第四周 day4 python学习笔记
关于装饰器的更多信息可以参考http://egon09.blog.51cto.com/9161406/1836763
1.装饰器Decorator
装饰器:本质上是函数,(装饰其他函数),就是为其他函数添加附加功能
原则:不能修改被装饰函数的源代码;不能修改被装饰函数的调用方式
#实现装饰器的知识储备:
1.函数即变量
2.高阶函数,有两种方式:
(1)把一个函数名当做实参传递给另一个函数(在不修改被装饰函数源代码的情况下为其添加功能)
(2)返回值中包含函数名(不修改函数调用的方式)
3.嵌套函数
高阶函数+嵌套函数==》装饰器import time
#计算一个函数的运行时间的装饰器
def timer(func):
def wrapper(*kargs,**kwargs):
start_time=time.time()
func()
end_time=time.time()
print("the func runtime is %s"%(end_time-start_time))
return wrapper @timer
def test1():
time.sleep(3)
print("in the test1....") test1()
def bar():
print("in the bar...") def test(func):
print(func)#打印出该函数变量的地址
func() test(bar)
import time
def bar():
time.sleep(2)
print("in the bar...") def test(func):
start_time=time.time()
func() #run bar()
end_time=time.time()
print(" the func runtime is %s"%(end_time-start_time)) test(bar)
import time
def bar():
time.sleep(2)
print("in the bar...") def test2(func):
print(func)
return func bar2=test2(bar)
bar2()#嵌套函数
#局部作用域和全局作用域的访问顺序
x=0
def grandpa():
x=1
print("grandpa:",x)
def dad():
x=2
print("dad:",x)
def son():
x=3
print("son:",x)
son()
dad()
grandpa()#匿名函数:没有定义函数名字的函数
calc=lambda x,y:x+y
print(calc(13,15))import time
def timer(func):
def deco(*kargs,**kwargs):
start_time=time.time()
func(*kargs,**kwargs)
end_time=time.time()
print(" the func runtime is %s"%(end_time-start_time))
return deco @timer # test1=timer(test1)
def test1():
time.sleep(2)
print("in the test1.....") # test1=timer(test1)
test1() @timer
def test2(name,age):
time.sleep(3)
print("in the test2:",name,age) test2("Jean_V",20)#装饰器进阶版
#对各个页面添加用户认证
username,password="admin",""
def auth(auth_type):
print("auth_type:",auth_type)
def out_wrapper(func):
def wrapper(*args,**kwargs):
if auth_type=="local":
uname=input("请输入用户名:").strip()
passwd=input("请输入密码:").strip()
if uname==username and passwd==password:
print("\033[32;1m User has passed authentication\033[0m")
res=func(*args,**kwargs)
print("************after authentication")
print(res)
else:
exit("\033[31;1m Invalid username or password\033[0m")
elif auth_type=="LADP":
print("我不会LADP认证,咋办?。。。")
return wrapper
return out_wrapper def index():
print("index page......") @auth(auth_type="local")#home 页采用本地验证
def home():
print("home page.....")
return "from home page....." @auth(auth_type="LADP")#bbs 页采用LADP验证
def bbs():
print("bbs page....") index()
print(home())
home()
bbs()2.列表生成式
#列表生成式:一句代码更加简洁
a=[i*2 for i in range(10)]
print(a)
b=[i*i for i in range(20)]
print(b)
#上面的列表生成式等同于
res=[]
for i in range(10):
res.append(i*2)
print(res) #列表生成式的更加高级的用法:
#[funv(i) for i in range(10)]
def fun(n):#定义一个求阶乘的函数
if n>1:
return n*fun(n-1)
else:
return 1
#利用函数生成10以内的阶乘
c=[fun(i) for i in range(10)]
