大数据基础总结---MapReduce和YARN技术原理
Map Reduce和YARN技术原理
学习目标
- 熟悉MapReduce和YARN是什么
- 掌握MapReduce使用的场景及其原理
- 掌握MapReduce和YARN功能与架构
- 熟悉YARN的新特性
MapReduce的概述
MapReduce基于Google发布的MapReduce论文设计开发,用于大规模数据集(大于1TB)的并行计算
具有如下特点:
- 易于编程:程序员仅需描述做什么,具体怎么做交由系统的执行框架处理。
- 良好的扩展性:可通过添加节点以扩展集群能力。
- 高容错性:通过计算迁移或数据迁移等策略提高集群的可用性与容错性。
当某些节点发生故障时,可以通过计算迁移或数据迁移在其他节点继续执行任务,保证任务执行成功。
- MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。
- MapReduce是一个并行计算与运行软件框架(Software Framework)。
- MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。
YARN的概述
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者) 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
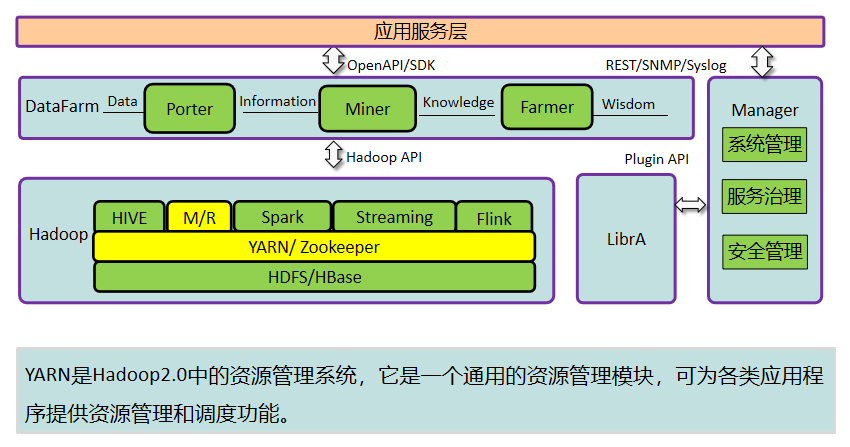
MapReduce过程详解
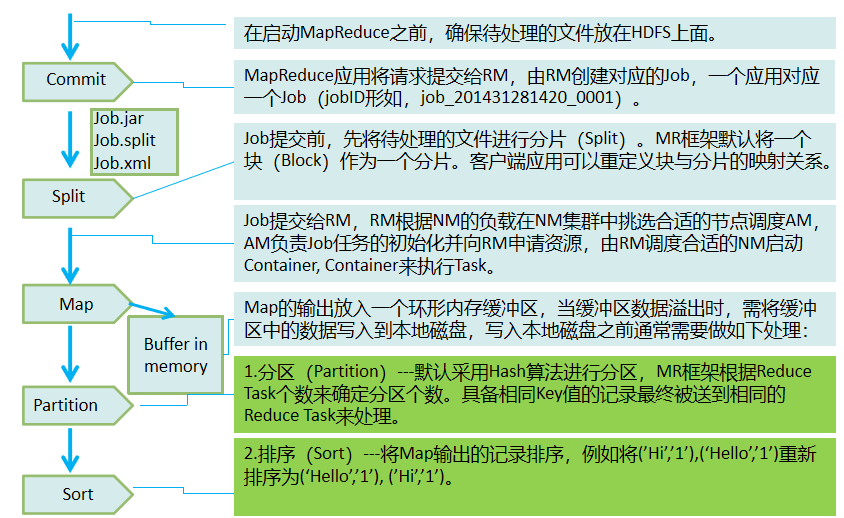
- 分片的必要性:MR框架将一个分片和一个Map TasK对应,即一个Map Task只负责处理一个数据分片。数据分片的数量确定了为这个Job创建Map Task的个数。
- Application Master(AM)负责一个Application生命周期内的所有工作。包括:与RM调度器协商以获取资源;将得到的资源进一步分配给内部任务(资源的二次分配);与NM通信以启动/停止任务;监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
- ResourceManager(RM) 负责集群中所有资源的统一管理和分配。它接收来自各个节点(NodeManager)的资源汇报信息,并根据收集的资源按照一定的策略分配给各个应用程序。
- NodeManager(NM)是每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
- MR组件在FI中只有jobhistoryserver实例,它只是存储任务的执行记录,执行列表,没有它,也可以运行任务。但是无法查询任务的详细信息。
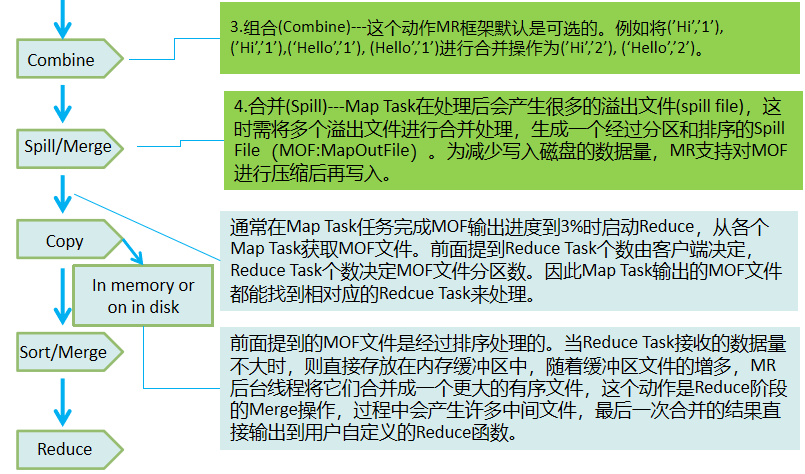
Reduce阶段的三个过程:
- Copy:Reduce Task从各个Map Task拷贝MOF文件。
- Sort:通常又叫Merge,将多个MOF文件进行合并再排序。
