lucene实现初级搜索引擎
一、系统设计
搜索引擎项目代码主要分为三个部分,第一部分是构建索引,全文检索;第二部分是输入问题,对问题进行分词、提取关键词、关键词扩展;第三部分是将搜索结果输出到GUI图形用户界面。
二、搜索引擎
搜索引擎的工作流程可以简化归结为以下四个步骤:
(1)网上抓取网页
(2)建立索引数据库
(3)在索引数据库中搜索
(4)对搜索结果进行处理和排序
三、全文检索
1.什么是全文检索?
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。
2.全文检索流程
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
①索引创建:从结构化和非结构化数据提取信息,创建索引的过程。
②搜索索引:得到用户的查询请求,搜索创建的索引,然后返回结果。
四、利用Lucene实现索引和搜索
1.简介
Lucene是一个高性能,易于扩展的IR(Information Retrieval)Java类库,可以利用其中的Java类轻松地在应用程序中增加索引和搜索功能。Lucene完全用Java实现,具有良好的跨平台性,是Apache Jakarta项目中一个子项目。
2.lucene架构图
Lucene的架构图如下图4.1所示:
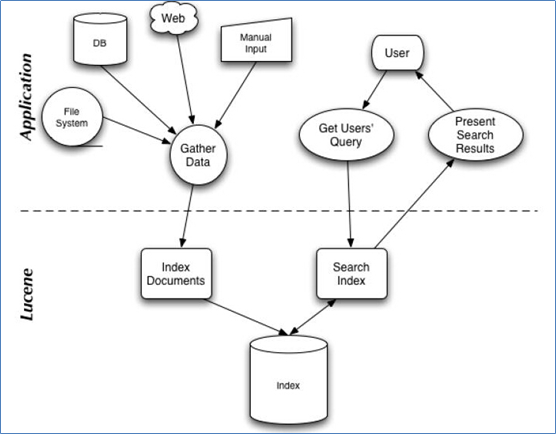
图4.1Lucene的架构图
3. Lucene的核心类
Lucene的核心的索引类简介如下:
① IndexWriter类
IndexWriter是索引过程中的核心部件。这个类建立一个新的索引和添加文档(Documents)到一个存在的索引中,它对索引只有写权限,不具有读和搜索的权限。
② Directory类
Directory类代表了Lucene索引的位置,它是一个抽象类,有两个子类: FSDirectory类,它将索引存储在磁盘上,并在文件系统中维护一个真实文件的列表;另一个是RAMDirectory类,它将所有索引信息都放在内存中,适用于索引较小的情况。
③ Analyzer类
在文本被索引之前,要经过一个Analyzer的处理。在IndexWriter的构造函数中指定的Analyzer负责从被索引的文本中抽取出标志(tokens),并排除掉标志以外的部分。假如被索引的内容不是纯文本的话,应该先将它转换为纯文本。Analyzer是一个抽象类,Lucene中包含了几种它的实现,用于完成不同的功能,例如用于去掉文本中的无用词(stop word)、将标志(tokens)全部转换为小写等等。为了达到特定的目标,可以设计不同的Analyzer的实现,这样就使得Lucene具有高度的灵活性及可扩充性。
④ Document类
一个Document代表了一些字段(fields)的集合。
⑤ Field类:
在索引中的每个Document都包含了一个或更多的命名了的字段(fields),这些字段用一个称为Field的类来表示。每个字段都对应于在搜索期间能从索引中查询并提取的一段数据。
⑥ IndexSearcher类
IndexSearcher用于搜索IndexWriter建立的索引。IndexSearcher以只读方式打开索引,并提供了几种搜索方法,这些方法是它的抽象父类的实现。
⑦ Term类
Term是最基本的搜索单元。与Field对象类似,它也包含了一对字符串元素:名字和值。Term对象和索引过程也是相关的。在搜索期间,先构建Term对象然后连同TermQuery一起使用。
⑧ TermQuery类
TermQuery类是Lucene支持的最基本的查询类。它被用来匹配含有特定值的字段的文档。
⑨ Hits类
Htis类是一个简单的指向分级搜索结果的指针容器。考虑到性能的原因,Hits的实例并不从索引中装载匹配查询的所有文档只是他们的一小部分。
五、构建索引的数据库
构建索引所用到的数据来自搜狗实验室( www.sogou.com/labs/resource)的搜狐新闻数据,对其中健康(health)和娱乐(yule)两类的数据构建了索引。
六、结合例子代码分析具体步骤
1.本实验代码用到的lucene版本和子 jar包
①Lucene-core-4.0.0.jar:包括了常用的文档,索引,搜索,存储等相关核心代码。
②Lucene-analyzers-common-4.0.0.jar:包含词法分析器,用于提取关键字。
③Lucene-highlighter-4.0.0.jar:将搜索出的内容高亮显示。
④Lucene-queryparser-4.0.0.jar:用于各种搜索,如模糊搜索,范围搜索等。
2. 使用Lucene的两个主要步骤
①创建索引,通过IndexWriter对不同的文件进行索引的创建,并将其保存在索引相关文件存储的位置中。
②通过索引查询关键字相关文档。
3.代码具体分析
①定义词法分析器

②确定索引文件存储的位置


③创建IndexWriter,进行索引文件的写入

④内容提取,进行索引的存储

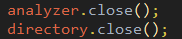
⑤关闭查询器
4.全部代码
package lucene;
public class Article {
private Integer id;
private String title;
private String content;
public Article() {
super();
}
public Article(Integer id, String title, String content) {
super();
this.id = id;
this.title = title;
this.content = content;
}
public synchronized Integer getId() {
return id;
}
public synchronized void setId(Integer id) {
this.id = id;
}
public synchronized String getTitle() {
return title;
}
public synchronized void setTitle(String title) {
this.title = title;
}
public synchronized String getContent() {
return content;
}
public synchronized void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Article [id=" + id + ", title=" + title + ", content=" + content + "]";
}
}
package lucene;
/*
* 环境:lucene-3.6.0
*/
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer; import lucene.Article; /**
* Lucene 检索各种索引的实现方式总结
* @author Administrator
*
*/
public class lucene_Search { //public static final String INDEX_DIR_PATH = "indexDir1";
public static final String INDEX_DIR_PATH = "indexDir";
/* 创建简单中文分析器 创建索引使用的分词器必须和查询时候使用的分词器一样,否则查询不到想要的结果 */
private Analyzer analyzer = null;
// 索引保存目录
private File indexFile = null;
//目录对象,因为操作索引文件都要用到它,所以定义为全局变量
private Directory directory = null;
//索引搜索对象
private IndexSearcher indexSearcher; /**
* 初始化方法
* @throws IOException
*/
public void init() throws IOException{
analyzer = new IKAnalyzer(true);
