「DIARY」PKUSC2021 小结
另外有一个纯吐槽游记版本的,还没有写完(快写完了,真的)
欢迎各路神仙来吐槽一个菜鸡的考场思路
# Day1 考场小结
总体而言,T1 完全就是送分,做得也挺快的;T2 大概是本场最难的题;然后 T3 靠码量和细节最后加上一些小优化,成功地成为了压轴题,虽然正解确实恶心,但是看起来前两个部分分应该可做(但是我没有写出来第二个部分分)。
- Day1 T1
点击展开/折叠 题意
给定 $n\times n$ 的矩阵 $A$,定义 $f(A)=B$,其中 $b_{i,j}=\sum_{k=1}^na_{i,k}+a_{k,j}$。求
$$
\underbrace{f(f(\cdots f}_{t\text{ 个 }f}(A)))
$$
计算在模 $m$ 意义下进行。
$n\le 5000$(记不住了,反正就是要求 $\mathcal O(n^2)$),$t\le10^9$。
一看 \(t\) 这么大,不是结论就是要矩阵加速。
先观察一次变换 \(f(A)=B\),\(b_{ij}\) 是第 \(i\) 行的和 \(R_i\) 和第 \(j\) 列的和 \(C_j\) 之和。于是我们只需要求解 \(R_{1\sim n},C_{1\sim n}\) 这样 \(\mathcal O(n)\) 个变量就可以求得 \(B\) 矩阵了。
初步判断为矩阵加速,然后考虑 \(A\) 进行变换得到的 \(B\) 的第 \(i\) 行之和 \(R_i'\) 和第 \(j\) 列之和 \(C'_j\) 的式子,记 \(S\) 为 \(A\) 中所有元素的和:
\]
\(C_j\) 也是差不多的式子,这提示我们考虑 \(S\) 的变化,记 \(S'\) 为 \(B\) 中所有元素的和:
\]
所以可以矩阵加速:
\]
注意到对于 \(R_i,C_j\),中间的转移矩阵 \(T\) 都是一模一样的,可以直接算出 \(T^t\),算 \(R_i,C_j\) 只需进行一次矩阵乘法。复杂度 \(\mathcal O(n^2+\log t)\)。
总共用了 30min 做这道题,做得应该还算顺利。
- Day1 T2
点击展开/折叠 题意
给定序列 $\{a_n\}$,$q$ 次操作,类型如下
- 给定 $l,r$,从小到大枚举 $i$ 从 $l$ 到 $r-1$,修改 $a_i$ 为 $\max\{a_i,a_{i+1}\}$;
- 给定 $l,r$,贪心地求 $[l,r]$ 中严格上升子序列的元素之和(即如果当前元素严格大于当前上升子序列的末尾,就把它加入上升子序列)。
下面列一些我记得住的部分分:
- $n,q\le3\times10^3$;
- 对每个 1 操作,$l=1, r=n$;
- $n,q\le3\times10^5$。
\(\mathcal O(nq)\) 的大模拟就不说了。
然后对正解没什么思路,就想 \(l=1,r=n\) 的部分分,即每次修改都包括全局。
观察可得,元素 \(a_i\) 被操作若干次后会变成其后方第一个比它大的值。将这样的变化关系建出一棵带边权的树——
- \(a_i\) 向其后方第一个严格大于它的元素连边;
- 边的权值为两个元素之间的距离;
- 若 \(a_i\) 后方没有比它大的数,就连向一个虚拟节点,边权 \(+\infty\)。
这棵树可以看作以虚拟节点为根。
这棵树的最大作用是快速计算 \(a_i\) 现在会变成哪个数。记当前进行了 \(t\) 次全局操作,\(a_i\) 会变为「从 \(a_i\) 向上爬 \(t\) 的距离,能够到达的深度最浅的元素」。倍增即可 \(\mathcal O(\log n)\) 计算。
当时想到这里,思路就有点卡顿。主要的问题是「答案是树上从 \(a_l\) 一直向上跳,不超过 \(r\) 的树链上的所有元素之和;而进行一次修改后,树的形态会变化,有一些元素直接“消失”了」,这样就很难维护。
后来发现没有必要动态维护每次修改过后的树——原始序列的树具有比较优美的性质。
「结论」
记 $f(u,s)$ 是 $u$ 向上爬 $s$ 的距离,能到达的深度最浅的点;记 $t$ 是当前全局修改的次数。
对于一次询问 $(l,r)$,求出 $l$ 沿树边向后跳且不超过 $r$,最远能跳到的点 $p$。则答案为 $f(l,t)$ 到 $f(p,t)$ 这条树链上的元素之和。
链尾为 $f(p,t)$ 非常好理解,就是原来的链尾向后 $t$ 的距离,关键是 $f(l,t)$。考虑原本答案是 $l$ 到 $p$ 这样一条上升子序列,经过 $t$ 次变化后,**只会有** $\mathbf{l}$ **到** $\mathbf{f(l,t)}$ **之前的元素** 会从答案中消失。
其实考场上没想这么多,感觉很有道理,写了过了样例就交,反正 PKUSC 能看到结果。
- Day1 T3
感谢出题人教我打德州扑克,请问考试的时候能和旁边的同学打一把模拟一下吗?
