编译器工程师眼中的好代码:Loop Interchange
摘要:本文将以Loop Interchange的场景为例,讲述在编写代码时可以拿到更优性能的书写方式。
本文分享自华为云社区《编译器工程师眼中的好代码(1):Loop Interchange》,作者:毕昇小助手。
编者按:C/C++代码在编译时,编译器将源码翻译成CPU可识别的指令序列并生成可执行代码,而最终代码的运行效率取决于由编译器生成的可执行代码。在大部分情况下,编写源代码时就已经决定了程序可以在何种程度下被编译器优化。即使对源代码做微小改动也可能会对编译器生成的代码运行效率产生重大影响。因此,源代码的优化可以在一定程度上帮助编译器生成更高效的可执行代码。
本文将以Loop Interchange的场景为例,讲述在编写代码时可以拿到更优性能的书写方式。
1、Loop Interchange 相关基本概念
1.1 访问局部性
访问局部性指的是在计算机科学领域中应用程序在访问内存的时候,倾向于访问内存中较为靠近的值。这种局部性是出现在计算机系统中的一种可预测行为,我们可以利用系统的这种强访问局部性来进行性能优化。访问局部性分为三种基本形式,分别为时间局部性、空间局部性、循序局部性。
而本文主要讲述的Loop Interchange主要是利用了空间局部性。空间局部性指的是,最近引用过的内存位置以及其周边的内存位置容易再次被使用。比较常见于循环中,比如在一个数组中,如果第3个元素在上一个循环中被使用,那么本次循环中极有可能会使用第4个元素;如果本次循环确实使用第4个元素,就是命中上一次迭代所prefetch到的cache数据。
所以对于数组循环运算,可以利用空间局部性这一特征,保证两次相邻循环中对数组元素的访问在内存上是更加靠近的,即循环访问数组中的元素时stride越小,相应的性能可能会有所优化。
那么,数组在内存上是如何存储的呢?
1.2 Row-major 和 Column-major
Row-major 和 Column-major 是两种将多维数组存储在线性存储中的方式。数组的元素在内存中是连续的;Row-major ordering代表行的连续元素在内存中彼此相邻,而Column-major ordering则是代表列的连续元素彼此相邻,如下图所示。
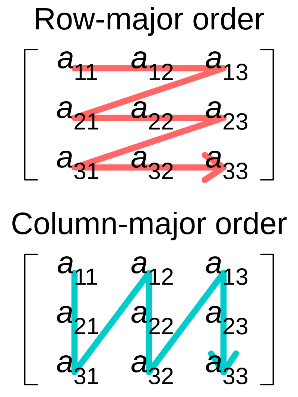
虽然Row和Column的名称看起来像是特指二维数组,但是Row-major和Column-major也可以推广适用于任何维度的数组。
那么在C/C++中,数组是以以上哪种方式存储的呢?
举一个小例子,用cachegrind工具来展示C使用两种不同的访问形式的CPU的cache丢失率对比。
按行访问:
#include <stdio.h>
int main(){
size_t i,j;
const size_t dim = 1024 ;
int matrix [dim][dim];
for (i=0;i< dim; i++)
for (j=0;j <dim;j++)
matrix[i][j]= i*j;
return 0;
}

按列访问:
#include <stdio.h>
int main(){
size_t i,j;
const size_t dim = 1024 ;
int matrix [dim][dim];
for (i=0;i< dim; i++){
for (j=0;j <dim;j++){
matrix[j][i]= i*j;
}
}
return 0;
}

根据上述C代码中对相同数组的两种不同访问方式时cache丢失率的对比,可以说明在C/C++代码中,数组是以Row-major形式储存的。也就是说,如果前一步访问了a[i][j],那么对a[i][j+1]的访问会命中cache。这样就不会执行对主存储器的访问,而cache比主内存快,因此遵循相应编程语言的储存形式使其可以命中cache可能会带来优化。
至于其他常用的编程语言,Fortran、MATLAB等则是默认Column-major形式。
1.3 Loop Interchange
Loop Interchange利用系统倾向于访问内存中较为靠近的值的特征以及C/C++ Row-major的特点,通过改变循环嵌套中两个循环之间的执行顺序,增加整体代码空间局部性。此外,它还可以启用其他重要的代码转换,例如,Loop Reordering就是Loop Interchange扩展到两个以上循环被重新排序时的优化。在LLVM中,Loop Interchange需要通过使能-mllvm -enable-loopinterchange选项启用。
2、优化示例
2.1 基础场景
简单看下面一个矩阵运算的示例:
原始代码:
for(int i = 0; i < 2048; i++) {
for(int j = 0; j < 1024; j++) {
for(int k = 0; k < 1024; k++) {
C[i * 1024 + j] += A[i * 1024 + k] * B[k * 1024 + j];
}
}
}
试着把jk两层循环进行Loop Interchange之后的代码:
for(int i = 0; i < 2048; i++) {
for(int k = 0; k < 1024; k++) {
for(int j = 0; j < 1024; j++) {
C[i * 1024 + j] += A[i * 1024 + k] * B[k * 1024 + j];
}
}
}
可以发现,在原始代码中,最内层的k每次迭代,C要访问的数据不变,A每次访问的stride为1,大概率命中cache,但B由于每次访问的stride为1024,几乎每次都会cache miss。
Loop Interchange之后,j位于最内层循环,每次迭代时A每次要访问的数据不变,C和B每次访问的stride为1,都会有很大概率命中cache,cache命中率大大增加。
那么cache命中率是否真的增加,以及两者的性能又如何呢?
