【NLP_Stanford课堂】语言模型3
一、产生句子
方法:Shannon Visualization Method
过程:根据概率,每次随机选择一个bigram,从而来产生一个句子
比如:
- 从句子开始标志的bigram开始,我们先有一个(<s>, w),w是随机一个单词,比较有可能的是I这个单词,那么我们就有(<s>, I)
- 随机选择下一个单词,得到(w,x),这里w是I,x概率最大的是want
- 重复以上步骤,直到得到</s>

问题1:过度拟合。N-grams在预测句子上只有当测试语料库和训练语料库非常相似的时候才会比较准确。比如不能把在《莎士比亚全集》上训练的模型在《华尔街日报》上测试。
问题2:在训练集中没有出现但是测试集中有出现。比如:

在训练集中"denied the offer"出现的概率为0,但是其在测试集中有出现,但是我们的模型依然只会记住其概率为0,那么就识别不了这个词组,如果是机器翻译,那么就无法翻译这个词组。
那么如何应对测试集中概率为0的数据呢?
二、如何应对bigram中概率为0的数据?
方法:add-one smoothing (Laplace smoothing)
主要思想:假装每个单词我们都看了一遍,然后都加到总数里
从而将原来使用最大似然估计的概率转变为Add-1 估计的概率:
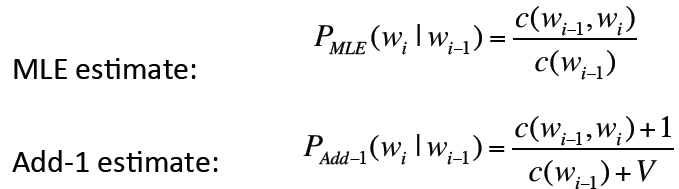
因为我们把每个单词的计数都加了1,那么一共有V的单词的话,计数总数就加了V
· 最大似然估计:
假设单词“bagel”在一个由1000000个词组成的语料库中出现了400次,那么在其他语料库中随机出现一个单词是“bagel”的概率是多少?
最大似然估计出来的概率为400/1000000=.004
这个可能会非常不准确,但是这最有可能的估计了。
· Add-1 估计:
将所有的计数都加1,则有:

bigram概率则为:
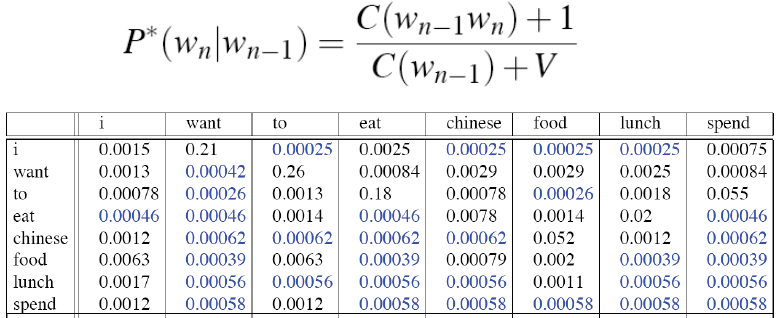
重新计算计数得:
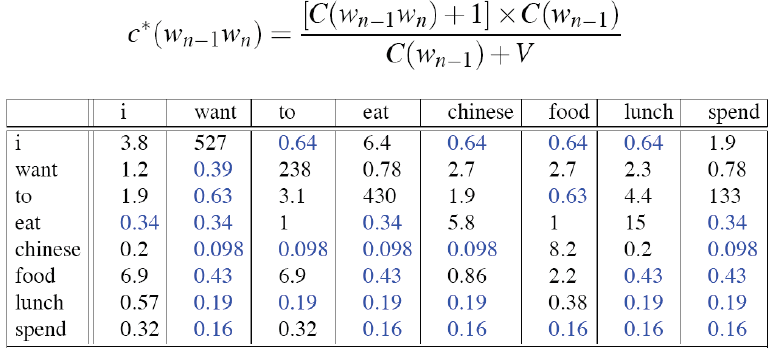
可以发现跟实际的计数非常不一样,差别可能会很大,add-1估计太过粗糙,所以实际应用中我们并不在N-gram中使用这种方法,但是在其他模型中会使用这种方法,比如文本分类这种概率为0的数目并不会很多的情况。
三、backoff回退和interpolation插值
backoff指:由于N-gram模型中当使用的N值较大时,很多项的概率会是0,所以换用较小的N值。
interpolation指:混合多种模型,比如trigram、bigram和unigram,其是按照权重分配多种模型的概率的。
实际应用表明interpolation的效果更好。
1. 线性插值
简单插值:
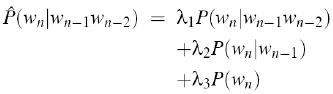 ,
, 
第一项是trigram得出的概率,第二项是bigram,第三项是unigram。
上式中使用的权值lambdas值为常数,下式我们基于内容使用前两个词作为权值的参数,更科学灵活:
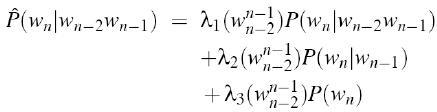
· 怎么设置lambdas参数
方法:使用held-out留存语料库
首先将数据分为训练数据集、留存数据集和测试数据集:

