day61-mysql-索引原理和慢查询优化
ProgramData是C盘隐藏的文件夹,mysql的data文件夹在里面,C:\ProgramData\MySQL\MySQL Server 8.0\Data
一、存储引擎
重点[面试题]: innodb与MyISAM存储引擎的区别:
1.innodb 是mysql5.5版本以后的默认存储引擎, 而MyISAM是5.5版本以前的默认存储引擎.
2.innodb 支持事物,而MyISAM不支持事物
3.innodb 支持行级锁.而MyIASM 它支持的是并发的表级锁.
4.innodb 支持外键, 而MyIASM 不支持外键
5.innodb与MyIASM存储引擎都采用B+TREE存储数据, 但是innodb的索引与数据存储在一个文件中,这种方式我们称之为聚合索引.
而MyIASM则会单独创建一个索引文件,也就是说,数据与索引是分离开的
6.在效率方面MyISAM比innodb高,但是在性能方面innodb要好一点. 创建三个表,分别使用innodb,myisam,memory 存储引擎,进行插入数据测试
create table t1(id int)engine=innodb;--如果不写上存储引擎,默认是innodb。
create table t2(id int)engine=myisam;
create table t3(id int)engine=memory; #看一下三个存储引擎创建的 表文件
t1.frm t1.ibd
t2.MYD t2.MYI t2.frm
t3.frm
#细心的同学会发现最后的存储引擎只有表结构,无数据
#memory,在重启mysql或者重启机器后,表内数据清空 停止mysql的方法:cmd--net stop mysql 或者 任务管理器--服务--打开服务--mysql--停止此服务
开始mysql的方法:cmd--net start mysql 或者 任务管理器--服务--打开服务--mysql--重启此服务 二、索引: 本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果--缩小范围,筛选结果。
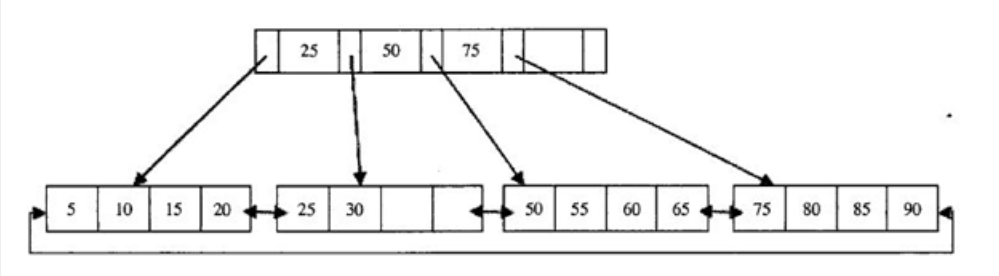
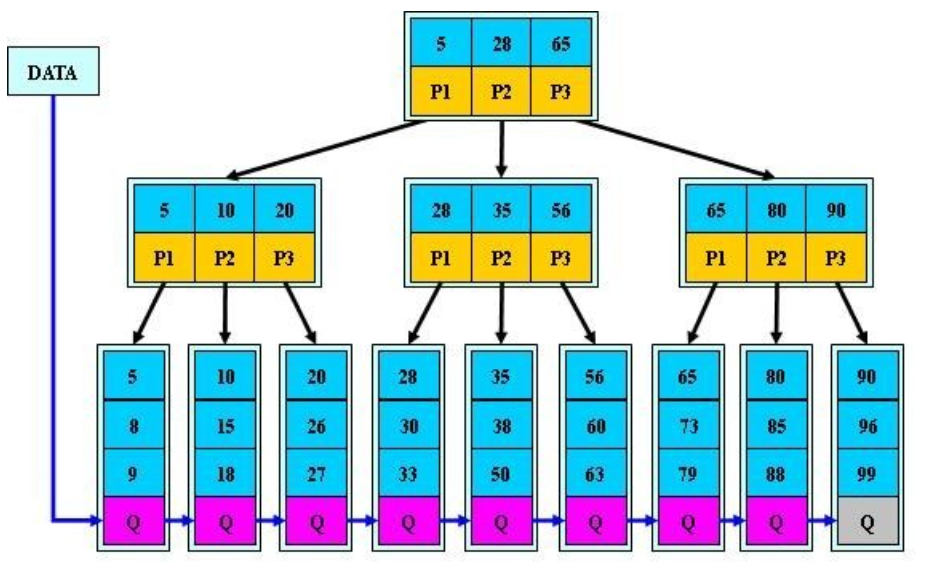
1.索引方法:B+TREE 索引 和 HASH 索引
注意:通常其高度都在2~3层,查询时可以有效减少IO次数。强烈注意: 索引字段要尽量的小,磁盘块可以存储更多的索引.
