从 CPU 讲起,深入理解 Java 内存模型!

Java 内存模型,许多人会错误地理解成 JVM 的内存模型。但实际上,这两者是完全不同的东西。Java 内存模型定义了 Java 语言如何与内存进行交互,具体地说是 Java 语言运行时的变量,如何与我们的硬件内存进行交互的。而 JVM 内存模型,指的是 JVM 内存是如何划分的。
Java 内存模型是并发编程的基础,只有对 Java 内存模型理解较为透彻,我们才能避免一些错误地理解。Java 中一些高级的特性,也建立在 Java 内存模型的基础上,例如:volatile 关键字。为了让大家能明白 Java 内存模型存在的意义,本篇文章将从计算机硬件出发,一路写到操作系统、编程语言,一环扣一环的引出 Java 内存模型存在的意义,让大家对 Java 内存模型有较为深刻的理解。看完之后,希望大家能够明白如下几个问题:
- 为什么要有 Java 内存模型?
- Java 内存模型解决了什么问题?
- Java 内存模型是怎样的一个东西?
从 CPU 说起
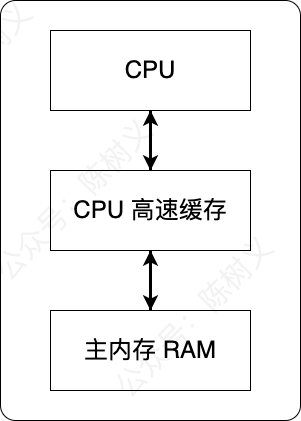
我们知道计算机有 CPU 和内存两个东西,CPU 负责计算,内存负责存储数据,每次 CPU 计算前都需要从内存获取数据。我们知道 CPU 的运行速度远远快于内存的速度,因此会出现 CPU 等待内存读取数据的情况。
由于两者的速度差距实在太大,我们为了加快运行速度,于是计算机的设计者在 CPU 中加了一个CPU 高速缓存。这个 CPU 高速缓存的速度介于 CPU 与内存之间,每次需要读取数据的时候,先从内存读取到CPU缓存中,CPU再从CPU缓存中读取。这样虽然还是存在速度差异,但至少不像之前差距那么大了。
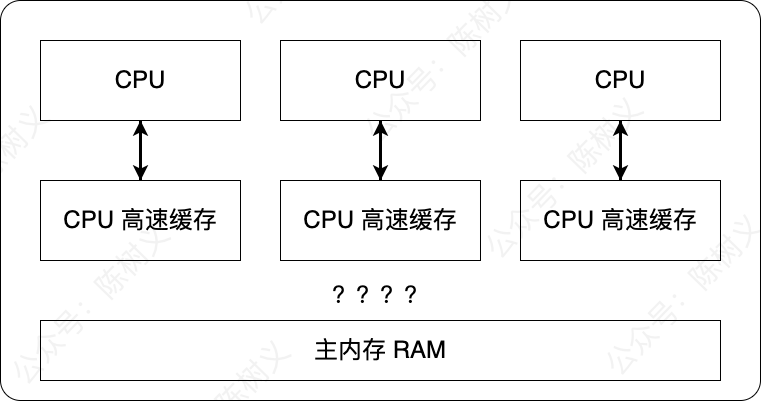
随着技术的发展,多核 CPU 出现了,CPU 的计算能力进一步提高。原本同一时间只能运行一个任务,但现在可以同时运行多个任务。由于多核 CPU 的出现,虽然提高了 CPU 的处理速度,但也带来了新的问题:缓存一致性。
在多 CPU 系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存,如下图所示。当多个 CPU 的运算任务都涉及同一块主内存区域时,可能导致各自的缓存数据不一致。如果发生了这种情况,那同步回主内存时以哪个 CPU 高速缓存的数据为准呢?
