大数据存储利器 - Hbase 基础图解
由于疫情原因在家办公,导致很长一段时间没有更新内容,这次终于带来一篇干货,是一篇关于 Hbase架构原理 的分享。
Hbase 作为实时存储框架在大数据业务下承担着举足轻重的地位,可以说目前绝大多数大数据场景都离不开Hbase。
今天就先从 Hbase 基础入手,来说说 Hbase 经常用到却容易疏忽的基础知识。
本文主要结构总结如下:
Hbase 主从架构
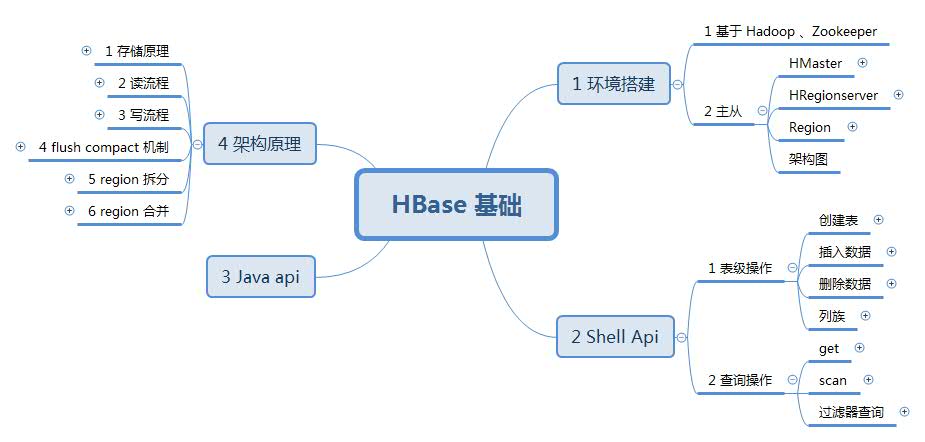
Hbase 安装依靠 Hadoop 与 Zookeeper,网上有很多安装教程,安装比较简单,这里我们就着重看下 Habse 架构,如图:

可以从图中看出,Hbase 也是主从架构,其中 HMaster 为主,HRegionServer 为从。
Zookeeper 主要存储了Hbase中的元数据信息,如哪个表存储在哪个 HRegionServer 上;
HLog 是作为 Hbase 写数据前的日志记录;
BLockCache 作为读写数据的缓存;
HMaster:
负责新Region分配到指定HRegionServer
管理HRegionServer 间负载均衡,迁移 region
当HRegionServer 宕机,负责 region 迁移
HRegionserver:
响应客户端读写请求
管理Region
切分变大的 Region
Region:
一个 Region 对应一个 Table 表
Hbase 存储的最小单元
HBase 表结构
Hbase 列式存储的结构与行式存储不同,它的表模型类似下图:

表中大致可以分为 rowKey 、列族 、版本号三大元素,列族下可以创建多个列,表中的每一个单元格又称为 cell,需要注意的是 cell 并不是只有一个数据,它可以有多个版本从而实现在同一rowkey ,同一列族, 同一列下存储多个数据。
重点来了,有了上面的铺垫,接下来就可以进入正题部分了 ,下面我们来看下 Hbase 的架构原理。
Hbase 架构原理
1. Hbase 的存储原理
还回到上边的架构图,可以看到 一个 HRegionServer 上有多个 HRegion,一个 Region 实际上就对应了一张表,由于 region 的拆分机制,同一张表的数据可能不会在一个HRegionServer上, 但是一个 Region 肯定只存一张表的数据。
下面我们再看看 HRegion 里面的结构:
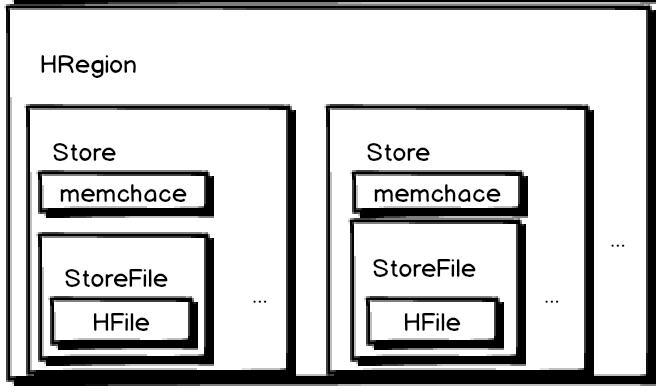
从图中我看可以看到以下几点:
一个region包含多个 store,其中 :
一个列族就划分成一个 store
