Expectation Maximization(EM)算法note
EM算法,之前上模式识别课上,推导过,在《统计学习方法》中没耐性的看过几次,个人感觉讲的过于理论,当时没怎么看懂,后来学lda,想要自己实现一下em算法,又忘记了,看来还是学的不够仔细,认识的不够深刻,现在做点笔记。本文是看了几篇blog和《统计学习方法》之后做的笔记,只是用来给自己做记录,很多地方都是直接引用。
一、初识
1. 迭代
EM算法本身可以理解为一个迭代算法,很抽象&简单的形容迭代就是,比如我们有两个公式a=f(b), b=g(a),需要求解,我们可以先随机的给a赋一个值,在根据b=g(a)计算出b,得到b,在根据b得到a,如此往复,直到a,b基本不变。
2. 隐变量问题
EM算法很适用与求解包含隐变量的问题,这里引用《统计学习方法》中的一个例子(pLSA的弱化版本):
eg. 有3枚硬币,分别记为A,B,C,掷得正面的概率分别为∏,p,q;
先投掷硬币A,如果是正面则继续投掷硬币B,是反面则投掷硬币C,最终出现正面记为1,出现反面记为0;
独立的重复n次实验后,得到一串实验结果Y=(Y1,Y2,……,Yn)。
这里Y=(Y1,Y2,……,Yn)T称作观测变量,但这里也有不能直接观测到,但却需要知道的一个变量,即投掷A的结果,可以记为Z=(Z1,Z2,……,Zn)T,同时有些已知的参数,我们可以统一记为θ=(∏, p, q)。通过上面的一些符号,我们可以得知Y的分布:
上式即为Y的似然函数,得到了似然函数,第一想到的便是参数的似然估计 ,下面回顾一下最大似然估计(MLE)的一般步骤:
求最大似然函数估计值的一般步骤:
()写出似然函数;
()对似然函数取对数,并整理;
()求导数,令导数为0,得到似然方程;
()解似然方程,得到的参数即为所求 其实最大似然可以这样想,我们假设已经知道到了θ,在已知θ的情况下,产生Y,很自然,如果我们看到结果产生了很多个Yi,那么P(Yi|θ)一定是比较大的。现在我们反过来想,我们已经知道了Y,
,那么使该结果出现的可能性最大的参数情况,就是我们估计的参数。
很不巧,上述步骤,是没有解析解的,这样我们就必须用到EM算法了。
(ps,这里有一篇对常见的三类估计介绍写的不错的文章文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计)
3. Jensen不等式
回顾优化理论中的一些概念。设f是定义域为实数的函数,如果对于所有的实数x,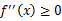 ,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(
,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(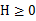 ),那么f是凸函数。如果
),那么f是凸函数。如果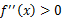 或者
或者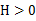 ,那么称f是严格凸函数。
,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么
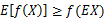
特别地,如果f是严格凸函数,那么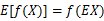 当且仅当
当且仅当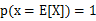 ,也就是说X是常量。
,也就是说X是常量。
如果用图表示会很清晰:
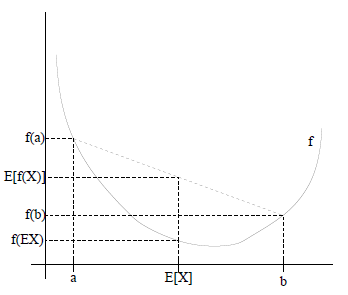
图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到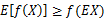 成立。
成立。
当f是(严格)凹函数当且仅当-f是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向,也就是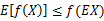 。
。
二、EM算法
上面的例子,有个很悬乎的变量,我们无法直接知道,即A硬币的投掷结果,但如果我们知道了某一次输出在投掷A后的输出是什么了,我们就能够很容易运用最大似然(当然,这个例子用简单的直觉也能知道)得到p,q的估计值。
eg.