原始代码:
$ time -p ./a.out
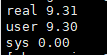
$ sudo perf stat -r 3 -e cache-misses,cache-references,L1-dcache-load-misses,L1-dcache-loads ./a.out

Loop Interchange后的结果如下:
$ time -p ./a.out
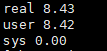
$ sudo perf stat -r 3 -e cache-misses,cache-references,L1-dcache-load-misses,L1-dcache-loads ./a.out

两者相比:
L1-dcache-loads的数目差不多,因为要访问的数据总量差不多;
L1-dcache-load-misses所占L1-dcache-loads的比例在进行loop interchange代码修改后降低了将近10倍。
同时,性能数据上也能带来接近9.5%的性能提升。
2.2 特殊场景
当然,在实际使用时,并不是所有的场景都是如2.1中所示的那种工整的可Loop Interchange场景。
for ( int i = 0; i < N; ++ i )
{
if( I[i] != 1 ) continue;
for ( int m = 0; m < M; ++ m )
{
Res2 = res[m][i] * res[m][i];
norm[m] += Res2;
}
}
如上述场景,如果N是超大数组,那么Loop Interchange理论上可以带来较大收益;但由于两层循环中间增加一个分支判断,导致原本可以Loop Interchange的场景无法实现。
针对这种场景,可以考虑将中间的分支判断逻辑剥离,可以先保证Loop Interchange使得数组res在连续内存上进行访问;至于中间的判断分支逻辑,可以在Loop Interchange两层循环后再进行回退。
for ( int m = 0; m < M; ++ m )
{
for ( int i = 0; i < N; ++ i)
{
Res2 = res[m][i] * res[m][i];
norm[m] += Res2;
if( I[i] != 1 ) //补充逻辑,保证源代码语义
{
norm[m] -= Res2;
continue;
}
}
}
当然,这样的源码修改也需要考虑cost是否值得,如果该if分支进入频率非常高,那么之后回退带来的cost也会较大,可能就需要重新考虑Loop Interchange是否值得;反之,如果分支进入频率非常低,那么Loop Interchange的实现还是可以带来可观的收益的。
3、毕昇编译器对Loop Interchange pass社区的贡献
毕昇编译器团队在llvm社区中对Loop Interchange pass也做出了不小的贡献。团队从legality、profitability等方面对Loop Interchange pass做了全方位的增强,同时也对该pass所支持的场景做了大量的扩展。在Loop Interchange方面,近两年来团队小伙伴为社区提供了二十余个主要的patch,包含Loop Interchange,以及相关的dependence analysis、loop cache analysis、delinearization等分析和优化的增强。简单举几个例子:
- D114916 [LoopInterchange] Enable loop interchange with multiple outer loop indvars (https://reviews.llvm.org/D114916)
- D114917 [LoopInterchange] Enable loop interchange with multiple inner loop indvars
(https://reviews.llvm.org/D1149167)
这两个patch将Loop Interchange的应用场景扩展到内层或者外层循环中包含不止一个induction variable的情况:
for (c = 0, e = 1; c + e < 150; c++, e++) {
d = 5;
for (; d; d--)
a |= b[d + e][c + 9];
}
}
- D118073 [IVDescriptor] Get the exact FP instruction that does not allow reordering
(https://reviews.llvm.org/D118073) - D117450 [LoopInterchange] Support loop interchange with floating point reductions
(https://reviews.llvm.org/D117450)
这两个patch将Loop Interchange的应用场景扩展到支持浮点类型的reduction计算的场景:
double matrix[dim][dim];
for (i=0;i< dim; i++)
for (j=0;j <dim;j++)
matrix[i][j] += 1.0;
D120386 [LoopInterchange] Try to achieve the most optimal access pattern after interchange
(https://reviews.llvm.org/D120386)
这个patch增强了Interchange的能力使编译器能够将循环体permute成为全局最优的循环顺序:
void f(int e[100][100][100], int f[100][100][100]) {
for (int a = 0; a < 100; a++) {
for (int b = 0; b < 100; b++) {
for (int c = 0; c < 100; c++) {
f[c][b][a] = e[c][b][a];
}
}
}
}
=>
void f(int e[100][100][100], int f[100][100][100]) {
