python实现进程的三种方式及其区别
1.fork()方法
- ret = os.fork()
- if ret == 0:
- #子进程
- else:
- #父进程
这是python中实现进程最底层的方法,其他两种从根本上也是利用fork()方法来实现的,下面是fork()方法的原理示意图
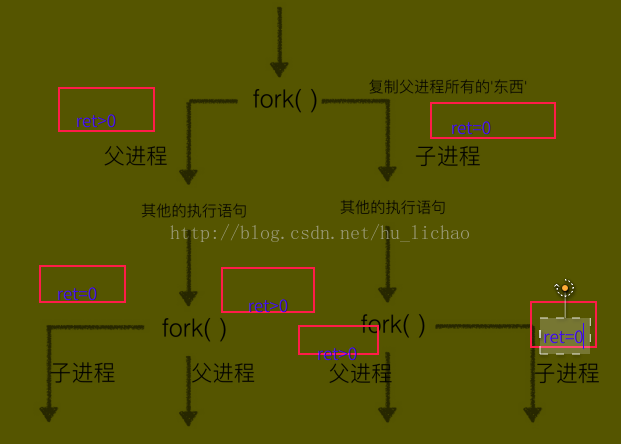
- import os
- rpid = os.fork()
- if rpid<0:
- print("fork调⽤失败。 ")
- elif rpid == 0:
- print("我是⼦进程( %s) , 我的⽗进程是(%s) "%(os.getpid(),os.getppid()))
- x+=1
- else:
- print("我是⽗进程( %s) , 我的⼦进程是( %s) "%(os.getpid(),rpid))
- print("⽗⼦进程都可以执⾏这⾥的代码")
运行结果:
- 我是⽗进程( 19360) , 我的⼦进程是( 19361)
- ⽗⼦进程都可以执⾏这⾥的代码
- 我是⼦进程( 19361) , 我的⽗进程是( 19360)
- ⽗⼦进程都可以执⾏这⾥的代码
- #coding=utf-8
- import os
- import time
- num = 0
- # 注意, fork函数, 只在Unix/Linux/Mac上运⾏, windows不可以
- pid = os.fork()
- if pid == 0:
- num+=1
- print('哈哈1---num=%d'%num)
- else:
- time.sleep(1)
- num+=1
- print('哈哈2---num=%d'%num)
运行结果
- 哈哈1---num=1
- 哈哈2---num=1
- #多进程不共享全局变量
多次fork()问题
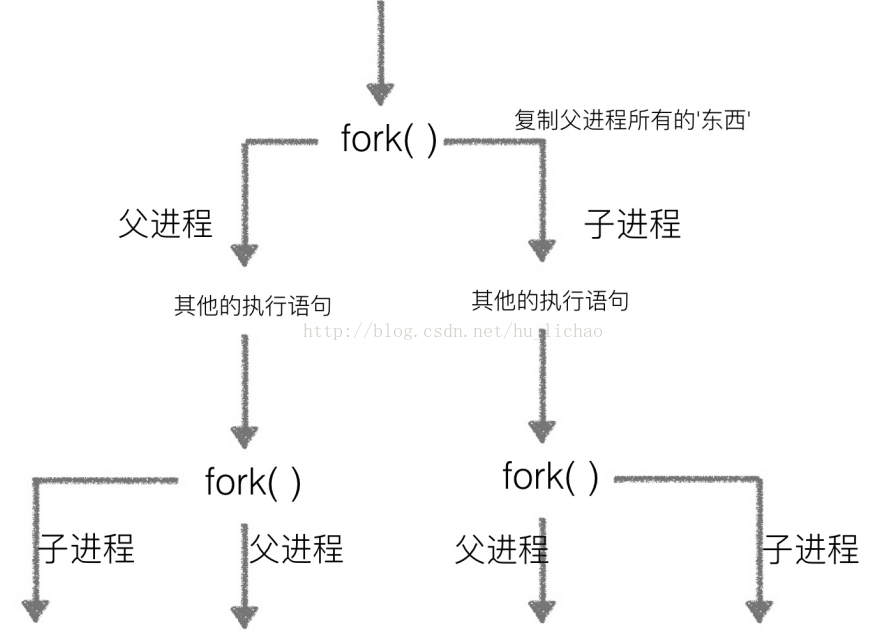
2,Process方法
- from multiprocessing import Process
- p1=Process(target=xxxx)
- p1.start()
- #coding=utf-8
- from multiprocessing import Process
- import os
- # ⼦进程要执⾏的代码
- def run_proc(name):
- print('⼦进程运⾏中, name= %s ,pid=%d...' % (name, os.getpid()))
- if __name__=='__main__':
- print('⽗进程 %d.' % os.getpid())
- p = Process(target=run_proc, args=('test',))
- print('⼦进程将要执⾏')
- p.start()
- p.join()
- print('⼦进程已结束')
- ⽗进程 4857.
