Nvidia Tensor Core初探
1 背景
2 硬件单元
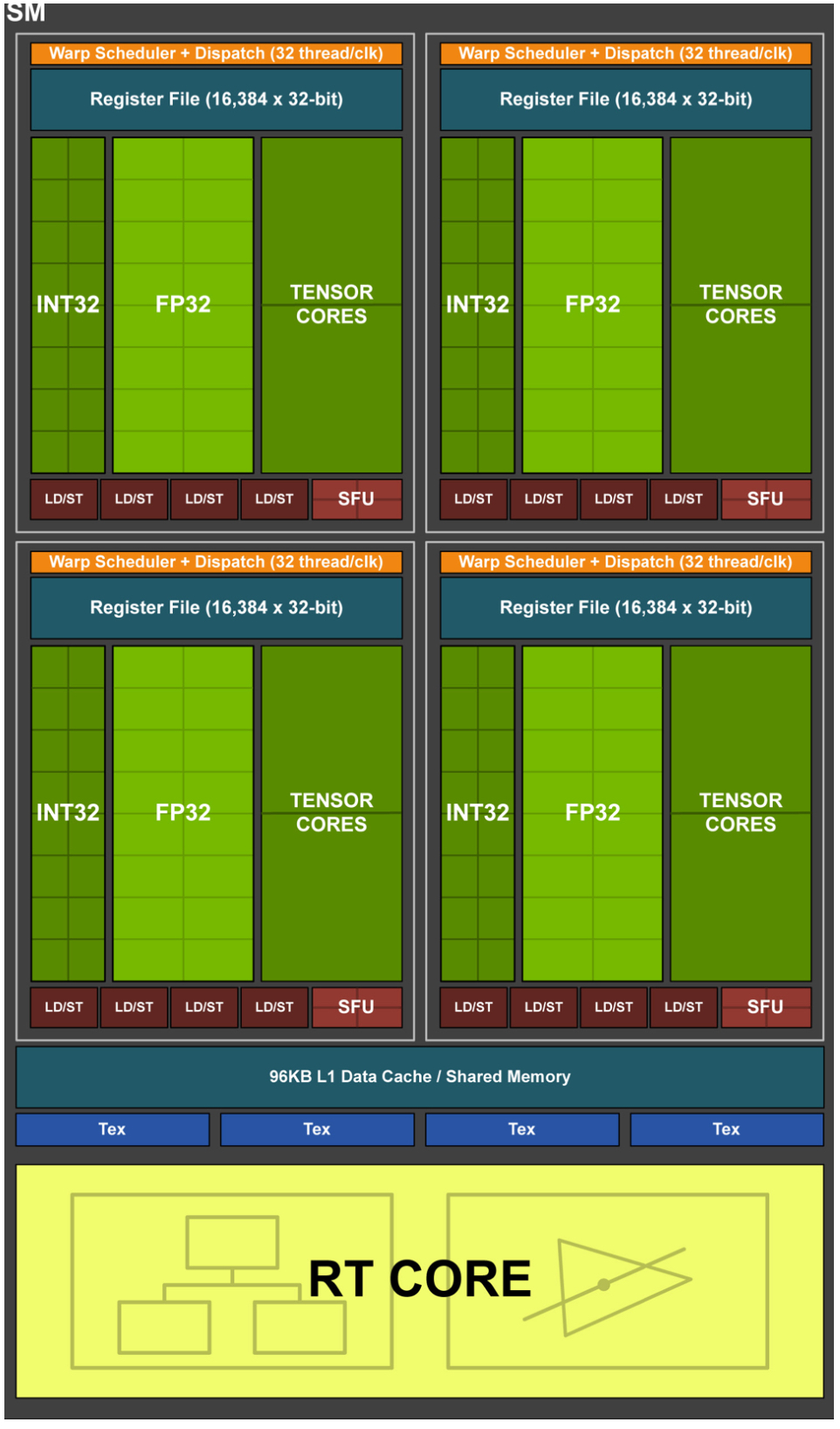
3 架构
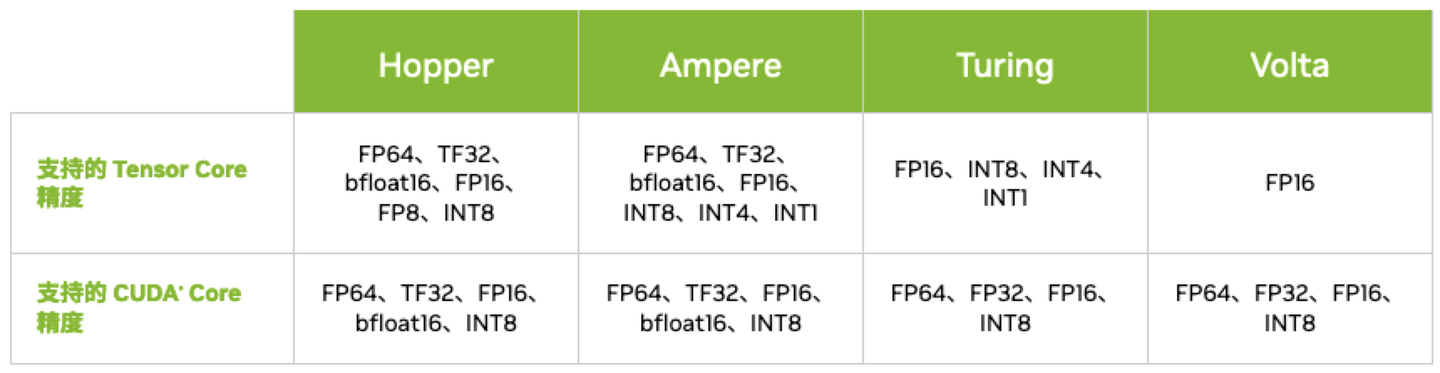
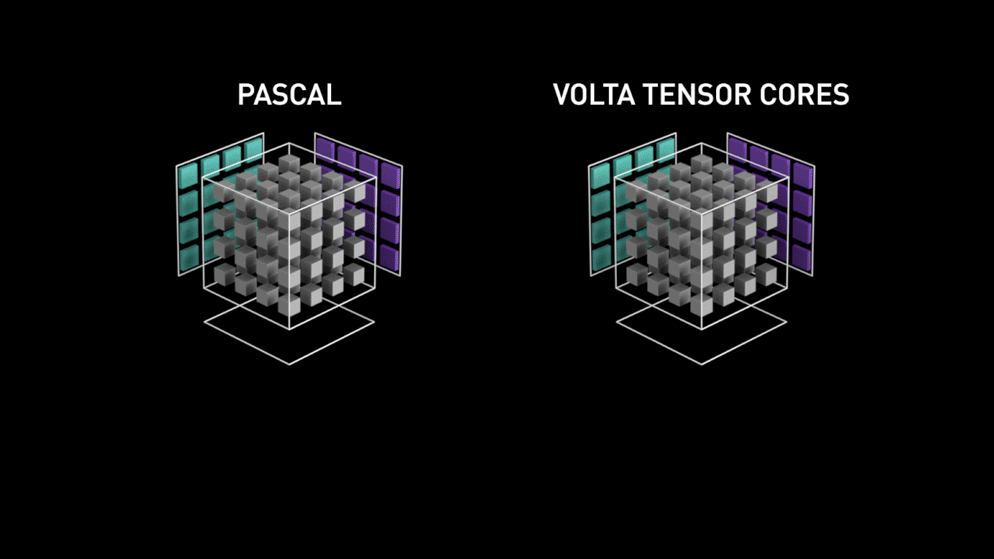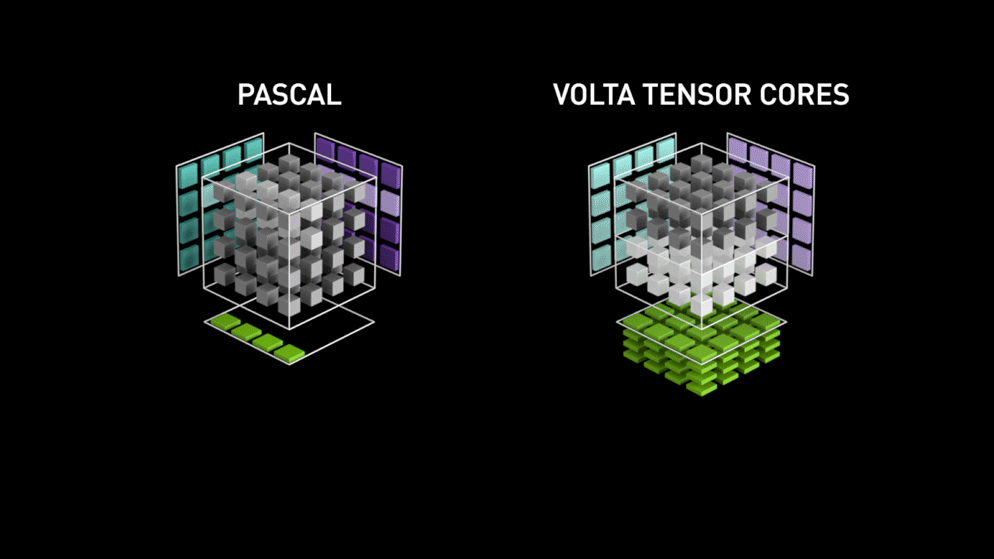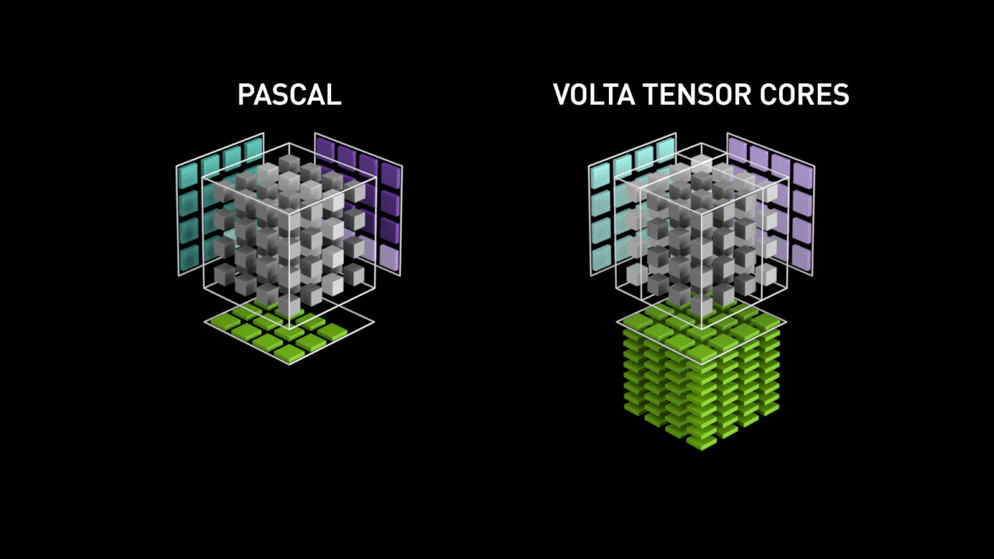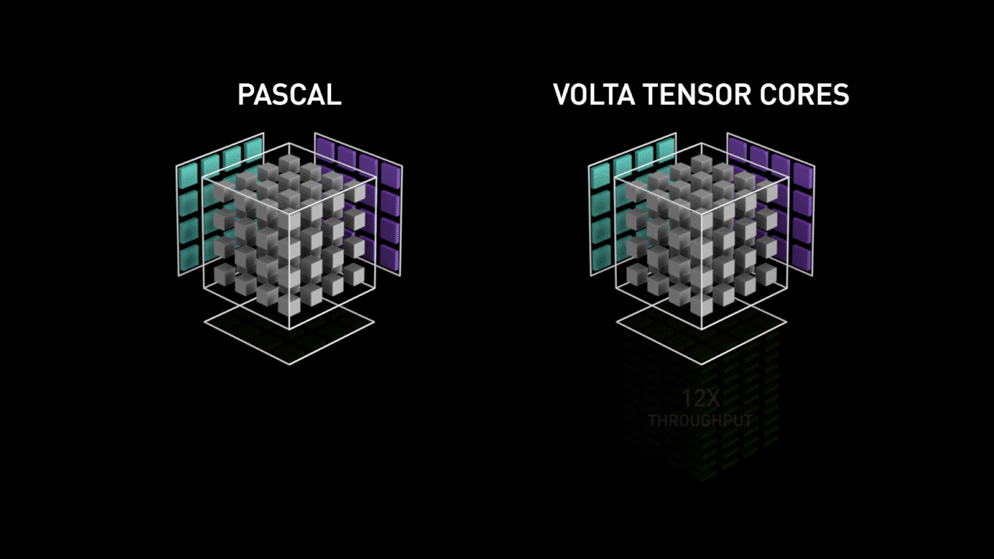
3.1 Volta Tensor Core
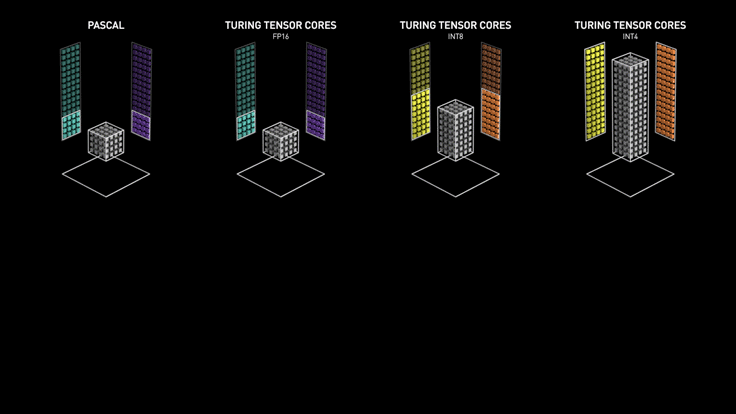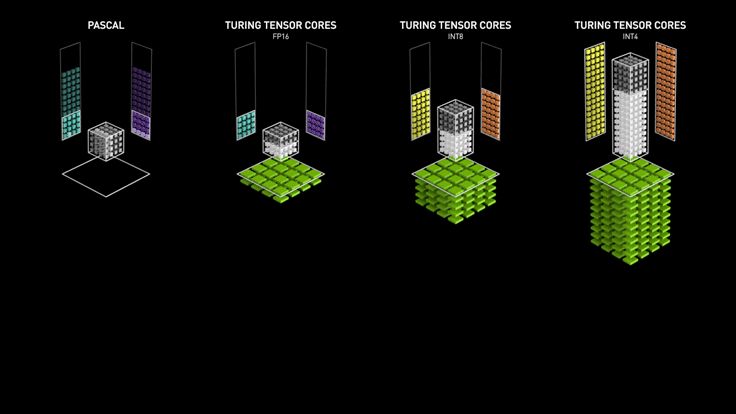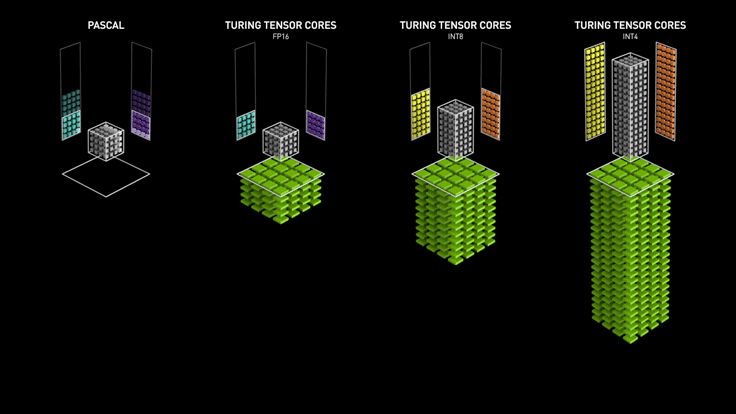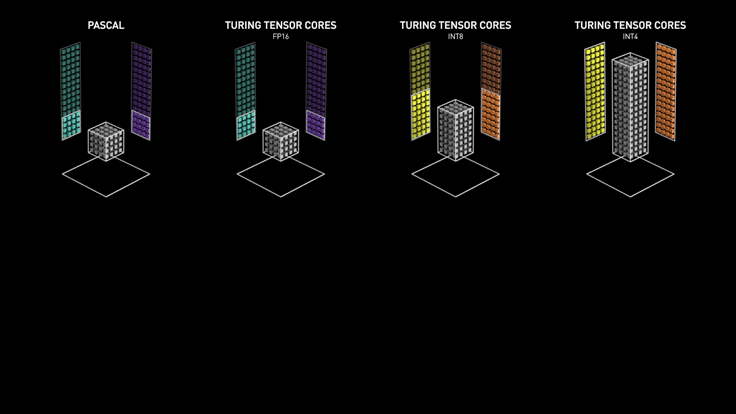