B+TREE 索引:
2.常见四种索引:
2.1.普通索引 加速查询
创建:--创建表的时候创建索引:
create table t1(
id int not null,
name varchar(50), --不写not null就默认是null
index idx_id (id) --index替换成key也是同样的效果, idx_id是索引名(key_name)
)
通过命令创建--有了表再创建索引:
CREATE index idx_name on t1(name);--on是指定某个表的某个字段
查看索引
show index from t1;
删除索引
drop index idx_id on t1; 2.2.唯一索引 加速查询 和 唯一约束(可含一个null 值),只需要在普通索引前面加unique
create table t2(
id int not null auto_increment primary key,
name varchar(50) not null,
age int not null,
unique index idx_age (age)
)
通过命令创建--有了表再创建唯一索引:
create unique index idx_age on t2(age);
查看索引
show index from t2;
删除索引
drop index idx_id on t2;
所有查看和删除索引的方法都一样的,除了主键索引。 2.3.主键索引 加速查询 和 唯一约束(不可含null),主键索引的索引名默认是PRIMARY,不能写其他索引名。注意:一个表中最多只能有一个主键索引。
create table t3(
id int not null,
name varchar(50),
primary key(id,name)--给id和name添加主键索引
); alter table t3 add primary key(id); alter table t3 drop primary key;--可同时删除id和name的主键索引。如果想只删除id的索引不删name的索引,代码不知怎样写,但是
通过navicat可以操作。 2.4.组合索引
create unique index idx_age_name on t2(age,name); 3. 聚合索引和辅助索引
总结二者区别:
相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
不同的是:聚集索引叶子结点存放的是一整行的信息,而辅助索引叶子结点存放的是单个索引列信息. 4.引擎修改为myisam的方法:
-- 4.1.创建表
CREATE TABLE userInfo(
id int NOT NULL,
name VARCHAR(16) DEFAULT NULL,
age int,
sex char(1) not null,
email varchar(64) default null
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
注意:MYISAM存储引擎 不产生引擎事务,数据插入速度极快,为方便快速插入测试数据,等我们插完数据,再把存储类型修改为InnoDB
ALTER TABLE userinfo ENGINE=INNODB; 5.正确使用索引
#1. 范围查询(>、>=、<、<=、!= 、between...and)
#1. = 等号
select count(*) from userinfo where id = 1000 -- 执行索引,索引效率高 #2. > >= < <= between...and 区间查询
select count(*) from userinfo where id <100; -- 执行索引,区间范围越小,索引效率越高 select count(*) from userinfo where id >100; -- 执行索引,区间范围越大,索引效率越低 select count(*) from userinfo where id between 10 and 500000; -- 执行索引,区间范围越大,索引效率越低 #3. != 不等于
select count(*) from userinfo where id != 1000; -- 索引范围大,索引效率低 #2.like '%xx%'
#为 name 字段添加索引
create index idx_name on userinfo(name); select count(*) from userinfo where name like '%xxxx%'; -- 全模糊查询,索引效率低
select count(*) from userinfo where name like '%xxxx'; -- 以什么结尾模糊查询,索引效率低 #例外: 当like使用以什么开头会索引使用率高
select * from userinfo where name like 'xxxx%'; #3. or
select count(*) from userinfo where id = 12334 or email ='xxxx'; -- email不是索引字段,索引此查询全表扫描 #例外:当or条件中有未建立索引的列才失效,以下会走索引
select count(*) from userinfo where id = 12334 or name = 'alex3'; -- id 和 name 都为索引字段时, or条件也会执行索引 #4.使用函数
select count(*) from userinfo where reverse(name) = '5xela'; -- name索引字段,使用函数时,索引失效 #例外:索引字段对应的值可以使用函数,我们可以改为一下形式
select count(*) from userinfo where name = reverse('5xela'); #5.类型不一致
#如果列是字符串类型,传入条件是必须用引号引起来,不然...
