Flink Flow

1. Create environment for stream computing
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().disableSysoutLogging();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
public static StreamExecutionEnvironment getExecutionEnvironment() {
if (contextEnvironmentFactory != null) {
return contextEnvironmentFactory.createExecutionEnvironment();
}
// because the streaming project depends on "flink-clients" (and not the other way around)
// we currently need to intercept the data set environment and create a dependent stream env.
// this should be fixed once we rework the project dependencies
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
if (env instanceof ContextEnvironment) {
return new StreamContextEnvironment((ContextEnvironment) env);
} else if (env instanceof OptimizerPlanEnvironment || env instanceof PreviewPlanEnvironment) {
return new StreamPlanEnvironment(env);
} else {
return createLocalEnvironment();
}
}
2. Now we need to add the data source for further computing
DataStream<KafkaEvent> input = env
.addSource( new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-topic"),
new KafkaEventSchema(),
parameterTool.getProperties()).assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.keyBy("word")
.map(new RollingAdditionMapper());
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function) {
return addSource(function, "Custom Source");
}
@SuppressWarnings("unchecked")
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource<OUT, ?> sourceOperator;
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({ "unchecked", "rawtypes" })
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
@Internal
public void addOperator(StreamTransformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
public KeyedStream<T, Tuple> keyBy(String... fields) {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));
}
private KeyedStream<T, Tuple> keyBy(Keys<T> keys) {
return new KeyedStream<>(this, clean(KeySelectorUtil.getSelectorForKeys(keys,
getType(), getExecutionConfig())));
}
3. The data from data source will be streamed into Flink Distributed Computing Runtime and the computed result will be transfered to data Sink.
input.addSink( new FlinkKafkaProducer010<>(
parameterTool.getRequired("output-topic"),
new KafkaEventSchema(),
parameterTool.getProperties()));
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// configure the type if needed
if (sinkFunction instanceof InputTypeConfigurable) {
((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());
}
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
getExecutionEnvironment().addOperator(sink.getTransformation());
return sink;
}
@Internal
public void addOperator(StreamTransformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
4. The last step is to start executing.
env.execute("Kafka 0.10 Example");
The mapper computing template is defined as blow.
private static class RollingAdditionMapper extends RichMapFunction<KafkaEvent, KafkaEvent> {
private static final long serialVersionUID = 1180234853172462378L;
private transient ValueState<Integer> currentTotalCount;
@Override
public KafkaEvent map(KafkaEvent event) throws Exception {
Integer totalCount = currentTotalCount.value();
if (totalCount == null) {
totalCount = 0;
}
totalCount += event.getFrequency();
currentTotalCount.update(totalCount);
return new KafkaEvent(event.getWord(), totalCount, event.getTimestamp());
}
@Override
public void open(Configuration parameters) throws Exception {
currentTotalCount = getRuntimeContext().getState(new ValueStateDescriptor<>("currentTotalCount", Integer.class));
}
}
http://www.debugrun.com/a/LjK8Nni.html
Flink Flow的更多相关文章
- 在 Cloudera Data Flow 上运行你的第一个 Flink 例子
文档编写目的 Cloudera Data Flow(CDF) 作为 Cloudera 一个独立的产品单元,围绕着实时数据采集,实时数据处理和实时数据分析有多个不同的功能模块,如下图所示: 图中 4 个 ...
- Flink Internals
https://cwiki.apache.org/confluence/display/FLINK/Flink+Internals Memory Management (Batch API) In ...
- Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Join Processin ...
- Flink - Juggling with Bits and Bytes
http://www.36dsj.com/archives/33650 http://flink.apache.org/news/2015/05/11/Juggling-with-Bits-and-B ...
- Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型 本文翻译自General Architecture and Process Model ----------------------------------------- ...