.如果A硬币的投掷结果有x次正面,n-x次反面(在这个假设下,也就得到了∏的估计值),那么我们只要统计那x次中最后出现的正反面情况就能得到p的估计值了,对q也同理;
.得到了p,q值之后,我们又容易反过来问,你怎么知道之前的假设是正确的呢?而在已知p,q的情况下,之前我们的似然函数就能够求解了,这样我们就又能得到一个新的∏
.在新的∏值下,我们又可以对p,q进行新的估计了。如此往复,如果最终收敛了,那么就得到了我们对参数θ的估计值
上面说的很抽象,下面具体地说一说(以下部分引自(EM算法)The EM Algorithm)。
给定的训练样本是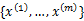 ,样例间独立,那么样本的似然函数如下:
,样例间独立,那么样本的似然函数如下:
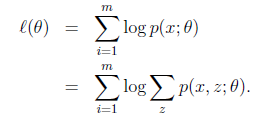
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和(对z求和后即可得到x的边缘分布概率)。但是直接求θ一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。竟然不能直接最大化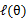 ,我们可以不断地建立
,我们可以不断地建立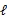 的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
对于每一个样例i,让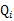 表示该样例隐含变量z的某种分布,
表示该样例隐含变量z的某种分布,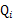 满足的条件是
满足的条件是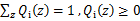 。(如果z是连续性的,那么
。(如果z是连续性的,那么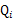 是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了(上文提到的三个硬币的例子中的∏就可以理解为这里的,对于每个i,都是∏,∏是伯努利分布)。
是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了(上文提到的三个硬币的例子中的∏就可以理解为这里的,对于每个i,都是∏,∏是伯努利分布)。
可以由前面阐述的内容得到下面的公式:
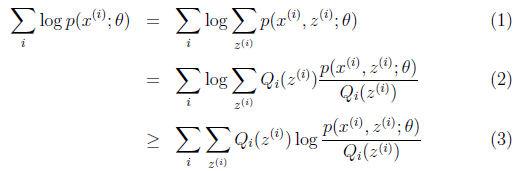
(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。
(2)到(3)利用了Jensen不等式。
考虑到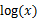 是凹函数(二阶导数小于0),而且
是凹函数(二阶导数小于0),而且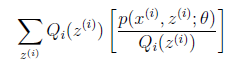 ,可以理解为
,可以理解为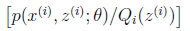 的期望。得到(3)式后,我可以理解为,得到了似然函数l(θ)的一个下界,如果不断提升下界,使下界的值与l(θ)近似相等时,我们就可以用不等式右边的值代替l(θ)了。
的期望。得到(3)式后,我可以理解为,得到了似然函数l(θ)的一个下界,如果不断提升下界,使下界的值与l(θ)近似相等时,我们就可以用不等式右边的值代替l(θ)了。
对于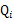 的选择,有多种可能,那种更好的?假设
的选择,有多种可能,那种更好的?假设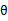 已经给定,那么
已经给定,那么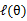 的值就决定于
的值就决定于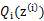 和(其实应该是
和(其实应该是 ,但这里只有未知)。首先我们思考当和都已经确定时,也就是jensen不等式中的随机变量已知时,我们可以知道当该随机变量恒为常数时,不等式取等号,即:
,但这里只有未知)。首先我们思考当和都已经确定时,也就是jensen不等式中的随机变量已知时,我们可以知道当该随机变量恒为常数时,不等式取等号,即:
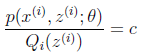
c为常数,不依赖于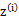 (但确是依赖于x(i)的,所以对于不同i,c还是不一样的,但都是常数,所以在M步中
(但确是依赖于x(i)的,所以对于不同i,c还是不一样的,但都是常数,所以在M步中 不能恒为c)。对此式子做进一步推导,我们知道
不能恒为c)。对此式子做进一步推导,我们知道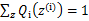 ,那么也就有
,那么也就有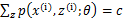 ,那么有下式:
,那么有下式:
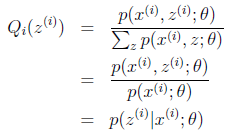
至此,我们推出了在固定其他参数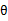 后,
