使用 Spark SQL 高效地读写 HBase
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:
- 一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;
- TableInputFormat 中不支持 BulkGet;
- 不能享受到 Spark SQL 内置的 catalyst 引擎的优化。
基于这些问题,来自 Hortonworks 的工程师们为我们带来了全新的 Apache Spark—Apache HBase Connector,下面简称 SHC。通过这个类库,我们可以直接使用 Spark SQL 将 DataFrame 中的数据写入到 HBase 中;而且我们也可以使用 Spark SQL 去查询 HBase 中的数据,在查询 HBase 的时候充分利用了 catalyst 引擎做了许多优化,比如分区修剪(partition pruning),列修剪(column pruning),谓词下推(predicate pushdown)和数据本地性(data locality)等等。因为有了这些优化,通过 Spark 查询 HBase 的速度有了很大的提升。
注意:SHC 同时还提供了将 DataFrame 中的数据直接写入到 HBase 中,但是整个代码并没有什么优化的地方,所以本文对这部分不进行介绍。感兴趣的读者可以直接到这里查看相关写数据到 HBase 的代码。
SHC 是如何实现查询优化的呢
SHC 主要使用下面的几种优化,使得 Spark 获取 HBase 的数据扫描范围得到减少,提高了数据读取的效率。
将使用 Rowkey 的查询转换成 get 查询
我们都知道,HBase 中使用 Get 查询的效率是非常高的,所以如果查询的过滤条件是针对 RowKey 进行的,那么我们可以将它转换成 Get 查询。为了说明这点,我们使用下面的例子进行说明。假设我们定义好的 HBase catalog 如下:
val catalog = s"""{ |"table":{"namespace":"default", "name":"iteblog", "tableCoder":"PrimitiveType"}, |"rowkey":"key", |"columns":{ |"col0":{"cf":"rowkey", "col":"id", "type":"int"}, |"col1":{"cf":"cf1", "col":"col1", "type":"boolean"}, |"col2":{"cf":"cf2", "col":"col2", "type":"double"}, |"col3":{"cf":"cf3", "col":"col3", "type":"float"}, |"col4":{"cf":"cf4", "col":"col4", "type":"int"}, |"col5":{"cf":"cf5", "col":"col5", "type":"bigint"}, |"col6":{"cf":"cf6", "col":"col6", "type":"smallint"}, |"col7":{"cf":"cf7", "col":"col7", "type":"string"}, |"col8":{"cf":"cf8", "col":"col8", "type":"tinyint"} |}|}""".stripMargin |
那么如果有类似下面的查询
val df = withCatalog(catalog)df.createOrReplaceTempView("iteblog_table")sqlContext.sql("select * from iteblog_table where id = 1")sqlContext.sql("select * from iteblog_table where id = 1 or id = 2")sqlContext.sql("select * from iteblog_table where id in (1, 2)") |
因为查询条件直接是针对 RowKey 进行的,所以这种情况直接可以转换成 Get 或者 BulkGet 请求的。第一个 SQL 查询过程类似于下面过程
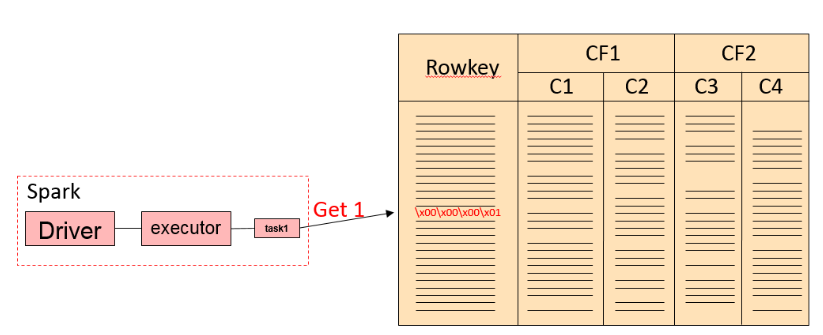
后面两条 SQL 查询其实是等效的,在实现上会把 key in (x1, x2, x3..) 转换成 (key == x1) or (key == x2) or ... 的。整个查询流程如下:
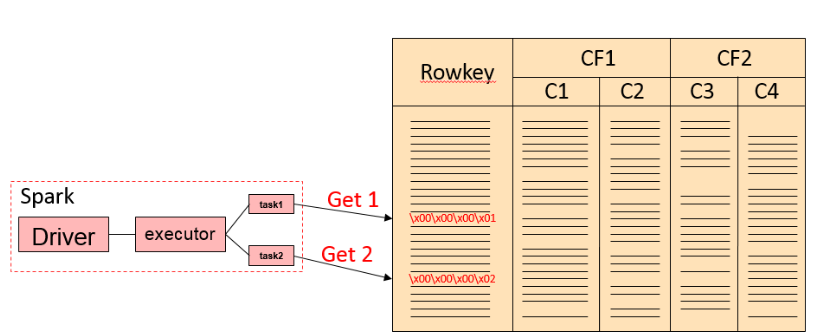
如果我们的查询里面有 Rowkey 还有其他列的过滤,比如下面的例子
sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 and col7 = 'xxx'") |
那么上面的 SQL 翻译成 HBase 的下面查询
val filter = new SingleColumnValueFilter( Bytes.toBytes("cf7"), Bytes.toBytes("col7 ") CompareOp.EQUAL, Bytes.toBytes("xxx"))val g = new Get(Bytes.toBytes(1))g.addColumn(Bytes.toBytes("cf6"), Bytes.toBytes("col6"))g.addColumn(Bytes.toBytes("cf8"), Bytes.toBytes("col8"))g.setFilter(filter) |
