Kafka 学习翻译 - 介绍
Kafka是一个分布式的流式平台。可以从几个方面理解:
1. 三个重要的能力:
能够实现流式的发布和订阅数据,类似于消息队列或者企业级的消息分发系统。
能够在提供一定容错性和持久性能力的基础上存储数据。
流式处理数据
2. 用途:a. 系统间实时交换数据。 b. 利用其构建一个流式数据处理系统。
3. Kafka以集群的形式运行,并且具有跨数据中心横向扩展的能力。Kafka以topics归类消息。每一条数据都由key,value,timestamp构成。
4. 四类核心API:
Producer\Consumer:发布或者订阅topics
Stream:以流式的方式消费指定的topic,并向指定的topic发布内容
Connector:允许应用以对topics重用
客户端与服务端的通信通过TCP协议完成,并且协议被设计成后向兼容的方式。
Topics And Logs
Kafka的topic可以有任意多个消费者。
对每个topic来说,Kafka集群维护的分区日志(partitioned logs)机制如下:
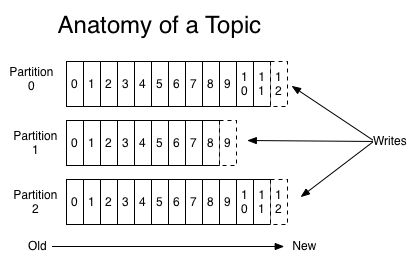
在每个分区中,数据都以不可改变的序列组织,新的数据追加在commit log尾部。每条记录均有一个offset唯一标识。
Kafka集群提供数据持久性保证,并且提供可配置的数据保留期限。
消费者记录所消费记录的当前offset,并且可以连续地或者跳跃地对记录进行消费。
上述机制使得消费者对Kafka集群的影响非常小,任意一个消费者的加入或者离开对于集群本身或者其他消费者都没有任何明显影响。
log的分区设计主要有如下目的。首先,分区使得可以log的大小不受单台服务器的限制。其次,这种设计也提供一定的并行性。
数据分布
Kafka集群中,每台服务器维护一定数量的分区,所有的分区平均分布在所有的机器上。对于每个分区来说,数据也被复制到一定数量的备份节点上,以提供一定的容错能力。
Geo-Replication
Kafka MirrorMaker 提供跨数据中心或者云端region的数据备份机制。可以利用这种机制实现数据的冷备份,或者双活场景中将数据放置在位置更近的机房中。
Producers
Producer向Topic发布数据,Producer负责选择将数据发送到topic的那个partion。可以通过轮询或者其他机制实现选择。
Comsumers
Comumer通过Group标识自己,每个topic中的一条记录都会被送到group中的一台consumer进行处理。
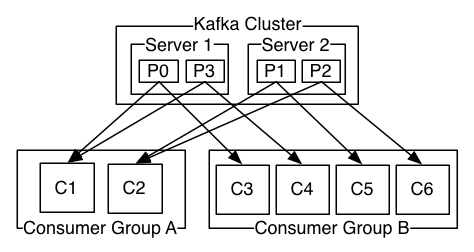
通常来说,topic的consumer group 数量都不会太大,但每个group中的consumer数通常是数个。
Kafka的消费机制通过将log的partitions分配各group中的每个消费者实例,使得在任意时间每个consumer都处理相当的partions。这种机制通过Kafka的通信协议动态维护。新加入的消费者节点或者挂掉的消费者节点都会引起重新分配。
Kafka仅提供分区内数据的顺序保证,对大多数应用来说够用了。如果需要topic的全局有序,则可以通过仅有一个partition来实现,这也意味着group中consumer的数量也是1。
多租户
Kafka支持多租户部署。
Guarantees
Kafka提供如下保证
同一个producer发送的数据以发送的数据追加记录。
consumer消费数据的顺序与其存储的顺序一致。
对于一个具有N个备份的topic,最大N-1个节点的故障不会引起数据丢失。
与传统企业级消息系统的比较
消息的分发通常有两种形式:队列模型或者发布-订阅模型。队列模型支持多个订阅者,但某条数据只会被某一个订阅者获取。发布-订阅模型中,消息广播到每个消费者中,因此,消费的整体能力不能够得到水平扩展。
Kafka的partition及consumer group设计使得其同时提供了这两种能力:水平扩展消费者群的处理能力 以及 某条消息被多个消费者处理。partition的设计使得同一个consumer group中可以扩展consumer来使得消费者群的处理能力得到提升。consumer group的设计使得某条消息可以发往多个group中的consumer,不同group间互不影响。
同时,这种设计机制也提供了一定程度的顺序性保证。在传统的消息系统中,要保证顺序性,则只能丢失消费者的水平扩展能力,如果要水平扩展消费者,由于每条记录被分发到不同的消费者中,则整体的顺序性得不到保证。而Kafka的partion设计使得在partition中,消息一定是被顺序送达消费者的,同时,对于有N个partion的topic,其最大的消费者数也能达到N。
Kafka提供的存储能力
作为任何一个消息系统,由于producer和consumer间是异步的,所有的消息都需要保存下来。
所有发往Kafka的数据都写盘并且复制到备份节点以提供容错能力。Kafka也允许producer在数据得到完全复制和写入硬盘后才得到成功响应。