3.2 Turing Tensor Core
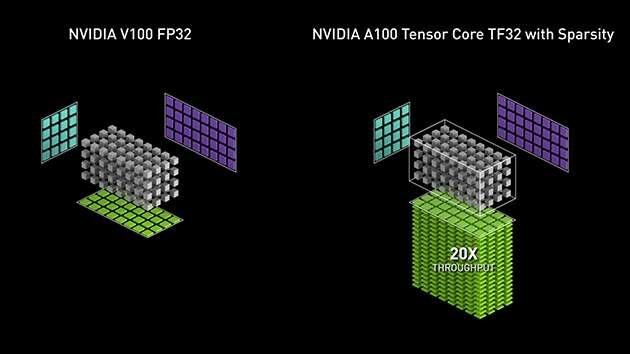
3.3 Ampere Tensor Core
3.4 Hopper Tensor Core

4 调用
4.1 WMMA (Warp-level Matrix Multiply Accumulate) API
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment; void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
- fragment:Tensor Core数据存储类,支持matrix_a、matrix_b和accumulator
- load_matrix_sync:Tensor Core数据加载API,支持将矩阵数据从global memory或shared memory加载到fragment
- store_matrix_sync:Tensor Core结果存储API,支持将计算结果从fragment存储到global memory或shared memory
- fill_fragment:fragment填充API,支持常数值填充
- mma_sync:Tensor Core矩阵乘计算API,支持D = AB + C或者C = AB + C
4.2 WMMA PTX (Parallel Thread Execution)
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;
- wmma.load:Tensor Core数据加载指令,支持将矩阵数据从global memory或shared memory加载到Tensor Core寄存器
- wmma.store:Tensor Core结果存储指令,支持将计算结果从Tensor Core寄存器存储到global memory或shared memory
- wmma.mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.3 MMA (Matrix Multiply Accumulate) PTX
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
- ldmatrix:Tensor Core数据加载指令,支持将矩阵数据从shared memory加载到Tensor Core寄存器
- mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.4 SASS
Nvidia Tensor Core初探的更多相关文章
- NVIDIA Tensor Cores解析
NVIDIA Tensor Cores解析 高性能计算机和人工智能前所未有的加速 Tensor Cores支持混合精度计算,动态调整计算以加快吞吐量,同时保持精度.最新一代将这些加速功能扩展到各种工作 ...
- NVIDIA深度学习Tensor Core性能解析(下)
NVIDIA深度学习Tensor Core性能解析(下) DeepBench推理测试之RNN和Sparse GEMM DeepBench的最后一项推理测试是RNN和Sparse GEMM,虽然测试中可 ...
- NVIDIA深度学习Tensor Core性能解析(上)
NVIDIA深度学习Tensor Core性能解析(上) 本篇将通过多项测试来考验Volta架构,利用各种深度学习框架来了解Tensor Core的性能. 很多时候,深度学习这样的新领域会让人难以理解 ...