如果有多个 and 条件,都是使用 SingleColumnValueFilter 进行过滤的,这个都好理解。如果我们有下面的查询
sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 or col7 = 'xxx'") |
那么在 shc 里面是怎么进行的呢?事实上,如果碰到非 RowKey 的过滤,那么这种查询是需要扫描 HBase 的全表的。上面的查询在 shc 里面就是将 HBase 里面的所有数据拿到,然后传输到 Spark ,再通过 Spark 里面进行过滤,可见 shc 在这种情况下效率是很低下的。
def or[T](left: HRF[T], right: HRF[T])(implicit ordering: Ordering[T]): HRF[T] = { val ranges = ScanRange.or(left.ranges, right.ranges) val typeFilter = TypedFilter.or(left.tf, right.tf) HRF(ranges, typeFilter, left.handled && right.handled)} |
同理,类似于下面的查询在 shc 里面其实都是全表扫描,并且将所有的数据返回到 Spark 层面上再进行一次过滤。
sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 or col7 <= 'xxx'")sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 or col7 >= 'xxx'")sqlContext.sql("select id, col6, col8 from iteblog_table where col7 = 'xxx'") |
很显然,这种方式查询效率并不高,一种可行的方案是将算子下推到 HBase 层面,在 HBase 层面通过 SingleColumnValueFilter 过滤一部分数据,然后再返回到 Spark,这样可以节省很多数据的传输。
组合 RowKey 的查询优化
shc 还支持组合 RowKey 的方式来建表,具体如下:
def cat = s"""{ |"table":{"namespace":"default", "name":"iteblog", "tableCoder":"PrimitiveType"}, |"rowkey":"key1:key2", |"columns":{ |"col00":{"cf":"rowkey", "col":"key1", "type":"string", "length":"6"}, |"col01":{"cf":"rowkey", "col":"key2", "type":"int"}, |"col1":{"cf":"cf1", "col":"col1", "type":"boolean"}, |"col2":{"cf":"cf2", "col":"col2", "type":"double"}, |"col3":{"cf":"cf3", "col":"col3", "type":"float"}, |"col4":{"cf":"cf4", "col":"col4", "type":"int"}, |"col5":{"cf":"cf5", "col":"col5", "type":"bigint"}, |"col6":{"cf":"cf6", "col":"col6", "type":"smallint"}, |"col7":{"cf":"cf7", "col":"col7", "type":"string"}, |"col8":{"cf":"cf8", "col":"col8", "type":"tinyint"} |} |}""".stripMargin |
上面的 col00 和 col01 两列组合成一个 rowkey,并且 col00 排在前面,col01 排在后面。比如 col00 ='row002',col01 = 2,那么组合的 rowkey 为 row002\x00\x00\x00\x02。那么在组合 Rowkey 的查询 shc 都有哪些优化呢?现在我们有如下查询
df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 = 'row000' and col01 = 0").show() |
根据上面的信息,RowKey 其实是由 col00 和 col01 组合而成的,那么上面的查询其实可以将 col00 和 col01 进行拼接,然后组合成一个 RowKey,然后上面的查询其实可以转换成一个 Get 查询。但是在 shc 里面,上面的查询是转换成一个 scan 和一个 get 查询的。scan 的 startRow 为 row000,endRow 为 row000\xff\xff\xff\xff;get 的 rowkey 为 row000\xff\xff\xff\xff,然后再将所有符合条件的数据返回,最后再在 Spark 层面上做一次过滤,得到最后查询的结果。因为 shc 里面组合键查询的代码还没完善,所以当前实现应该不是最终的。
在 shc 里面下面两条 SQL 查询下沉到 HBase 的逻辑一致
df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 = 'row000'").show()df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 = 'row000' and col01 = 0").show() |
