B+树比B树更适合实际应用中操作系统的文件索引和数据库索引
B+树比B树更适合实际应用中操作系统的文件索引和数据库索引
为什么选择B+树作为数据库索引结构?
背景
首先,来谈谈B树。为什么要使用B树?我们需要明白以下两个事实:
【事实1】
不同容量的存储器,访问速度差异悬殊。以磁盘和内存为例,访问磁盘的时间大概是ms级的,访问内存的时间大概是ns级的。有个形象的比喻,若一次内存访问需要1秒,则一次外存访问需要1天。所以,现在的存储系统,都是分级组织的。最常用的数据尽可能放在更高层、更小的存储器中,只有在当前层找不到,才向更低层、更大的存储器中寻找。这也就解释了,当处理大规模数据的时候(指无法将数据一次性存入内存),算法的实际运行时间,往往取决于数据在不同存储级别之间的IO次数。因此,要想提升速度,关键在于减少IO。
【事实2】
磁盘读取数据是以数据块(block)(或者:页,page)为基本单位的,位于同一数据块中的所有数据都能被一次性全部读取出来。换句话说,从磁盘中读1B,与读1KB几乎一样快!因此,想要提升速度,应该利用外存批量访问的特点,在一些文章中,也称其为磁盘预读。系统之所以这么设计,是基于一个著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用,程序运行期间所需要的数据通常比较集中
B树
假设有10亿条记录(1000*1000*1000),如果使用平衡二叉搜索树(Balanced Binary Search Tree, BBST),最坏的情况下,查找需要log(2, 10^9) = 30次 I/O 操作,且每次只能读出一个关键字(即如果这次读出来的关键字不是我要查找的,就要再进行一次I/O去读取数据)。如果换成B树,会是怎样的情况呢?
B 树是为了磁盘或其它辅助存储设备而设计的一种多叉平衡搜索树。多级存储系统中使用B树,可针对外部查找,大大减少I/O次数。通过B树,可充分利用外存对批量访问的高效支持,将此特点转化为优点。每下降一层,都以超级结点为单位(超级结点就是指一个结点内包含多个关键字),从磁盘中读入一组关键字。那么,具体多大为一组呢?
一个节点存放多少数据视磁盘的数据块大小而定,比如磁盘中1 block的大小有1024KB,假设每个关键字的大小为 4 Byte,则可设定每一组的大小m = 1024 KB / 4 Byte = 256。目前,多数数据库系统采用 m = 200~300。假设取m = 256,则B树存储1亿条数据的树的高度大概是 log(256, 10^9) = 4,也就是单次查询所需要进行的I/O次数不超过 4 次,由此大大减少了I/O次数。
一般来说,B树的根节点常驻于内存中,B树的查找过程是这样的:首先,由于一个节点内包含多个(比如,是256个)关键码,所以需要先顺序/二分来查找,如果找到则查找成功;如果失败,则根据相应的引用从磁盘中读入下一层的节点数据(这里就涉及到一次磁盘I/O),同样的在节点内顺序查找,如此往复进行...事实上,B树查找所消耗的时间很大一部分花在了I/O上,所以减少I/O次数是非常重要的。
B树的定义
B树就是平衡的多路搜索树,所谓的m阶B树,即m路平衡搜索树。根据维基百科的定义,一棵m阶B树需满足以下要求:
- 每个结点至多含有m个分支节点(m>=2)。
- 除根结点之外的每个非叶结点,至少含有┌m/2┐个分支。
- 若根结点不是叶子结点,则至少有2个孩子。
- 一个含有k个孩子的非叶结点包含k-1个关键字。 (每个结点内的关键字按升序排列)
- 所有的叶子结点都出现在同一层。实际上这些结点并不存在,可以看作是外部结点。
根据节点的分支的上下限,也可以称其为(┌m/2┐, m)树。比如,阶数m=4时,这样的B树也可以称为(2,4)树。(事实上,(2,4)树是一棵比较特殊的B树,它和红黑树有着特别的渊源!后面谈及红黑树时会谈到。)
并且,每个内部结点的关键字都作为其子树的分隔值。比如,某结点含有2个关键字(假设为a1和a2),也就是说该结点含有3个子树。那么,最左子树的关键字均小于a1;中间子树的关键字介于a1~a2;最右子树的关键字均大于a2。
示例,一棵3阶的B树是这个样子:
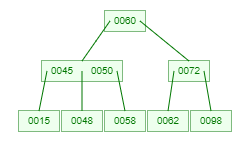
B树的高度(了解)
假定一棵B树非空,具有n个关键字、高度为h(令根结点为第1层)、阶数为m,那么该B树的最大高度和最小高度分别是多少?