- Tensor Core技术解析(下)
Tensor Core技术解析(下) 让FP16适用于深度学习 Volta的深度学习能力是建立在利用半精度浮点(IEEE-754 FP16)而非单精度浮点(FP32)进行深度学习训练的基础之上. 该能 ...
- Tensor Core技术解析(上)
Tensor Core技术解析(上) NVIDIA在SIGGRAPH 2018上正式发布了新一代GPU架构--Turing(图灵),黄仁勋称Turing架构是自2006年CUDA GPU发明以来最大的 ...
- 用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割 Accelerating Medical Image Segmentation with NVIDIA Tensor ...
- Asp.net Core 初探(发布和部署Linux)
前言 俗话说三天不学习,赶不上刘少奇.Asp.net Core更新这么长时间一直观望,周末帝都小雨,宅在家看了下Core Web App,顺便搭建了个HelloWorld环境来尝尝鲜,第一次看到.Ne ...
- jenkins部署net core初探
一步一步,小心翼翼吖.看了好几个博客,摸索了两天了,才搭建成功,不容易,先写篇文章记下来,hhhhhhhhhhhh 相关环境配置 服务器:centos7 源代码管理器:git 技术选型:net cor ...
- ASPNET CORE初探
ASP.NET Core 开发-中间件(Middleware) ASP.NET Core开发,开发并使用中间件(Middleware). 中间件是被组装成一个应用程序管道来处理请求和响应的软件组件 ...
- linux环境上运行.net core 初探
1.安装 .net core 环境 rpm --import https://packages.microsoft.com/keys/microsoft.ascsh -c 'echo -e " ...
随机推荐
- Arduino教程目录
目录 第一节.安装Arduino开发环境 第二节.第一个HelloWorld 第二节续.LED操作 呼吸灯 流水灯 正在加快制作,大家可以先看下面的视频了解基本语法,我准备基础课程和实际项目结合讲解. ...
- python 购物小程序
要求: 1.启动程序后,让用户输入预算,然后打印商品列表 2.允许用户根据商品编号购买商品 3.用户选择商品后,检测余额够不够,够就直接付款,不够就提醒 4.可随时退出,推出时打印已购买商品和余额 ...
- Web_Servlet之间请求转发
Servlet2 @WebServlet(urlPatterns = "/aa") public class JspService extends HttpServlet { pr ...
- SQL Server 分页问题
------------- SQL Server 1.使用row_number分页 declare @PageSize int = 5 declare @PageIndex int = 1 selec ...
- SSH、SFTP、FTP、Telnet、SCP、TFTP协议的原理
一.SSH协议1.什么是SSH?SSH全称 安全外壳协议(Secure Shell),,是一种加密的网络传输协议,可在不安全的网络中为网络服务提供安全的传输环境. 如果一个用户从本地计算机,使用SSH ...
- python3判断ip类型
利用socket库附带的校验功能实现校验.
- C#向其实进程子窗体发送指令
近日,想在自己的软件简单控制其它软件的最大化最小化,想到直接向进程发送指令,结果一直无效,经过Spy++发现,原来快捷方式在子窗体上,所以需要遍历子窗体在发送指令,以下为参考代码: 1 [DllImp ...
- PHP 计算一个月第一天和最后一天
$fistday= date('Y-m-1 23:59:59'); $lastday= strtotime("$fistday+1 month -1 day");
- ffmpeg+nginx+hls(低延迟)
先看一下我参考的原文实现: 实现方案 https://zhuanlan.zhihu.com/p/87225094 流媒体服务器环境搭建 https://blog.csdn.net/impingo/ar ...
- iframe跨域通信window.postMessage()方法
需求:A页面中要嵌入一个iframe,这个iframe是B页面,此时A页面需要得到B页面的一些信息. window.postMessage() 我们都知道浏览器的同源策略,即对于两个不同页面的脚本,只 ...