【重难点整理】通过kafka的全过程叙述kafka的原理、特性及常见问题
一、kafka的实现原理
1、逻辑结构
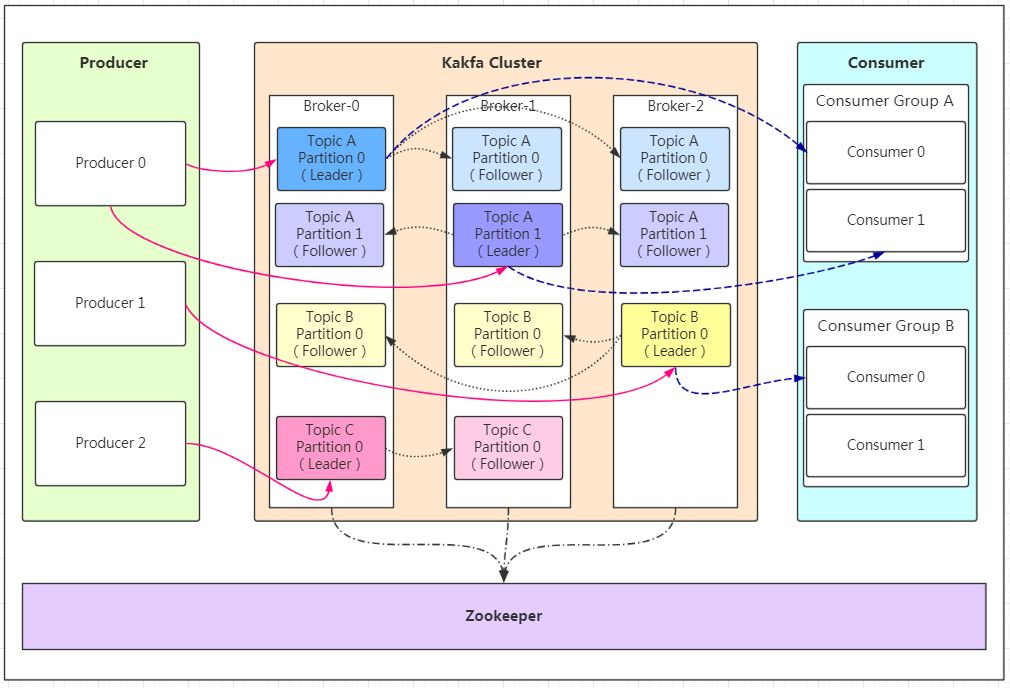
2、组成
生产者:生产消息,来自服务、客户端、端口……
消息本身:消息主体
topic主题:对消息的分类,例如数仓不同层中的不同类型数据(订单、用户……);自带__consumer_offsets的topic,以k-v形式保存CG-topic-partition下的位移
partition分区:Topic 的分区(同一topic由多个分区组成,每个分区的内容不同,怎么划分???),表现形式为一个文件夹,用作kafka负载,提高其吞吐量
Replication:表示分区的副本,即follower节点,用于leader宕机时进行选主;副本数量<=集群中节点个数<=10
Cluster集群:
broker节点:Kafka 实例,表示一台机器,broker0、broker1、broker2表示节点编号
Consumer Group消费者组:(一个消费者组消费一个topic)同一个消费者组的消费者可以消费同一个 Topic 的不同分区的数据,用于提高吞吐量;同一个分区的数据只能被消费者组中的某一个消费者消费
消费者:(一个消费者消费一个分区)消息的出口,例如一个服务、一个数据库、hdfs、kafka……(怎么分配partition到消费者:range和roundroubin?)
offset偏移量:消费者提交offset表示消息读取的位置,自带__consumer_offsets的topic,以k-v形式保存CG-topic-partition下的位移
zookeeper:保存集群的元信息,保证kafka的高可用性
3、发送消息
集群中返回leader
将消息以push模式发给leader
消息被追加到指定分区(顺序写),保证同一分区内的数据顺序有序
如何确定消息发送到topic的哪个分区?
