KubeSphere 多行日志采集方案深度探索
作者:大飞哥,视源电子运维工程师,KubeSphere 用户委员会广州站站长
采集落盘日志
日志采集,通常使用 EFK 架构,即 ElasticSearch,Filebeat,Kibana,这是在主机日志采集上非常成熟的方案,但在容器日志采集方面,整体方案就会复杂很多。我们现在面临的需求,就是要采集容器中的落盘日志。
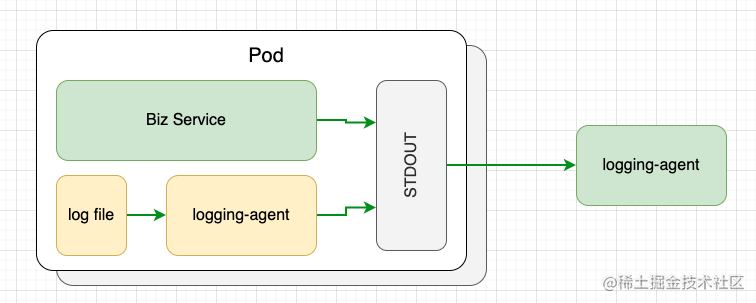
容器日志分为标准输出日志和落盘日志两种。应用将日志打印在容器标准输出 STDOUT 中,由容器运行时(Docker 或 Containerd)把标准输出日志写入容器日志文件中,最终由采集器导出。这种日志打印采集是业界推荐方案。但对于不打印标准输出而直接将日志落盘的情况,业界最常用见的方案是,使用 Sidecar 采集落盘日志,把落盘日志打印到容器标准输出中,再利用标准输出日志的采集方式输出。
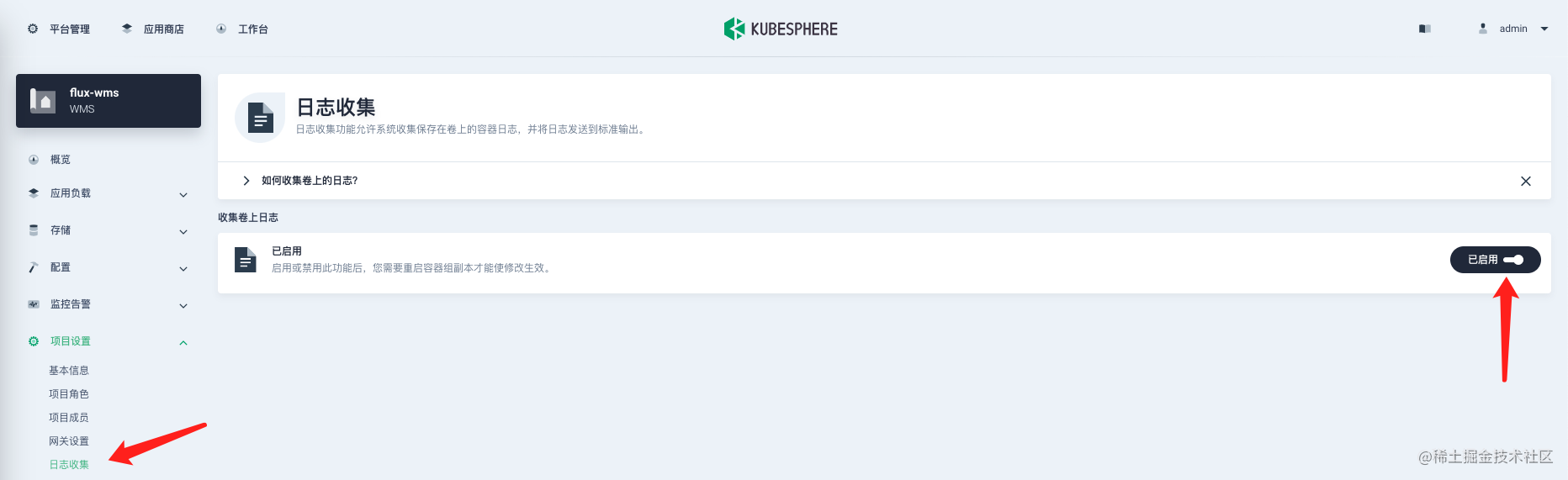
对于 KubeSphere 用户,只需要两步即可:第一在项目中开启收集卷上日志,第二在工作负载中配置落盘文件路径。具体操作见下图所示。
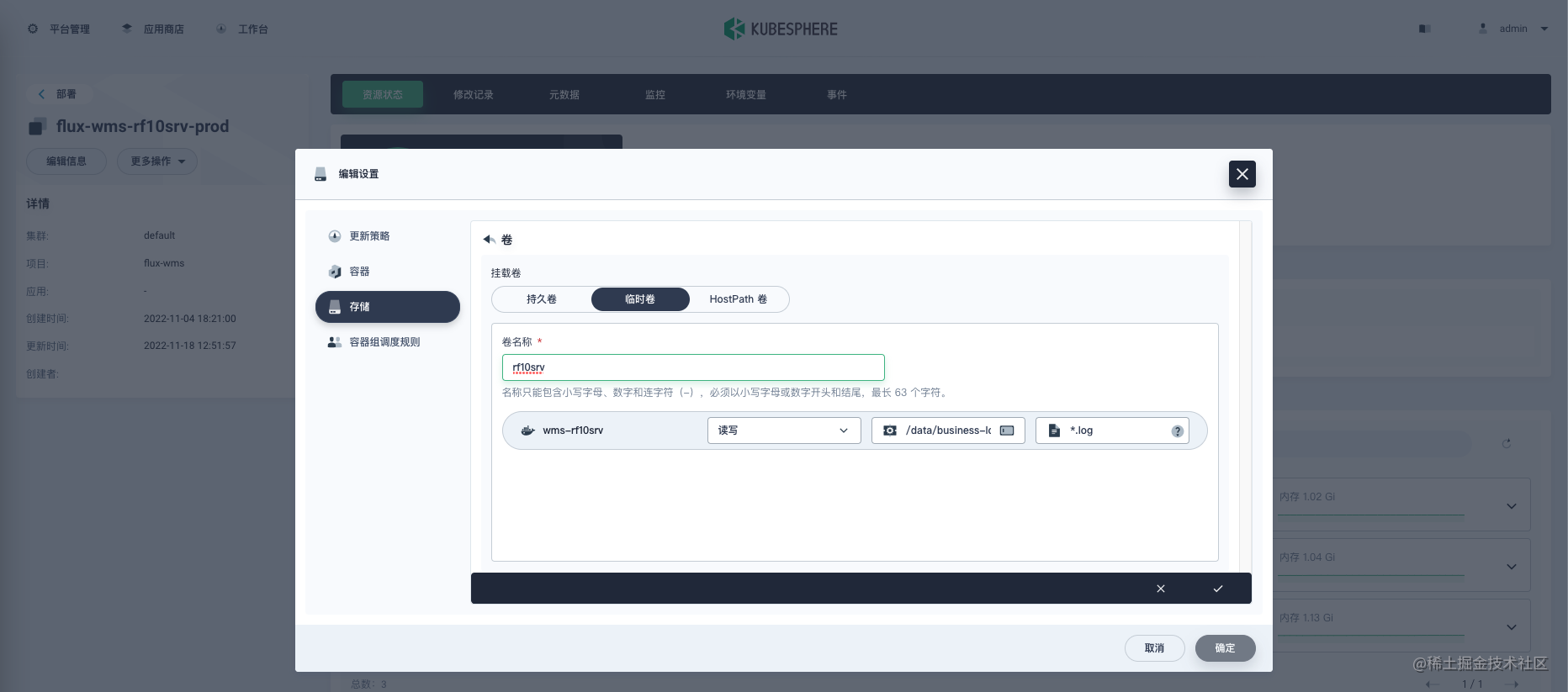
上述两个步骤,会自动在容器中注入 Filebeat Sidecar 作为 logging-agent,将落盘日志打印输出在容器标准输出中。Filebeat 配置可通过 ConfigMap 修改。
$ kubectl get cm -n kubesphere-logging-system logsidecar-injector-configmap -o yaml
## Filebeat 配置
filebeat.inputs:
- type: log
enabled: true
paths:
{{range .Paths}}
- {{.}}
{{end}}
output.console:
codec.format:
string: '%{[log.file.path]} %{[message]}'
logging.level: warning
接入第三方日志服务
默认 KubeSphere 将日志采集到集群内置 Elasticsearch 中,数据保存周期为 7 天,这对于生产服务动辄 180 天的日志存储需求,显然无法满足。企业运维团队都会建立集中化的日志服务,将集群内日志接入到第三方日志服务中,已是必然选择。我们来看如何操作。
上文说到,容器运行时会将标准输出日志,落盘写入到集群节点的日志文件中,Linux 系统默认在 /var/log/containers/*.log。KubeSphere 使用 FluentBit 以 DemonSet 形式在各集群节点上采集日志,由 FluentBit 输出给 ElasticSearch 服务。具体配置可参考如下两个配置:
$ kubectl get Input -n kubesphere-logging-system tail -o yaml
$ kubectl get Output -n kubesphere-logging-system es -o yaml
我们把日志导出到第三方日志服务,那就需要定制 FluentBit 输入输出。使用 tail 插件采集 /var/log/containers/flux-wms-*.log 文件中的日志,输出到 Kafka 中。可参考如下配置:

---
apiVersion: logging.kubesphere.io/v1alpha2
kind: Input
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: "true"
name: kafka-flux-wms
namespace: kubesphere-logging-system
spec:
tail:
db: /fluent-bit/tail/pos.db
dbSync: Normal
memBufLimit: 5MB
path: /var/log/containers/flux-wms-*.log
refreshIntervalSeconds: 10
tag: fluxwms.*
---
apiVersion: logging.kubesphere.io/v1alpha2
kind: Output
metadata:
annotations:
kubesphere.io/creator: admin
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: "true"
name: kafka-flux-wms
namespace: kubesphere-logging-system
spec:
kafka:
brokers: xxx.xxx.xxx.xxx:9092
topics: my-topic
match: fluxwms.*
值得注意的是,目前 FluentBit 不支持 Kafka 认证。
多行日志的尴尬
原本以为至此就可万事大吉,没想到消费 kafka 日志时突然看到,某些日志被拆得七零八碎,不忍入目。为了支持多行日志,直观的想法,就是逐个组件往前排查。
前方有坑,请小心阅读。
配置 FluentBit 支持多行日志
FluentBit 对多行日志的支持,需要配置 Parser,并通过 parserFirstline 指定日志 Parser,用以解析出多行日志块的第一行。官方参考文档,Parser 正则表达式,根据 Filebeat 日志输出格式而定,可参考上文或直接看这段:string: '%{[log.file.path]} %{[message]}'。
---