Kafka存储的数据量也不会对其本身的性能造成影响。
Kafka提供的流式处理能力
除了读、写、存储这些基本的能力,Kafka被设计为能够实时处理数据流。
Kafka将如此场景视为流式处理:从输入的topic中流式获取数据,经过一定的处理并将流式结果写入输出的topic。Kafkati提供Stream API,支持对数据流的复杂处理。这使得对无序数据的处理,执行有状态的计算等成为可能。
Kafka 学习翻译 - 介绍的更多相关文章
- Kafka学习(一)kafka指南(about云翻译)
kafka 权威指南中文版 问题导读 1. 为什么数据管道是数据驱动企业的一个关键组成部分? 2. 发布/订阅消息的概念及其重要性是什么? 第一章 初识 kafka 企业是由数据驱动的.我们获取信息, ...
- Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- 【译】Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- KafKa——学习笔记
学习时间:2020年02月03日10:03:41 官网地址 http://kafka.apache.org/intro.html kafka:消息队列介绍: 近两年发展速度很快.从1.0.0版本发布就 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- Kafka学习-入门
在上一篇kafka简介的基础之上,本篇主要介绍如何快速的运行kafka. 在进行如下配置前,首先要启动Zookeeper. 配置单机kafka 1.进入kafka解压目录 2.启动kafka bin\ ...
- kafka学习2:kafka集群安装与配置
在前一篇:kafka学习1:kafka安装 中,我们安装了单机版的Kafka,而在实际应用中,不可能是单机版的应用,必定是以集群的方式出现.本篇介绍Kafka集群的安装过程: 一.准备工作 1.开通Z ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
随机推荐
- C++模板详解(系转载,但是个人添加了一些内容)
原文地址:http://www.cnblogs.com/gw811/archive/2012/10/25/2738929.html 零.概述 模板是C++支持参数化多态的工具,使用模板可以使用户为类或 ...
- spring----面试题
1.什么是Spring beans? Spring beans 是那些形成Spring应用的主干的java对象.它们被Spring IOC容器初始化,装配,和管理.这些beans通过容器中配置的元数据 ...
- linux系统参数
vm.swappiness = 清理掉cache给新的程序用当然可以, 但也带来了新的问题, 也就是如果这些(原来cache里的)数据还要使用, 又得重新cache. 产生了新的IO, 新的wait. ...
- MySql接口API函数综述
C API函数概述 函数 描述 mysql_affected_rows() 返回上次UPDATE.DELETE或INSERT查询更改/删除/插入的行数. mysql_autocommit() 切换 a ...
- CSS position属性 标签: css 2016-09-06 15:58 78人阅读 评论(0) 收藏
踩了position的坑,主要是因为对position属性理解不深. 以下是w3school中对position的解释: 可能的值 值 描述 absolute 生成绝对定位的元素,相对于 static ...
- php 上传大文件注意问题
一.如果要对文件进行复杂的处理,注意设置php.ini中的max_execution_time.max_input_time为足够大,如大量字符串处理urlencode等. 二.如果文件处理要占用较大 ...
- nfs 服务器
1.创建共享目录 #mkdir /home/hellolinux/nfs 2.创建或修改/etc/exports文件 #vi /etc/exports home/hellolinux/nfs 192. ...
- Windows环境双系统安装环境配置
(最惊喜的事情莫过于...在安装系统完成重新试图安装Docker时解决了关于HyperV的问题,结果提示Docker只能在Win10 Pro或者Enterprise环境下运行...我很坚强...可以按 ...
- Spring 整合Hibernate 示例
虽然Spring整合Hibernate早就会了,但经常在创建项目整合这两个框架的时候出一些低级错误.所以在这里写一个示例,以后再遇到错误时,再把遇到的错误或异常添加上. 一.创建一个动态WEB工程,添 ...
- bzoj2331 [SCOI2011]地板
Description lxhgww的小名叫“小L”,这是因为他总是很喜欢L型的东西.小L家的客厅是一个的矩形,现在他想用L型的地板来铺满整个客厅,客厅里有些位置有柱子,不能铺地板.现在小L想知道,用 ...