点击展开/折叠 题面
德州扑克共有 $13$ 种牌值 2~9, T, J, Q, K, A,以及 $4$ 种花色 0~3。
牌值的大小排序为 2 < 3 < ... < 9 < T < J < Q < K < A。
一个牌组由 $5$ 张牌构成,按下述规则分类:
- 同花顺:$5$ 张牌的花色相同,且是「顺子」(见下);
- 四条:存在 $4$ 张牌值相同的牌;
- 葫芦:存在 $3$ 张牌值相同的牌,剩下的两张牌的牌值也相同;
- 同花:$5$ 张牌的花色相同;
- 顺子:$5$ 张牌的牌值连续,特殊地,认为
A, 2, 3, 4, 5是顺子; - 三条:存在三张牌值相同的牌,且剩下两张牌牌值与其他牌都不同;
- 两对:存在两对牌值相同的牌,且不满足之前其他类型;
- 对子:存在一对牌值相同的牌,且不满足之前其他类型;
- 高牌:不满足上述所有类型的牌组。
两套牌组 $A,B$ 的比较方式如下:
- 若 $A,B$ 类型不同,则类型编号较小的牌组更大;
- 若 $A,B$ 都是同花顺或顺子,取其顺子的开头元素,按照
A < 2 < 3 < ... < 9 < T < J < Q < K的方式比较大小; - 若 $A,B$ 同为非同花顺和顺子的其他类型,分别将 $A,B$ 中的牌安装 `(出现次数, 牌值)` 从大到小排序,然后按照牌值比较字典序大小。
一个场面由 $7$ 张牌组成。从一个场面中任取 $5$ 张牌构成牌组,其中最大的一个牌组可以“代表”这个场面。
A, B 两人进行简化版的德州扑克,先将牌随机打乱,初始池中有 $2w$ 枚筹码,A,B 两人各持有 $m$ 枚筹码。游戏共 $4$ 轮:
- A, B 从牌堆中各取 $2$ 张牌并公开,两人进行决策(决策定义见下),若 B 不弃权,进入下一轮;
- 从牌堆中取出 $3$ 张牌公开,两人进行决策,若 B 不弃权,进入下一轮;
- 从牌堆中取出 $1$ 张牌公开,两人进行决策,若 B 不弃权,进入下一轮;
- 从牌堆中取出 $1$ 张牌公开;A,B 各自的场面由第一轮中自己抽到的 $2$ 张牌、以及之后公开的 $5$ 张牌构成,场面较大的一人获得池中所有筹码,若场面等大,则两人平分筹码池。
“两人决策”指「A 从自己持有的筹码中拿 $i$ 个放入筹码池($i$ 不超过当前持有筹码数),B 选择“继续”或“弃权”:若“继续”,则 B 也放入 $i$ 个筹码;若“弃权”,则 B 不需要放入筹码,游戏直接结束,A 获得池中全部筹码。」
A,B 都绝对聪明,且希望最大化游戏结束时自己的筹码期望数量。
此时 A,B 已经进行到第 $t$ 轮,即前 $t-1$ 轮 B 没有弃权,且你知道前 $t$ 轮已公开的牌以及 A,B 在第一轮中抽到的牌。以最简分数形式输出 A 在结束时的筹码期望数量。
部分分:$t=3$;$t=2$;$t=1$。
建议把「牌组」写一个结构体,实现两个牌组的比较,时间复杂度是一个较大的常数。
对于一个场面,只有 \(\binom 75=21\) 种牌组,直接暴搜找到最大的一个牌组即可。