- Reduce:用户自定义的Reduce逻辑。
Shuffle机制

Shuffle的定义:Map阶段和Reduce阶段之间传递中间数据的过程,包括Reduce Task从各个Map Task获取MOF文件的过程,以及对MOF的排序与合并处理。
典型程序WorldCound举例
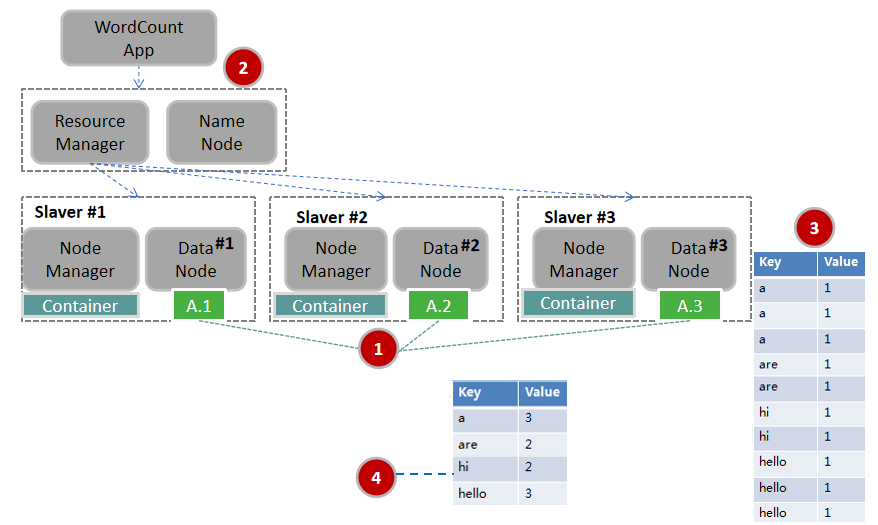
假设要分析一个大文件A里每个英文单词出现的个数,利用MapReduce框架能快速实现这一统计分析。
- 第一步:待处理的大文件A已经存放在HDFS上,大文件A被切分的数据块A.1、A.2、A.3分别存放在Data Node #1、#2、#3上。
- 第二步:WordCount分析处理程序实现了用户自定义的Map函数和Reduce函数。WordCount将分析应用提交给RM,RM根据请求创建对应的Job,并根据文件块个数按文件块分片,创建3个 MapTask 和 3个Reduce Task,这些Task运行在Container中。
- 第三步:Map Task 1、2、3的输出是一个经分区与排序(假设没做Combine)的MOF文件,记录形如表所示。
- 第四步:Reduce Task从 Map Task获取MOF文件,经过合并、排序,最后根据用户自定义的Reduce逻辑,输出如表所示的统计结果。
WorldCound程序功能
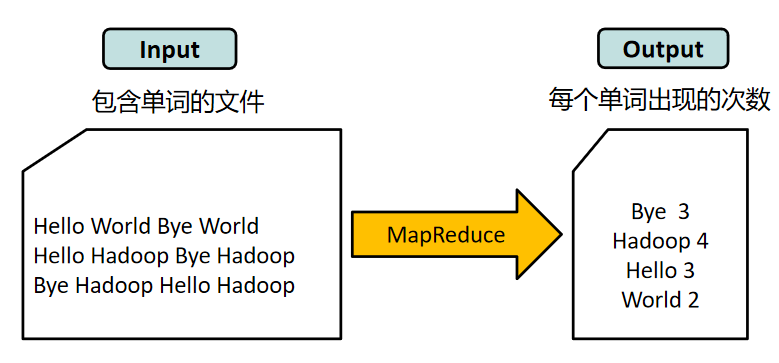
WorldCound的Map过程
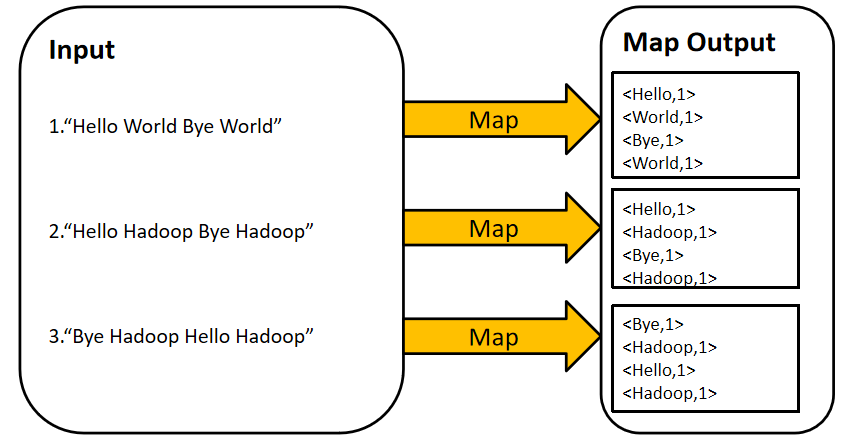
WorldCound的Reduce过程
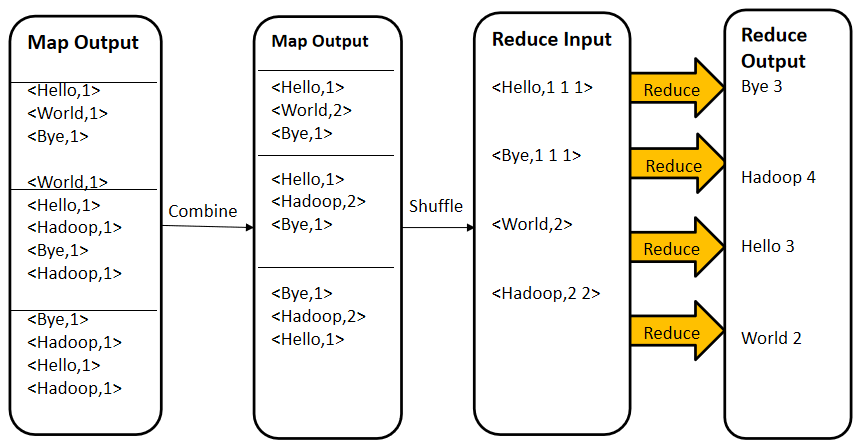
YARN的组件架构
在图中有两个客户端向YARN提交任务,蓝色表示一个任务流程,棕色表示另一个任务流程。
- 首先client提交任务,ResourceManager接收到任务,然后启动并监控起来的第一个Container,也就是App Mstr。
- App Mstr通知nodemanager管理资源并启动其他container。
- 任务最终是运行在Container当中。
MapReduce On YARN任务调度流程
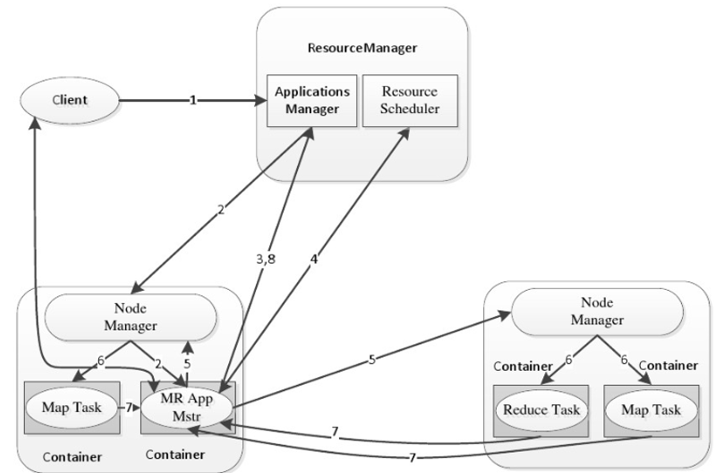
- 步骤1:用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
- 步骤2:ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster 。
- 步骤3:ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
- 步骤4:ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
- 步骤5:一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