print(c)
3.迭代器与生成器
参考信息:http://www.cnblogs.com/alex3714/articles/5765046.html
生成器:按照某种算法可以进行推算,不必创建完整的List,节省大量空间,在迭代过程中一边循环一边计算的机制,称之为生成器generator
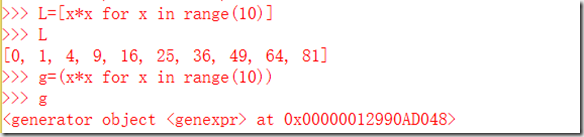
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
针对generator可以使用for循环输出;因为generator也是可迭代对象
for j in g:
print(j)
如果要一个一个打印出来,可以通过__next__()函数获得generator的下一个返回值:

 著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
#斐波那契数列
#输出斐波那契数列的前m个数
def fibnacci(m):
n,a,b=0,0,1
while n<m:
print(b)
a,b=b,a+b #这一句相当于:t=(b,a+b) a=t[0] b=t[1]
n+=1
return 'done'
fibnacci(10)
上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
#斐波那契数列
#输出斐波那契数列的前m个数
def fibnacci(m):
n,a,b=0,0,1
while n<m:
yield b #这一句很关键
a,b=b,a+b #这一句相当于:t=(b,a+b) a=t[0] b=t[1]
n+=1
return ' well done'#异常的时候显示的信息
f=fibnacci(10)
for i in f:
print(i) g=fibnacci(6)
#捕获异常并处理
while True:
try:
x=next(g)
print("g:",x)
except StopIteration as e:
print("Generator return value :",e.value)
break
在上面fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
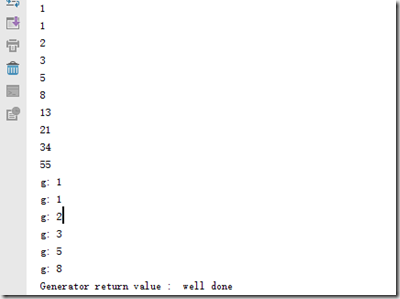
还可通过yield实现在单线程的情况下实现并发运算的效果
生产者消费者问题 (通过生成器实现协程并行运算)
#生产者消费者问题
import time
def consumer(name):
print("%s,准备好吃汉堡包了"%name)
while True:
hamburg=yield
print("第[%s]个汉堡包来了,被[%s]吃了"%(hamburg+1,name)) def producer(name):
c1=consumer('Alice')
c2=consumer('Bob')
#生产者生产的时候需要通知消费者前来吃
c1.__next__()
c2.__next__()
print("%s,开始做汉堡包了"%name)
for i in range(10):
time.sleep(1.5)
print("做好了1个汉堡包,可以吃了")
c1.send(i)
c2.send(i) producer("Jean")
迭代器
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str、bytes等;
一类是generator,包括生成器和带yield的generator function。
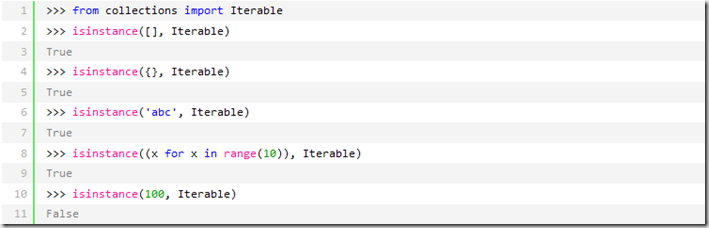
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
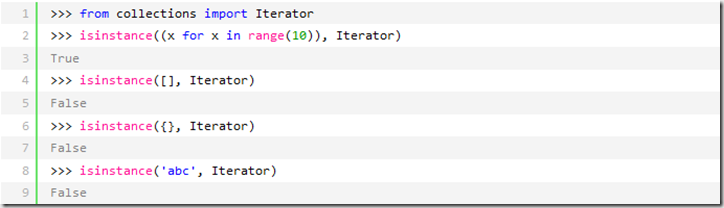
而生成器不但可以作用于for循环,还可以被__next__()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:

#迭代器 range(10)表示一个可迭代对象,不是迭代器
from collections import Iterable
from collections import Iterator
a=range(10)
print(a)
print(type(a))
print(isinstance(a,Iterable))
print(isinstance(range(20),Iterator))
for x in a:
print(x)
#for循环其实就是__next__函数不断迭代出来的
Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
 Iterator
Iterator
 小结:
小结:
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
4.python 内置函数
参考python官方信息:https://docs.python.org/3/library/functions.html
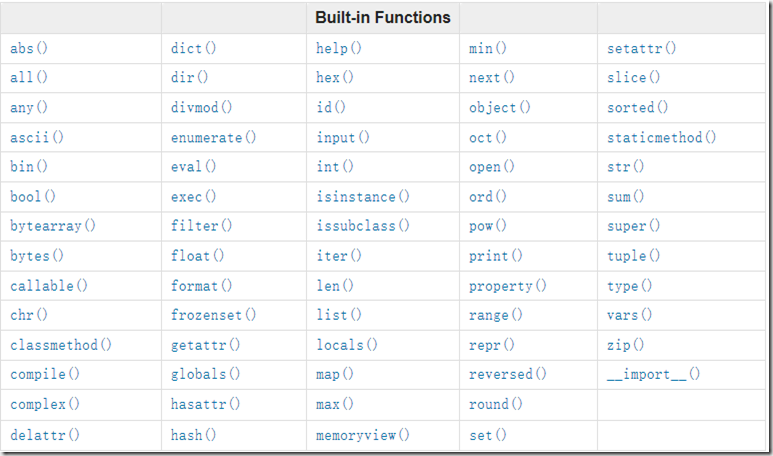
#内置函数
#all(Iterable),当所有的元素都是为true,则返回true;0为false,非零为true
print(all([1,2]))#True
print(all([0,1,2]))#false
print(any([0,1,2]))#True
print(ascii([1,2,"hello","你好世界"]))#[1, 2, 'hello', '\u4f60\u597d\u4e16\u754c']
print(bin(128))#十进制转二进制#0b10000000
#字符串不能修改,只是生成一个新的字符串;二进制的字符串更不可以修改
a=bytes("abcde",encoding="utf8")#二进制类型
print(a)
print(a.capitalize())
b=bytearray("abcde",encoding="utf-8")
