mapreduce导出MSSQL的数据到HDFS
今天想通过一些数据,来测试一下我的《基于信息熵的无字典分词算法》这篇文章的正确性。就写了一下MapReduce程序从MSSQL SERVER2008数据库里取数据分析。程序发布到hadoop机器上运行报SQLEXCEPTION错误
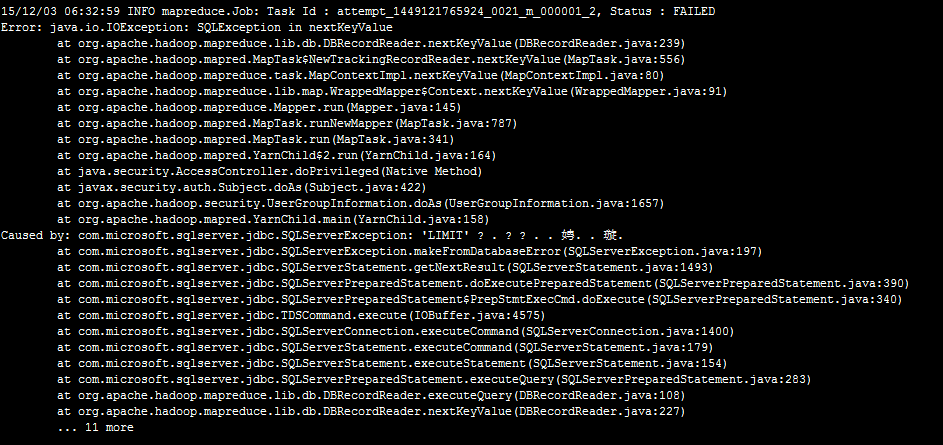
奇怪了,我的SQL语句中没有LIMIT,这LIMIT哪来的。我翻看了DBInputFormat类的源码,
- protected RecordReader<LongWritable, T> createDBRecordReader(DBInputSplit split,
- Configuration conf) throws IOException {
- @SuppressWarnings("unchecked")
- Class<T> inputClass = (Class<T>) (dbConf.getInputClass());
- try {
- // use database product name to determine appropriate record reader.
- if (dbProductName.startsWith("ORACLE")) {
- // use Oracle-specific db reader.
- return new OracleDBRecordReader<T>(split, inputClass,
- conf, createConnection(), getDBConf(), conditions, fieldNames,
- tableName);
- } else if (dbProductName.startsWith("MYSQL")) {
- // use MySQL-specific db reader.
- return new MySQLDBRecordReader<T>(split, inputClass,
- conf, createConnection(), getDBConf(), conditions, fieldNames,
- tableName);
- } else {
- // Generic reader.
- return new DBRecordReader<T>(split, inputClass,
- conf, createConnection(), getDBConf(), conditions, fieldNames,
- tableName);
- }
- } catch (SQLException ex) {
- throw new IOException(ex.getMessage());
- }
- }
DBRecordReader的源码
- protected String getSelectQuery() {
- StringBuilder query = new StringBuilder();
- // Default codepath for MySQL, HSQLDB, etc. Relies on LIMIT/OFFSET for splits.
- if(dbConf.getInputQuery() == null) {
- query.append("SELECT ");
- for (int i = 0; i < fieldNames.length; i++) {
- query.append(fieldNames[i]);
- if (i != fieldNames.length -1) {
- query.append(", ");
- }
- }
- query.append(" FROM ").append(tableName);
- query.append(" AS ").append(tableName); //in hsqldb this is necessary
- if (conditions != null && conditions.length() > 0) {
- query.append(" WHERE (").append(conditions).append(")");
- }
- String orderBy = dbConf.getInputOrderBy();
- if (orderBy != null && orderBy.length() > 0) {
- query.append(" ORDER BY ").append(orderBy);
- }
- } else {
- //PREBUILT QUERY
- query.append(dbConf.getInputQuery());
- }
- try {
- query.append(" LIMIT ").append(split.getLength()); //问题所在
- query.append(" OFFSET ").append(split.getStart());
- } catch (IOException ex) {
- // Ignore, will not throw.