如果一个表中只有1个列族,那么每一个region中只有一个store
如果一个表中只有N个列族,那么每一个region中有N个store
一个store里面只有一个memstore
memstore 是一块内存,数据会先写进 memstore,然后再把数据刷到硬盘
一个store里面有很多的StoreFile,最后数据以很多 HFile 这种数据结构存在HDFS上
StoreFile 是 Hfile 的抽象对象,说到StoreFile就等于HFile
每次 memsotre 刷新数据到磁盘,就生成对应的一个新的 HFile
2. Hbase 的读流程
在说读读写流程前,需要说明一下,整个 HBase集群,只有一张meta表(元数据信息表),此表只有一个region,该region数据保存在一个HRegionServer上 。
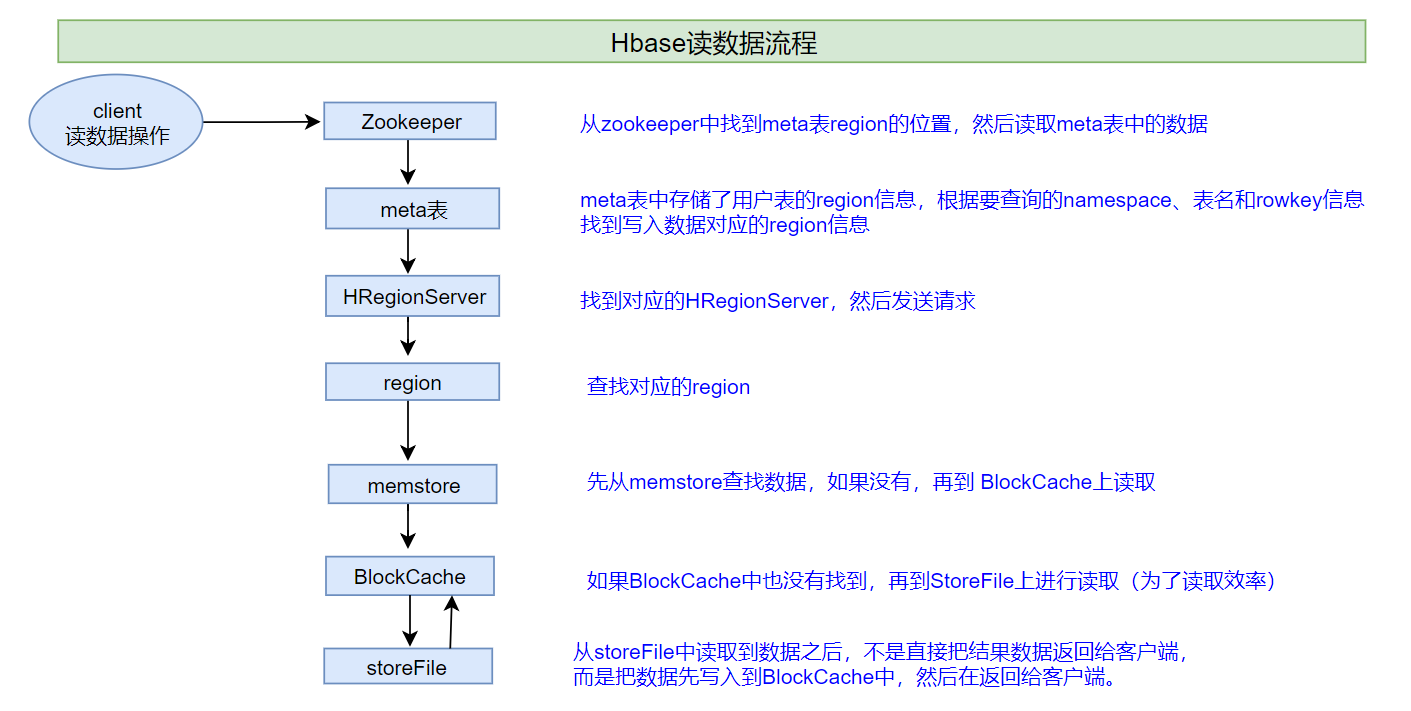
1、客户端首先与zk进行连接;从zk找到meta表的region位置,即meta表的数据存储在某一HRegionServer上;客户端与此HRegionServer建立连接,然后读取meta表中的数据;meta表中存储了所有用户表的region信息,我们可以通过
scan 'hbase:meta'来查看meta表信息2、根据要查询的namespace、表名和rowkey信息。找到写入数据对应的region信息
3、找到这个region对应的regionServer,然后发送请求
4、查找并定位到对应的region
5、先从memstore查找数据,如果没有,再从BlockCache上读取
一部分作为Memstore,主要用来写;
另外一部分作为BlockCache,主要用于读数据;
HBase上Regionserver的内存分为两个部分
6、如果BlockCache中也没有找到,再到StoreFile上进行读取
从storeFile中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。
3. Hbase 的写流程
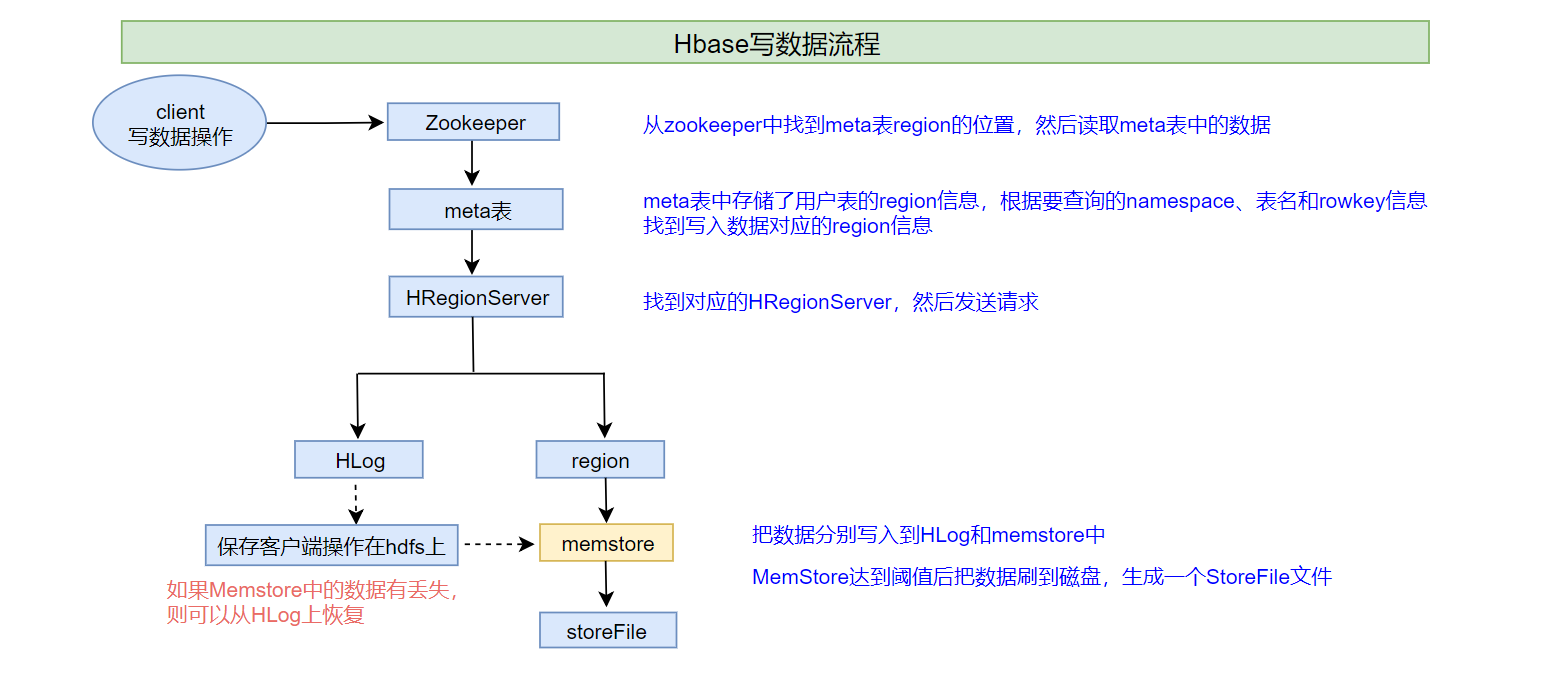
1、客户端首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
2、根据namespace、表名和rowkey信息。找到写入数据对应的region信息
3、找到这个region对应的regionServer,然后发送请求
4、把数据分别写到HLog(write ahead log)和memstore各一份