- 步骤6:NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 步骤7:各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
- 步骤8 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
YARN HA方案
YARN中的ResourceManager负责整个集群的资源管理和任务调度,YARN高可用性方案通过引入冗余的ResourceManager节点的方式,解决了ResourceManager 单点故障问题。
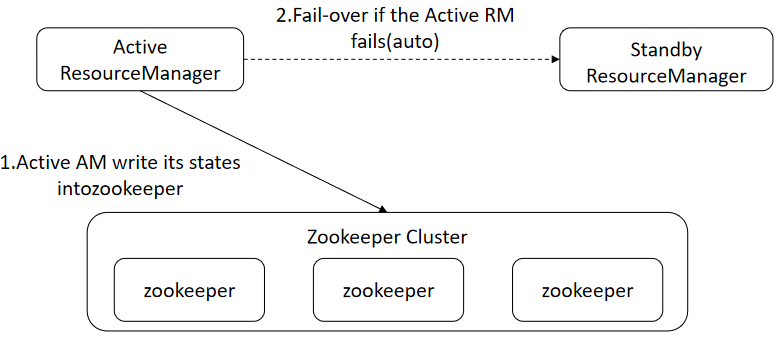
- ResourceManager的高可用性方案是通过设置一组Active/Standby的ResourceManager节点来实现的。与HDFS的高可用性方案类似,任何时间点上都只能有一个ResourceManager处于Active状态。当Active状态的ResourceManager发生故障时,可通过自动或手动的方式触发故障转移,进行Active/Standby状态切换。
- 在未开启自动故障转移时,YARN集群启动后,管理员需要在命令行中使用YARN rmadmin命令手动将其中一个ResourceManager切换为Active状态。当需要执行计划性维护或故障发生时,则需要先手动将Active状态的ResourceManager切换为Standby状态,再将另一个ResourceManager切换为Active状态。
- 开启自动故障转移后,ResourceManager会通过内置的基于ZooKeeper实现的ActiveStandbyElector来决定哪一个ResouceManager应该成为Active节点。当Active状态的ResourceManager发生故障时,另一个ResourceManager将自动被选举为Active状态以接替故障节点。
- 当集群的ResourceManager以HA方式部署时,客户端使用的“YARN-site.xml”需要配置所有ResourceManager地址。客户端(包括ApplicationMaster和NodeManager)会以轮询的方式寻找Active状态的ResourceManager。如果当前Active状态的ResourceManager无法连接,那么会继续使用轮询的方式找到新的ResourceManager。
YARN APPMaster容错机制
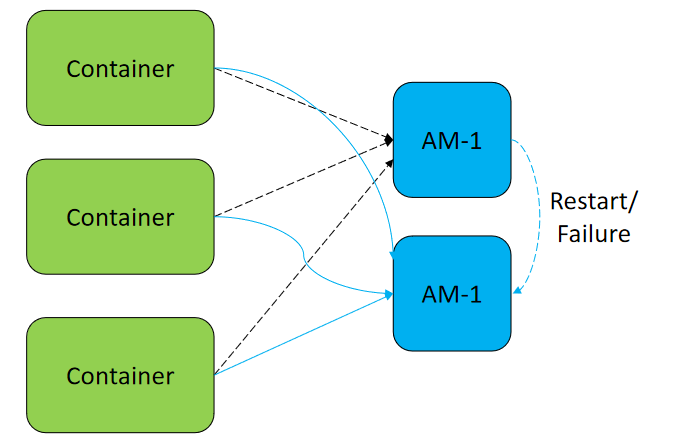
- 在YARN中,ApplicationMaster(AM)与其他Container类似也运行在NodeManager上(忽略未管理的AM)。AM可能会由于多种原因崩溃、退出或关闭。如果AM停止运行,ResourceManager(RM)会关闭ApplicationAttempt中管理的所有Container,包括当前任务在NodeManager(NM)上正在运行的所有Container。RM会在另一计算节点上启动新的ApplicationAttempt。