- ⼦进程将要执⾏
- ⼦进程运⾏中, name= test ,pid=4858...
- ⼦进程已结束
is_alive(): 判断进程实例是否还在执⾏;
join([timeout]): 是否等待进程实例执⾏结束, 或等待多少秒;
start(): 启动进程实例( 创建⼦进程) ;
run(): 如果没有给定target参数, 对这个对象调⽤start()⽅法时, 就将执⾏对象中的run()⽅法;
terminate(): 不管任务是否完成, ⽴即终⽌;
3,利用进程池Pool
- from multiprocessing import Pool
- pool=Pool(3)
- pool.apply_async(xxxx)
- from multiprocessing import Pool
- import os,time,random
- def worker(msg):
- t_start = time.time()
- print("%s开始执⾏,进程号为%d"%(msg,os.getpid()))
- #random.random()随机⽣成0~1之间的浮点数
- time.sleep(random.random()*2)
- t_stop = time.time()
- print(msg,"执⾏完毕, 耗时%0.2f"%(t_stop-t_start))
- po=Pool(3) #定义⼀个进程池, 最⼤进程数3
- for i in range(0,10):
- #Pool.apply_async(要调⽤的⽬标,(传递给⽬标的参数元祖,))
- #每次循环将会⽤空闲出来的⼦进程去调⽤⽬标
- po.apply_async(worker,(i,))
- print("----start----")
- po.close() #关闭进程池, 关闭后po不再接收新的请求
- po.join() #等待po中所有⼦进程执⾏完成, 必须放在close语句之后
- print("-----end-----")
运行结果
- ----start----
- ----start----
- 0开始执⾏,进程号为5025
- ----start----
- 1开始执⾏,进程号为5026
- ----start----
- ----start----
- ----start----
- ----start----
- ----start----
- ----start----
- ----start----
- 2开始执⾏,进程号为5027
- 0 执⾏完毕, 耗时0.58
- 3开始执⾏,进程号为5025
- 1 执⾏完毕, 耗时0.70
- 4开始执⾏,进程号为5026
- 2 执⾏完毕, 耗时1.36
- 5开始执⾏,进程号为5027
- 3 执⾏完毕, 耗时1.03
- 6开始执⾏,进程号为5025
- 4 执⾏完毕, 耗时1.12
- 7开始执⾏,进程号为5026
- 5 执⾏完毕, 耗时1.25
- 8开始执⾏,进程号为5027
- 7 执⾏完毕, 耗时1.28
- 9开始执⾏,进程号为5026
- 6 执⾏完毕, 耗时1.91
- 8 执⾏完毕, 耗时1.23
- 9 执⾏完毕, 耗时1.38
- -----end-----
- from multiprocessing import Pool
- import os,time,random
- def worker(msg):
- t_start = time.time()
- print("%s开始执⾏,进程号为%d"%(msg,os.getpid()))
- #random.random()随机⽣成0~1之间的浮点数
- time.sleep(random.random()*2)
- t_stop = time.time()
- print(msg,"执⾏完毕, 耗时%0.2f"%(t_stop-t_start))
- po=Pool(3) #定义⼀个进程池, 最⼤进程数3
- for i in range(0,10):
- po.apply(worker,(i,))
- print("----start----")
- po.close() #关闭进程池, 关闭后po不再接收新的请求
- po.join() #等待po中所有⼦进程执⾏完成, 必须放在close语句之后
- print("-----end-----")
运行结果
- 0开始执⾏,进程号为5280
- 0 执⾏完毕, 耗时0.91
- 1开始执⾏,进程号为5281
- 1 执⾏完毕, 耗时1.59
- 2开始执⾏,进程号为5282
- 2 执⾏完毕, 耗时1.25
- 3开始执⾏,进程号为5280
- 3 执⾏完毕, 耗时0.53
- 4开始执⾏,进程号为5281
- 4 执⾏完毕, 耗时1.49
- 5开始执⾏,进程号为5282
- 5 执⾏完毕, 耗时0.18
- 6开始执⾏,进程号为5280
- 6 执⾏完毕, 耗时1.51
- 7开始执⾏,进程号为5281
- 7 执⾏完毕, 耗时0.88
- 8开始执⾏,进程号为5282
- 8 执⾏完毕, 耗时1.08
- 9开始执⾏,进程号为5280
- 9 执⾏完毕, 耗时0.12
- ----start----
- -----end-----
apply_async(func[, args[, kwds]]) : 使⽤⾮阻塞⽅式调⽤func( 并⾏执⾏, 堵塞⽅式必须等待上⼀个进程退出才能执⾏下⼀个进程) , args为传递给func的参数列表, kwds为传递给func的关键字参数列表;
python实现进程的三种方式及其区别的更多相关文章
- python核心高级学习总结3-------python实现进程的三种方式及其区别
python实现进程的三种方式及其区别 在python中有三种方式用于实现进程 多进程中, 每个进程中所有数据( 包括全局变量) 都各有拥有⼀份, 互不影响 1.fork()方法 ret = os.f ...