最大高度
当树的高度最大时,则每个结点含有的关键字数应该尽量少。根据定义,根结点至少有2个孩子(即1个关键字),除根结点之外的非叶结点至少有┌m/2┐个孩子(即┌m/2┐-1个关键字),为了描述方便,这里令p = ┌m/2┐。
第1层 1个结点 (含1个关键字)
第2层 2个结点 (含2*(p-1)个关键字)
第3层 2p个结点 (含2p*(p-1)^2个关键字)
...
第h层 2p^(h-2)个结点
故总的结点个数n
≥ 1+(p-1)*[2+2p+2p^2+...+2p^(h-2)]
≥ 2p^(h-1)-1
从而推导出 h ≤ log_p[(n+1)/2] + 1 (其中p为底数,p=┌m/2┐)最小高度
当树的高度最低时,则每个结点的关键字都至多含有m个孩子(即m-1个关键字),则有
n ≤ (m-1)*(1 + m + m^2 +...+ m^(h-1)) = m^h - 1
从而推导出 h ≥ log_m(n+1) (其中m为底数)B+树
B+树的定义
B+树是B树的一个变体,B+树与B树最大的区别在于:
- 叶子结点包含全部关键字以及指向相应记录的指针,而且叶结点中的关键字按大小顺序排列,相邻叶结点用指针连接。
- 非叶结点仅存储其子树的最大(或最小)关键字,可以看成是索引。
一棵3阶的B+树示例:(好好体会和B树的区别,两者的关键字是一样的)
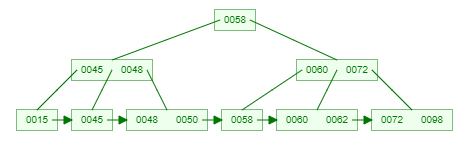
问:为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
答:
- B+树更适合外部存储。由于内结点不存放真正的数据(只是存放其子树的最大或最小的关键字,作为索引),一个结点可以存储更多的关键字,每个结点能索引的范围更大更精确,也意味着B+树单次磁盘IO的信息量大于B树,I/O的次数相对减少。
- MySQL是一种关系型数据库,区间访问是常见的一种情况,B+树叶结点增加的链指针,加强了区间访问性,可使用在区间查询的场景;而使用B树则无法进行区间查找。
参考:
1)清华大学邓俊辉数据结构-高级搜索树
2)https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html (数据结构可视化)
B+树比B树更适合实际应用中操作系统的文件索引和数据库索引的更多相关文章
- 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
B树: B+树 1) B+-tree的磁盘读写代价更低 B+-tree的内部结点并没有指向关键字具体信息的指针.因此其内部结点相对B 树更小.如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所 ...
- 哪种方式更适合在React中获取数据?
作者:Dmitri Pavlutin 译者:小维FE 原文:dmitripavlutin.com 国外文章,笔者采用意译的方式,以保证文章的可读性. 当执行像数据获取这样的I/O操作时,你必须发起获取 ...
- 从B 树、B+ 树、B* 树谈到R 树
从B 树.B+ 树.B* 树谈到R 树 作者:July.weedge.Frankie.编程艺术室出品. 说明:本文从B树开始谈起,然后论述B+树.B*树,最后谈到R 树.其中B树.B+树及B*树部分由 ...