select count(*) from userinfo where name = 454;--索引效率低 #类型一致
select count(*) from userinfo where name = '';--索引效率高 #6.order by
#排序条件为索引,则select字段必须也是索引字段,否则无法命中
select email from userinfo ORDER BY name DESC; -- 无法命中索引 select name from userinfo ORDER BY name DESC; -- 命中索引 #特别的:如果对主键排序,则还是速度很快:
select id from userinfo order by id desc; 6.组合索引 组合索引: 是指对表上的多个列组合起来做一个索引. 最左匹配原则: 从左往右依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用; select * from mytable where a=3 and b=5 and c=4;
#abc三个索引都在where条件里面用到了,而且都发挥了作用 select * from mytable where c=4 and b=6 and a=3;
#这条语句列出来只想说明 mysql没有那么笨,where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样 select * from mytable where a=3 and c=7;
#a用到索引,b没有用,所以c是没有用到索引效果的 select * from mytable where a=3 and b>7 and c=3;
#a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引 select * from mytable where b=3 and c=4;
#因为a索引没有使用,所以这里 bc都没有用上索引效果 select * from mytable where a>4 and b=7 and c=9;
#a用到了 b没有使用,c没有使用 select * from mytable where a=3 order by b;
#a用到了索引,b在结果排序中也用到了索引的效果 select * from mytable where a=3 order by c;
#a用到了索引,但是这个地方c没有发挥排序效果,因为中间断点了 select * from mytable where b=3 order by a;
#b没有用到索引,排序中a也没有发挥索引效果 7.注意事项
1. 避免使用select *
2. 其他数据库中使用count(1)或count(列) 代替 count(*),而mysql数据库中count(*)经过优化后,效率与前两种基本一样.
3. 创建表时尽量时 char 代替 varchar
4. 表的字段顺序固定长度的字段优先
5. 组合索引代替多个单列索引(经常使用多个条件查询时)
6. 使用连接(JOIN)来代替子查询(Sub-Queries)
7. 不要有超过4个以上的表连接(JOIN)
8. 优先执行那些能够大量减少结果的连接。
9. 连表时注意条件类型需一致
10.索引散列值不适合建索引,例:性别不适合 8.查询计划
预估查询的结果,不太精准
type : 查询计划的连接类型, 有多个参数,先从最佳类型到最差类型介绍 性能: null > system/const > eq_ref > ref > ref_or_null > index_merge > range > index > all 9.慢日志查询
将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件,
通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。 #.查询慢日志配置信息 :
show variables like '%query%';
#.修改配置信息
set global slow_query_log = on; # 显示参数
show variables like '%log_queries_not_using_indexes';
# 开启状态
set global log_queries_not_using_indexes = on; #查看慢日志记录的方式
show variables like '%log_output%'; #设置慢日志在文件和表中同时记录
set global log_output='FILE,TABLE'; #查询时间超过10秒就会记录到慢查询日志中
select sleep(3) FROM user ; #查看表中的日志
select * from mysql.slow_log; 11.大数据量分页优化(面试可能遇到)
执行此段代码:
1
select * from userinfo limit 3000000,10;
优化方案:
一. 简单粗暴,就是不允许查看这么靠后的数据,比如百度就是这样的最多翻到72页就不让你翻了,这种方式就是从业务上解决; 二.在查询下一页时把上一页的行id作为参数传递给客户端程序,然后sql就改成了
1
select * from userinfo where id>3000000 limit 10;
这条语句执行也是在毫秒级完成的,id>300w其实就是让mysql直接跳到这里了,不用依次在扫描全面所有的行
如果你的table的主键id是自增的,并且中间没有删除和断点,那么还有一种方式,比如100页的10条数据
1
select * from userinfo where id>100*10 limit 10;
三.最后第三种方法:延迟关联
我们在来分析一下这条语句为什么慢,慢在哪里。
1
select * from userinfo limit 3000000,10;
玄机就处在这个 * 里面,这个表除了id主键肯定还有其他字段 比如 name age 之类的,因为select * 所以mysql在沿着id主键走的时候要回行拿数据,走一下拿一下数据;
如果把语句改成
1
select id from userinfo limit 3000000,10;
你会发现时间缩短了一半;然后我们在拿id分别去取10条数据就行了;
语句就改成这样了:
1
select table.* from userinfo inner join ( select id from userinfo limit 3000000,10 ) as tmp on tmp.id=userinfo.id;
这三种方法最先考虑第一种 其次第二种,第三种是别无选择
day61-mysql-索引原理和慢查询优化的更多相关文章
- MySQL索引原理及慢查询优化-来自美团网的技术blog(写的深入浅出)
MySQL索引原理及慢查询优化 转:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首 ...