- 不同类型的应用希望以多种方式处理AM重新启动的事件。MapReduce类应用目标是不丢失任务状态,但也能允许一部分的状态损失。但是对于长周期的服务而言,用户并不希望仅仅由于AM的故障而导致整个服务停止运行。
- YARN支持在新的ApplicationAttempt启动时,保留之前Container的状态,因此运行中的作业可以继续无故障的运行。
资源管理
当前YARN支持内存和CPU两种资源类型的管理和分配。 每个NodeManager可分配的内存和CPU的数量可以通过配置选项设置(可在YARN服务配置页面配置)。
- Yarn.nodemanager.resource.memory-mb
- Yarn.nodemanager.vmem-pmem-ratio
- Yarn.nodemanager.resource.cpu-vcore
- Yarn.nodemanager.resource.memory-mb表示用于当前NodeManager上可以分配给容器的物理内存的大小,单位:MB。必须小于NodeManager服务器上的实际内存大小。
- Yarn.nodemanager.vmem-pmem-ratio表示为容器设置内存限制时虚拟内存跟物理内存的比值。容器分配值使用物理内存表示的,虚拟内存使用率超过分配值的比例不允许大于当前这个比例。
- Yarn.nodemanager.resource.cpu-vcore表示可分配给container的CPU核数。建议配置为CPU核数的1.5-2倍。
资源分配模型

- 调度器维护一群队列的信息。用户可以向一个或者多个队列提交应用。
- 每次NM心跳的时候,调度器根据一定的规则选择一个队列,再在队列上选择一个应用,尝试在这个应用上分配资源。
- 调度器会优先匹配本地资源的申请请求,其次是同机架的,最后是任意机器的。
- 当任务提交上来,首先会声明提交到哪个队列上,调度器会分配队列,如果没有指定则任务运行在默认队列。
- 队列是封装了集群资源容量的资源集合,占用集群的百分比例资源。
- 队列分为父队列,子队列,任务最终是运行在子队列上的。父队列可以有多个子队列。
- 调度器选择队列上的应用,然后根据一些算法给应用分配资源。
容量调度器的介绍
容量调度器:Capacity Scheduler 。
- 容量调度器使得Hadoop应用能够共享的、多用户的、操作简便的运行在集群上,同时最大化集群的吞吐量和利用率。
- 容量调度器以队列为单位划分资源,每个队列都有资源使用的下限和上限。每个用户可以设定资源使用上限。管理员可以约束单个队列、用户或作业的资源使用。支持作业优先级,但不支持资源抢占。
容量调度器的特点
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上限,所有提交到该队列的应用程序共享这些资源。
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,当该队列有新的应用程序提交,则其他队列释放的资源会归还给该队列。
- 支持优先级:队列支持任务优先级调度(默认是FIFO)。
