Golang校招简历项目-简单的分布式缓存
前言
前段时间,校招投了golang岗位,但是没什么好的项目往简历上写,于是参考了许多网上资料,做了一个简单的分布式缓存项目。
现在闲下来了,打算整理下。
github项目地址:https://github.com/Jun10ng/Gache
里面还有我整理的一些面试问题,给颗星吧。
typora-root-url: ./
Golang校招面试项目-类redis分布式缓存
实现一个分布式缓存,功能有:LRU淘汰策略,http调用,并发缓存,一致性哈希,分布式节点,防止缓存击穿
实现LRU淘汰策略
LRU的数据结构大致如下,上层是一个map,key是数据对象的key值,而value值则是指向 下层双向链表的节点,在双向链表中,每个节点存储的元素是完整的数据对象,包含key值和value。
- get:存在->将元素所在节点提到最前面,不存在->返回失败
- add:存在->更新,不存在->增加;将元素所在节点提到最前面,判断是否大于
maxSize - removeOldest:删除链表最后方的节点

代码实现
具体代码实现看:https://github.com/Jun10ng/Gache/tree/master/lru
定义了三个数据结构
Value是golang中的接口类型,可以理解为java中的Object类,是一个能“兜底”所有数据结构的数据类型。
entry是一个双向链表存储的数据结构
Cache则是lru核心数据结构,包含一个哈希表和一个双向链表
type Value interface {
//返回占用的内存大小
Len() int
}
type entry struct {
key string
value Value
}
type Cache struct {
//允许使用的最大内存
maxBytes int64
//当前已使用的内存
nbytes int64
ll *list.List
cache map[string] *list.Element
//某条记录被移除时的回调函数,可以是nil
OnEvicted func(key string, value Value)
}
这里说一下OnEvicted成员,这是一个函数对象,他的作用是,在缓存中没有需要的数据对象时,我们需要去原始数据源获取,(redis中没有,就需要去数据库中获取),但是数据源不唯一,有时候是数据库,有时候是磁盘,有时候是表格,他们的获取方式都不相同,所以OnEvicted成员传入的函数,就是自定义的获取方法。
实现单机并发
具体代码实现:https://github.com/Jun10ng/Gache/blob/master/cache.go
上文实现的LRU数据结构并不支持并发,需要加锁来实现并发,所以使用sync.Mutex,在LRU数据结构上封装,使之实现并发功能。
type cache struct {
mu sync.Mutex
lru *lru.Cache
cacheBytes int64
}
cache并没有new方法,因为采用的是延迟初始化 在add方法中,判断c.lru是否为nil,如果等于nil再创建 这种方法称为延迟初始化,一个对象的延迟初始化意味着该对象的 创建将会延迟至第一次使用该对象时。 这个方法在redis中很常见,因为能一定程度上提高性能
func (c *cache) add(key string, value ByteView){
