深度学习中损失函数之RMS和MES
学校给我们一人赞助了100美元购买英文原版图书,几方打听后选择了PRML 即Pattern Recognition and Machine Learning。自从拆封这本书开始慢慢的品读,经常会有相见恨晚之感。虽然目前我只是慢慢地阅读了前几个小节,也知道后面的章节会越来越晦涩,但是还是下定决心一定要把这本书弄透彻。这篇文章是在阅读引章:曲线拟合时发现的问题。想记录下来学到的两个点,并对一道课后习题作解析。
第一节是曲线拟合,曲线拟合是深度学习问题中的regression问题,即回归问题。其他的问题据我了解还有classification问题,即分类问题和clustering问题,即聚类问题。regression问题很显然是一个有监督学习。给你一系列点x,再给你一系列这些点对应的target,我们的目标是找到一个函数使得target和我们预测的x之间的误差最小。
在这一节是以一个正弦函数为例,给出正弦曲线上加上了随机误差的一系列点。我们选择多项式拟合polynomial fitting:$$y(x,\textbf{w})=w_0+w_{1}x+w_{2}x^{2}+\cdots+w_{M}x^{M}=\sum_{j=0}^M w_j x^j$$
现在我们要解决的问题有三个:
1.什么叫误差?既然我们的目标是让误差最小,那么误差函数error function(或者是loss function?)应该长什么样?
2.有了误差函数,怎么样确定多项式的系数coefficients来使得误差函数最小。
3.多项式的次数order应该怎么选择?
下面一一进行解答:
1.首先我们选用了一类简单而且广泛被使用的error function--SSE,即和方差。我们的目标是最小化以下的目标error function(SSE):$$E(\textbf{w})=\frac{1}{2} \sum_{n=1}^{N} \left\{y(x_n ,\textbf{w})-t_n \right\}^2$$从直观上可以看到,这个损失函数是正定的,而且它的值越小,预测值和target值间的差距就越小,相应的,拟合效果就越好。其中$\frac{1}{2}$是为了方便计算,还可以选为其他值。我们的问题转化为了最小化误差函数。
2.已经交代过,我们采用多项式拟合,那么模型的参数就是多项式的系数$w_{0}~w_{M}$。怎样确定模型参数使得error function最小呢?这里的解法很特殊。我们使用的是最小平方误差,那么对误差函数关于多项式系数进行求导,得到的结果将是关于系数$\textbf{w}$的线性函数(我有一个理解,其实就是让loss对w向量求梯度,是不是呢?以后应该能回答)。为了求取极小值,在这里我们是可以让这个导数为$\textbf{0}$,从而获得解析形式的解$w^{*}$,(这里和之前模式识别课上学的那个什么伪逆解是不是有些关系?也是解析解)。具体细节在PRML中体现在课后习题,在后面讲。
3.现在我们能够对一个给定次数的多项式求出使error function最小的参数了,还没有解决的问题是,多项式的order应该如何选择?将这个问题推广就变成了一个模型选择的问题,使用更高次数的多项式一定能对样本点进行最好的拟合,进而获得最佳的泛化性能吗?下面的的几张图能够说明问题。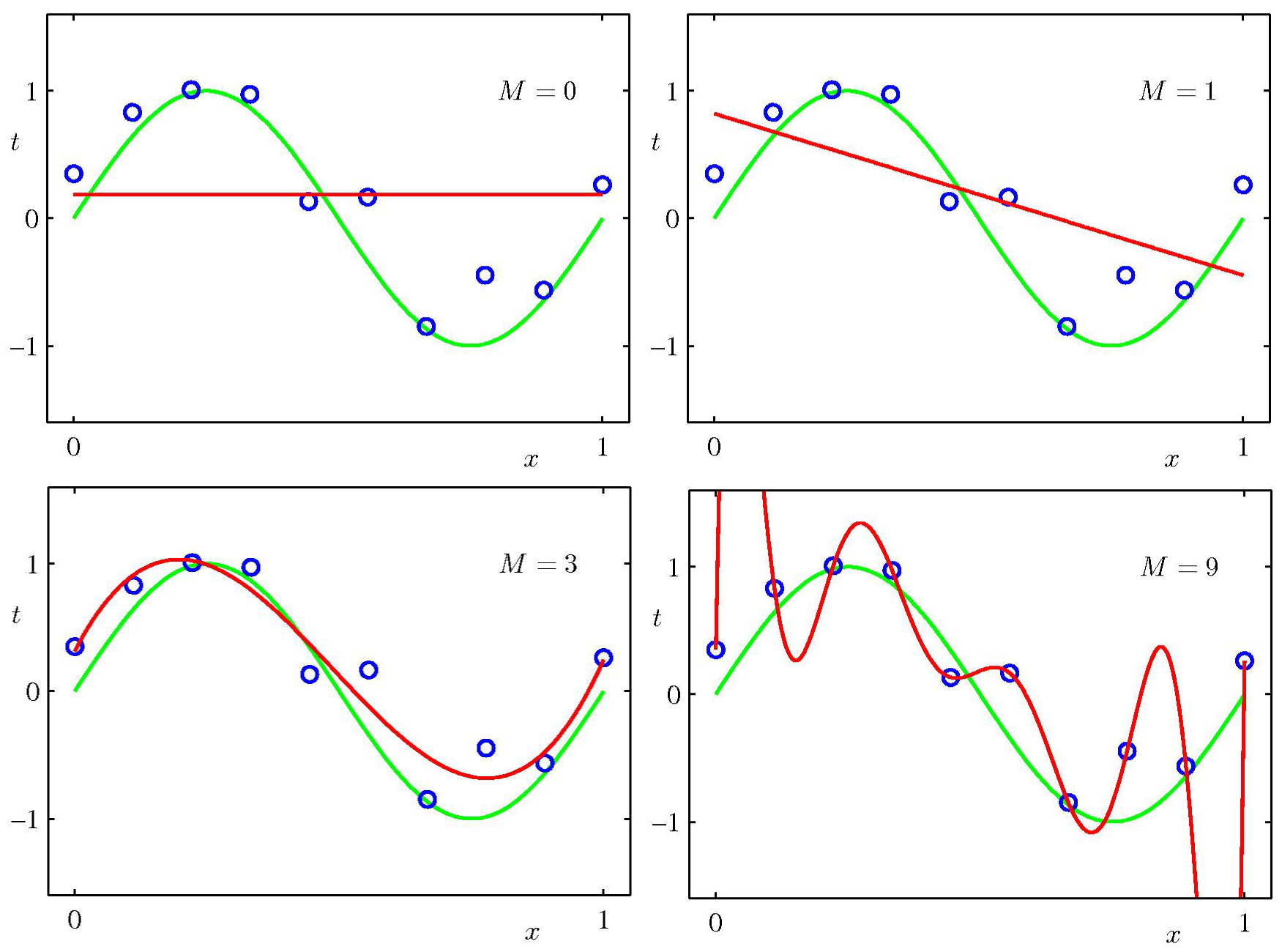
我们看到,当M比较小时,拟合效果很差,随着M增加(如M=3),能够进行较好的拟合。但是当M达到9时,因为对十个样本点,9次多项式能够唯一确定。拟合曲线却在样本点之间发生了剧烈的振荡,不能够获得很好的泛化性能。原因是出现了over-fitting过拟合。此时的曲线对随机的噪声非常敏感,且不具有任何的灵活性。当样本点增加后,这种过拟合现象得到了极大的缓解。此时为了让不同大小的数据集产生的误差函数的有相同的比例和单位。我们选用RMS error function:$$E_{RMS} = \sqrt{2E(\textbf{w* })/N}$$