- 多重租赁:支持多用户共享集群和多应用程序同时运行。为防止单个应用程序、用户或者队列独占集群资源,管理员可为之增加多重约束。
- 动态更新配置文件:管理员可根据需要动态修改配置参数,以实现在线集群管理。
容量调度器的任务选择
调度时,首先按以下策略选择一个合适队列:
- 资源利用量最低的队列优先,比如同级的两个队列Q1和Q2,它们的容量均为30,而Q1已使用10,Q2已使用12,则会优先将资源分配给Q1。
- 最小队列层级优先,例如:QueueA与QueueB.childQueueB,则QueueA优先。
- 资源回收请求队列优先。
然后按以下策略选择该队列中一个任务:
- 按照任务优先级和提交时间顺序选择,同时考虑用户资源量限制和内存限制。
队列资源限制(1)
队列的创建是在多租户页面,当创建一个租户关联YARN服务时,会创建同名的队列。比如先创建QueueA,QueueB两个租户,即对应YARN两个队列。
队列资源限制(2)
队列的资源容量(百分比),有default、QueueA、QueueB三个队列,每个队列都有一个[队列名].capacity配置:
- Default队列容量为整个集群资源的20%。
- QueueA队列容量为整个集群资源的10%。
- QueueB队列容量为整个集群资源的10%,后台有一个影子队列root-default使队列之和达到100% 。
- 在集群的Manager页面点击“租户管理”》“动态资源计划”》“资源分布策略”可以看到,可配置各队列资源容量。
- 影子队列:是不对外呈现的一个队列。以XX-default为名字,目的是为了使同级的队列容量之和不够一百时,将剩余容量值赋予此队列(容量调度器要求同级队列容量和要为100)。
队列资源限制(3)
共享空闲资源
- 由于存在资源共享,因此一个队列使用的资源可能超过其容量(例如QueueA.capacity),而最大资源使用量可通过参数限制。
- 如果某个队列任务较少,可将剩余资源共享给其他队列,例如QueueA的maximum-capacity配置为100,假设当前只有QueueA在运行任务,理论上QueueA可以占用整个集群100%的资源。
参数:Yarn.scheduler.capacity.root.QueueA.maximum-capacity
用户限制和任务限制
用户限制和任务限制的参数可通过“租户管理”>“动态资源计划”>“队列配置”进行配置。
用户限制(1)
每个用户最低资源保障(百分比):
- 任何时刻,一个队列中每个用户可使用的资源量均有一定的限制,当一个队列中同时运行多个用户的任务时,每个用户的可使用资源量在一个最小值与最大值之间浮动,其中,最大值取决于正在运行的任务数目,而最小值则由minimum-user-limit-percent决定。
- 例如,设置队列A的这个值为25,即Yarn.scheduler.capacity.root.QueueA.minimum-user-limit-percent=25,那么随着提任务的用户增加,队列资源的调整如下:
|
第1个用户提交任务到QueueA |
会获得QueueA的100%资源。 |
