爬虫--BeautifulSoup
什么是BeautifulSoup?

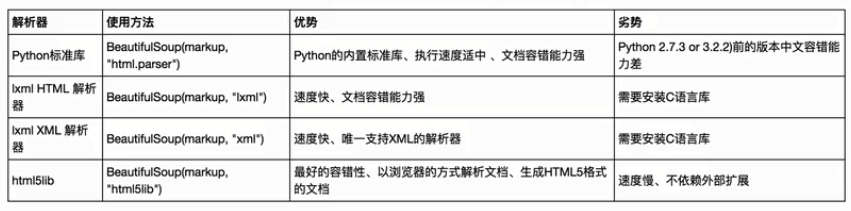
BeautifulSoup支持的一些解析库
基本使用
from bs4 import BeautifulSoup html ="""
<html><head><title> The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1"> <!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">..</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.prettify()) # .prettify() 格式化代码
print(soup.title.string) # .title.string
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title" name="dromouse">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
</body>
</html>
The Dormouse's story
打印后的结果为:
标签选择器
选择元素
from bs4 import BeautifulSoup html ="""
<html><head><title> The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1"> <!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">..</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
<title> The Dormouse's story</title>
<class 'bs4.element.Tag'>
<head><title> The Dormouse's story</title></head>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
打印的结果为:
获取名称
from bs4 import BeautifulSoup html ="""
<html><head><title> The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1"> <!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">..</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.title.name)
title
打印的结果为:
获取属性
from bs4 import BeautifulSoup html ="""
<html><head><title> The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1"> <!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">..</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.p.attrs["name"])
print(soup.p["name"])
dromouse
dromouse
打印的结果为:
获取内容
from bs4 import BeautifulSoup html ="""
<html><head><title> The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1"> <!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">..</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.title.string)
The Dormouse's story
打印后的结果为:
嵌套选择
from bs4 import BeautifulSoup html ="""
<html><head><title> The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"> <b> The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1"> <!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">..</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.head.title.string)
The Dormouse's story
打印后的结果为:
子节点和子孙节点
from bs4 import BeautifulSoup html ="""
<html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<!--Elsie-->
</a>,
<a href="http://example.com/lacie" class="sister" id="link2">
Lacie
</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.p.contents)
['\n Once upon a time there were three little sisters;and their names were\n ', <a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>, ',\n ', <a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>, '\n and\n ', <a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>, ';\n and \n they lived at the bottom of a well.\n ']
打印后的结果为:
from bs4 import BeautifulSoup html ="""
<html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<!--Elsie-->
</a>,
<a href="http://example.com/lacie" class="sister" id="link2">
Lacie
</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.p.children) # .children就相当于迭代器,需要循环的方式才能把内容取走
for i,child in enumerate(soup.p.children):
print(i,child)
<list_iterator object at 0x00000000012C5E10>
0
Once upon a time there were three little sisters;and their names were 1 <a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>
2 , 3 <a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
4
and 5 <a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
6 ;
and
they lived at the bottom of a well.
打印后的结果为:
from bs4 import BeautifulSoup html ="""
<html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<!--Elsie-->
</a>,
<a href="http://example.com/lacie" class="sister" id="link2">
Lacie
</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.p.descendants) # .descendants就相当于迭代器,获取所有的子孙节点,需要循环的方式才能把内容取走
for i,child in enumerate(soup.p.descendants):
print(i,child)
Once upon a time there were three little sisters;and their names were 1 <a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>
2
3 Elsie
4
5 ,
6 <a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
7
Lacie
8
and
9 <a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
10
Tillie
11 ;
and
they lived at the bottom of a well.
打印后的结果为:
父节点和祖先节点
from bs4 import BeautifulSoup html ="""
<html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<!--Elsie-->
</a>,
<a href="http://example.com/lacie" class="sister" id="link2">
Lacie
</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
""" soup=BeautifulSoup(html,"lxml")
print(soup.a.parent) # .descendants就相当于迭代器,获取所有的父节点
<p class="story">
Once upon a time there were three little sisters;and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
打印后的结果为:
from bs4 import BeautifulSoup html ="""
<html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<!--Elsie-->
</a>,
<a href="http://example.com/lacie" class="sister" id="link2">
Lacie
</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
""" soup=BeautifulSoup(html,"lxml")
print(list(enumerate(soup.a.parents))) # .descendants就相当于迭代器,获取所有的祖先节点)
[(0, <p class="story">
Once upon a time there were three little sisters;and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>), (1, <body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
</body>), (2, <html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
</body></html>), (3, <html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!--Elsie-->
</a>,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
</body></html>)]
打印后的结果为:
兄弟节点
from bs4 import BeautifulSoup html ="""
<html>
<head>
<title> The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<!--Elsie-->
</a>,
<a href="http://example.com/lacie" class="sister" id="link2">
Lacie
</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">
Tillie
</a>;
and
they lived at the bottom of a well.