当 \(t=3\),我们只需要判断 B 是否会弃权。不妨假设不会,则枚举第四轮公开的牌,每张未出现的牌概率相等,直接计算出 A, B 各自期望筹码数 \(a,b\)。如果 B 弃权,则 B 的筹码数为 \(m\),如果 \(b\lt m\),则 B 会弃权,答案为 \(m+2w\),否则答案为 \(a\)。
当 \(t=2\),需要决策两次。不过只需要判断第二轮 B 是否弃权后就转化为 \(t=3\) 的问题。仍然假设 B 不弃权,枚举下一张牌是什么,然后转化为 \(t=3\) 的问题用上述方法计算,从而得到 A, B 各自期望筹码数 \(a,b\)。同样比较 \(b\) 和 \(m\) 的大小判断是否弃权。
有一点卡,之前 TLE 了几发,后来发现 A,B 各自的场面只有最后两张牌是不确定的,只有 \(52\times52\) 种场面,可以把它们对应的最大牌组记忆化下来。这样就跑得飞快,飞快地 Wa 了 QwQ
调到最后都不知道怎么回事。
- Day1 再总结
T1 这种该切的题切得比较快,是比较好的。
T2 看了题解,的确在能力范围之内,但是不一定能够在考场上想出来,所以拿一个较高的部分分也足够了。
T3 比较遗憾,全场花时间最多的一道题,如果能过掉第二个部分分就可以多 41 分(说不定可以免面试了?),还是代码实现细节的问题。
# Day2 考场小结
应该还是比 Day1 要难一些吧,不过倒是挺谢谢出题人留了一道签到题。T1 把该送的分都送了,T2 就开始人类智慧,T3 看到实数集就完全不会,尝试暴力推 \(n=3\) 的积分不知道哪里推错了。
- Day2 T1
点击展开/折叠 题面
给定一棵 $n$ 个点的树,两类问题:
- 求所有点对 $(u,v)$($u\lt v$)的距离和;
- 断掉一条边后连接一条边,得到树 $T'$,求所有断边连边的方案得到的 $T'$ 做第一个问题的答案之和。
输出对质数取模。
数据规模:$n\le10^5$。
考虑经典的「计算边的贡献」的方法。
第一问直接算,第二问考虑枚举断哪条边。断开后记两个连通块为 \(A,B\),新连接的边一定在 \(A,B\) 之间,新边的贡献为 \(|A|\times|B|\)。考虑连接一条边过后,对其他某一条原本就有的边 \(e\) 的贡献的影响。
不妨设“原本就有的边 \(e\)”在 \(A\) 中,记该边把 \(A\) 分成 \(A_1,A_2\) 两部分。若新边连接 \(A_1,B\),共有 \(|A_1|\times|B|\) 种连法,\(e\) 的贡献为 \(|A_2|\times\big(|A_1|+|B|\big)\),总的贡献为 \(|A_1|\times|A_2|\times|B|\times(|A_1|+|B|)\);若新边连接 \(A_2,B\) 是同样的道理,总的贡献为 \(|A_1|\times|A_2|\times|B|\times\big(|A_2|+|B|\big)\)。