indexFile = new File(INDEX_DIR_PATH);
directory = new SimpleFSDirectory(indexFile);
indexSearcher = new IndexSearcher(directory);
System.out.println("*****************搜索索引程序初始化成功**********************");
} /**
* 根据传递的结果集 封装成集合后显示出来
* @param scoreDocs
* @return
* @throws IOException
* @throws CorruptIndexException
*/
public List<String> showResult(ScoreDoc[] scoreDocs) throws CorruptIndexException, IOException{
List<Article> articles = new ArrayList<Article>();
for (int i = 0; i < scoreDocs.length; i++) {
int doc = scoreDocs[i].doc;//索引id
Document document = indexSearcher.doc(doc); Article article = new Article();
if (document.get("id") == null) {
System.out.println("id为空");
} else {
article.setId(Integer.parseInt(document.get("id")));
article.setTitle(document.get("title"));
article.setContent(document.get("content"));
articles.add(article);
}
}
List<String> resultList = new ArrayList<String>(); if(articles.size()!=0){
for (Article article : articles) {
//System.out.println(article);
resultList.add(article.getContent());
}
}else{
System.out.println("没有查到记录。");
}
return resultList;
} /**
* 通过QueryParser绑定单个字段来检索索引记录
* @param keyword
* @return
* @throws ParseException
* @throws IOException
* @throws CorruptIndexException
*/
public List<String> searchByQueryParser(String keyword) throws ParseException, CorruptIndexException, IOException{
System.out.println("*****************通过QueryParser来检索索引记录**********************");
QueryParser queryParser = new QueryParser(Version.LUCENE_36, "content", analyzer);
Query query = queryParser.parse(keyword);
// public TopFieldDocs search(Query query, int n, Sort sort)
// 参数分别表示 Query查询对象,返回的查询数目,排序对象
TopDocs topDocs = indexSearcher.search(query, 50, new Sort());
List<String> resultList = showResult(topDocs.scoreDocs);
return resultList;
} /**
* 销毁当前的操作类的实现,主要关闭资源的连接
*/
public void destory()
throws IOException{
analyzer.close();
directory.close();
System.out.println("*****************成功关闭资源连接**********************");
} public static List<String> lucene_searchIndex(String question)
throws IOException, ParseException {
lucene_Search luceneInstance = new lucene_Search();
luceneInstance.init();
List<String> resultList = luceneInstance.searchByQueryParser(question);
luceneInstance.destory();
HashSet<String> resultset = new HashSet<String>();
for(int i=0;i<resultList.size();i++){
resultset.add(resultList.get(i));
}
resultList.clear();
for(String data:resultset){
resultList.add(data);
}
return resultList;
}
}
package lucene; import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer; import Utils.readBigData; public class lucene_BuildIndex { // public static final String INDEX_DIR_PATH = "indexDir1";
public static final String INDEX_DIR_PATH = "indexDir3";
/* 创建简单中文分析器 创建索引使用的分词器必须和查询时候使用的分词器一样,否则查询不到想要的结果 */
private Analyzer analyzer = null;
// 索引保存目录
private File indexFile = null;
//目录对象,因为操作索引文件都要用到它,所以定义为全局变量
private Directory directory = null;
//创建IndexWriter索引写入器
IndexWriterConfig indexWriterConfig = null; SimpleDateFormat simpleDateFormat = null; /**
* 获得指定格式的时间字符串
* @return
*/
public String getDate(){
return simpleDateFormat.format(new Date());
} /**
* 初始化方法
* @throws IOException
*/
public void init() throws IOException{
analyzer = new IKAnalyzer(true);
indexFile = new File(INDEX_DIR_PATH);
directory = new SimpleFSDirectory(indexFile); simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("*****************倒排索引程序初始化成功**********************");
} /**
* 将article对象的属性全部封装成document对象,重构之后方便创建索引
* @param article
* @return
*/
public Document createDocument(Article article){
Document document = new Document();