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil{
c.lru = lru.New(c.cacheBytes,nil)
}
c.lru.Add(key,value)
}
主体结构
具体代码实现:https://github.com/Jun10ng/Gache/blob/master/gache.go
本质上是再进行一次封装
难道一台机器就只有一个缓存表吗?你打开redis的可视化工具,能看到redis还有16个池呢,所以我们要实现多个缓存表。怎么做?再加一层。试想一下:
//groups 实例集合表
groups = make(map[string]*Group)
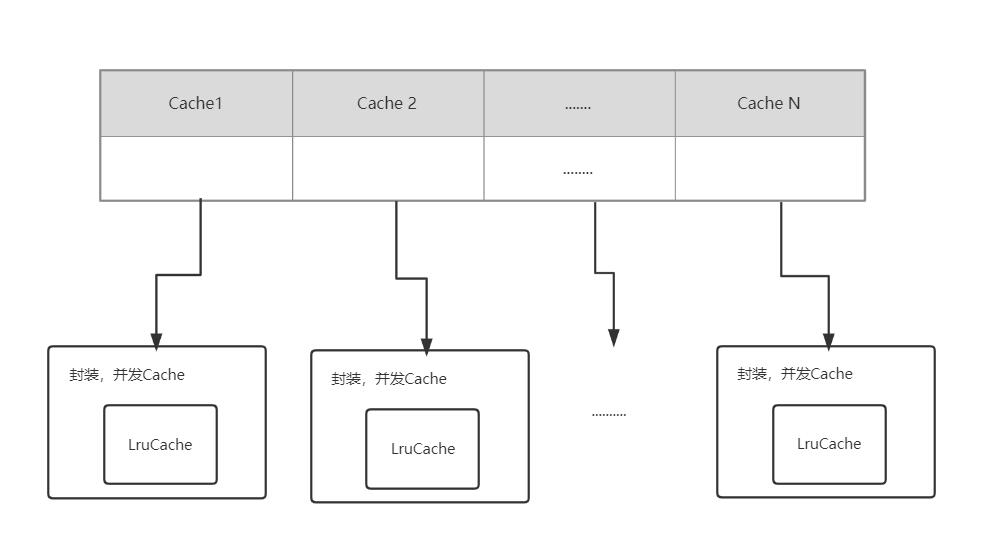
我们要实现的数据结构大致是这样的,是一个存储并发cache的表,这是本项目的核心结构
//这里的group是实例
type Group struct {
name string
getter Getter
mainCache cache
}
http服务调用
具体代码实现:https://github.com/Jun10ng/Gache/blob/master/http.go
当请求URL具有前缀/_Gache/时,则认为该请求为缓存调用。
约定的请求URL为:http://XXX.com/_Gache/<groupname>/<key>
groupname字段为主体结构中groups中的某个元素的name值,由此调用。key字段为元素中的元素的key值,所以最后逻辑为
groups[groupname][key]
一致性哈希
一致性哈希抽象的解释就是一个很大的环,但是在实现的时候,我们总不可能声明一个有个成千链表节点的环吧,何况其中大多节点还是闲置节点,没有实际的作用,所以我们需要在逻辑上去声明哈希环。
代码实现:https://github.com/Jun10ng/Gache/blob/master/consistent/consistentHash.go
数据结构
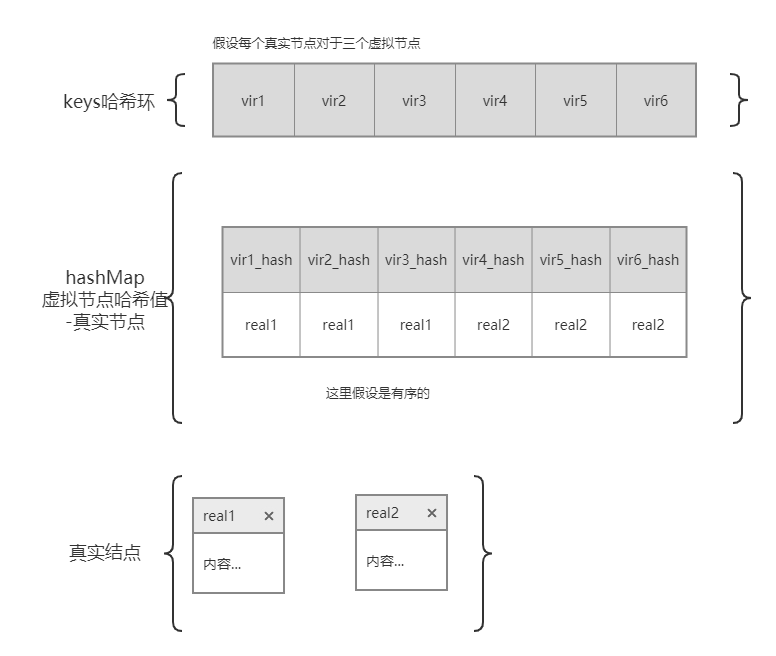
(真实节点就是指机器,虚拟节点相反)
type Map struct {
hash Hash
virMpl int
keys []int
hashMap map[int]string
}
hash是函数变量virMpl是虚拟节点的倍数keys是存放节点哈希值的有序数组- hashMap中存放的是虚拟节点和真实节点的对映,之所以是
[int]string类型,是因为key是虚拟节点的哈希值,value是真实节点
添加真实节点
代码注释写的很详细了,就不多说了。
缺点是,当有一个真实节点添加进来的时候,所有值都要重新计算一遍。这在并发情况下,会造成一定拥塞。因为在重新计算期间,不能进行正确的访问操作。
欢迎提供解决思路。
func (m* Map) Add(keys ...string){
for _,realNodeKey:=range keys{
for i:=0;i<m.virMpl;i++{
/*
keys中的每个真实节点都对映着virMpl个虚拟节点
每个虚拟节点的key(即virNodeKey)为 i+realNodekey
(即一个“不定数”,这里用i值,加上真实节点key
*/