&|A_1|\times|A_2|\times|B|\times(|A_1|+|B|)+|A_1|\times|A_2|\times|B|\times\big(|A_2|+|B|\big)\\
=&|A_1|\times|A_2|\times|B|\times\big(|A_1|+|A_2|+2|B|\big)\\
=&|B|\times\big(|A|+2|B|\big)\times|A_1|\times\big(|A|-|A_1|\big)
\end{aligned}
\]
记枚举的断开的边为 \((u,v)\),\(u\in A,v\in B\),那么 \(|A|,|B|\) 都是常数。把 \(u\) 提为 \(A\) 子树的根,不妨设 \(A_1\) 是一棵子树,于是我们只需要维护「子树大小之和」以及「子树大小的平方的和」,这个换根DP可以解决。
复杂度 \(\mathcal O(n)\)。
式子推起来行云流水,半个小时做出来,感觉和 Day1 差不多。
- Day2 T2
点击展开/折叠 题面
食堂在搞活动,对于金额为 $a$ 的菜品,可怜可以用 $b$($b\le a$)张代金券,且可怜不能预支代金券,支付 $a-b$ 的现金并获得 $\lfloor\frac{a-b}{c}\rfloor$ 张代金券,其中 $c$ 为常数。
可怜有计划依次吃 $a_1,a_2,\cdots,a_n$ 金额的菜品,还有 $q$ 次修改,每次令 $a_x=y$。对于初始状态和每次修改后,求可怜吃完这些菜至少需要支付的金额。
我记得的部分分:
- $n,q\le50, a_i\le100$;
- $n,q\le10^3$;
- $c=1$;
- $c=2$;
- 对于全部数据,$n,q\le10^5$,$c\le10^9$,在任意时刻都有 $a_i\le10^{12}$。
显然,这是一道贪心题。但是贪心题的算法很容易假,我们不如先写一个 \(\mathcal O(qna_i^2)\) 的 DP,即已经吃了 \(i\) 份菜(\(i\le n\)),持有 \(j\) 张代金券(\(j\le na_i\))的最小花费。转移直接枚举使用的代金券数目(\(\mathcal O(a_i)\))。
首先,菜品的总价格是一定的,相当于我们要最大化使用的代金券数量。
先不考虑最后代金券用不完的情况,我们希望尽可能多得代金券。不难发现对价格为 \(a\) 的菜品,使用不超过 \(a-\lfloor\tfrac ac\rfloor\) 的代金券,获得的代金券数目不变。因此在不超过 \(a-\lfloor\tfrac ac\rfloor\) 时,我们会尽可能多用代金券。
但是如果我们得到的代金券太多了,以至于最后还会剩很多,那也非常浪费,说明我们应该在之前多用一些代金券。之后能够使用的代金券最大数量即为剩下的菜品的 \(a_i\) 之和。
(下面这个贪心不知道哪里错了,不要当成正解了)