- 二叉树学习笔记之B树、B+树、B*树
动态查找树主要有二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Search Tree), 红黑树 (Red-Black Tree ), 都是典型的 ...
- 从B树、B+树、B*树谈到R 树
从B 树.B+ 树.B* 树谈到R 树 作者:July.weedge.Frankie.编程艺术室出品. 说明:本文从B树开始谈起,然后论述B+树.B*树,最后谈到R 树.其中B树.B+树及B*树部分由 ...
- B-树、B+树、B*树的区别
原文地址: http://blog.csdn.net/dazhong159/article/details/7963846/ B-树.B+树.B*树的区别 2012-09-11 22:41 97 ...
- B树,B+树,B*树
参考资料 http://www.cnblogs.com/Bob-FD/archive/2012/06/20/2556505.html 第一节.B树.B+树.B*树 1.前言: 动态查找树主要有:二叉查 ...
- 二叉查找树及B-树、B+树、B*树变体
动态查找树主要有二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Search Tree), 红黑树 (Red-Black Tree ), 都是典型的 ...
- 【转】B树、B+树、B*树
出处:http://blog.csdn.net/v_JULY_v 1.前言: 动态查找树主要有:二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Se ...
随机推荐
- shell脚本中大于,大于等于,小于,小于等于、不等于的表示方法
症状:shell中大于,大于等于,小于等于,lt,gt ,ne,ge,le 很对应. 应对方法: 大于 -gt (greater than) 小于 -lt (less than) 大于或等于 -ge ...
- hdfs的文件个数 HDFS Quotas Guide
HDFS Quotas Guide Overview HDFS允许管理员为多个每个目录设置使用的命名空间和空间的配额.命名空间配额和空间配额独立操作,但是这两种类型的配额的管理和实现非常类似. Nam ...
- 瀑布流插件|jquery.masonry|使用demo
Maonsry+Infinite-Scroll实现滚动式分页,网上有很多,这里只说: 瀑布流插件的一个基本使用,附上基本功能的demo <html> <head> <me ...
- Ajax无法访问回调函数seccess问题
1,后台返回的数据是标准json格式,前端dataType也是josn, 2,没有跨域访问, 但是一直只执行error方法, 原因出在: 应设置为button按钮,指明类型为button
- Java逆变(Covariant)和协变(Contravariant)
1. 定义 逆变和协变描述的经过类型变换后的类型之间的关系.假如A和B表示类型,f表示类型变换,A ≤B表示A是B的子类型,那么 如果A ≤B,f(A) ≤f(B),那么f是协变 如果A ≤B,f(B ...
- Codeforces Round #558 (Div. 2)-Cat Party (Hard Edition)-(前缀和 + 模拟)
http://codeforces.com/problemset/problem/1163/B2 题意:有n天,每天有一个颜色,截取前x天,随便抽掉一天,使剩下的各个颜色出现的次数相等. 解题,也可以 ...
- A1016 | 磨人的大模拟
这题写得头晕……明天我再评价 #include <stdio.h> #include <memory.h> #include <math.h> #include & ...
- DISCO Presents Discovery Channel Code Contest 2020 Qual题解
传送门 \(A\) 咕咕 int x,y; int c[4]={0,300000,200000,100000}; int res; int main(){ cin>>x>>y; ...
- mysql5.7密码过期ERROR 1862 (HY000): Your password has expired. To log in you must change
环境: ubuntu14.04 mysql5.7 一.mysql5.7 密码过期问题 报错: ERROR 1862 (HY000): Your password has expired. To lo ...
- ubuntu之路——day17.4 卷积神经网络示例
以上是一个识别手写数字的示例 在这个示例中使用了两个卷积-池化层,三个全连接层和最后的softmax输出层 一般而言,CNN的构成就是由数个卷积层紧跟池化层再加上数个全连接层和输出层来构建网络. 在上 ...