- }
- return query.toString();
- }
终于找到原因了。
原来,hadoop只实现了Mysql的DBRecordReader(MySQLDBRecordReader)和ORACLE的DBRecordReader(OracleDBRecordReader)。
原因找到了,我参考着OracleDBRecordReader实现了MSSQL SERVER的DBRecordReader代码如下:
MSSQLDBInputFormat的代码:
- /**
- *
- */
- package org.apache.hadoop.mapreduce.lib.db;
- import java.io.IOException;
- import java.sql.SQLException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.RecordReader;
- /**
- * @author summer
- * MICROSOFT SQL SERVER
- */
- public class MSSQLDBInputFormat<T extends DBWritable> extends DBInputFormat<T> {
- public static void setInput(Job job,
- Class<? extends DBWritable> inputClass,
- String inputQuery, String inputCountQuery,String rowId) {
- job.setInputFormatClass(MSSQLDBInputFormat.class);
- DBConfiguration dbConf = new DBConfiguration(job.getConfiguration());
- dbConf.setInputClass(inputClass);
- dbConf.setInputQuery(inputQuery);
- dbConf.setInputCountQuery(inputCountQuery);
- dbConf.setInputFieldNames(new String[]{rowId});
- }
- @Override
- protected RecordReader<LongWritable, T> createDBRecordReader(
- org.apache.hadoop.mapreduce.lib.db.DBInputFormat.DBInputSplit split,
- Configuration conf) throws IOException {
- @SuppressWarnings("unchecked")
- Class<T> inputClass = (Class<T>) (dbConf.getInputClass());
- try {
- return new MSSQLDBRecordReader<T>(split, inputClass,
- conf, createConnection(), getDBConf(), conditions, fieldNames,
- tableName);
- } catch (SQLException ex) {
- throw new IOException(ex.getMessage());
- }
- }
- }
MSSQLDBRecordReader的代码:
- /**
- *
- */
- package org.apache.hadoop.mapreduce.lib.db;
- import java.io.IOException;
- import java.sql.Connection;
- import java.sql.SQLException;
- import org.apache.hadoop.conf.Configuration;
- /**
- * @author summer
- *
- */
- public class MSSQLDBRecordReader <T extends DBWritable> extends DBRecordReader<T>{
- public MSSQLDBRecordReader(DBInputFormat.DBInputSplit split,
- Class<T> inputClass, Configuration conf, Connection conn, DBConfiguration dbConfig,
- String cond, String [] fields, String table) throws SQLException {
- super(split, inputClass, conf, conn, dbConfig, cond, fields, table);
- }
- @Override
- protected String getSelectQuery() {
- StringBuilder query = new StringBuilder();
- DBConfiguration dbConf = getDBConf();
- String conditions = getConditions();
- String tableName = getTableName();
- String [] fieldNames = getFieldNames();
- // Oracle-specific codepath to use rownum instead of LIMIT/OFFSET.
- if(dbConf.getInputQuery() == null) {
- query.append("SELECT ");
- for (int i = 0; i < fieldNames.length; i++) {
- query.append(fieldNames[i]);
- if (i != fieldNames.length -1) {
- query.append(", ");
- }
- }
- query.append(" FROM ").append(tableName);
- if (conditions != null && conditions.length() > 0)
- query.append(" WHERE ").append(conditions);
- String orderBy = dbConf.getInputOrderBy();
- if (orderBy != null && orderBy.length() > 0) {
- query.append(" ORDER BY ").append(orderBy);
- }
- } else {
- //PREBUILT QUERY
- query.append(dbConf.getInputQuery());
- }
- try {
- DBInputFormat.DBInputSplit split = getSplit();
- if (split.getLength() > 0){
- String querystring = query.toString();
- String id = fieldNames[0];
- query = new StringBuilder();
- query.append("SELECT TOP "+split.getLength()+"* FROM ( ");
- query.append(querystring);
- query.append(" ) a WHERE " + id +" NOT IN (SELECT TOP ").append(split.getEnd());
- query.append(" "+id +" FROM (");
- query.append(querystring);
- query.append(" ) b");
- query.append(" )");
- System.out.println("----------------------MICROSOFT SQL SERVER QUERY STRING---------------------------");
- System.out.println(query.toString());
- System.out.println("----------------------MICROSOFT SQL SERVER QUERY STRING---------------------------");
- }
- } catch (IOException ex) {
- // ignore, will not throw.