唯一区别是在 Spark 层面上的过滤。
scan 查询优化
如果我们的查询有 < 或 > 等查询过滤条件,比如下面的查询条件:
df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 > 'row000' and col00 < 'row005'").show() |
这个在 shc 里面转换成 HBase 的过滤为一条 get 和 一个 scan,具体为 get 的 Rowkey 为 row0005\xff\xff\xff\xff;scan 的 startRow 为 row000,endRow 为 row005\xff\xff\xff\xff,然后将查询的结果返回到 spark 层面上进行过滤。
总体来说,shc 能在一定程度上对查询进行优化,避免了全表扫描。但是经过评测,shc 其实还有很多地方不够完善,算子下沉并没有下沉到 HBase 层面上进行。目前这个项目正在和 hbase 自带的 connectors 进行整合(https://github.com/apache/hbase-connectors),相关 issue 参见 Enhance the current spark-hbase connector。
使用 Spark SQL 高效地读写 HBase的更多相关文章
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
- Spark SQL讲解
Spark SQL讲解 Spark SQL是支持在Spark中使用Sql.HiveSql.Scala中的关系型查询表达式.它的核心组件是一个新增的RDD类型SchemaRDD,它把行对象用一个Sche ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
- Adaptive Execution如何让Spark SQL更高效更好用
1 背 景 Spark SQL / Catalyst 和 CBO 的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性.但是 执行计划一旦生成,便不可更改,即使执行过程中发 ...
- spark sql读hbase
项目背景 spark sql读hbase据说官网如今在写,但还没稳定,所以我基于hbase-rdd这个项目进行了一个封装,当中会区分是否为2进制,假设是就在配置文件里指定为#b,如long#b,还实用 ...
随机推荐
- Educational Codeforces Round 56 (Rated for Div. 2) F. Vasya and Array
题意:长度为n的数组,数组中的每个元素的取值在1-k的范围内或者是-1,-1代表这个元素要自己选择一个1-k的数字去填写,然后要求填完的数组中不能出现连续长度大于len的情况,询问填空的方案数. 题解 ...
- Golang源码学习:调度逻辑(二)main goroutine的创建
接上一篇继续分析一下runtime.newproc方法. 函数签名 newproc函数的签名为 newproc(siz int32, fn *funcval) siz是传入的参数大小(不是个数):fn ...
- 【原创】CentOS 7搭建多实例MySQL8(想要几个搞几个)
起因 最近项目上开始重构,可能会用到主从加读写分离的情况,就想先在本地搭一个出来试试效果,结果百度一搜出来一大堆,然而自己去踩坑的没几个,绝大多数都是去抄的别人的内容,关键是实际应用中还会出错,浏览器 ...
- ELK-日志管理平台
elk日志收集工具 1.日志在工作当中的重要性 1 分析日志的意义: 2 1.分析日志监控系统运行的状态 3 2.分析日志来定位程序的bug 4 3.分析日志监控网站访问流量 ...
- 解决docker创建的elasticsearch-head容器不能连接elasticsearch等问题
在使用docker创建elasticsearch-head容器去连接elasticsearch的时候,容易出两个问题 1.不能连接elasticsearch 修改elasticsearch.yml文件 ...
- 关于bootstrap modal 垂直滚动条 每次打开后不置顶的问题
打开modal时,滚动条默认没有置顶. 查了很久,网上找了很多资料都没有解决. 经分析是需要在modal的消失事件中添加让滚动条置顶的方法.
- Chisel3 - model - 子模块,顶层模块
https://mp.weixin.qq.com/s/3uUIHW8DmisYARYmNzUZeg 介绍如何构建由模块组成的硬件模型. 1. 子模块 一个模块可以有一个或多个子模块,创建子 ...
- jchdl - RTL实例 - Adder
https://mp.weixin.qq.com/s/9S29BCTcJfbpR62ALjSidA 加法器. 参考链接 https://github.com/wjcdx/jchdl/blob/ ...
- 文件包含漏洞(file inclusion)
文件包含漏洞原理:(php) 是指当服务器开启allow_url_include选项的时候,通过php某些特性函数.如include().include_once().require().requir ...
- Java实现 蓝桥杯VIP 算法训练 数的划分
[题目描述] 将整数n分成k份,且每份不能为空,任意两份不能相同(不考虑顺序). 例如:n=7,k=3,下面三种分法被认为是相同的. 1,1,5: 1,5,1: 5,1,1: 问有多少种不同的分法. ...