1、指定partition
2、未指定partition但指定了key,对数据的key进行哈希选出partition
3、既未指定partition也未指定key,则以轮训方式确定partition
另外:如果指定的topic不存在,那么会自动创建1分区1副本的topic
leader收到消息后发送ack给生产者,保证可靠发送【默认ack=?】
如何保证消息发送时不丢失/如何保证消息被可靠发送?-ack机制
生产者向队列中写入数据时确定kafka是否接收到数据,参数值为0,1,all
0表示无需等待集群返回,不确保消息发送成功
1表示只需要leader应答存盘,就可以发送下一条
all表示leader应答+followers同步完成,才会发送下一条数据
leader将消息持久化
followers从leader上pull消息进行同步
follower持久化消息后向leader发送ack
4、数据落盘
kafka将数据存盘,单独划分一块区域,进行顺序写(比随机写拥有更高的效率)
partition以文件夹形式存储,对partition进行分段存储:partition/segment/(最小的offset.index,log,timeindex )
利用分段+索引的方式解决查找效率的问题
使用log文件存储message,消息的组成?
消息主要包含Offset(8字节,确定消息在partition中的位置)、消息大小(4字节byte)、消息体(被压缩后的实际数据)、压缩类型
旧消息会进行删除
旧消息删除策略/消息保存多久?
基于时间,默认配置是 168 小时(7 天)。
基于大小,默认配置是 1073741824。
读取的复杂度是O(1),因此,删除文件不会提高kafka的性能
5、消费数据
消费者点对点拉取pull数据
一个消费者组消费同一个topic
一个组内的消费者消费不同的partition【一个消费者能消费多个partition,但是一个partition不能被多个消费者消费】(建议消费者数目=分区数)
消费者利用Segment+Offset在leader所在的partition中共同查找消息(二分找segment、打开index文件、稀疏索引确定其相对偏移量、顺序查找确定其位置)
消费者如何记录读取的偏移量?
早期使用zk,每隔一段时间就需要上报一次,容易导致重复消费且性能较差
新版本使用__consumer_offsets这个topic维护消费者消费某个分区的偏移量
二、kafka如何保证可靠消费
1、手动提交offset
enable.auto.commit设置为false,如果自动提交可能会未被消费就提交,从而导致消息丢失
2、降低重复消费的概率
开启自动提交并设置auto.commit.interval.ms时长
默认值是每5秒钟提交一次
设置的时间短一点,频繁提交会增加额外的开销,但也会降低重复处理消息的概率
3、配置auto.offset.reset
当请求的偏移量不存在时,配置auto.offset.reset
使用earliest会产生重复数据,但可以避免数据丢失
使用latest,减少重复消费,但可能会丢失数据
4、依靠at-least once+kafka的幂等性,借助第三方系统
使用键值对数据库存储唯一key,消息作为value
三、kafka如何保证exactly once
1、at-least once+幂等性实现
2、自身实现
exactly-once定义为: 不管在处理的时候是否有错误发生,计算的结果(包括所有所改变的状态)都一样。
(1)消息生产者提交数据到broker,开启幂等性,即修改配置文件:enable.idempotence=true 同时要求 ack=all 且 retries>1
(2)broker进行消息处理,将模式“消息读入->消息处理->结果写出”作为事务操作
默认情况下kafka的事务是关闭的,通过配置文件开启,需要
transactional.id=“unique-id”, 要求enable.idempotence=true.
开启事务后,配置启动exactly-once:processing.guarantee="exactly-once ", 默认是最少一次。
(3)消费者消费数据,只读取已经标记为“成功提交”的数据,避免消费到脏数据
配置为isolation.level=“read_committed”。默认是read_uncommitted
【重难点整理】通过kafka的全过程叙述kafka的原理、特性及常见问题的更多相关文章
- 这是一份非常适合收藏的Android进阶/面试重难点整理
写在前面 记得我大二时“不务正业”地自学Android并跟了老师做项目,到大三开始在目前的公司实习,至今毕业已有几年多,学习Android已经6.7年多了!但总感觉知识点很零散,并且不够深入,遇到瓶颈 ...
- 李洪强漫谈iOS开发[C语言-008]- C语言重难点
C语言学习的重难点 写程序的三个境界: 照抄的境界,翻译的境界,创新的境界 1 伪代码: 描述C语言的编程范式 范式: 规范的一种表示 对于C的范式学会的话,C, C++ Java 都会了 2 ...