print(b[0])#
b[2]=54#在bytearry 中可以修改
print(b)
print(chr(97))#'a'
print(ord('a'))# print(divmod(5,2))#返回商和余数
#filter过滤器
#编写过滤器,把奇数过滤掉,打印剩下剩下偶数
res=filter(lambda n:n%2==0,range(100))
for x in res:
print(x) #map函数,映射函数
res2=map(lambda n:n*n,range(10))
for x in res2:
print(x) import functools
#reduce 函数,求累加
res3=functools.reduce(lambda x,y:x+y,range(10))
print(res3)
#利用reduce求阶乘
res4=functools.reduce(lambda x,y:x*y,range(1,10))
print(res4) #打印当前页面中的变量利用《key,values》的字典样式
print(globals())#全局变量
print(locals())#局部变量 #hex()转成十六进制,oct转八进制
print(hex(361))
print(oct(361))
#python中一切皆对象,python是一门面向对象的解释性语言
print(pow(2,8))#2的八次方
print(round(3.555412,2))#四舍五入法,3.56
a={5:12,3:14,-51:25,45:98,100:23,56:78}
print(sorted(a.items()))#将字典进行排序,默认采用key进行排序
print(sorted(a.items(),key=lambda x:x[1]))#将字典进行排序,使用的value进行排序
print(a) #zip()将两个对象的元素对应起来
A=[1,2,3,4]
B=['a','b','c','d','e','f']
for i in zip(A,B):
print(i)
#内置函数中的compile()方法
#把fibnacci函数进行编译并执行
code='''#输出斐波那契数列的前m个数
def fibnacci(m):
n,a,b=0,0,1
while n<m:
yield b #这一句很关键,yield返回当前状态,保存当前状态
a,b=b,a+b #这一句相当于:t=(b,a+b) a=t[0] b=t[1]
n+=1
return ' well done'#异常的时候显示的信息
f=fibnacci(10)
for i in f:
print(i)
'''
# py_obj=compile(code,"err.log","exec")
# exec(py_obj)
exec(code)
5.序列化与反序列化
把变量从内存中变成可存储或传输的过程称之为序列化,在Python中可以利用
json
或则
pickle
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化
更多信息可以参考:http://www.cnblogs.com/MnCu8261/p/5539254.html
#json 序列化
#pickle序列化:与接送序列化相似,只是更高级而已
#将信息写入到硬盘上
import json
import pickle
def sayhi(name):
print("name",name)
info={
'name':'Jean_V',
'age':22,
'time':'2017-10-11',
'func':sayhi
}
#f=open("json_test.txt",'b')
f=open("json_test.txt",'wb')#使用pickle时要使用二进制编码格式,wb,rb等
# f.write(json.dumps(info))
f.write(pickle.dumps(info))
# f.write(str(info))也是ok
f.close()
#json反序列化
#pickle反序列化:与json序列化相似,支持更高级的
#从硬盘上把信息加载到内存中
import json
import pickle
def sayhi(name):
print("name",name)
print("name2:",name) f=open("json_test.txt","rb")
# f=open("json_test.txt",'r')
#print(eval(f.read())['age'])也可以ok
# data=json.loads(f.read())
data=pickle.loads(f.read())
print(data)
print(data['age'])
print(data['func'])
print(data['func']("Jean_Name"))
#pickle 序列化
#dump多次,只是复制了新的版本,原来的版本信息还在,因此:
#建议dump一次,load一次,保持最新的
import pickle
info={
'name':"Jean_V",
'age':22,
'hello':'hello friends'
}
f=open("json_test2.txt",'wb')
pickle.dump(info,f)
f.close()
#pickle反序列化
import pickle
f=open("json_test2.txt","rb")
data=pickle.load(f)#等同于data=pickele.loads(f.read())
print(data['name'])
f.close()
6.作业
第四周 day4 python学习笔记的更多相关文章
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- python学习笔记之module && package
个人总结: import module,module就是文件名,导入那个python文件 import package,package就是一个文件夹,导入的文件夹下有一个__init__.py的文件, ...