我们举个例子,线程 A 执行这样一段代码:
i = i + 10;
线程 B 执行这样一段代码:
i = i + 10;
他们的 i 都是存储在内存中共用的,初始值是 0。按照我们的设想,最终输出的值应该是 20 才对。但实际上有可能输出的值是 10。下面是可能发生的一种情况:
- 线程 A 分配到 CPU0 执行,这时候读取 i 的值为 0,存到 CPU0 的高速缓存中。
- 线程 B 分配到 CPU1 执行,这时候读取 i 的值为 0,存到 CPU1 的高速缓存中。
- CPU0 进行运算,得出结果 10,运算结束,写回内存,此时内存 i 的值为 10。
- CPU1 进行运算,得出结果 10,运算结束,写回内存,此时内存 i 的值为 10。
可以看到发生错误结果的主要原因是:两个 CPU 高速缓存中的数据是相互独立,它们无法感知到对方的变化。
到这里,就产生了第一个问题:硬件层面上,由于多 CPU 的存在,以及加入 CPU 高速缓存,导致的数据一致性问题。
要注意的是,这个问题是硬件层面上的问题。只要使用了多 CPU 并且 CPU 有高速缓存,那就会遇到这个问题。对于生产该 CPU 的厂商,就需要去解决这个问题,这与具体操作系统无关,也与编程语言无关。
那么如何解决这个问题呢?答案是:缓存一致性协议。
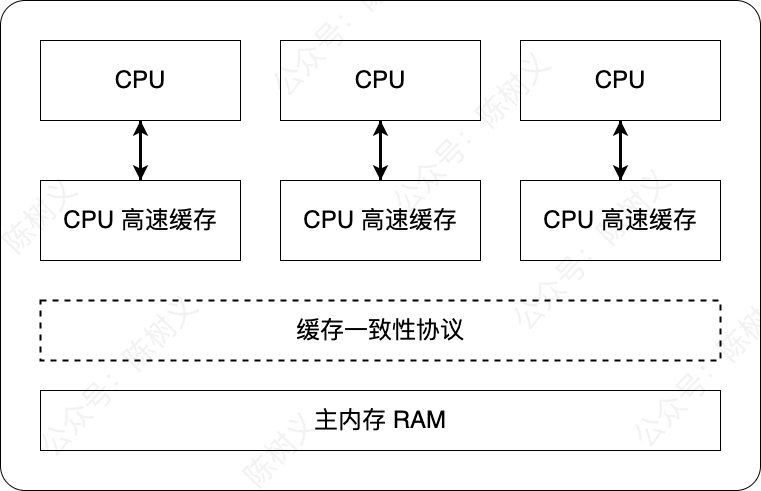
所谓的缓存一致性协议,指的是在 CPU 高速缓存与主内存交互的时候,遵守特定的规则,这样就可以避免数据一致性问题了。
在不同的 CPU 中,会使用不同的缓存一致性协议。例如 MESI 协议用于奔腾系列的 CPU 中,而 MOSEI 协议则用于 AMD 系列 CPU 中,Intel 的 core i7 处理器使用 MESIF 协议。在这里我们介绍最为常见的一种:MESI数据一致性协议。
在 MESI 协议中,每个缓存可能有有4个状态,它们分别是:
- M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中。
- E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本 Cache 中。
- S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多 Cache 中。
- I(Invalid):这行数据无效。
那么在 MESI 协议的作用下,我们上面的线程执行过程就变为:
- 线程 A 分配到 CPU0 执行,这时候读取 i 的值为 0,存到 CPU0 的高速缓存中。
- 线程 B 分配到 CPU1 执行,这时候读取 i 的值为0,存到 CPU1 的高速缓存中。
- CPU0 进行运算,得出结果 10,运算结束,写回内存,此时内存 i 的值为 10。同时通过消息的方式告诉其他持有 i 变量的 CPU 缓存,将这个缓存的状态值为 Invalid。
- CPU1 进行运算,从 CPU 缓存取出值,但是发现这个缓存值被置为 Invalid了。于是重新去内存中读取,读取到 10 这个值放入 CPU 缓存。
- CPU1 进行运算,得出结果 20,运算结束,写回内存,此时内存 i 的值为 20。
从上面的例子,我们可以知道 MESI 缓存一致性协议,本质上是定义了一些内存状态,然后通过消息的方式通知其他 CPU 高速缓存,从而解决了数据一致性的问题。
从操作系统说起
操作系统,它屏蔽了底层硬件的操作细节,将各种硬件资源虚拟化,方便我们进行上层软件的开发。在我们开发应用软件的时候,我们不需要直接与硬件进行交互,只需要和操作系统交互即可。既然如此,那么操作系统就需要将硬件进行封装,然后抽象出一些概念,方便上层应用使用。于是 CPU 时间片、内核态、用户态等概念也诞生了。
前面我们说到 CPU 与内存之间会存在缓存一致性问题,那操作系统抽象出来的 CPU 与内存也会面临这样的问题。因此,操作系统层面也需要去解决同样的问题。所以,对于任何一个系统来说,它们都需要去解决这样一个问题。我们把在特定的操作协议下,对特定内存或高速缓存进行读写访问的过程进行抽象,得到的就是内存模型了。 无论是 Windows 系统,还是 Linux 系统,它们都有特定的内存模型。