apiVersion: logging.kubesphere.io/v1alpha2
kind: Input
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: "true"
name: kafka-flux-wms
namespace: kubesphere-logging-system
spec:
tail:
db: /fluent-bit/tail/pos.db
dbSync: Normal
memBufLimit: 5MB
path: /var/log/containers/flux-wms-*.log
multiline: true
parserFirstline: kafka-flux-wms
refreshIntervalSeconds: 10
tag: fluxwms.*
---
apiVersion: logging.kubesphere.io/v1alpha2
kind: Parser
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: "true"
name: kafka-flux-wms
namespace: kubesphere-logging-system
spec:
regex:
regex: '^\/data\/business-logs\/[^\s]*'
配置 Filebeat 支持多行日志
查看 kakfka 消息,多行日志仍然被拆分。难道 Filebeat 没有支持多行日志吗?整个落盘日志采集链条中,只要有一个环节不支持多行日志,就会导致结果不及预期。查看项目原始日志文件,发现多行日志以时间格式开头,于是 Filebeat 增加如下配置:
filebeat.inputs:
- type: log
enabled: true
paths:
{{range .Paths}}
- {{.}}
{{end}}
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.max_lines: 100
multiline.timeout: 10s
output.console:
codec.format:
string: '%{[log.file.path]} %{[message]}'
logging.level: warning
进入 Sidecar 容器,使用如下命令测试 Filebeat 输出,确认正确分割多行日志。
$ filebeat -c /etc/logsidecar/filebeat.yaml
不可忽视的容器运行时
按理说,FluentBit 和 Filebeat 都支持了多行日志,kafka 应该可以正确输出多行日志,但结果令人失望。肯定还有哪个环节被遗漏了,在登录集群节点主机查看容器标准输出日志时,这个被忽视的点被发现啦!