write ahead log :也称为WAL,类似mysql中的binlog,用来做灾难恢复时用,HLog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
5、memstore达到阈值后把数据刷到磁盘,生成storeFile文件
6、删除HLog中的历史数据
4. Hbase 的 flush 与 compact 机制
概括来说,flush 是数据由 memstore 刷写到磁盘的过程,compact 是 磁盘文件合并的过程,如图所示:
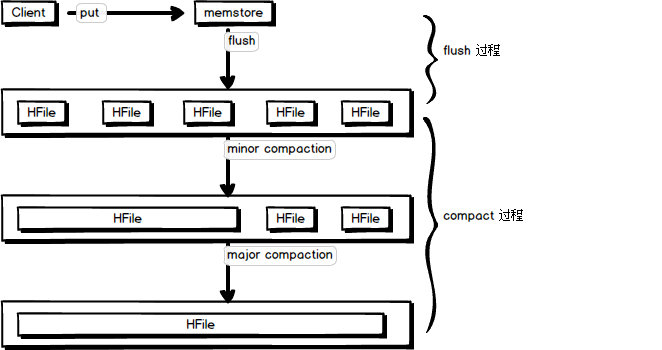
flush 机制
flush 大致可以分为三个阶段,prepare 阶段,flush 阶段,commit 阶段:
prepare 阶段
遍历当前 Region 中所有的 Memstore,将Memstore中当前数据集CellSkipListSet 做一个快照snapshot,之后创建一个新的CellSkipListSet,后期写入的数据都会写入新的CellSkipListSet中
flush 阶段
遍历所有Memstore,将 prepare阶段生成的 snapshot 持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时
commit 阶段
遍历所有 Memstore,将 flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot 。
flush 的触发条件一般分为 memstore 级别,region 级别,regionServer 级别,HLog数量上限,具体配置可在官网文档中查询到。
compact 机制
从图中可以看出 compact 合并机制,主要分为 小合并 、大合并两个阶段。
minor compaction 小合并
将Store中多个HFile合并为一个HFile,一次Minor Compaction的结果是HFile数量减少并且合并出一个更大的StoreFile,这种合并的触发频率很高。
major compaction 大合并
合并 Store 中所有的 HFile 为一个HFile,被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空闲时间手动触发。一般可以是手动控制进行合并,防止出现在业务高峰期。
5. Hbase 的 region 拆分 与 合并
region 的拆分
Q:
为什么要拆分 region 呢?
A:
region中存储的是大量的 rowkey 数据 ,当 region 中的数据条数过多, region 变得很大的时候,直接影响查询效率.因此当 region 过大的时候.hbase会拆分region , 这也是Hbase的一个优点 。