其中训练数据集用以训练n-gram模型、然后在留存数据集里检验模型计算出的概率,再反过来修正训练数据集中的lambdas值,用以找到能使留存数据集中的概率最大的lambdas值,即:
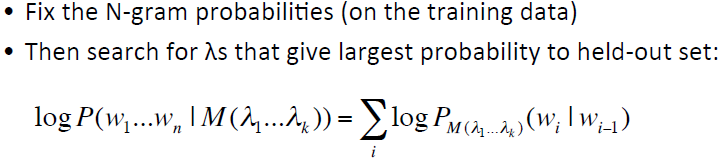
2. 如何应对未知的词汇
如果我们能提前知道所有的词汇,那词汇表就固定下来了,只能进行封闭的词汇任务。
而在大多数应用中,并不能提前知道所有的词汇,我们称词汇表外的词为Out Of Vocabulary(OOV words),从而能进行开放的词汇任务。
我们使用token<UNK>来标记这种未知的词汇。
在具体的训练过程中,首先有一个固定的词汇表L,大小为V,在文本标准化时,将所有不在词汇表中的训练词汇替换为<UNK>,然后在此基础上,将其作为正常的单词进行数据的训练。
在测试阶段,如果在输入文本中出现一个未知的单词(没有在训练阶段出现过的),就将其替换为<UNK>,然后做正常的测试。
3. n-gram如何应对非常巨大的语料库
诸如Google N-gram corpus,其语料库非常巨大,n-gram难以应对。
方法之一是剪枝:
a) 只存储N-gram计数超过界限值的项,移除只出现一次的高阶n-grams。
b)使用基于熵的剪枝方法。
还有其他的方法:
a) 使用有效的数据结构,比如字典树Trie
b) Bloom filters布隆过滤器:一种近似语言模型
c) 不将词简单地存为字符串,而存储为索引:使用哈弗曼编码
d) 使用Quantize probabilities,不将概率存储为8位的float,而存储为长度为4-8的位
· 如何对巨量的N-grams做平滑
通用方法是“Stupid backoff” (Brants et al. 2007),非常简单但是有效,具体如下:

即,当某项计数为0时,再往前一个词,即从k-gram变成k+1-gram,并设有一个权重0.4。
四、总结:N-gram平滑方法
1. Add-1 smoothing:对文本类别有效,但是对语言模型效果不好
2. 最通用的方法:插值方法
3. 对大型语料库:Stupid backoff
五、高级语言模型
1. 判别模型:选择多个N-gram的权重来提高效果,而不是在多个N-gram中选择一个
2. 基于解析的模型
3. 缓存模型:将最近使用的单词放入缓存,然后在缓存的基础上计算新词的条件概率
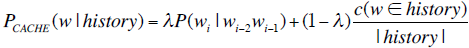
但是这种方法对于语音识别效果非常差。
【NLP_Stanford课堂】语言模型3的更多相关文章
- 【NLP_Stanford课堂】语言模型2
一.如何评价语言模型的好坏 标准:比起语法不通的.不太可能出现的句子,是否为“真实”或"比较可能出现的”句子分配更高的概率 过程:先在训练数据集上训练模型的参数,然后在测试数据集上测试模型的 ...
- 【NLP_Stanford课堂】语言模型1
一.语言模型 旨在:给一个句子或一组词计算一个联合概率 作用: 机器翻译:用以区分翻译结果的好坏 拼写校正:某一个拼错的单词是这个单词的概率更大,所以校正 语音识别:语音识别出来是这个句子的概率更大 ...
- 【NLP_Stanford课堂】语言模型4
平滑方法: 1. Add-1 smoothing 2. Add-k smoothing 设m=1/V,则有 从而每一项可以跟词汇表的大小相关 3. Unigram prior smoothing 将上 ...
- 【NLP_Stanford课堂】文本分类1
文本分类实例:分辨垃圾邮件.文章作者识别.作者性别识别.电影评论情感识别(积极或消极).文章主题识别及任何可分类的任务. 一.文本分类问题定义: 输入: 一个文本d 一个固定的类别集合C={c1,c2 ...
- 【NLP_Stanford课堂】拼写校正
在多种应用比如word中都有拼写检查和校正功能,具体步骤分为: 拼写错误检测 拼写错误校正: 自动校正:hte -> the 建议一个校正 建议多个校正 拼写错误类型: Non-word Err ...
- 【NLP_Stanford课堂】情感分析
一.简介 实例: 电影评论.产品评论是positive还是negative 公众.消费者的信心是否在增加 公众对于候选人.社会事件等的倾向 预测股票市场的涨跌 Affective States又分为: ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- 【NLP_Stanford课堂】最小编辑距离
一.什么是最小编辑距离 最小编辑距离:是用以衡量两个字符串之间的相似度,是两个字符串之间的最小操作数,即从一个字符转换成另一个字符所需要的操作数,包括插入.删除和置换. 每个操作数的cost: 每个操 ...
- 【NLP_Stanford课堂】句子切分
依照什么切分句子——标点符号 无歧义的:!?等 存在歧义的:. 英文中的.不止表示句号,也可能出现在句子中间,比如缩写Dr. 或者数字里的小数点4.3 解决方法:建立一个二元分类器: 检查“.” 判断 ...
随机推荐
- APP高级抓包
1.fiddler的证书安装问题时密码问题 问题:我手机下载了fiddler证书 从设置里面安装证书 可是需要输入密码 我没有设置过密码 不知道密码是什么 请问有人遇到过这样的问题的?求解决方法 因为 ...
- TortoiseGit学习系列之Git和TortoiseGit的区别
不多说,直接上干货! Git和TortoiseGit的区别: TortoiseGit的安装和使用依赖Git.
- 关于ie8兼容性问题的处理
1.replace将单引号变成双引号 var page=user.customConfig.replace(/\‘|’/ig,"\""); 兼容谷歌和ie var pag ...
- Hibernate实体类编写规则和主键策略
一.实体类的编写规则 1.属性要是私有的. 2.要有公开的setter和getter方法供外界访问和修改. 3.每一个实体类要有一个属性作为唯一值(一般都是使用对于数据表的主键). 4.建议数据类型不 ...
- bzoj 4161: Shlw loves matrixI
Description 给定数列 {hn}前k项,其后每一项满足 hn = a1h(n-1) + a2h(n-2) + ... + ak*h(n-k) 其中 a1,a2...ak 为给定数列.请计算 ...
- Magento 2中文文档教程 - Magento 2.1.x 系统需求
Magento 2.1.x 系统需求 操作系统 (Linux x86-64) Linux发行版如红帽企业Linux(RHEL),CentOS,Ubuntu,Debian,等等 内存需求 升级的应用程序 ...
- PHP学习6——常用函数
主要内容: 字符串处理函数 时间和日期处理函数 字符串处理函数 echo输出字符串 print输出字符串,带返回值1 print.php <?php var_dump(print("有 ...
- first post
post
- C++Array类模板编写笔记
C++Array类模板 函数模板和类模板都属于泛型技术,利用函数模板和类模板来创建一个具有通用功能的函数和类,以支持多种不同的形参,从而进一步简化重载函数的函数体设计. 声明方法:template&l ...
- BEM样式使用规范
BEM 是 Block(块) Element(元素) Modifier(修饰器)的简称 使用BEM规范来命名CSS,组织HTML中选择器的结构,利于CSS代码的维护,使得代码结构更清晰(弊端主要是名字 ...