;
2.52 limit在最后
select * from students where gender=2 order by height desc limit 0, 2;

2.6 连接查询(多个表的关联查询)

2.61 内连接(inner join)
-- 查询 有能够对应班级以及班级信息
select * from students inner join classes on students.cls_id = classes.id;
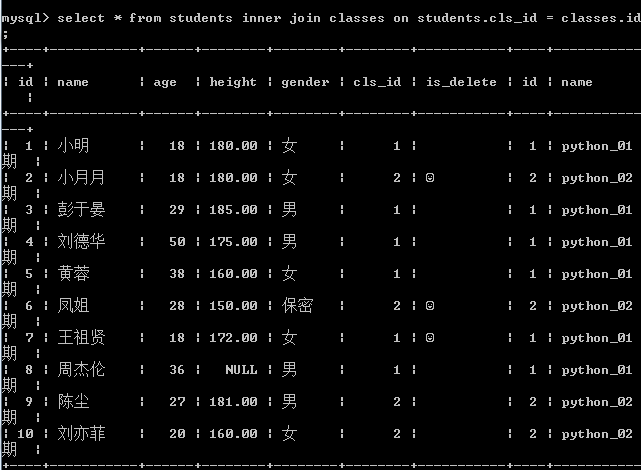
优化
-- 按照要求显示姓名、班级
select students.*, classes.name from students inner join classes on students.cls_id = classes.id;
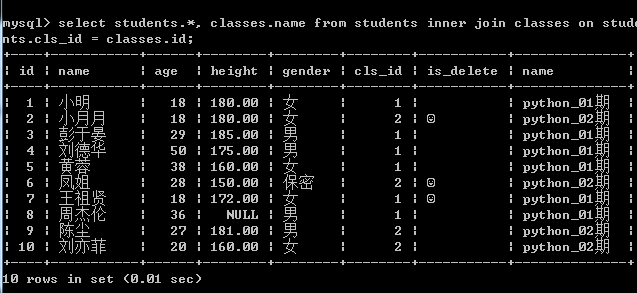
给表起名字
select s.*, c.name from students as s inner join classes as c on s.cls_id = c.id;
加排序
-- 查询 有能够对应班级的学生以及班级信息,按照班级进行排序
select c.name, s.* from students as s inner join classes as c on s.cls_id = c.id order by c.name, s.id;

2.62 左连接(left join)(谁写在left左边,就以谁为基准)
-- 查询每位学生对应的班级信息
select * from students as s left join classes as c on s.cls_id = c.id;
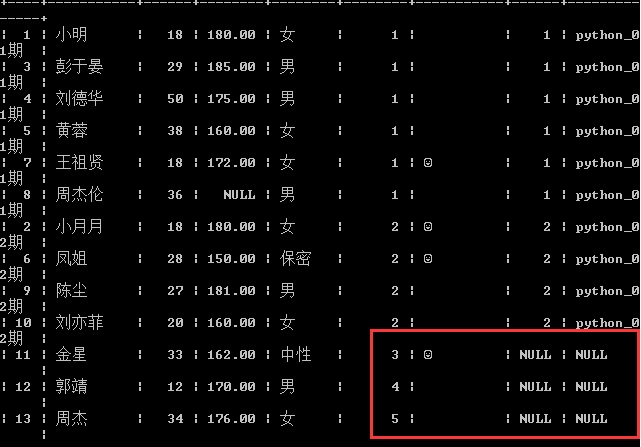
注意:没有对应班级的学生
-- 查询没有对应班级的学生信息
-- having: 是从结果集里判断结果
select * from students as s left join classes as c on s.cls_id = c.id having c.id is null;
-- where: 是从原表里判断结果
select * from students as s left join classes as c on s.cls_id = c.id where c.id is null;

2.7 自关联
如这种形式:

自己关联自己,p_id里存放上一级的id,null表示最高级。

2.71 创建areas表
create table areas(
aid int primary key,
atitle varchar(20),
pid int
);
插入数据,source areas.sql
-- 查xx省的xx市
select province.atitle, city.atitle from areas as province inner join areas as city on city.pid = province.aid having province.atitle="山东省";
2.8 子查询
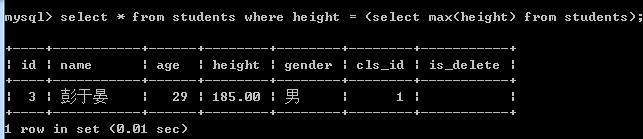
-- 查询最高的学生信息
select * from students where height = (select max(height) from students);
3. MySQL和Python交互
3.1 准备数据
3.2 SQL演练
3.3 数据库设计
3.4 python操作mysql步骤
3.5 增删改查
3.6 参数化
4. MySQL高级
Python高级笔记(九)Python使用MySQL的更多相关文章
- python3.4学习笔记(九) Python GUI桌面应用开发工具选择
python3.4学习笔记(九) Python GUI桌面应用开发工具选择 Python GUI开发工具选择 - WEB开发者http://www.admin10000.com/document/96 ...
- Python 高级网络操作 - Python Advanced Network Operations
Python 高级网络操作 - Python Advanced Network Operations Half Open Socket, 一个单向的 socket 被称为 half open sock ...
- Python学习笔记九
Python学习笔记之九 为什么要有操作系统 管理硬件,提供接口. 管理调度进程,并且将多个进程对硬件的竞争变得有序. 操作系统发展史 第一代计算机:真空管和穿孔卡片 没有操作系统,所有的程序设计直接 ...
- python 学习笔记 9 -- Python强大的自省简析
1. 什么是自省? 自省就是自我评价.自我反省.自我批评.自我调控和自我教育,是孔子提出的一种自我道德修养的方法.他说:“见贤思齐焉,见不贤而内自省也.”(<论语·里仁>)当然,我们今天不 ...
- python学习笔记(一):python简介和入门
最近重新开始学习python,之前也自学过一段时间python,对python还算有点了解,本次重新认识python,也算当写一个小小的教程.一.什么是python?python是一种面向对象.解释型 ...
- python学习笔记:python简介和入门
编程语言各有千秋.C语言适合开发那些追求运行速度.充分发挥硬件性能的程序.而Python是用来编写应用程序的高级编程语言. Python就为我们提供了非常完善的基础代码库,覆盖了网络.文件.GUI.数 ...
- python学习笔记(python简史)
一.python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum) 目前python主要应用领域: ·云计算 ·WEB开发 ·科学运算.人工智能 ·系统运维 ·金融:量化交 ...
- python学习笔记(1)--python特点
python诞生于复杂的信息系统时代,是计算机时代演进的一种选择. python的特点,通用语言,脚本语言,跨平台语言.这门语言可以用于普适的计算,不局限于某一类应用,通用性是它的最大特点.pytho ...
- python学习笔记之——python模块
1.python模块 Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. 模块让你能够有逻辑地组织你的 Python ...
- Python学习笔记 - day12 - Python操作NoSQL
NoSQL(非关系型数据库) NoSQL,指的是非关系型的数据库.NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称.用于超大规模数据的存储.(例如 ...
随机推荐
- mysqdump+binlog恢复数据
备份全库 [root@db01 b]# mysqldump -uroot -poldboy123 -A > /b/full.sql Warning: Using a password on th ...
- jetbreains的crack方法
https://zhile.io/2018/08/20/jetbrains-license-server-crack.html
- SHA-1算法——(2)
地址:https://www.alvestrand.no/objectid/1.3.14.3.2.26.html 地址:http://oidref.com/1.3.14.3.2.26 这个值好像是个标 ...
- TPA测试项目管理系统-测试用例管理
Test Project Administrator(简称TPA)是经纬恒润自主研发的一款专业的测试项目管理工具,目前已广泛的应用于国内二十余个整车厂和零部件供应商.它可以管理测试过程 ...
- class Pagination(object)分页源码
class Pagination(object): def init(self, current_page, all_count, per_page_num=10, pager_count=11): ...
- UVA 13024: Saint John Festival(凸包+二分 ,判定多个点在凸包内)
题意:给定N个点,Q次询问,问当前点知否在N个点组成的凸包内. 思路:由于是凸包,我们可以利用二分求解. 二分思路1:求得上凸包和下凸包,那么两次二分,如果点在对应上凸包的下面,对应下凸包的上面,那么 ...
- spark-scala开发的第一个程序WordCount
package ***** import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Ar ...
- numpy函数库中一些常用函数的记录
##numpy函数库中一些常用函数的记录 最近才开始接触Python,python中为我们提供了大量的库,不太熟悉,因此在<机器学习实战>的学习中,对遇到的一些函数的用法进行记录. (1) ...
- faster-rcnn系列原理介绍及概念讲解
faster-rcnn系列原理介绍及概念讲解 faster-rcnn系列原理介绍及概念讲解2 转:作者:马塔 链接:https://www.zhihu.com/question/42205480/an ...
- LeetCode 1059. All Paths from Source Lead to Destination
原题链接在这里:https://leetcode.com/problems/all-paths-from-source-lead-to-destination/ 题目: Given the edges ...