后,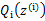 的计算公式就是后验概率,解决了
的计算公式就是后验概率,解决了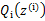 如何选择的问题。这一步就是E步,建立
如何选择的问题。这一步就是E步,建立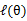 的下界。接下来的M步,就是在给定
的下界。接下来的M步,就是在给定 后,调整
后,调整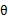 ,去极大化
,去极大化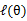 的下界(在固定
的下界(在固定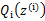 后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
|
循环重复直到收敛 { (E步)对于每一个i,计算
(M步)计算
|
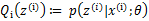
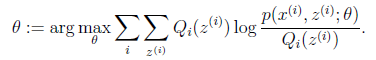
这里需要说明几点,比如,从第(t)步到(t+1)步:E步是固定θ(t),得到了,那么在M步中,中的θ将还是上一步的θ(t),而P(x(i),z(i);θ)则是需要求解的θ,改变该θ的值,去使M步中式子的值最大的时刻对应的θ,即为新的θ(t+1)所以M步中的式子可以进一步优化成
因为都是求max时对应的θ,所以分母上的可以不用计算了,而这一步就是最大化似然函数的期望。
Zhai老师在一篇经典的EM算法Notes中讲到,当原始数据的似然函数很复杂时,我们通过增加一些隐含变量来增强我们的数据,得到“complete data”,而“complete data”的似然函数更加简单,方便求极大值。于是,原始的数据就成了“incomplete data”。我们将会看到,我们可以通过最大化“complete data”似然函数的期望来最大化"incomplete data"的似然函数,以便得到求似然函数最大值更为简单的计算途径。
那么如何证明EM算法会收敛,其实有下面公式就好了:
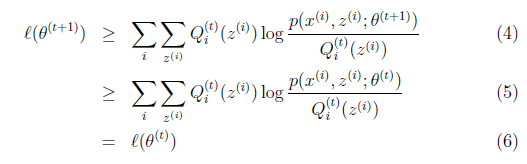
这里证明了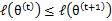 ,即l(θ)是单调上升的,到最后就一定能收敛到最大值。具体解释:
,即l(θ)是单调上升的,到最后就一定能收敛到最大值。具体解释:
(4)是对所有的参数都满足,而其等式成立条件只是在固定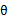 ,并调整好Q时成立(即如果是
,并调整好Q时成立(即如果是,等式成立),这里
不一定等于
,所以不一定能取等号。
(4)到(5)就是M步的定义,是固定第t步,固定Q调整
得到的结果
(5)到(6)是前面E步所保证等式成立条件。
也就是说E步会将下界拉到与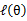 一个特定值
一个特定值 (这里
(这里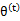 )一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与
)一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与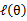 另外一个特定值一样的高度,即此时下界还是要小于
另外一个特定值一样的高度,即此时下界还是要小于 ,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到将下界拉升到的最大值。
,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到将下界拉升到的最大值。
某 blog 中有个很形象的图,引用到这里

如果定义
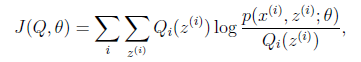
从前面的推导中我们知道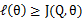 ,EM可以看作是J的坐标上升法,E步固定
,EM可以看作是J的坐标上升法,E步固定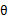 ,优化
,优化 ,M步固定
,M步固定 优化
优化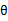 。
。
EM算法的基本原理就是这些了
Reference
1. 统计学习方法
2. http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
3. http://blog.csdn.net/zouxy09/article/details/8537620
4. Andrew Ng 课程
5. http://blog.csdn.net/yangliuy/article/details/8330640
Expectation Maximization(EM)算法note的更多相关文章
- Expectation maximization - EM算法学习总结
原创博客,转载请注明出处 Leavingseason http://www.cnblogs.com/sylvanas2012/p/5053798.html EM框架是一种求解最大似然概率估计的方法.往 ...