</p>
<p class="story">
..
</p>
""" soup=BeautifulSoup(html,"lxml")
print(list(enumerate(soup.a.next_siblings))) # .descendants就相当于迭代器,获取兄弟节点
print(list(enumerate(soup.a.previous_siblings))) # .descendants就相当于迭代器,获取兄弟节点
[(0, ',\n '), (1, <a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>), (2, '\n and\n '), (3, <a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>), (4, ';\n and \n they lived at the bottom of a well.\n ')]
[(0, '\n Once upon a time there were three little sisters;and their names were\n ')]
打印后的结果为:
标准选择器
find_all(name,attrs,recursive,text,**kwargs)
可根据标签名、属性、内容查找文档
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1>
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
""" soup=BeautifulSoup(html,"lxml")
print(soup.find_all("ul"))
print(type(soup.find_all("ul")[0]))
[<ul class="list" element="" id="list-1><li class=">Foo
<li class="element">Bar</li>
<li class="element">Jay
</li></ul>,
<ul class="list list-small" id="list-2">
<li class="element">Foo
<ll class="element">Bar
</ll></li></ul>]
<class 'bs4.element.Tag'>
打印后的结果为:
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1>
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
""" soup=BeautifulSoup(html,"lxml")
for UL in soup.find_all("ul"):
print(UL.find_all("li"))
[<li class="element">Bar</li>, <li class="element">Jay</li>]
[<li class="element">Foo<ll class="element">Bar</ll></li>]
打印后的结果为:
attrs
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1 name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
print(soup.find_all(attrs={"id":"list-1"}))
print(soup.find_all(attrs={"name":"elements"}))
[]
[]
打印后的结果为:
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1 name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
print(soup.find_all(id="list-1"))
print(soup.find_all(class_="element"))
[<ul class="list list-small" id="list-2"><li class="element">Foo<ll class="element">Bar</ll></li></ul>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo<llclass="element">Bar</ll></li>, <ll class="element">Bar</ll>]
打印后的结果为:
text
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1 name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
print(soup.find_all(text="Foo"))
['Foo']
打印后的结果为:
find(name,attrs,recursive,text,**kwargs)
find返回单个元素,find_all返回所有元素
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1 name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
print(soup.find("ul"))
print(type(soup.find("ul")))
print(soup.find("h4"))
<ul class="list" elements="" id="list-1 name=">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<class 'bs4.element.Tag'>
<h4>Hello</h4>
打印后的结果为:
find_parents() , find_parent()
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings() , find_next_sibling()
find_next_siblings()返回后面所有兄弟节点,findnext_sibling0返回后面第一个兄弟节点。
find_previous_ siblings() , find_previous_sibling()
find_previous_siblings0返回前面所有兄弟节点,find_previous_sibling0返回前面第一个兄弟节点。
find_all_next() , find_next()
find_all_next()返回节点后所有符合条件的节点,find_next()返回第一个符合条件的节点
find_all_previous()和find_previous()
find_all_previous()返回节点后所有符合条件的节点,find_previous()返回第一个符合条件的节点
CSS选择器
通过select()直接传入CSS选择器即可完成选择
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1 name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
print(soup.select(".panel .panel-heading"))
print(soup.select("ul li"))
print(soup.select("#list-2 .element"))
print(type(soup.select("ul")[0]))
[<div class="panel-heading"><h4>Hello</h4></div>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo<ll class="element">Bar</ll></li>]
[<li class="element">Foo<li class="element">Bar</li></li>, <li class="element">Bar</li>]
<class 'bs4.element.Tag'>
打印后的结果为:
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1 name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</ll>
<ll class="element">Bar</l>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
for ul in soup.select("ul"):
print(ul.select("li"))
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay </li>]
[<li class="element">Foo<ll class="element">Bar</ll></li>]
打印后的结果为:
获取属性
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
for ul in soup.select("ul"):
print(ul["id"])
print(ul.attrs["id"])
list-1
list-1
list-2
list-2
打印的结果为:
获取内容
from bs4 import BeautifulSoup html="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</ll>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
soup=BeautifulSoup(html,"lxml")
for ul in soup.select("li"):
print(ul.get_text())
Foo
Bar
Jay Foo
Bar
打印后的结果为:
总结:
●推荐使用lxml解析库,必要时使用html.parser
●标签选择筛选功能弱但是速度快
●建议使用find()、find_all()查询匹配单个结果或者多个结果
●如果对CSS选择器熟悉建议使用select()
●记住常用的获取属性和文本值的方法
爬虫--BeautifulSoup的更多相关文章
- 爬虫beautifulsoup实践
爬虫beautifulsoup实践: 目的:在https://unsplash.com/上爬取图片并保存到本地文件夹里. 一.观察response.首先,在Chrome浏览器里观察一下该网页的re ...