- Python—创建进程的三种方式
方式一:os.fork() 子进程是从os.fork得到的值,然后赋值开始执行的.即子进程不执行os.fork,从得到的值开始执行. 父进程中fork之前的内容子进程同样会复制,但父子进程空间独立,f ...
- python实现单例模式的三种方式及相关知识解释
python实现单例模式的三种方式及相关知识解释 模块模式 装饰器模式 父类重写new继承 单例模式作为最常用的设计模式,在面试中很可能遇到要求手写.从最近的学习python的经验而言,singlet ...
- Python实现定时执行任务的三种方式简单示例
本文实例讲述了Python实现定时执行任务的三种方式.分享给大家供大家参考,具体如下: 1.定时任务代码 import time,os,sched schedule = sched.scheduler ...
- Python格式化输出的三种方式
Python格式化输出的三种方式 一.占位符 程序中经常会有这样场景:要求用户输入信息,然后打印成固定的格式比如要求用户输入用户名和年龄,然后打印如下格式:My name is xxx,my age ...
- Java实现线程的三种方式和区别
Java实现线程的三种方式和区别 Java实现线程的三种方式: 继承Thread 实现Runnable接口 实现Callable接口 区别: 第一种方式继承Thread就不能继承其他类了,后面两种可以 ...
- 记住 Python 变量类型的三种方式
title: 记住变量类型的三种方式 date: 2017-06-11 15:25:03 tags: ['Python'] category: ['Python'] toc: true comment ...
- javascript函数命名的三种方式及区别
1, function fn(val1,val2) { alert(val1+val2); } fn(1,2); 2, var fn=function() { alert(val1+val2); } ...
- React创建组件的三种方式及其区别
内容转载于http://www.cnblogs.com/wonyun/p/5930333.html React推出后,出于不同的原因先后出现三种定义react组件的方式,殊途同归; 具体的三种方式: ...
随机推荐
- PTA的Python练习题(三)
继续在PTA上编写Python的编程题. 从 第2章-11 求平方与倒数序列的部分和 开始 1. a,b=map(int,input().split()) s=0 while(a<=b): s= ...
- RedHat OpenShift QuickStart 1.2
一.在容器中传入/出文件 1. 创建一个初始化项目 oc login -u developer -p developer oc new-project myproject 2. 在容器中下载文件 先通 ...
- jquery $.ajax status为200 却调用了error方法
参考: https://blog.csdn.net/shuifa2008/article/details/41121269 https://blog.csdn.net/shuifa2008/artic ...
- C++ STL之动态数组vector(⽮量)的使⽤
写再最前面:摘录于柳神的笔记: 之前C语⾔⾥⾯⽤ int arr[] 定义数组,它的缺点是数组的⻓度不能随⼼所欲的改变,⽽C++⾥⾯有⼀个能完全替代数组的动态数组 vector (有的书⾥⾯把它翻 ...
- Android FM模块学习之四源码解析(一)
转自:http://blog.csdn.net/tfslovexizi/article/details/41516149?utm_source=tuicool&utm_medium=refer ...
- Linux centos7iptables filter表案例、iptables nat表应用
一.iptables filter表案例 vim /usr/local/sbin/iptables.sh 加入如下内容 #! /bin/bash ipt="/usr/sbin/iptable ...
- node.js是什么,node.js创建应用
简单的说 Node.js 就是运行在服务端的 JavaScript.Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台.Node.js是一个事件驱动I/O服务端Java ...
- mysql 命令行个性化设置
通过配置显示主机和用户名 mysql -u root -p --prompt="(\u@\h) [\d]>" 或在配置文件中修改,可在命令行中的目标位置查看 --tee na ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 表格:表示一个危险的操作
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- C#用SQLDMO操作数据库----转载
C#用SQLDMO操作数据库 sqldmo.dll是随sql server2000一起发布的.sqldmo.dll自身是一个com对象 sqldmo(sql distributed managemen ...