document.add(new Field("id", article.getId().toString(),
Field.Store.YES, Field.Index.NOT_ANALYZED));
document.add(new Field("content", article.getContent().toString(),
Field.Store.YES, Field.Index.ANALYZED));
//document.add(new Field("title", article.getTitle().toString(),Field.Store.YES, Field.Index.ANALYZED)); return document;
} /**
* 为了如实反映操作索引文件之后的效果,每次操作之后查询索引目录下所有的索引内容
* @throws IOException
* @throws CorruptIndexException
*/
public void openIndexFile()
throws CorruptIndexException, IOException{
System.out.println("*****************读取索引开始**********************");
IndexReader indexReader = IndexReader.open(directory);
int docLength = indexReader.maxDoc();
for (int i = 0; i < docLength; i++) {
Document doc = indexReader.document(i);
Article article = new Article();
if (doc.get("id") == null) {
System.out.println("id为空");
} else {
article.setId(Integer.parseInt(doc.get("id")));
article.setTitle(doc.get("title"));
article.setContent(doc.get("content"));
}
//System.out.println(article);
}
System.out.println("*****************读取索引结束**********************\n");
} /**
* 创建索引到索引文件中
* @param article
* @throws IOException
* @throws LockObtainFailedException
* @throws CorruptIndexException
*/
public void createIndex(Article article)
throws CorruptIndexException, LockObtainFailedException, IOException{
indexWriterConfig = new IndexWriterConfig(Version.LUCENE_36, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.addDocument(createDocument(article)); indexWriter.close();
//System.out.println("[ " + getDate() + " ] Lucene写入索引到 [" + indexFile.getAbsolutePath() + "] 成功。");
} /**
* 根据文件中的id删除对应的索引文件
* @param contentId
* @throws IOException
* @throws ParseException
*/
public void deleteIndex(String contentId)
throws IOException, ParseException{
//判断索引文件目录内容是否有索引,有返回true ,没有返回false
if(IndexReader.indexExists(directory)){
indexWriterConfig = new IndexWriterConfig(Version.LUCENE_36, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//封装term去检索字段名为id ,具体值为contentId的记录,如果存在就会删除,否则什么都不做
indexWriter.deleteDocuments(new Term("id",contentId));
/*
QueryParser queryParser = new QueryParser(Version.LUCENE_36, "id", analyzer);
Query query = queryParser.parse(contentId);
indexWriter.deleteDocuments(query);
*/
indexWriter.close();
System.out.println("[ " + getDate() + " ] Lucene删除索引到 [" + indexFile.getAbsolutePath() + "] 成功。");
}else{
throw new IOException("[ " + getDate() + " ] Lucene删除索引失败,在 " + indexFile.getAbsolutePath() + "目录中没有找到索引文件。" );
}
} /**
* 由于实际的内容修改,所以索引文件也要跟着修改 ,具体实现方式就是先删除索引,然后重新添加
* @param article
* @throws IOException
* @throws ParseException
*/
public void updateIndex(Article article)
throws IOException, ParseException{
deleteIndex(article.getId().toString());
createIndex(article);
System.out.println("updateIndex函数执行完毕");
} /**
* 销毁当前的操作类的实现,主要关闭资源的连接
*
* @throws IOException
*/
public void destory()
throws IOException{
analyzer.close();
directory.close();
System.out.println("*****************成功关闭资源连接**********************");
} public static void main(String[] args) throws IOException, ParseException {
String path = "D:\\#我的文件夹\\自然语言处理\\问答系统\\爬取网页\\1_2文档切分成句子.txt";
List<String> information = readBigData.readTxtByStringBuffer(path);
lucene_BuildIndex luceneInstance = new lucene_BuildIndex();
luceneInstance.init();//初始化
for(int i=0;i<information.size();i++){
Article article = new Article(i,null,information.get(i));
luceneInstance.createIndex(article);
}
luceneInstance.openIndexFile();
luceneInstance.destory();//销毁 }
}
lucene实现初级搜索引擎的更多相关文章
- 8 个基于 Lucene 的开源搜索引擎推荐
Lucene是一种功能强大且被广泛使用的搜索引擎,以下列出了8种基于Lucene的搜索引擎,你可以想象它们有多么强大. 1. Apache Solr Solr 是一个高性能,采用Java5开发,基于L ...