- }
- return query.toString();
- }
- }
mapreduce的代码
- /**
- *
- */
- package com.nltk.sns.mapreduce;
- import java.io.IOException;
- import java.util.List;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.MRJobConfig;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
- import org.apache.hadoop.mapreduce.lib.db.MSSQLDBInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import com.nltk.utils.ETLUtils;
- /**
- * @author summer
- *
- */
- public class LawDataEtl {
- public static class CaseETLMapper extends
- Mapper<LongWritable, LawCaseRecord, LongWritable, Text>{
- static final int step = 6;
- LongWritable key = new LongWritable(1);
- Text value = new Text();
- @Override
- protected void map(
- LongWritable key,
- LawCaseRecord lawCaseRecord,
- Mapper<LongWritable, LawCaseRecord, LongWritable, Text>.Context context)
- throws IOException, InterruptedException {
- System.out.println("-----------------------------"+lawCaseRecord+"------------------------------");
- key.set(lawCaseRecord.id);
- String source = ETLUtils.format(lawCaseRecord.source);
- List<LawCaseWord> words = ETLUtils.split(lawCaseRecord.id,source, step);
- for(LawCaseWord w:words){
- value.set(w.toString());
- context.write(key, value);
- }
- }
- }
- static final String driverClass = "com.microsoft.sqlserver.jdbc.SQLServerDriver";
- static final String dbUrl = "jdbc:sqlserver://192.168.0.1:1433;DatabaseName=XXX";
- static final String uid = "XXX";
- static final String pwd = "XXX";
- static final String inputQuery = "select id,source from tablename where id<1000";
- static final String inputCountQuery = "select count(1) from LawDB.dbo.case_source where id<1000";
- static final String jarClassPath = "/user/lib/sqljdbc4.jar";
- static final String outputPath = "hdfs://ubuntu:9000/user/test";
- static final String rowId = "id";
- public static Job configureJob(Configuration conf) throws Exception{
- String jobName = "etlcase";
- Job job = Job.getInstance(conf, jobName);
- job.addFileToClassPath(new Path(jarClassPath));
- MSSQLDBInputFormat.setInput(job, LawCaseRecord.class, inputQuery, inputCountQuery,rowId);
- job.setJarByClass(LawDataEtl.class);
- FileOutputFormat.setOutputPath(job, new Path(outputPath));
- job.setMapOutputKeyClass(LongWritable.class);
- job.setMapOutputValueClass(Text.class);
- job.setOutputKeyClass(LongWritable.class);
- job.setOutputValueClass(Text.class);
- job.setMapperClass(CaseETLMapper.class);
- return job;
- }
- public static void main(String[] args) throws Exception{
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(conf);
- fs.delete(new Path(outputPath), true);
- DBConfiguration.configureDB(conf, driverClass, dbUrl, uid, pwd);
- conf.set(MRJobConfig.NUM_MAPS, String.valueOf(10));
- Job job = configureJob(conf);
- System.out.println("------------------------------------------------");
- System.out.println(conf.get(DBConfiguration.DRIVER_CLASS_PROPERTY));
- System.out.println(conf.get(DBConfiguration.URL_PROPERTY));
- System.out.println(conf.get(DBConfiguration.USERNAME_PROPERTY));
- System.out.println(conf.get(DBConfiguration.PASSWORD_PROPERTY));
- System.out.println("------------------------------------------------");
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
辅助类的代码:
- /**
- *
- */
- package com.nltk.sns;
- import java.util.ArrayList;
- import java.util.List;
- import org.apache.commons.lang.StringUtils;
- /**
- * @author summer
- *
- */
- public class ETLUtils {
- public final static String NULL_CHAR = "";
- public final static String PUNCTUATION_REGEX = "[(\\pP)&&[^\\|\\{\\}\\#]]+";
- public final static String WHITESPACE_REGEX = "[\\p{Space}]+";
- public static String format(String s){
- return s.replaceAll(PUNCTUATION_REGEX, NULL_CHAR).replaceAll(WHITESPACE_REGEX, NULL_CHAR);
- }
- public static List<String> split(String s,int stepN){
- List<String> splits = new ArrayList<String>();
- if(StringUtils.isEmpty(s) || stepN<1)
- return splits;
- int len = s.length();
- if(len<=stepN)
- splits.add(s);
- else{
- for(int j=1;j<=stepN;j++)
- for(int i=0;i<=len-j;i++){
- String key = StringUtils.mid(s, i,j);
- if(StringUtils.isEmpty(key))
- continue;
- splits.add(key);
- }
- }
- return splits;
- }
- public static void main(String[] args){
- String s="谢婷婷等与姜波等";
- int stepN = 2;
- List<String> splits = split(s,stepN);
- System.out.println(splits);
- }
- }
运行成功了

代码初略的实现,主要是为了满足我的需求,大家可以根据自己的需要进行修改。
实际上DBRecordReader作者实现的并不好,我们来看DBRecordReader、MySQLDBRecordReader和OracleDBRecordReader源码,DBRecordReader和MySQLDBRecordReader耦合度太高。一般而言,就是对于没有具体实现的数据库DBRecordReader也应该做到运行不报异常,无非就是采用单一的SPLIT和单一的MAP。
mapreduce导出MSSQL的数据到HDFS的更多相关文章
- 使用C#导出MSSQL表数据Insert语句,支持所有MSSQL列属性
在正文开始之前,我们先看一下MSSQL的两张系统表sys.objects . syscolumnsMSDN中 sys.objects表的定义:在数据库中创建的每个用户定义的架构作用域内的对象在该表中均 ...