- day--41 mysql索引原理与慢查询优化
mysql索引原理与慢查询优化一:什么是索引 01:索引的出现是为了提高查询数据的效率 02:索引在mysql叫做“键” 或则“key“(primary key,uniquekey ,还有一个inde ...
- python 3 mysql 索引原理与慢查询优化
python 3 mysql 索引原理与慢查询优化 一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最 ...
- MySQL 索引原理以及慢查询优化
本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL索引原理与慢查询优化
索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才 ...
随机推荐
- VIJOS-P1282 佳佳的魔法照片 排序
Description 一共有n(n≤20000)个人(以1--n编号)向佳佳要照片,而佳佳只能把照片给其中的k个人.佳佳按照与他们的关系好坏的程度给每个人赋予了一个初始权值W[i].然后将初始权值从 ...
- flink笔记(三) flink架构及运行方式
架构图 Job Managers, Task Managers, Clients JobManager(Master) 用于协调分布式执行.它们用来调度task,协调检查点,协调失败时恢复等. Fli ...
- Spark 内存管理
Spark 内存管理 Spark 执行应用程序时, 会启动 Driver 和 Executor 两种 JVM 进程 Driver 负责创建 SparkContext 上下文, 提交任务, task的分 ...
- 实验吧-隐写术-黑与白(二)(反转+五笔+Image steganography)
反转有二:颜色反转.文件名反转 文件名这么乱,毫无规律,好奇怪,进行反转后发现是:steganography(就是隐写术的意思),这还是个图片文件,有一款工具正好叫Image steganograph ...
- mysql 事务使用教程
一.什么是事务 事务Transaction,是指作为一个基本工作单元执行的一系列SQL语句的操作,要么完全地执行,要么完全地都不执行. 二.事务的特性 原子性 事务是一 ...
- md5sum|zip|
##move## ;i<=;i++));do cp combine_all.split_$i split_$i;done ##gzip## mkdir gzip/workshell ;i< ...
- UVA - 120 Stacks of Flapjacks(煎饼)
题意:一叠煎饼,每个煎饼都有一个数字,每次可以选择一个数k,把从锅底开始数第k张以及其上面的煎饼全部翻过来,最终使煎饼有序排列(锅顶最小,锅底最大). 分析:依次从锅底向上,优先排数字最大的煎饼.每次 ...
- 干货分享|Law Essay写作高分攻略
很多法学院的留学生对于Law Essay写作不是特别擅长,理论知识都了解,但是写出来的essay分数就是不高.同学们要从哪些方面入手呢?Law Essay写作要怎么拿高分?具体就跟小编一起来看看吧! ...
- 吴裕雄--天生自然TensorFlow2教程:填充与复制
import tensorflow as tf a = tf.reshape(tf.range(9), [3, 3]) a tf.pad(a, [[0, 0], [0, 0]]) tf.pad(a, ...
- C++ DirectShow读取摄像头后然后保存图像数据
#include <stdio.h> #include "camerads.h" #include <highgui.h> const char *g_sz ...