Java 语言是建立在操作系统上层的高级语言,它只能与操作系统进行交互,而不与硬件进行交互。与操作系统相对于硬件类似,操作系统需要抽象出内存模型,那么 Java 语言也需要抽象出相对于操作系统的内存模型。一般来说,编程语言也可以直接复用操作系统层面的内存模型,例如:C++ 语言就是这么做的。但由于不同操作系统的内存模型不同,有可能导致程序在一套平台上并发完全正常,而在另外一套平台上并发访问却经常出错。因此在某些场景下,就必须针对不同的平台来编写程序。
而我们都知道 Java 的最大特点是「Write Once, Run Anywhere」,即一次编译哪里都可以运行。而为了达到这样一个目标,Java 语言就必须在各个操作系统的基础上进一步抽象,建立起一套对内存或高速缓存的读写访问抽象标准。这样就可以保证无论在哪个操作系统,只要遵循了这个规范,都能保证并发访问是正常的。
Java 内存模型
经过了前面的铺垫,相信你已经明白了为什么要有 Java 内存模型,以及 Java 内存模型是什么,有了一个感性的理解。这里我们再给 Java 内存模型下一个较为准确的定义。
Java 内存模型(Java Memory Model,JMM)用于屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台都能达到一致的内存访问效果。
Java 内存模型定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。这里说的变量包括了实例字段、静态字段和构成数组对象的元素,但不包括局部变量与方法参数。因为后者是线程私有的,不会被共享,自然就不会存在竞争问题。
内存模型的定义
Java 内存模型规定所有的变量都存储在主内存中,每条线程都有自己的工作内存。线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递都需要通过主内存来完成。主内存、工作内存、线程三者之间的关系如下图所示。
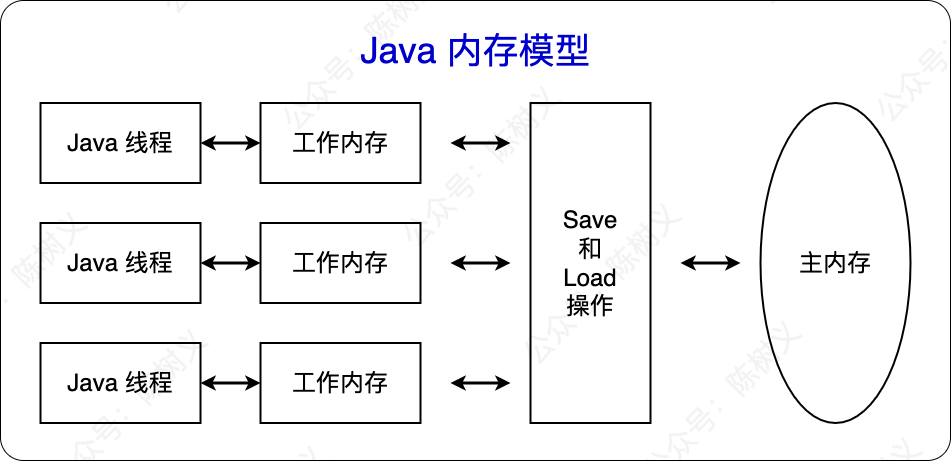
Java 内存模型的主内存、工作内存与 JVM 的堆、栈、方法区,并不是同一层次的内存划分,两者是没有关联的。如果一定要对应一下,那么主内存主要对应于 Java 堆中对象实例的数据部分,而工作内存则对应于虚拟机栈中的部分区域。
内存间的交互
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存,以及如何从工作内存同步回主内存的细节,Java 内存模型定义了 8 种操作来完成。虚拟机实现的时候必须保证下面提及的每一种操作都是原子的、不可再分的。
- lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
- write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
如果要把一个变量从主内存复制到工作内存,那就要顺序地执行 read 和 load 操作,如果要把变量从工作内存同步回主内存,就要顺序地执行 store 和 write 操作。注意,Java 内存模型只要求上述两个操作必须按顺序执行,而没有保证是连续执行。也就是说,read 与 load 之间、store 与 write 之间是可插入其他指令的,如对主内存中的变量 a、b 进行访问时,一种可能出现顺序是 read a、read b、load b、load a。
此外,Java 内存模型还规定上述 8 种基本操作时必须满足如下规则:
- 不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起回写了但主内存不接受的情况出现。
- 不允许一个线程丢弃它的最近的 assign 操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
- 一个新的变量只能在主内存中「诞生」,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说,就是对一个变量实施use、store操作之前,必须先执行过了assign和load操作。