virNodeKey := []byte(strconv.Itoa(i)+realNodeKey)
/*
对虚拟节点做哈希
*/
virNodeHash:= int(m.hash(virNodeKey))
/*
添加进哈希环,所以虚拟节点也存在于哈希环中
*/
m.keys = append(m.keys,virNodeHash)
/*
虚拟节点的hash对映某个真实节点的key
*/
m.hashMap[virNodeHash] = realNodeKey
}
}
sort.Ints(m.keys)
}
访问真实节点
也就是get函数
分为三个步骤
- 计算出虚拟节点的哈希值
virNodeHash - 在
keys数组中找到大于等于virNodeHash的值,返回其下标index,则对应的节点为keys[index] - 通过下标在
hashMap中找到keys[index]的真实节点
自己试着写下get函数,会对整个逻辑更清晰。
分布式节点设计
这一章涉及的东西有点多,在代码中给出了详细的注释,
主要是下面几个文件:
https://github.com/Jun10ng/Gache/blob/master/peer.go
定义了两个抽象接口,用于远程节点的获取
https://github.com/Jun10ng/Gache/blob/master/http.go
实现了peer.go中的两个接口,并定义了新的结构体httpGetter用于获取远程节点缓存数据
https://github.com/Jun10ng/Gache/blob/master/gache.go
集成了一致性哈希表,使用http访问各个节点
主要参考资料:https://geektutu.com/post/geecache.html
Golang校招简历项目-简单的分布式缓存的更多相关文章
- .NetCore实现简单的分布式缓存
分布式缓存能够处理大量的动态数据,因此比较适合应用在Web 2.0时代中的社交网站等需要由用户生成内容的场景.从本地缓存扩展到分布式缓存后,关注重点从CPU.内存.缓存之间的数据传输速度差异也扩展到了 ...
- 我发起了一个 .Net Core 平台上的 分布式缓存 开源项目 ShareMemory 用于 取代 Redis
Redis 的 安装 是 复杂 的, 使用 是 复杂 的, Redis 的 功能 是 重型 的, Redis 本身的 技术实现 是 复杂 的 . Redis 是用 C 写的, C 语言 编写的代码需要 ...
- ASP.Net Core使用分布式缓存Redis从入门到实战演练
一.课程介绍 人生苦短,我用.NET Core!缓存在很多情况下需要用到,合理利用缓存可以一方面可以提高程序的响应速度,同时可以减少对特定资源访问的压力. 所以经常要用到且不会频繁改变且被用户共享的 ...
- 企业项目开发--分布式缓存Redis
第九章 企业项目开发--分布式缓存Redis(1) 注意:本章代码将会建立在上一章的代码基础上,上一章链接<第八章 企业项目开发--分布式缓存memcached> 1.为什么用Redis ...
- 第九章 企业项目开发--分布式缓存Redis(1)
注意:本章代码将会建立在上一章的代码基础上,上一章链接<第八章 企业项目开发--分布式缓存memcached> 1.为什么用Redis 1.1.为什么用分布式缓存(或者说本地缓存存在的问题 ...