|
第2个用户提交任务到QueueA |
每个用户会最多获得50%的资源。 |
|
第3个用户提交任务到QueueA |
每个用户会最多获得33.33%的资源。 |
| 第4个用户提交任务到QueueA |
每个用户会最多获得25%的资源。 |
|
第5个用户提交任务到QueueA |
为了保障每个用户最低能获得25%的资源,第5个用户将无法再获取到QueueA的资源,必须等待资源的释放。 |
用户限制(2)
每个用户最多可使用的资源量(所在队列容量的倍数):
- queue容量的倍数,用来设置一个user可以获取更多的资源。 Yarn.scheduler.capacity.root.QueueD.user-limit-factor=1。默认值为1,表示一个user获取的资源容量不能超过queue配置的capacity,无论集群有多少空闲资源,最多不超过maximum-capacity。
用户可以使用超过capacity的资源,但不超过maximum-capacity。
任务限制
最大活跃任务数:
- 整个集群中允许的最大活跃任务数,包括运行或挂起状态的所有任务,当提交的任务申请数据达到限制以后,新提交的任务将会被拒绝。默认值10000。
每个队列最大任务数:
- 对于每个队列,可以提交的最大任务数,以QueueA为例,可以在队列配置页面配置,默认是1000,即此队列允许最多1000个活跃任务。
每个用户可以提交的最大任务数:
- 这个数值依赖每个队列最大任务数。根据上面的数据, QueueA最多可以提交1000个任务,那么对于每个用户而言,可以向QueueA提交的最大任务数为1000* 用户最低资源保障率(假设25%)* 用户可使用队列资源的倍数(假设1)。
- 用户最低资源保障率:Yarn.scheduler.capacity.root.QueueA.minimum-user-limit-percent。
- 用户可使用队列资源的倍数:Yarn.scheduler.capacity.root.QueueA.user-limit-factor。
查看队列信息
- 队列的信息可以通过YARN webUI进行查看,进入方法是“服务管理”>“YARN”>“ResouceManager(主)”>“Scheduler”。
增强特性 - YARN动态内存管理
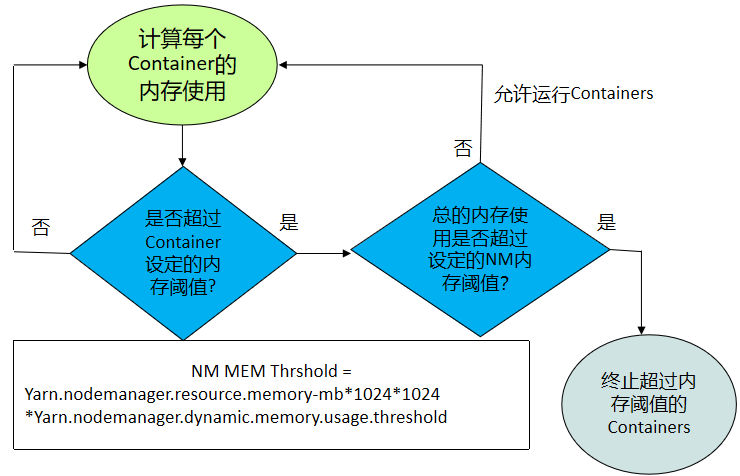
- 动态内存管理可用来优化NodeManager中Containers的内存利用率。任务在运行过程中可能产生多个Container。
- 当前,当单个节点上的Container超过Container运行内存大小时,即使节点总的配置内存利用还很低,NodeManager也会终止这些Containers。这样就会经常使用户作业失败。
- 动态内存管理特性在当前是一个改进,只有当NodeManager中的所有Containers的总内存使用超过了已确定的阈值,NM总内存阈值的计算方法是
- Yarn.nodemanager.resource.memory-mb*1024*1024*Yarn.nodemanager.dynamic.memory.usage.threshold,单位GB,那么那些内存使用过多的Containers才会被终止。