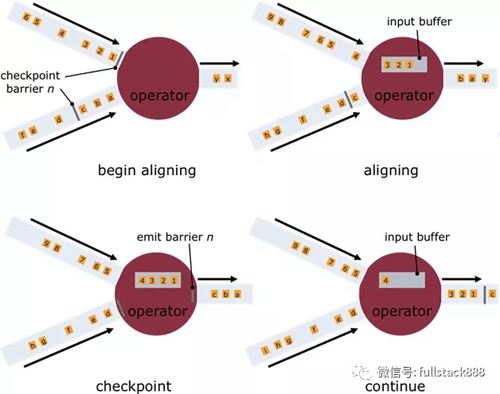
- Flink资料(2)-- 数据流容错机制
数据流容错机制 该文档翻译自Data Streaming Fault Tolerance,文档描述flink在流式数据流图上的容错机制. ------------------------------- ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- [Note] Apache Flink 的数据流编程模型
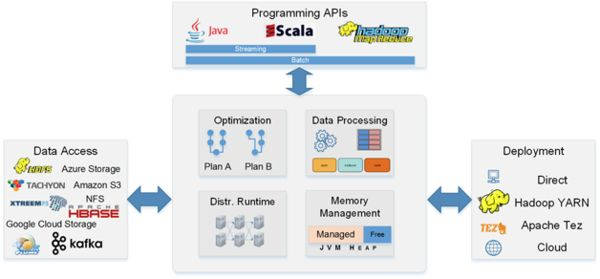
Apache Flink 的数据流编程模型 抽象层次 Flink 为开发流式应用和批式应用设计了不同的抽象层次 状态化的流 抽象层次的最底层是状态化的流,它通过 ProcessFunction 嵌入到 ...
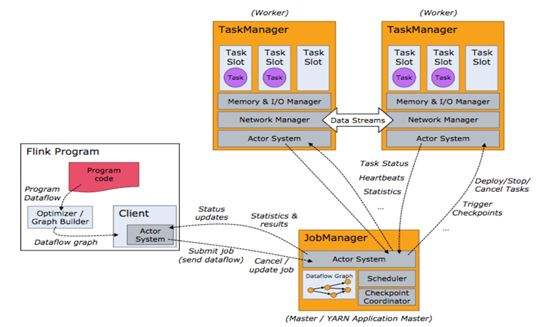
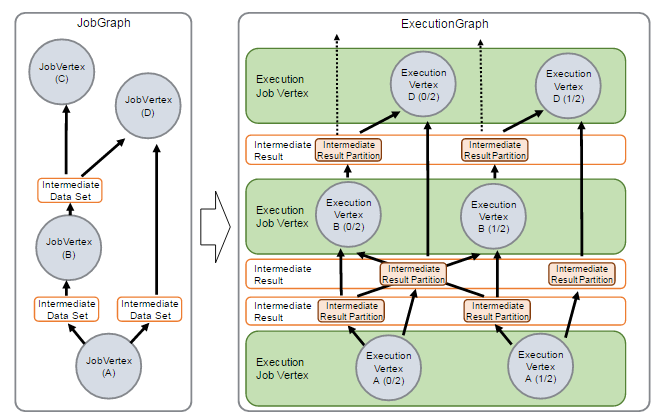
- Apache Flink 分布式执行
Flink 的分布式执行过程包含两个重要的角色,master 和 worker,参与 Flink 程序执行的有多个进程,包括 Job Manager,Task Manager 以及 Job Clien ...
随机推荐
- [Shell]如何获取Maven工程的project.version信息
问题: 今天遇到Shell中如何能获取Maven项目工程中的project.version信息的问题 解决方案: 使用Maven的Exec 插件 #! /bin/bash MVN_VERSION=$( ...
- annotation-config和component-scan
以前学到<context:annotation-config></context:annotation-config>和<context:component-scan b ...
- 【测试的艺术】+测试分析&测试计划+模板
一.项目概述 1.1.项目背景 #就是说一下为什么要做这个项目 1.2.项目目标 #这个项目最终要达到的目标是什么 二.项目整体分析 #项目分为哪些部分?各部分之间的关联是什么?各部分的目标是什么? ...
- 手机端页面调试工具-vconsole使用
用的是VUE-CLI3第一步.安装vconsole npm install vconsole 第二步.创建js文件并写入内容 import Vconsole from 'vconsole' let v ...
- python 使用缓存加快运算
from functools import lru_cache import time from functools import wraps def clock(func): @wraps(func ...
- jQuery示例 | 分级菜单
<!DOCTYPE html> Title .header{ background-color: black; color: wheat; } .content{ min-height: ...
- IO流(一)字节流
1:io流体系:对数据进行读写操作.所以IO不是读就是写咯. 2:io流的相关的类:java.io包. 有关IO的操作都会产生IOException异常 3:io:参照物是程序, i:input.进来 ...
- Visual Studio中修改项目的输出目录
1. 如在Solution中的项目名称为 ProjectA 但在本地目录显示却想换成: MyProject 2. 应该做的修改是: 2.1. 将本地目录的 ProjectA手动修改成 MyProjec ...
- poj 2105 IP Address
IP Address Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 18951 Accepted: 10939 Desc ...
- 【c++】类中带默认参数的函数
反思两个问题 1. 带默认参数的函数,为何声明.定义不能同时有参数? 2. 带默认参数的函数, 为何带默认参数的参数靠后站? 上程序 #include <iostream> #includ ...