- EM(Expectation Maximization)算法
EM(Expectation Maximization)算法 参考资料: [1]. 从最大似然到EM算法浅解 [2]. 简单的EM算法例子 [3]. EM算法)The EM Algorithm(详尽 ...
- EM算法(Expectation Maximization)
1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成绩的分 ...
- Expectation Maximization and GMM
Jensen不等式 Jensen不等式给出了积分的凸函数值必定大于凸函数(convex)的积分值的定理.在凸函数曲线上的任意两点间连接一条线段,那么线段会位于曲线之上,这就是将Jensen不等式应用到 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- 机器学习五 EM 算法
目录 引言 经典示例 EM算法 GMM 推导 参考文献: 引言 Expectation maximization (EM) 算法是一种非常神奇而强大的算法. EM算法于 1977年 由Dempster ...
- 最大期望算法 Expectation Maximization概念
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- 数据挖掘十大经典算法(5) 最大期望(EM)算法
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- NLP —— 图模型(零):EM算法简述及简单示例(三硬币模型)
最近接触了pLSA模型,该模型需要使用期望最大化(Expectation Maximization)算法求解. 本文简述了以下内容: 为什么需要EM算法 EM算法的推导与流程 EM算法的收敛性定理 使 ...
- EM算法及其推广
概述 EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计. EM算法的每次迭代由两步组成:E步,求期望(expectation): ...
随机推荐
- 30个iPhone健康应用帮助你保持身体健康
来源:GBin1.com 技 术进步的最大缺陷是,现在大部分人花费大量时间在他们的电脑前和移动设备上.他们没有任何时间锻炼和顾及他们的健康.这些科技产品让我们变得慵 懒,甚至 让我们愿意花费闲暇的时间 ...
- 如何使用angularjs实现文本框获取焦点
<!DOCTYPE html> <html ng-app="myApp"> <head> <title>angularjs-focu ...
- .NET 之 有效预防.NET应用程序OOM
大部分的内存溢出(及内存泄漏)都和不好的开发习惯有直接关系,以下几个方式可以有效预防OOM. 一.批量和分页 每个合格的coder对数据的处理,必须要有分页或批量多次的意识.大数据量的读取或查询结果集 ...
- 获取ping的最短、最长、平均时间
# -*- coding: utf-8 -*- import osimport rep = os.popen('ping 120.26.77.101') out = p.read()regex = r ...
- 关于comet
Comet是彗星的意思,这一技术之所以借用这个名字,是因为这里的每一次请求都有一个长长的“尾巴”.这个长尾巴就是我们感兴趣的长连接. 因为长连接的实现,Comet可以不需要安装浏览器插件就可以向客户端 ...
- Java中abstract class 和 interface 的解释和他们的异同点(转)
(一)概述 在Java语言中, abstract class 和interface 是支持抽象类定义的两种机制.正是由于这两种机制的存 在,才赋予了Java强大的 面向对象能力.abstract ...
- 基于redis的简易分布式爬虫框架
代码地址如下:http://www.demodashi.com/demo/13338.html 开发环境 Python 3.6 Requests Redis 3.2.100 Pycharm(非必需,但 ...
- nginx location静态文件配置
进入nginx安装目录的conf目录下,修改nginx.conf文件,在一个server{}中添加 一个location 部分配置代码如下 root@ubuntu:/usr/local/nginx/c ...
- Python之基础数学知识
一.线性代数 1.求转置 import numpy m = numpy.mat([[1, 2], [3, 4]]) print("Matrix.Transpose:") print ...
- pandas数据处理基础——基础加减乘除的运算规则
上周公司对所有员工封闭培训了一个星期,期间没收手机,基本上博客的更新都停止了,尽管培训时间不长,但还是有些收获,不仅来自于培训讲师的,更多的是发现自己与别人的不足,一个优秀的人不仅仅是自己专业那块的精 ...