for (int c = 0; c < 100; c++) {
for (int b = 0; b < 100; b++) {
for (int a = 0; a < 100; a++) {
f[c][b][a] = e[c][b][a];
}
}
}
}
D124926 [LoopInterchange] New cost model for loop interchange
(https://reviews.llvm.org/D124926)
这个patch为loop interchange提供了一个全新的,功能更强的cost model,可以更准确地对loop interchange的profitability做出判断。
此外,我们还为社区提供了大量的bugfix的patch:
- D102300 [LoopInterchange] Check lcssa phis in the inner latch in scenarios of multi-level nested loops
- D101305 [LoopInterchange] Fix legality for triangular loops
- D100792 [LoopInterchange] Handle lcssa PHIs with multiple predecessors
- D98263 [LoopInterchange] fix tightlyNested() in LoopInterchange legality
- D98475 [LoopInterchange] Fix transformation bugs in loop interchange
- D102743 [LoopInterchange] Handle movement of reduction phis appropriately during transformation (pr43326 && pr48212)
- D128877 [LoopCacheAnalysis] Fix a type mismatch bug in cost calculation
以及其他功能的增强:
- D115238 [LoopInterchange] Remove a limitation in legality
- D118102 [LoopInterchange] Detect output dependency of a store instruction with itself
- D123559 [DA] Refactor with a better API
- D122776 [NFC][LoopCacheAnalysis] Add a motivating test case for improved loop cache analysis cost calculation
- D124984 [NFC][LoopCacheAnalysis] Update test cases to make sure the outputs follow the right order
- D124725 [NFC][LoopCacheAnalysis] Use stable_sort() to avoid non-deterministic print output
- D127342 [TargetTransformInfo] Added an option for the cache line size
- D124745 [Delinearization] Refactoring of fixed-size array delinearization
- D122857 [LoopCacheAnalysis] Enable delinearization of fixed sized arrays
结语
如果想要尽可能的利用Loop Interchange优化,那在书写C/C++代码时,请尽可能保证每个迭代之间对数组或数列的访问stride越小越好;stride越接近1,空间局部性就越高,自然cache命中率也会更高,在性能数据上也可以拿到更理想的收益。另外,由于C/C++的存储方式为Row-major ordering,所以在访问多维数组时,请注意内层循环要为Column才能拿到更小的stride。
参考
[1] https://zhuanlan.zhihu.com/p/455263968
[2] https://valgrind.org/info/tools.html#cachegrind
[3] https://blog.csdn.net/gengshenghong/article/details/7225775
[4] https://en.wikipedia.org/wiki/Loop_interchange
[5] https://johnysswlab.com/loop-optimizations-how-does-the-compiler-do-it/#footnote_6_1738
[6] https://blog.csdn.net/PCb4jR/article/details/85241114
[7] https://blog.csdn.net/Darlingqiang/article/details/118913291
[8] https://en.wikipedia.org/wiki/Row-_and_column-major_order
[9] https://en.wikipedia.org/wiki/Locality_of_reference
编译器工程师眼中的好代码:Loop Interchange的更多相关文章
- 全栈工程师眼中的HTTP
HTTP,是Web工程师每天打交道最多的一个基本协议.很多工作流程.性能优化都围绕HTTP协议来进行,但是我们对HTTP的理解是否全面呢?如果前端工程师和后台工程师坐在一起玩捉鬼游戏,他们对HTTP的 ...
- 第一篇:数据工程师眼中的智能电网(Smart Grid)
前言 想必第一次接触到智能电网这个概念的人,尤其是互联网从业者,都会顾名思义的将之理解为"智能的电网". 然而智能电网中的"智能"是广义上的智能,它就是指更好的 ...