- 举例,假如某些Containers的物理内存利用率超过了配置的内存阈值,但所有Containers的总内存利用率并没有超过设置的NodeManager内存阈值,那么那些内存使用过多的Containers仍可以继续运行。
增强特性 - YARN基于标签调度
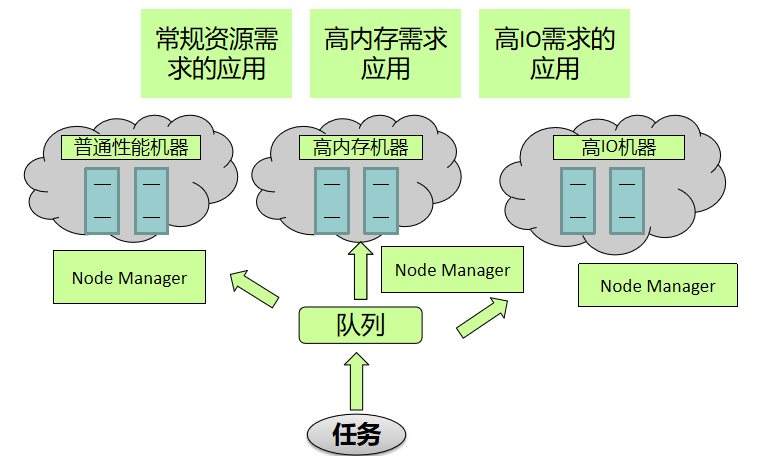
- 在没有标签调度之前,任务提交到哪个节点上是无法控制的,会根据一些算法及条件,集群随机分配到某些节点上。而标签调度可以指定任务提交到哪些节点上。
- 比如之前需要消耗高内存的应用提交上来,由于运行在那些节点不可控,任务可能运行在普通性能的机器上。
- Label based scheduling是一种调度策略。该策略的基本思想是:用户可以为每个nodemanager标注一个标签,比如high-memory,high-IO等进行分类,以表明该nodemanager的特性;同时,用户可以为调度器中每个队列标注一个标签,即队列与标签绑定,这样,提交到某个队列中的作业,只会使用标注有对应标签的节点上的资源,即任务实际运行在打有对应标签的节点上。
- 将耗内存消耗型的任务提交到绑定了high-memry的标签的队列上,那么任务就可以运行在高内存机器上。
思考题:
1 请简述MapReduce的工作原理。
答案:
- 一个MapReduce作业(job)通常会把输入的数据集切分为若干独立的数据块,由Map任务并行处理它们。框架会对map函数的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和和监控,以及重新执行已经失败的任务。
2 请简述YARN的工作原理。
答案:
- 用户将应用程序提交到RM;RM为AM申请资源,与某个NM通信,启动AM;AM与RM通信,为执行任务申请资源;得到资源后与NM通信,启动相应的任务;所有任务结束后,AM向RM注销,整个应用结束。
3 下面哪些是MapReduce的特点?( )
A 易于编程
B 良好的扩展性
C 实时计算
D 高容错性
答案:ABD
4 YARN中资源抽象用什么表示?( )
A 内存
B CPU
C Container
D 磁盘空间
答案:C
5 下面哪个是MapReduce适合做的?( )
A 迭代计算
B 离线计算
C 实时交互计算
D 流式计算
答案:B
6 容量调度器有哪些特点?( )
A 容量保证
B 灵活性
C 多重租赁
D 动态更新配置文件
答案:ABCD
大数据基础总结---MapReduce和YARN技术原理的更多相关文章
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- Atitit. BigConfirmTips 控件 大数据量提示确认控件的原理and总结O9