深度学习中损失函数之RMS和MES的更多相关文章
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- Hebye 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- 深度学习中的batch、epoch、iteration的含义
深度学习的优化算法,说白了就是梯度下降.每次的参数更新有两种方式. 第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度.这种方法每更新一次参数都要把数据集里的所有样本都看一遍, ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
随机推荐
- Python_OpenCV学习记录01安装
Python照样快! 众所周知,虽然Python语法简洁,编写高效,但相比C/C++运行慢很多.然 而Python还有个重要的特性:它是一门胶水语言!Python可以很容易地扩展 C/C++.Open ...
- SQL——AUTO INCREMENT(字段自增)
AUTO INCREMENT -- 在新记录插入表中时生成一个唯一的数字.插入表数据时,该字段不需规定值. 在每次插入新记录时,自动地创建主键字段的值.在表中创建一个 auto-incremen ...
- 3.Linux如何管理分区
上一次谈完了硬盘与分区的基础知识,下面谈一下Linux如何管理分区. Linux管理硬件和windows完全不同.任何东西(包括硬件)在Linux看来都是文件设备,有字符和二进制形式的设备.如打印机. ...
- 线程的同步机制:同步代码块&同步方法
解决存在的线程安全问题:打印车票时出现重票,错票 使用同步代码块的解决方案 TestWindow2 package com.aff.thread; /* 使用实现Runnable接口的方式,售票 存在 ...
- 【译】Gartner CWPP市场指南
https://www.gartner.com/doc/reprints?id=1-1YSHGBQ8&ct=200416&st=sb?utm_source=marketo&ut ...
- Unity 游戏框架搭建 2019 (五十六/五十七) 需求分析-架构中最重要的一环&从 EmptyGO 到 Manager Of Managers
我们的项目开始立项的时候,最常见的一个情况就是:几个人的小团队,一开始什么也不做,就开始写代码,验证逻辑,游戏就开始写起来了.而公司的一些所谓的领导层面一开始就把游戏定义为我们要做一个大作.这个事情本 ...
- Rocket - decode - 解码单个信号
https://mp.weixin.qq.com/s/0D_NaeBEZX5LBQRdCz2seQ 介绍解码单个信号逻辑的实现. 1. 单个信号 每个指令对应了一组信号,每个信号对应 ...
- Mysql查询语句,select,inner/left/right join on,group by.....[例题及答案]
创建如下表格,命名为stu_info, course_i, score_table. 题目: 有如图所示的三张表结构,学生信息表(stu_info),课程信息表(course_i),分数信息表(sco ...
- 核心记账业务可用jdk7的PriorityBlockingQueue优先阻塞队列结合乐观锁实现
-- 1.优先级阻塞队列 当前核心记账业务是悲观锁实现,但考虑到高并发和死锁的问题,可以用PriorityBlockingQueue优先阻塞队列结合乐观锁实现,对于并发时出现锁无法update时可以重 ...
- Java实现 LeetCode 815 公交路线(创建关系+BFS)
815. 公交路线 我们有一系列公交路线.每一条路线 routes[i] 上都有一辆公交车在上面循环行驶.例如,有一条路线 routes[0] = [1, 5, 7],表示第一辆 (下标为0) 公交车 ...