## 此处直接查看你的项目容器
$ tail -f /var/log/containers/*.log
你会发现,日志都是 JSON 格式,并且日志是逐行输出的,也就是说,没有支持多行日志块。本地 kubernetes 集群使用 Docker 作为容器运行时,来查看它的配置:
{
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 10,
"bip": "192.168.100.1/24",
"storage-driver": "overlay2",
"storage-opts": ["overlay2.override_kernel_check=true"]
}
log-driver配置为json-file, 这也是官方默认配置,可参考官方说明,除 json 格式外,还支持如下格式:
- local
- gelf
- syslog
- fluentd
- loki
显然其他格式也并不理想,而且对于生产环境,切换容器运行时日志格式,影响还是蛮大的。探索至此,这条路子难度偏大风险过高,暂时先搁置,待到身心惬意时接着玩。
去掉中间商,直达 kafka
既然上面的路子走不通,那就换个思路。Filebeat 也是 logging-agent,是支持输出日志到 Kafka 的,为何不省去中间环节,直奔主题呢?
$ kubectl edit cm -n kubesphere-logging-system logsidecar-injector-configmap
filebeat.inputs:
- type: log
enabled: true
paths:
{{range .Paths}}
- {{.}}
{{end}}
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.max_lines: 100
multiline.timeout: 10s
output.kafka:
enabled: true
hosts:
- XXX.XXX.XXX.XXX:9092
topic: sycx-cmes-app
## output.console:
## codec.format:
## string: '%{[log.file.path]} %{[message]}'
logging.level: warning
当看到 Kafka 消费者输出完美多行日志块时,脑后传来多巴胺的快感!再看一眼架构图,咱们来做总结!
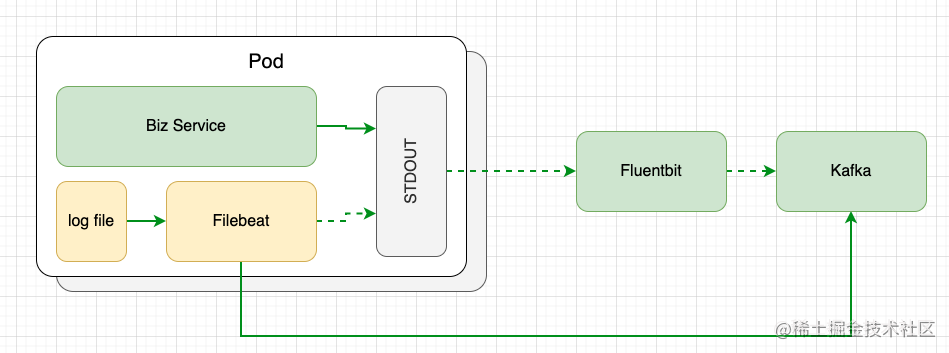
总结
最初我去 KubeSphere 社区论坛搜索日志采集相关帖子时,有朋友说无法实现。看到他的回复,心底一阵绝望。如今看来,某种角度上说,他的回答没错,他只是说那条路走不通,但他没说那条路能走通。
本文由博客一文多发平台 OpenWrite 发布!
KubeSphere 多行日志采集方案深度探索 的更多相关文章
- Filebeat+Kafka+Logstash+ElasticSearch+Kibana 日志采集方案
前言 Elastic Stack 提供 Beats 和 Logstash 套件来采集任何来源.任何格式的数据.其实Beats 和 Logstash的功能差不多,都能够与 Elasticsearch 产 ...
- docker容器日志收集方案汇总评价总结
docker日志收集方案有太多,下面截图罗列docker官方给的日志收集方案(详细请转docker官方文档).很多方案都不适合我们下面的系列文章没有说. 经过以下5篇博客的叙述简单说下docker容器 ...