- English--音标重难点
English|音标重难点 在拥有了,音标的元音与辅音的基础之后,需要对于这些音标进行加以区分,毕竟方言对于口型的影响非常的大. 前言 目前所有的文章思想格式都是:知识+情感. 知识:对于所有的知识点 ...
- 《十天学会 PHP》的重难点
记录一下我在学习<十天学会 PHP>(第六版)的过程中的遇到的重难点,该课程是学习制作一个简单的留言板. 准备工作 XAMPP(Apache + MySQL + PHP + PERL) 是 ...
- html和css的重难点知识
目录 html总难点总结: 1. 块级标签与内联标签的区别 1.1 块级标签: 1.2 内联标签: 2. 选择器 2.1 定义 2.2 选择器的分类 2.1 选择器的分类 3. css中margin, ...
- 老猿Python重难点知识博文汇总
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 除了相关教程外,老猿在学习过程中还写了大量的学习随笔,内容比较杂,文章内容也参差不齐,为了方便,老猿 ...
- Collection集合重难点梳理,增强for注意事项和三种遍历的应用场景,栈和队列特点,数组和链表特点,ArrayList源码解析, LinkedList-源码解析
重难点梳理 使用到的新单词: 1.collection[kəˈlekʃn] 聚集 2.empty[ˈempti] 空的 3.clear[klɪə(r)] 清除 4.iterator 迭代器 学习目标: ...
- Kafka(五)Kafka的API操作和拦截器
一 kafka的API操作 1.1 环境准备 1)在eclipse中创建一个java工程 2)在工程的根目录创建一个lib文件夹 3)解压kafka安装包,将安装包libs目录下的jar包拷贝到工程的 ...
- kafka 基础知识梳理-kafka是一种高吞吐量的分布式发布订阅消息系统
一.kafka 简介 今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何及时做到如上两点 ...
- kafka之二:Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
随机推荐
- Kubernetes 监控--Grafana
前面我们使用 Prometheus 采集了 Kubernetes 集群中的一些监控数据指标,我们也尝试使用 promQL 语句查询出了一些数据,并且在 Prometheus 的 Dashboard 中 ...
- kubernetes 调度器
调度器 kube-scheduler 是 kubernetes 的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理.更加充分 ...
- Jmix 中 REST API 的两种实现
你知道吗,在 Jmix 中,REST API 有两种实现方式! 很多应用是采取前后端分离的方式进行开发.这种模式下,对前端的选择相对灵活,可以根据团队的擅长技能选择流行的 Angular/React/ ...
- Python(一)转义字符及操作符
转义字符 描述 \(在行尾时) 续航符 \\ 反斜杠符号 \' 单引号 \'' 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 转行 \v 纵向制表符 \t 横向 ...
- 代码随想录第十三天 | 150. 逆波兰表达式求值、239. 滑动窗口最大值、347.前 K 个高频元素
第一题150. 逆波兰表达式求值 根据 逆波兰表示法,求表达式的值. 有效的算符包括 +.-.*./ .每个运算对象可以是整数,也可以是另一个逆波兰表达式. 注意 两个整数之间的除法只保留整数部分. ...
- 最长公共前缀(Java)
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入:strs = ["flower","flo ...
- 从0开始写一个简单的vite hmr 插件
从0开始写一个简单的vite hmr 插件 0. 写在前面 在构建前端项目的时候,除开基本的资源格式(图片,json)以外,还常常会需要导入一些其他格式的资源,这些资源如果没有第三方vite插件的支持 ...
- zookeeper之安装
zookeeper之安装 一.准备条件 1.1 最低三个服务器(一主多从,1个leader,多个flower)1.2 将zookeeper安装包上传到集群并解压zookeeper 二.将conf目录下 ...
- 20220728 - DP训练 #1
20220728 - DP训练 #1 时间记录 \(8:00-9:00\) T1 尝试做 \(T1\),可惜并未做出,没有想到是资源分配 设置三维状态,初值一直不知道怎么设置 并且对于距离有一部分不会 ...
- 一篇文章带你了解NoSql数据库——Redis简单入门
一篇文章带你了解NoSql数据库--Redis简单入门 Redis是一个基于内存的key-value结构数据库 我们会利用其内存存储速度快,读写性能高的特点去完成企业中的一些热门数据的储存信息 在本篇 ...