- 一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
- 如果对一个变量执行lock操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
- 如果一个变量事先没有被lock操作锁定,那就不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定住的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)。
这 8 种内存访问操作以及上述规则限定,再加上稍后介绍的对 volatile 的一些特殊规定,就已经完全确定了 Java 程序中哪些内存访问操作在并发下是安全的。 看完了 Java 内存模型的 8 个基本操作和 8 个规则,感觉太过于繁琐了,非常不利于我们日常代码的编写。为了能帮助编程人员理解,于是就有了与其相等价的判断原则 —— 先行发生原则,它可以用于判断一个访问在并发环境下是否安全。
总结
这篇文章我们从底层 CPU 开始讲起,一直讲到操作系统,最后讲到了编程语言层面,让大家能够一环扣一环地理解,最后明白 Java 内存模型诞生的原因(上层有数据一致性问题),以及最终要解决的问题(缓存一致性问题)。看到这里,我们大概把为什么要有 Java 内存模型讲清楚了,也知道了 Java 内存模型是什么。最后我们来做个总结:
- 由于多核 CPU 和高速缓存在存在,导致了缓存一致性问题。这个问题属于硬件层面上的问题,而解决办法是各种缓存一致性协议。不同 CPU 采用的协议不同,MESI 是最经典的一个缓存一致性协议。
- 操作系统作为对底层硬件的抽象,自然也需要解决 CPU 高速缓存与内存之间的缓存一致性问题。各个操作系统都对 CPU 高速缓存与缓存的读写访问过程进行抽象,最终得到的一个东西就是「内存模型」。
- Java 语言作为运行在操作系统层面的高级语言,为了解决多平台运行的问题,在操作系统基础上进一步抽象,得到了 Java 语言层面上的内存模型。
- Java 内存模型分为工作内存与主内存,每个线程都有自己的工作内存。每个线程都不能直接与主内存交互,只能与工作内存交互。此外,为了保证并发编程下的数据准确性,Java 内存模型还定义了 8 个基本的原子操作,以及 8 条基本的规则。
如果 Java 程序能够遵守 Java 内存模型的规则,那么其写出的程序就是并发安全的,这就是 Java 内存模型最大的价值。
参考资料
- Java 内存模型原理,你真的理解吗?
- 《Java并发编程的艺术》
- Java并发编程实战-盖茨等-微信读书
- Java 高并发编程详解:深入理解并发核心库 - 汪文君 - 微信读书
- 操作系统对 CPU 的控制权 | 王辉的博客
- Operating Systems: Three Easy Pieces
- 既然CPU有缓存一致性协议(MESI),为什么JMM还需要volatile关键字? - 罗一鑫的回答 - 知乎
从 CPU 讲起,深入理解 Java 内存模型!的更多相关文章
- 全面理解Java内存模型
尊重原创:http://blog.csdn.net/suifeng3051/article/details/52611310 Java内存模型即JavaMemory Model,简称JMM.JMM定义 ...
- 全面理解Java内存模型(JMM)及volatile关键字(转载)
关联文章: 深入理解Java类型信息(Class对象)与反射机制 深入理解Java枚举类型(enum) 深入理解Java注解类型(@Annotation) 深入理解Java类加载器(ClassLoad ...
- 全面理解Java内存模型(转)
转自:http://blog.csdn.net/suifeng3051/article/details/52611310 Java内存模型即Java Memory Model,简称JMM.JMM定义了 ...
- 深入理解java内存模型
深入理解Java内存模型(一)——基础 深入理解Java内存模型(二)——重排序 深入理解Java内存模型(三)——顺序一致性 深入理解Java内存模型(四)——volatile 深入理解Java内存 ...