- 一、源代码-面向CLR的编译器-托管模块-(元数据&IL代码)
本文脉络图如下: 1.CLR(Common Language Runtime)公共语言运行时简介 (1).公共语言运行时是一种可由多种编程语言一起使用的"运行时". (2).CLR ...
- Sublime Text webstorm等编译器快速编写HTML/CSS代码的技巧
<!DOCTYPE html> Sublime Text webstorm等编译器快速编写HTML/CSS代码的技巧--summer-rain博客园 xiayuhao 东风夜放花千树. 博 ...
- 快速开发MQTT(一)电子工程师眼中的MQTT
转载:https://zhuanlan.zhihu.com/p/54669124 DigCore 主页http://www.digcore.cn 文章首发于同名微信公众号:DigCore 欢迎关注同名 ...
- 【C# 线程】编译器代码优化技术 循环提升:Loop Hoisting
转载自:https://gandalfliang.github.io/2019/01/15/loop-hoisting/ Loop Hoisting 在上篇文章中,提到 Loop Hoisting , ...
- Sublime Text、webstorm等编译器快速编写HTML/CSS代码的技巧
Sublime Text.webstorm等编译器,如果你从事Web前端开发的话,对这几款软件一定不会陌生.它使用仿CSS选择器的语法来生成代码,大大提高了HTML/CSS代码编写的速度,比如下面的演 ...
- 如何利用C# Roslyn编译器写一个简单的代码提示/错误检查?
OK, 废话不多说,这些天在写C#代码时突然对于IDE提示有了一些想法,之前也有了解过,不过并没有深入. 先看个截图: 一段再简单不过的代码了,大家注意看到 count 字段下面的绿色波浪线了吗,我们 ...
- (二)如何利用C# Roslyn编译器写一个简单的代码提示/错误检查?
上一篇我们讲了如何建立一个简单的Roslyn分析项目如分析检查我们的代码. 今天我们主要介绍各个项目中具体的作用以及可视化分析工具. 还是这种截图,可以看到解决方案下一共有三个项目. Analyzer ...
随机推荐
- JavaMetaweblogClient,Metaweblog的java实现-从此上传博客实现全平台
目录 1. 什么是Metaweblog? 2. Metaweblog的应用 3. 如何使用Metaweblog 4. 本项目介绍 4.1 metaweblog与java之间的关系映射 4.2 使用Ja ...
- 【多线程】创建线程方式二:实现Runnable接口
创建线程方式二:实现Runnable接口 代码示例: /** * @Description 实现Runnable接口,重写run方法,执行线程需要丢入Runnable接口实现类,调用start方法 * ...
- layui数据表格导入数据
作为一个后端程序员,前端做的确实很丑,所以就学习了一下layui框架的使用.数据表格主要的问题就是传输数据的问题,这里我用我的前后端代码来做一个实际的分解. 前端部分 可以到layui官网示例中找到数 ...
- Spring Boot整合模板引擎freemarker
jsp本质是servlet,渲染都在服务器,freemarker模板引擎也是在服务器端渲染. 项目结构 引入依赖pom.xml <!-- 引入 freemarker 模板依赖 --> &l ...
- 好客租房49-组件的props(特点)
特点 1可以给组件传递任意类型的数据 2props是只读的对象 只能读取属性的值 无法修改对象 3注意:使用类组件时 如果写了构造函数 应该将props传递给super() 否则 无法在构造函数 中获 ...
- linux篇-centos7 安装cacti
1 cacti运行环境准备 cacti需要php+apache+mysql+snmp+RRDTool,以及cacti本身.cacti本体是用php开发的网站,通过snmp对远端设备信息进行采集.apa ...
- PKUSC2022 游记
PKUSC2022 游记 Day1 上午随便看了点题,感觉没看什么题就开考了. 开考之后先看 T1,发现 T1 好像不是那么简单. T1 : 九条可怜有两个账号,她每次都会打 \(\rm rating ...
- React简单教程-4-事件和hook
前言 在上一章 React 简单教程-3-样式 中我们建立了一个子组件,并稍微美化了一下.在另一篇文章 React 简单教程-3.1-样式之使用 tailwindcss 章我们使用了 tailwind ...
- 探究Presto SQL引擎(3)-代码生成
vivo 互联网服务器团队- Shuai Guangying 探究Presto SQL引擎 系列:第1篇<探究Presto SQL引擎(1)-巧用Antlr>介绍了Antlr的基本用法 ...
- Python装饰器Decorators
def hi(name="yasoob"): return "hi " + name print(hi()) # 我们甚至可以将一个函数赋值给一个变量,比如 g ...