- 爬虫——BeautifulSoup和Xpath
爬虫我们大概可以分为三部分:爬取——>解析——>存储 一 Beautiful Soup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功 ...
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- Python爬虫 | Beautifulsoup解析html页面
引入 大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据.因此,在聚焦爬虫中使用数据解析.所以,我们的数据爬取的流程为: 指定url 基于reque ...
- 网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息 #!/usr/bin/python3 import requests from bs4 import BeautifulSoup url='htt ...
- 爬虫----beautifulsoup的简单使用
beautifulSoup使用: 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. pip3 install beautifulsoup4 解析器 Beau ...
- 爬虫----BeautifulSoup模块
一.介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你 ...
- python爬虫---BeautifulSoup的用法
BeautifulSoup是一个灵活的网页解析库,不需要编写正则表达式即可提取有效信息. 推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前 ...
- Python 爬虫-BeautifulSoup
2017-07-26 10:10:11 Beautiful Soup可以解析html 和 xml 格式的文件. Beautiful Soup库是解析.遍历.维护“标签树”的功能库.使用Beautifu ...
随机推荐
- iOS奔溃日志信息统计使用笔记
1.Bugly的集成很简单,直接一个pod就可以搞定 pod 'Bugly' 2.在官网上注册账号 3.初始化SDK 导入头文件 在工程的AppDelegate.m文件导入头文件 #import &l ...
- 【Linux】CentOS安装redis
CENTOS7下安装REDIS 安装完成之后使用:redis-cli命令连接,如图: 提示:/var/run/redis_6379.pid exists, process is already run ...
- Android studio出现Error:Unable to tunnel through proxy. Proxy returns "HTTP/1.1 400 Bad Request"的解决办法
最近更新了一下Android Studio(下文简写成AS),然后打开工程发现出现Error:Unable to tunnel through proxy. Proxy returns "H ...
- 【Python】爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- mac终端命令-----常规操作
OSX 的文件系统 OSX 采用的Unix文件系统,所有文件都挂在跟目录 / 下面,所以不在要有Windows 下的盘符概念. 你在桌面上看到的硬盘都挂在 /Volumes 下. 比如接上个叫做 US ...
- BZOJ 2115 Xor(线性基)
题意:给定一个n<=50000个点m<=100000条边的无向联通图,每条边上有一个权值wi<=1e18.请你求一条从1到n的路径,使得路径上的边的异或和最大. 任意一条1到n的路径 ...
- BZOJ 1037 生日聚会(神DP)
这题的DP很难想,定义dp[i][j][a][b]表示用了i个男生,j个女生,任一连续的后缀区间内,男生比女生最多多a人,女生比男生最多多b人. 转移就是显然了. # include <cstd ...
- tcp协议的六个标识位
6个标识位: URG 紧急指针,告诉接收TCP模块紧要指针域指着紧要数据. ACK 置1时表示确认号(为合法,为0的时候表示数据段不包含确认信息,确认号被忽略. PSH 置1时请求的数据段在接收方得到 ...
- 51nod 1286 三段子串(树状数组+拓展kmp)
题意: 给定一个字符串S,找到另外一个字符串T,T既是S的前缀,也是S的后缀,并且在中间某个地方也出现一次,并且这三次出现不重合.求T最长的长度. 例如:S = "abababababa&q ...
- 【题解】洛谷9月月赛加时赛 —— Never·island
有趣有趣~ヾ(✿゚▽゚)ノ真的很有意思的一道dp题!感觉可以提供很多非常有意思的思路~ 现场打的时候考虑了很久,但并没有做出来,主要还是卡在了两个地方:1.考虑到按照端点来进行dp,但没有办法将两个端 ...