- C#编写了一个基于Lucene.Net的搜索引擎查询通用工具类:SearchEngineUtil
最近由于工作原因,一直忙于公司的各种项目(大部份都是基于spring cloud的微服务项目),故有一段时间没有与大家分享总结最近的技术研究成果的,其实最近我一直在不断的深入研究学习Spring.Sp ...
- scrapy+Lucene搭建小型搜索引擎
Reference: http://blog.csdn.net/napoay/article/details/51477586 一.选题 工程类搜索型: 定向采集 3-4 个新闻网站, 实现这些网站信 ...
- 关于k12领域Lucene.net+pangu搜索引擎设计开发的一些回顾
在中国最大的教育资源门户网站两年期间, 黄药师负责学科网搜吧的设计与开发…正好赶上了公司飞速发展的阶段.. 作为专注于k12领域内容与服务的互联网公司的一员,同时整个公司又在积极提升用户体验的氛围中, ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
- 聊聊基于Lucene的搜索引擎核心技术实践
最近公司用到了ES搜索引擎,由于ES是基于Lucene的企业搜索引擎,无意间在“聊聊架构”微信公众号里发现了这篇文章,分享给大家. 请点击链接:聊聊基于Lucene的搜索引擎核心技术实践
- Nutch搜索引擎(第1期)_ Nutch简介及安装
1.Nutch简介 Nutch是一个由Java实现的,开放源代码(open-source)的web搜索引擎.主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行查询的一 ...
- 分布式搜索引擎Elasticsearch的简单使用
官方网址:https://www.elastic.co/products/elasticsearch/ 一.特性 1.支持中文分词 2.支持多种数据源的全文检索引擎 3.分布式 4.基于lucene的 ...
- Lucene教程(转)
Lucene教程 1 lucene简介1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来 ...
随机推荐
- linux进程D状态_转
Linux进程状态:S (TASK_INTERRUPTIBLE),可中断的睡眠状态. 处于这个状态的进程因为等待某某事件的发生(比如等待socket连接.等待信号量),而被挂起.这些进程的task_s ...
- 2016-2017 ACM-ICPC CHINA-Final Ice Cream Tower 二分+贪心
/** 题目:2016-2017 ACM-ICPC CHINA-Final Ice Cream Tower 链接:http://codeforces.com/gym/101194 题意:给n个木块,堆 ...
- Nexus 5 刷机 - Android 5.0 Lollipop
Nexus刷机 : 官方地址 刷机步骤 下载相应的安装包 连接USB 重启手机,进入BootLoader界面 : 使用命令 adb reboot bootloader 关机; 音量键下 + 电源键 ...
- Struts2包含哪些标签?
Struts2包含哪些标签? 解答: A: <s:a href=”"></s:a>—–超链接,类似于html里的<a></a> <s:a ...
- phpstorm 内存设置
https://blog.csdn.net/qq_33862644/article/details/81938970
- 面试题思考: 什么是事务(ACID)?
事务(Transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序 执行逻辑单元(Unit). 狭义上的事务特指数据库事务.一方面,当多个应用程序并发访问数据库时,事务可以在这些 ...
- 【BZOJ2259】[Oibh]新型计算机 最短路
[BZOJ2259][Oibh]新型计算机 Description Tim正在摆弄着他设计的“计算机”,他认为这台计算机原理很独特,因此利用它可以解决许多难题. 但是,有一个难题他却解决不了,是这台计 ...
- iOS 苹果官方 Crash文件分析方法 (iOS系统Crash文件分析方法)
时间2013-08-20 12:49:20 GoWhich原文 http://www.gowhich.com/blog/view/id/343 苹果官方 Crash文件分析方法 (iOS系统Cras ...
- 在VerilogHDL中调用VHDL的模块
最近忽然要用到在VerilogHDL中调用VHDL的模块,从网上找了例程,把自己会忘掉的东西记在这里,. 2选1多路复用器的VHDL描述:entity mux2_1 is port( dina : i ...
- 02、微信小程序的数据绑定
02.微信小程序的数据绑定 目录结构: 模板内容: 使用bindtap绑定事件 <!--index.wxml--> <view class="container" ...