- ELK日志系统之通用应用程序日志接入方案
前边有两篇ELK的文章分别介绍了MySQL慢日志收集和Nginx访问日志收集,那么各种不同类型应用程序的日志该如何方便的进行收集呢?且看本文我们是如何高效处理这个问题的 日志规范 规范的日志存放路径和 ...
- kubernetes常见日志采集问题和解决方案分析
传统日志与kubernetes日志对比 传统服务 目录固定 重启不会丢失 不用关注标准与错误日志输出 容器服务 节点不固定 重启服务会漂移 需要关注标准与错误日志输出 日志文件重启会丢失 日志目录不固 ...
- K8S学习笔记之filebeat采集K8S微服务java堆栈多行日志
0x00 背景 K8S内运行Spring Cloud微服务,根据定制容器架构要求log文件不落地,log全部输出到std管道,由基于docker的filebeat去管道采集,然后发往Kafka或者ES ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- vivo大数据日志采集Agent设计实践
作者:vivo 互联网存储技术团队- Qiu Sidi 在企业大数据体系建设过程中,数据采集是其中的首要环节.然而,当前行业内的相关开源数据采集组件,并无法满足企业大规模数据采集的需求与有效的数据采集 ...
- Delphi深度探索-CodeSite应用指南
Delphi深度探索-CodeSite应用指南 Delphi虽然为我们提供极其强大的调试功能,查找Bug仍然是一项艰巨的工作,通常我们写代码和调试代码的所消耗的时间是大致相同的,甚至有可能更多.为了减 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 拾遗与填坑《深度探索C++对象模型》3.2节
<深度探索C++对象模型>是一本好书,该书作者也是<C++ Primer>的作者,一位绝对的C++大师.诚然该书中也有多多少少的错误一直为人所诟病,但这仍然不妨碍称其为一本好书 ...
随机推荐
- 【转载】 tf.slice()介绍
原文地址: https://blog.csdn.net/nini_coded/article/details/79852031 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议, ...
- Jax计算框架的JIT编译的static特性
官方: https://jax.readthedocs.io/en/latest/notebooks/thinking_in_jax.html#jit-mechanics-tracing-and-st ...
- git clone 如何通过proxy进行远程代码仓库拷贝下载
git使用proxy的方式和ssh的情况是差不多的,给出借鉴: SSH如何通过proxy进行服务器连接 ------------------------------------------------ ...
- 推荐一款.NET开源、功能强大的二维码生成类库
前言 在日常开发需求中,生成二维码以分享文本内容或跳转至指定网站链接等场景是比较常见的.今天大姚给大家分享一款.NET开源(MIT License).免费.简单易用.功能强大的二维码生成类库:QrCo ...
- python学习之---迭代器与生成器
什么是迭代器 可迭代对象: 可以通过for循环来实现遍历,例如list.string.dict 迭代器: 不仅可以使用for循环,还可以使用next()方法.__iter__() next():获取容 ...
- Problem - 616C - Codeforces
Problem - 616C - Codeforces C. The Labyrinth 如果是直接对\(*\)去跑dfs或者bfs的话无疑是会超时的 既然如此,那我们可以去对 \(.\) 跑搜索,将 ...
- 仿MFC的消息印射(全局函数的实现)
//弄了个仿MFC消息映射,这是全局函数都好弄,照着MFC就弄出来了,//在vs2017上可以通过#include <windows.h> #include "resource. ...
- java_GUI_监听事件关闭窗口_AWT
package Panel;import java.awt.*;import java.awt.event.WindowAdapter;import java.awt.event.WindowEven ...
- 带你了解 WebAssembly 的发展、应用与开发
一.WebAssembly 是什么? "WebAssembly(缩写为 Wasm)是一种基于堆栈式虚拟机的二进制指令集.Wasm 被设计成为一种编程语言的可移植编译目标,并且可以通过将其部署 ...
- uni-app之camera组件-人脸拍摄
小程序录制视频:10-30秒:需要拍摄人脸,大声朗读数字(123456)这种. 1.camera组件 camera页面内嵌的区域相机组件.注意这不是点击后全屏打开的相机 camera只支持小程序使用: ...