Atitit. BigConfirmTips 控件 大数据量提示确认控件的原理and总结O9 1. 主要的涉及的技术 1 2. 主要的流程 1 3. 调用法new confirmO9t(); 1 4. ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
随机推荐
- Vim操作:打开文件
1.打开文件并定位到某一行 vim +20 vendor/laravel/framework/src/Illuminate/Support/Facades/Facade.php # 定位至第20行 2 ...
- null,undefined.'',false关系
null == undefined //truefalse =='' //true boolean类型跟其它类型==时,会转换成Number类型 Number类型跟String类型==时,string ...
- 配置全文搜索引擎solr
前言 solr是apache下的一个子项目,用java编写基于Lucene开发的全文搜索服务器,不同于Lucene,solr一个完成的搜索服务器,提供了众多接口调用,而Lucene只是个工具包.如果用 ...
- 【已采纳】supervisor在服务器端(linux),如何一直运行你的python代码
正式开始之前,说一下我的项目是放在虚拟环境里的,具体什么是虚拟环境,怎么创建,请自行百度噢! 一.安装 源码安装 先下载最新的supervisor安装包:https://pypi.python.o ...
- Centos7安装宝塔控制面板
目录 宝塔面板安装和使用图文教程 1,通过ssh工具登录服务器 2,安装宝塔面板 2,登录宝塔面板 3,设置宝塔面板 3.1,首先我们进入面板设置 3.2,更改面板端口 3.3,绑定域名 3.4,绑定 ...
- if语句编写Mysql备份脚本
#!/bin/bash #auto bakcup mysql db #by authors zgh #define backup path BAK_DIR=/data/backup/`date +%Y ...
- 华为云fusionsphere 6.1组件功能
[fsp@controller-21 ~]$ openstack --version ##fusionsphere 6.1基于openstack 2.2.1 [fsp@controller-21 ...
- 10-剑指offer: 数值的整数次方
题目描述 给定一个double类型的浮点数base和int类型的整数exponent.求base的exponent次方. 代码 class Solution { public: double Powe ...
- JS高阶---浏览器内核
不同浏览器的内核,不太一样 360双核切换机制 一般涉及到金钱交易时,会切换到Trident内核,因为IE内核安全性较稳 不涉及金钱利益时,则会使用webkit内核 (1)内核是由很多模块构成 注意: ...
- mybatis多对多关联查询
多对多关系 一个学生可以选多门课程,而一门课程可以由多个学生选择,这就是一个典型的多对多关联关系.所谓多对多关系,其实是由两个互反的一对多关系组成.即多对多关系都会通过一个中间表来建立,例如选课表.学 ...