- MapReduce(十六): 写数据到HDFS的源代码分析
1) LineRecordWriter负责把Key,Value的形式把数据写入到DFSOutputStream watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZ ...
- 使用MapReduce将mysql数据导入HDFS
package com.zhen.mysqlToHDFS; import java.io.DataInput; import java.io.DataOutput; import java.io.IO ...
- 1.6-1.10 使用Sqoop导入数据到HDFS及一些设置
一.导数据 1.import和export Sqoop可以在HDFS/Hive和关系型数据库之间进行数据的导入导出,其中主要使用了import和export这两个工具.这两个工具非常强大, 提供了很多 ...
- BCP导入导出MsSql
BCP导入导出MsSql 1.导出数据 (1).在Sql Server Management Studio中: --导出数据到tset1.txt,并指定本地数据库的用户名和密码 --这里需要指定数据库 ...
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
- 大数据(1)---大数据及HDFS简述
一.大数据简述 在互联技术飞速发展过程中,越来越多的人融入互联网.也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了.比如淘宝,每天的活跃用户 ...
- 第3节 sqoop:4、sqoop的数据导入之导入数据到hdfs和导入数据到hive表
注意: (1)\001 是hive当中默认使用的分隔符,这个玩意儿是一个asc 码值,键盘上面打不出来 (2)linux中一行写不下,可以末尾加上 一些空格和 “ \ ”,换行继续写余下的命令: bi ...
- 关于Java导出100万行数据到Excel的优化方案
1>场景 项目中需要从数据库中导出100万行数据,以excel形式下载并且只要一张sheet(打开这么大文件有多慢另说,呵呵). ps:xlsx最大容纳1048576行 ,csv最大容纳1048 ...
随机推荐
- git开发流程、常用命令及工具、TortoiseGit使用及常见问题
根据我最近使用git的一些经历,git是基于分支的版本控制工具,分支有远程分支和本地分支. 一.开发流程 - 从远程服务器的master,clone一份项目文件到本地,然后本地master的基础上br ...
- HashMap和HashTable到底哪不同?
HashMap和HashTable有什么不同?在面试和被面试的过程中,我问过也被问过这个问题,也见过了不少回答,今天决定写一写自己心目中的理想答案. 代码版本 JDK每一版本都在改进.本文讨论的Has ...
- Linux(Centos)快速搭建SVN
前言 项目中源码或者文档需要进行管理与版本记录,历数此类工具VSS.CVS.SVN.GIT等等,有非常多的版本控制系统.SVN现在还是很常见,把笔记总结搬上博客,SVN这个再不放以后估计只能写GIT的 ...
- OpenGL新手框架
开始学习用OpenGL,也就想显示一些点,以为挺简单的,哎,看了两天才会画三维的点,做个总结. 使用OpenGL的基本流程 int main(int argv, char *argc[]) { //初 ...
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——词法解析
jQuery源码9600多行,而Sizzle引擎就独占近2000行,占了1/5.Sizzle引擎.jQuery事件机制.ajax是整个jQuery的核心,也是jQuery技术精华的体现.里面的有些策略 ...
- Windows 10 内置管理员无法打开Metro应用方法
前言 在windows 10中,由于权限原因,使用了内置管理员账户.虽然这样权限获取了,但是不能打开Metro应用,Microsoft Edge浏览器等,有点不太好.那有没有方法可以修改呢?这是本文要 ...
- Hibernate框架中Criteria语句
在Hibernate中有一种查询语句是Criteria查询(QBC查询),今天呢 我们就一个个的详细的跟大家一起探讨Criteria语句的相关知识点 案例前的准备 //插入测试数据,构建数据库 pub ...
- C# DataGridView中指定的单元格不能编辑
注意:DataGridView控件是从.NET Framework 2.0版本开始追加的. ReadOnly属性的使用 DataGridView内所有的单元格不能编辑 当DataGridView.Re ...
- entityframework学习笔记--004-无载荷与有载荷关系
1.无载荷(with NO Payload)的多对多关系建模 在数据库中,存在通过一张链接表来关联两张表的情况.链接表仅包含连接两张表形成多对多关系的外键,你需要把这两张多对多关系的表导入到实体框架模 ...
- ASP对XML的增、删、改、查
首先看一下xml文件 text.xml 'encoding使用gb2312中文,如果要用英文则用utf-8 <?xml version="1.0" encoding=&quo ...