region 拆分策略
0.94版本前默认切分策略,当region大小大于某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
0.94版本~2.0版本默认切分策略 :根据拆分次数来判断触发拆分的条件
region split的计算公式是:
regioncount^3 * 128M * 2,当region达到该 size 的时候进行split
例如:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了
预分区机制
当一个Hbase 表刚被创建的时候,Hbase默认的分配一个 region 给table。也就是说这个时候,所有的读写请求都会访问到同一个 regionServer 的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他 regionServer 就可能会处于比较空闲的状态。
为了解决这个问题,就有了 pre-splitting,也就是预分区机制,在创建table的时候就配置好,生成多个region,这样的好处就是可以优化数据读写效率;并且使用负载均衡机制,防止数据倾斜。
操作很简单,在创建表时,手动指定分区就好了:
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']
region 的合并
Region的合并不是为了性能, 而是出于维护的目的 。
比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个 Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些 Region 服务器节点,由此可见 region 的合并其实是为了更好的维护 Hbase 集群。
至此,正文内容就结束了,为了更好的梳理这些知识,我将文章中重要的部分都放到下面这张图中,方便以后总结查阅:

PS:后续文章更新方向除涉及大数据框架方向外,额外添加 C 语言和数据结构等计算机基础方向,敬请期待 ~
大数据存储利器 - Hbase 基础图解的更多相关文章
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- MapGis如何实现WebGIS分布式大数据存储的
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢? MapGIS在传统关系型空间数据库引擎MapGIS SDE的基础之上,针对地理大数据的特点,构建了MapGIS DataStore分布式 ...