我的策略是「当第一次发现按照“最大化获得代金券数量”的策略支付,当前拥有的代金券会用不完时,就在“保证之后的菜品能够完全用支付券支付”的前提下,在当前菜品尽可能多用」。
这样可以 \(\mathcal O(nq)\) 解决问题。但是我不知道哪里错了,而且一时没有更好的思路,于是就把剩下的时间拿去刚 T3 了。
- Day2 T3
点击展开/折叠 题面
在 $[0,m]$ 的数轴上随机点 $n$ 个实数点,求不存在包含超过 $2$ 个点的长度为 $k$ 的区间的概率。答案对 $998244353$ 取模。
我记得的部分分:
- $n\le3$;
- $n\le10$;
- 对于全部数据,$n\le50$,$1\le k\le m\le150$。
看到实数范围直接放弃思考,只想了 $n=3$ 怎么做。
设前两个点的坐标分别为 \(i,j\)(不妨设 \(i\lt j\)),考虑第三个点能放的区间的长度:
m&i+k\lt j\\
\max\{0,j-k\}+\max\{0,m-i-k\}&i+k\ge j
\end{cases}
\]
然后分类讨论 \(2k\) 和 \(m\) 的大小,可以用平面直角坐标系清晰地表示分类的准则:
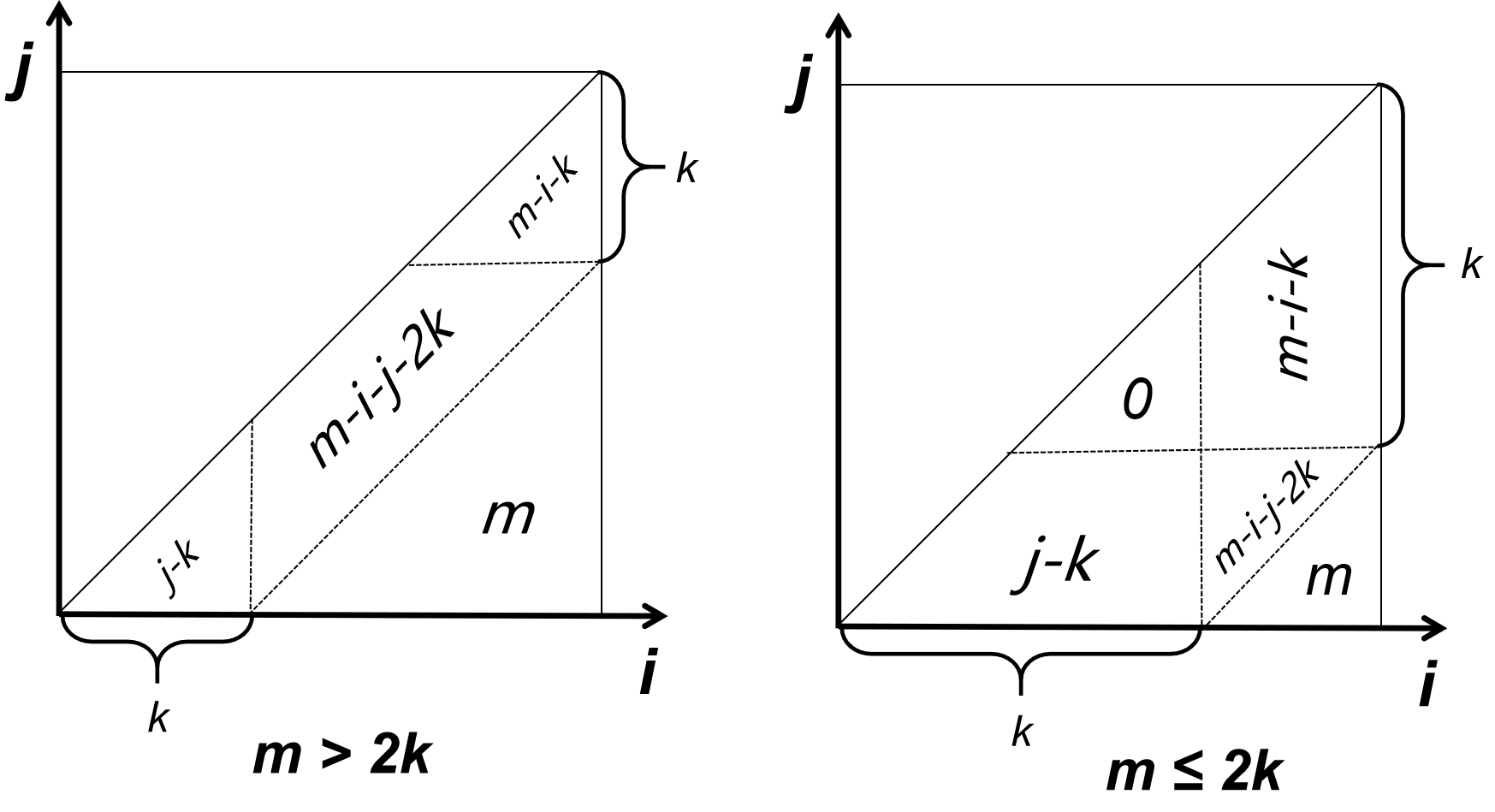
应该可以直接积分,但是大概是我积分不太熟练,不知道哪里推错了。
- Day2 再总结
两天的 T1 都非常顺利,开了个好头。
T2 先写暴力 DP 是正确的,但是之后在难度判断上有失误,说不定再改改能把贪心改对。
T3 用的时间太久了,而且没有把握。积分之类的还是运用得太少了,推导费时且容易出错。推了一页草稿纸没推出来的时候就应该回去再想想 T2 了。
# 后记
好家伙,怎么一写就写了这么长……一个晚自习就差不多过去了。
说起来两天都能(相比起其他人)迅速地切掉 T1 还是挺开心的,大概我更熟悉比较简单的题吧。但是毕竟题目难度是有梯度的,去年 NOI Day2 对我而言好像也没有签到题,对于难题的处理还是有些后劲不足。
Day3 去面试,感觉和面试官聊得挺开心的(结营仪式上发现两位面试官一个是校长,一个是院副主任,瑟瑟发抖)。大概也确实给面试官留下了比较深刻的印象吧,最后还是如愿以偿,拿到了所谓的一等约。(说起来 PKUSC 的评级太隐晦了 awa,什么优异优秀良好,拿到证书的时候一脸懵)
「DIARY」PKUSC2021 小结的更多相关文章
- spring cloud 入门,看一个微服务框架的「五脏六腑」
Spring Cloud 是一个基于 Spring Boot 实现的微服务框架,它包含了实现微服务架构所需的各种组件. 注:Spring Boot 简单理解就是简化 Spring 项目的搭建.配置.组 ...
- 从 Spring Cloud 看一个微服务框架的「五脏六腑」
原文:https://webfe.kujiale.com/spring-could-heart/ Spring Cloud 是一个基于 Spring Boot 实现的微服务框架,它包含了实现微服务架构 ...