- 第八章 企业项目开发--分布式缓存memcached
注意:本节代码基于<第七章 企业项目开发--本地缓存guava cache> 1.本地缓存的问题 本地缓存速度一开始高于分布式缓存,但是随着其缓存数量的增加,所占内存越来越大,系统运行内存 ...
- golang实现分布式缓存笔记(一)基于http的缓存服务
目录 前言 cache 缓存服务接口 cache包实现 golang http包使用介绍 hello.go Redirect.go http-cache-server 实现 cacheHandler ...
- 【开源项目系列】如何基于 Spring Cache 实现多级缓存(同时整合本地缓存 Ehcache 和分布式缓存 Redis)
一.缓存 当系统的并发量上来了,如果我们频繁地去访问数据库,那么会使数据库的压力不断增大,在高峰时甚至可以出现数据库崩溃的现象.所以一般我们会使用缓存来解决这个数据库并发访问问题,用户访问进来,会先从 ...
- 第十章 企业项目开发--分布式缓存Redis(2)
注意:本章代码是在上一章的基础上进行添加修改,上一章链接<第九章 企业项目开发--分布式缓存Redis(1)> 上一章说了ShardedJedisPool的创建过程,以及redis五种数据 ...
随机推荐
- PhalApi 2.7 开发快速上手
PhalApi是一款国人制作的PHP纯后端框架.它的开发相当简单,同时也具备文档生成等特色功能.下面,我通过简单的几点,让你可以快速入门使用该框架的开发. 建议使用PHPStorm作为IDE,代码提示 ...
- Hexo+github如何搭建博客
前言 博客有第三方平台,也可以自建,比较早的有博客园.CSDN,近几年新兴的也比较多诸如:WordPress.segmentFault.简书.掘金.知乎专栏.Github Page 等等. 这次我要说 ...
- 【Spring Data 系列学习】Spring Data JPA 基础查询
[Spring Data 系列学习]Spring Data JPA 基础查询 前面的章节简单讲解了 了解 Spring Data JPA . Jpa 和 Hibernate,本章节开始通过案例上手 S ...
- 服务器推送 SSE 了解一下?
hello~亲爱的看官老爷们大家好~过完年第一周已经结束,是时候开始制定新的工作计划了.主要负责的项目是数据可视化平台,而使用中如果服务器能有推送能力让页端得到相关通知的话,就能实现很多功能上的优化. ...
- 一份简明的 Base64 原理解析
书接上回,在 记一个 Base64 有关的 Bug 一文里,我们说到了 Base64 的编解码器有不同实现,交叉使用它们可能引发的问题等等. 这一回,我们来对 Base64 这一常用编解码技术的原理一 ...
- IDEA 配置自定义Apache与PHP环境
1. PHP环境 1.1 插件的安装 1.2 关于php环境的配置 2.关于apache的配置 至此,已经配置成功啦,愉快的学习吧!
- python之嵌套 闭包 装饰器 global、nonlocal关键字
嵌套: 在函数的内部定义函数闭包: 符合开放封闭原则:在不修改源代码与调用方式的情况下为函数添加新功能 # global 将局部变量变成全局变量 num = 100 def fn1(): globa ...
- Flink消费Kafka到HDFS实现及详解
1.概述 最近有同学留言咨询,Flink消费Kafka的一些问题,今天笔者将用一个小案例来为大家介绍如何将Kafka中的数据,通过Flink任务来消费并存储到HDFS上. 2.内容 这里举个消费Kaf ...
- CouchDB的简单使用
一.安装CouchDB 到官网下载CouchDB,在windows下安装CouchDB较为简单,略过. 安装完后,确认CouchDB在运行,然后在浏览器访问http://127.0.0.1:5984/ ...
- python对接elasticsearch的基本操作
基本操作 #!/usr/bin/env python # -*- coding: utf-8 -*- # author tom from elasticsearch import Elasticsea ...