- 大数据存储的进化史 --从 RAID 到 Hdfs
我们都知道现在大数据存储用的基本都是 Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdfs. 我们先来 ...
- 大数据篇:Hbase
大数据篇:Hbase Hbase是什么 Hbase是一个分布式.可扩展.支持海量数据存储的NoSQL数据库,物理结构存储结构(K-V). 如果没有Hbase 如何在大数据场景中,做到上亿数据秒级返回. ...
- 大数据存储:MongoDB实战指南——常见问题解答
锁粒度与并发性能怎么样? 数据库的读写并发性能与锁的粒度息息相关,不管是读操作还是写操作开始运行时,都会请求相应的锁资源,如果请求不到,操作就会被阻塞.读操作请求的是读锁,能够与其它读操作共享,但是当 ...
- Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案 随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
随机推荐
- Rip路由实验
以上是实验要求和实验拓扑图 (实验拓扑自己重新连线) 1.在R1-R4,4台路由器上各设置一个回环口 2.略 3.在四个路由器上配置rip(rip的基本命令) #rip 1 #version 2 #u ...
- RNA sequence单分子直测技术
生命组学 按照功能分类遗传物质,可能的分类有系统流.操作流.平衡流等等.下面是使用该理论解释DNA与RNA的关系: DNA和RNA有很大不同,DNA存储遗传信息,作为生命活动的最内核物质,如同操作系统 ...
- Ubuntu16.04使用sublime text3编写C语言后,实现编译并自动调用bash终端运行程序
实现编译并自动调用bash运行程序只需要新建自己的.build文件就OK 依次打开: tools->building system->new building system 后,把下面的内 ...
- haproxy笔记之三:配置HAProxy详细介绍
2.1 配置文件格式 HAProxy的配置处理3类来主要参数来源:——最优先处理的命令行参数,——“global”配置段,用于设定全局配置参数:——proxy相关配置段,如“defaults”.“li ...
- [SDOI2008] 洞穴勘测 (LCT模板)
bzoj 2049 传送门 洛谷P2147 传送门 这个大佬的LCT详解超级棒的! Link-Cut Tree的基本思路是用splay的森林维护一条条树链. splay的森林,顾名思义,就是若干spl ...
- python爬取许多图片的代码
from bs4 import BeautifulSoup import requests import os os.makedirs('./img/', exist_ok=True) URL = & ...
- 【内推】平安产险大数据测试开发工程师,15-30k!
平安产险技术岗内部推荐-大数据测试开发工程师等-欢迎中年人和2020应届生 上班地点:深圳福田平安金融中心 另有大量 上海 北京 成都 广州 岗位 交流qq群 828186629 微信pythonte ...
- 为什么 generator 忽略第一次 next 调用的参数值呢?
首先要理解几个基本概念. 执行生成器不会执行生成器函数体的代码,只是获得一个遍历器 一旦调用 next,函数体就开始执行,一旦遇到 yield 就返回执行结果,暂停执行 第二次 next 的参数会作为 ...
- 天哪!毫无思绪!令人感到恐惧的数学(水题?)(TOWQs)
这道题的题目描述灰常简单,第一眼看以为是一道十分水的题目: 但是!!!(我仔细一看也没有发现这背后隐藏着可怕的真相~) 下面给出题目描述: 给出一个整数x,你可以对x进行两种操作.1.将x变成4x+3 ...
- 乱世兄弟(豹老头 X 天捣臼)
论CP之冷冷冷 只为白凡扫剧- 片源: 乱世兄弟 BGM:兄弟 人物角色: 豹老头 - 白凡 天捣臼 大专栏 乱世兄弟(豹老头 X 天捣臼)- 姚鲁 B站:豹老头 X 天捣臼-MV<乱世兄弟& ...