- 从 Spring Cloud 看一个微服务框架的「五脏六腑」(转)
Spring Cloud 是一个基于 Spring Boot 实现的微服务框架,它包含了实现微服务架构所需的各种组件. 本文将从 Spring Cloud 出发,分两小节讲述微服务框架的「五脏六腑」: ...
- 「MoreThanJava」机器指令到汇编再到高级编程语言
「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」. 当然 ...
- 「MoreThanJava」Java发展史及起航新世界
「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」. 当然 ...
- Python后端日常操作之在Django中「强行」使用MVVM设计模式
扫盲 首先带大家了解一下什么是MVVM模式: 什么是MVVM?MVVM是Model-View-ViewModel的缩写. MVVM是MVC的增强版,实质上和MVC没有本质区别,只是代码的位置变动而已 ...
- 「译」JUnit 5 系列:条件测试
原文地址:http://blog.codefx.org/libraries/junit-5-conditions/ 原文日期:08, May, 2016 译文首发:Linesh 的博客:「译」JUni ...
- 「译」JUnit 5 系列:扩展模型(Extension Model)
原文地址:http://blog.codefx.org/design/architecture/junit-5-extension-model/ 原文日期:11, Apr, 2016 译文首发:Lin ...
- JavaScript OOP 之「创建对象」
工厂模式 工厂模式是软件工程领域一种广为人知的设计模式,这种模式抽象了创建具体对象的过程.工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题. function createPers ...
- 「C++」理解智能指针
维基百科上面对于「智能指针」是这样描述的: 智能指针(英语:Smart pointer)是一种抽象的数据类型.在程序设计中,它通常是经由类型模板(class template)来实做,借由模板(tem ...
随机推荐
- pycharm、pyqt5、pyuic、anaconda配置界面
转载一篇很棒的文档,讲解的是如何在pycharm里面使用QT desiger勾画界面并且将相应的界面转化成py文件 https://www.jianshu.com/p/8b992e47a0e4 个人 ...
- python 成功解决import librosa出错问题
在做音频处理时,用到了librosa这个库,但是一直在报错,一开始以为代码错误,后来发现import的时候就已经出错了. 我给他卸载了重新安装,结果是一样的,报错如下: Traceback (most ...
- 软件工程日报二——gradle的安装与环境配置
昨天下载了android studio 今天想要进行学习的时候,发现还需要下载gradle 一.进入官网,https://gradle.org/,点击下载 二.进入下载界面 三.选择相应的版本,点击b ...
- 27_wbpack_自定义Plugin
Tapable 要想学会自定义Plugin就要先了解Tapable这个库 在我们的wbpack中有两个非常重要的两个类Compiler和Compilation 他们是通过注入插件的方式,来监听webp ...
- 我们后端代码这样子设置虽然这样子返回的是字符串,但是json字符串也是字符串
我们后端代码这样子设置虽然这样子返回的是字符串 但是json字符串也是字符串,后端如果想接收的话,直接百度下怎么接收json字符串就行
- http 1.0、2.0、3.0 之间的区别
首先是HTTP协议: HTTP 是 HyperText Transfer Protocol(超文本传输协议)的缩写,它是互联网上应用最为广泛的一种网络协议,所有 WWW 文件都必须遵守这个标准.其他的 ...
- vscode中使用powershell显示分支名
https://blog.csdn.net/weixin_43932597/article/details/125000557 windows powershell(或windows terminal ...
- idea插件Tranlation配置有道搜索引擎
idea配置有道翻译引擎 一.更换翻译引擎原因 由于Google在2022年9月末宣布关闭GoogleTranslate在中国的服务,原本在chrome浏览器和idea上使用的google翻译引擎也不 ...
- SQL执行定时任务JOB,包教包会
什么是JOB? 数据库中可以定时执行任务的功能组件,那就是JOB. JOB的作用 它可以按我们设置好的参数定时执行查询语句或存储过程,特别适合一些每天,每周,每月,每年这种需要循环执行任务的场景,当然 ...
- ubuntu20.04系统中扩展swap分区
1.首先停止/swapfile #swapon /swapfile 2.删除以前的/swapfile #rm -rf swapfile 3.创建新的/swapfile(以2G为例) #dd if=/d ...