- python学习笔记(六)文件夹遍历,异常处理
python学习笔记(六) 文件夹遍历 1.递归遍历 import os allfile = [] def dirList(path): filelist = os.listdir(path) for ...
- python学习笔记--Django入门四 管理站点--二
接上一节 python学习笔记--Django入门四 管理站点 设置字段可选 编辑Book模块在email字段上加上blank=True,指定email字段为可选,代码如下: class Autho ...
- python学习笔记--Django入门0 安装dangjo
经过这几天的折腾,经历了Django的各种报错,翻译的内容虽然不错,但是与实际的版本有差别,会出现各种奇葩的错误.现在终于找到了解决方法:查看英文原版内容:http://djangobook.com/ ...
- python学习笔记(一)元组,序列,字典
python学习笔记(一)元组,序列,字典
随机推荐
- ie8兼容总结
ie兼容总结 1.页面必须编写规范 doctype 必须申明,否则会让浏览器出现怪异模式呈现,我记得一次是页面没有写doctype,样式的继承也会有问题,明明body里面写了字体样式12px,页面ta ...
- 【随笔】关于绝对定位absolute相对于父元素定位的问题
绝对定位absolute的官方定义: 设置为绝对定位的元素框从文档流完全删除,并相对于其包含块定位,包含块可能是文档中的另一个元素或者是初始包含块.元素原先在正常文档流中所占的空间会关闭,就好像该元素 ...
- 关于Jquery事件绑定的心得
今日在工作的时候,遇上了一些和事件绑定有关的问题无法解决,于是在网上找到了以下资料,稍加整理了下. 对于事件绑定,jQuery的 bind / unbind 大多数时候可能并不会用到,取而代之的是直接 ...
- css3毛玻璃效果白边问题
注:css3毛玻璃效果应该很多人都知道怎么实现,但是有个问题是图片模糊了之后相当于缩小了,所以颜色深的图片会出现白边,这里说下我参考网上的解决方式吧! 1.毛玻璃实现方法: CSS3 blur滤镜实现 ...
- 破解b站极验验证码
这就是极验验证码,通过拖动滑块移动拼图来验证.我们观察到点击滑块时拼图才会出现,所以我们可以在点击滑块之前截取图像,点击滑块再截取一次图像,将前后两次图像做比较就可以找到图片改动的位置.获得位置后,我 ...
- 微信小程序wx:for循环
最近做微信小程序碰到了一些问题,和wx:for循环相关,wx:for有很多用途,例如可以用于swiper中图片的循环,也就是所谓的轮播图,也可以用于其它的循环,可以大大地减少代码量. 但wx:for. ...
- nodejs图片裁剪、水印(使用images)
/** * Created by chaozhou on 2015/9/21. */ var images = require("images"); /** * 缩放图像 * @p ...
- struts2随笔
1.struts.properties配置常量等同于struts.xml中配置(置于类加载路径下面)struts.multipart.maxSize文件上传最大大小struts.action.exte ...
- Octotree Chrome安装与使用整理
Octotree Chrome作用: 主要使你在github查看项目时可以清晰明了的看到项目的结构以及具体代码,使下载代码更具有目的性,减少不必要代码的下载,而且看起来更清楚. 效果图:(安装插件前) ...
- webpack使用extract-text-webpack-plugin打包时提示错误Use Chunks.groupsIterable and filter by instanceof Entryp
转自:https://blog.csdn.net/gezilan/article/details/80020417 前提条件: 当前时间是2018年4月20日. webpack的最新版本为是 v4.6 ...