- 全面理解Java内存模型(JMM)及volatile关键字(转)
原文地址:全面理解Java内存模型(JMM)及volatile关键字 关联文章: 深入理解Java类型信息(Class对象)与反射机制 深入理解Java枚举类型(enum) 深入理解Java注解类型( ...
- 深入理解 Java 内存模型(转载)
摘要: 原创出处 http://www.54tianzhisheng.cn/2018/02/28/Java-Memory-Model/ 「zhisheng」欢迎转载,保留摘要,谢谢! 0. 前提 &l ...
- 【并发编程】一文带你读懂深入理解Java内存模型(面试必备)
并发编程这一块内容,是高级资深工程师必备知识点,25K起如果不懂并发编程,那基本到顶.但是并发编程内容庞杂,如何系统学习?本专题将会系统讲解并发编程的所有知识点,包括但不限于: 线程通信机制,深入JM ...
- 深入理解Java内存模型(摘)
--摘自 周志明<深入理解Java虚拟机> 转自 https://www.jianshu.com/p/15106e9c4bf3 深入理解Java内存模型(摘) java内存模型(Java ...
- 用实例带你深入理解Java内存模型
摘要:本文的目的来理解 J V M 与我们的内存两者之间是如何协调工作的. 本文分享自华为云社区<一文带你图解Java内存模型>,作者: 龙哥手记 . 我们今天要特别重点讲的,也就是我们本 ...
- 【Todo】【转载】深入理解Java内存模型
提纲挈领地说一下Java内存模型: 什么是Java内存模型 Java内存模型定义了一种多线程访问Java内存的规范.Java内存模型要完整讲不是这里几句话能说清楚的,我简单总结一下Java内存模型的几 ...
随机推荐
- 用来创建用户docker registry认证的Secret
集群环境:1.k8s用的是二进制方式安装2.操作系统是linux (centos)3.操作系统版本为 7.4/7.94.k8s的应用管理.node管理.pod管理等用rancher.k8s令牌以及ma ...
- 3.初识Java
一.Java特性和优势 简单性 面向对象 可移植性 高性能 分布式 动态性 多线程 安全性 健壮性 二.Java三大版本 一次编写到处运行 JavaSE:标准版(桌面程序,控制台开发) JavaME: ...
- setAttribute 和 getAttribute 的用法
setAttribute() 是用于设置自定义属性的方法,有两个参数,第一个是属性名,第二个是属性值, 添加时必须用引号括起来: 此时的box就加上了一个自定义属性名和属性值,可以根据需要赋取 g ...
- 开始项目之前整理Xmind
今天为将要做的项目整理了一份Xmind文档,每个页面,模块,功能都记了下来.带我的老师说过于详细了,但我还是新手,也不懂哪里改精简那里不该. 总结:整理Xmind文档还是很有必要的,之前这个项目我大致 ...
- 转换为布尔类型 Boolean
1. js 代码 console.log(Boolean('')); // false console.log(Boolean(0)); // false console.log(Boolean(Na ...
- MySQL 的 GRANT和REVOKE 命令
MySQL 的 GRANT和REVOKE 命令 GRANT - 授权 将指定 操作对象 的指定 操作权限 授予指定的 用户; 发出该 GRANT语句的可以是数据库管理员,也可以是该数据库对象的创建者; ...
- 通过OptaPlanner优化 COVID-19 疫苗接种预约安排(2)
本文为OptaPlanner官方博客<Optimizing COVID-19 vaccination appointment scheduling>的第二篇译文.第一篇介绍了通过OptaP ...
- 短信登录与注册接口、前端所有方式登录注册页面、redis数据库介绍与安装
今日内容概要 短信登陆接口 短信注册接口 登陆注册前端 redis介绍和安装 内容详细 1.短信登陆接口 在视图类 user/views.py中修改并添加: from .serializer impo ...
- ONNXRuntime学习笔记(三)
接上一篇完成的pytorch模型训练结果,模型结构为ResNet18+fc,参数量约为11M,最终测试集Acc达到94.83%.接下来有分两个部分:导出onnx和使用onnxruntime推理. 一. ...
- 干货|给小白的 Nginx 10分钟入门指南
一个执着于技术的公众号 前言 今天主要对Nginx Web服务软件进行介绍,作为HTTP服务软件的后起之秀,Nginx与它的老大哥Apache相比有很多改进之处,比如,在性能上,Nginx占用的系统资 ...