论文笔记 - SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
motivation
Active Learning 存在的重要问题:现实数据极度不平衡,有许多类别很少见(rare),又有很多类别是冗余的(redundancy),又有些数据是 OOD 的(out-of-distribution)。
1. 不同的次模函数
提出三种次模函数的变体:
- 次模条件增长(Submodular Conditional Gain, SCG),越大说明差异越大:
$$f(\mathcal{A}|\mathcal{P})=f(\mathcal{A}\cup\mathcal{P})-f(\mathcal{P})$$
- 次模交互信息(Submodular Mutual Information, SMI),越大说明相似性越大:
$$I_f(\mathcal{A};\;\mathcal{Q})=f(\mathcal{A})+f(\mathcal{Q})-f(\mathcal{A}\cup\mathcal{Q})$$
- 次模条件交互信息(Submodular Conditional Mutual Information, SCMI),上面二者的结合:
$$I_f(\mathcal{A};\;\mathcal{Q}|\mathcal{P})=f(\mathcal{A}\cup\mathcal{P})+f(\mathcal{Q}\cup\mathcal{P})-f(\mathcal{A}\cup\mathcal{Q}\cup\mathcal{P})-f(\mathcal{P})$$
其中 SCMI 可以通过设置不同的 $\mathcal{Q}$ 和 $\mathcal{P}$ 得到另外两种次模函数(算上标准次模函数的话就是三种),对应关系和适用场景如下:

图 1 各种SIM 函数
2. 次模函数的实例化问题
次模信息度量(submodular information measures, SIM),一般有三种实例化的问题:
- 设施选址问题(Facility Location)
- 图切问题(Graph Cut)
- 对数行列式问题(Log Determinant)
Analysis
1. 标准 Active Learning
见图 1 的第一行,此时问题退化:AL 的检索样本过程只考虑多样性(不考虑检索的数据是否冗余、OOD,也不偏向 rare 的样本)。
2. 样本不平衡
主要指某些类别出现很少的情况,例如医疗影像病灶判断,真正 positive 的数据是很少的,因此可以使用 SMI 次模函数(图 1 第二行),在保证多样性的基础上,使得 AL 检索的样本与 $\mathcal{Q}$(有病灶的影像)尽可能接近。
3. 样本冗余
虽然次模函数本身保证了多样性,但是在 batch active learning 中,多样性的保证指存在与一个 batch 中。因此可以使用 SCG 次模函数(图 1 第三行),提供额外的多样性正则信息。
4. OOD 数据
未标注的数据容易出现 OOD 的数据,例如在手写数字识别的任务中,未标注的数据集中出现了手写字母的图片(不是任务目标也无法提供有效信息),是应当避免的。因此可以使用 SCMI 次模函数(图 1 第四行),使得 AL 检索的样本与 in-domin 的数据尽可能相似,与 out-of-domin 的数据尽可能远离,同时保证多样性。
5. 混合场景
当未标注数据出现了多种情景时也可以进行组合(例如即出现了冗余的数据,也出现了 OOD 的数据):
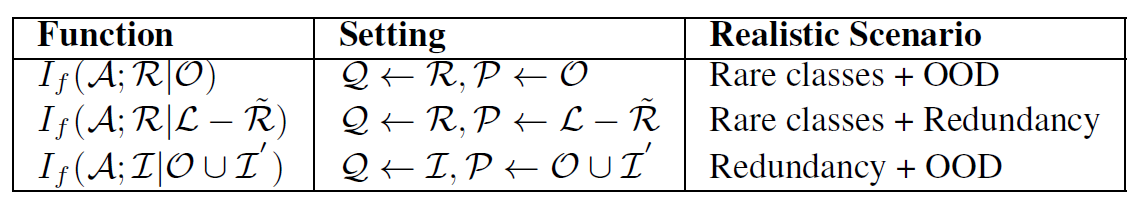
图 2 混合场景
同时,类似于在线学习(online learning),未标注的数据集有可能是在不断产生中的,因此一开始数据集未出现上述场景的时候可以使用标准次模函数,出现了上述场景之后(例如某次数据收集之后出现了大量 OOD 样本)了可以再改用 SIM 的变体。
论文笔记 - SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios的更多相关文章
- 论文笔记 - PRISM: A Rich Class of Parameterized Submodular Information Measures for Guided Subset Selection
Motivation 与 Active Learning 类似,Target Learning 致力于 挑选外卖更"感兴趣"的数据,即人为为更重要的数据添加 bias.例如我们当前 ...
- 论文笔记:Visual Object Tracking based on Adaptive Siamese and Motion Estimation Network
Visual Object Tracking based on Adaptive Siamese and Motion Estimation 本文提出一种利用上一帧目标位置坐标,在本帧中找出目标可能出 ...
- 论文笔记 - GRAD-MATCH: A Gradient Matching Based Data Subset Selection For Efficient Learning
Analysis Coreset 是带有权重的数据子集,目的是在某个方面模拟完整数据的表现(例如损失函数的梯度,既可以是在训练数据上的损失,也可以是在验证数据上的损失): 给出优化目标的定义: $w^ ...
- 论文笔记之:Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation
Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation Google 2016.10.06 官方 ...
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记:(CVPR2017)PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
目录 一. 存在的问题 二. 解决的方案 1.点云特征 2.解决方法 三. 网络结构 四. 理论证明 五.实验效果 1.应用 (1)分类: ModelNet40数据集 (2)部件分割:ShapeNet ...
- 论文笔记(6):Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
这篇文章的主要贡献点在于: 1.实验证明仅仅利用图像整体的弱标签很难训练出很好的分割模型: 2.可以利用bounding box来进行训练,并且得到了较好的结果,这样可以代替用pixel-level训 ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
随机推荐
- 「题解报告」Blocks
P3503 Blocks 题解 原题传送门 思路 首先我们可以发现,若 \(a_l\) ~ \(a_r\) 的平均值大于等于 \(k\) ,则这个区间一定可以转化为都大于等于 \(k\) 的.我们就把 ...
- 前端Long类型丢失精度问题
有时候后端向前端传输Long类型,数字过长会出现丢失精度的问题 比如后端传来的是这样一个长数字串 那么前端的弹窗显示的是 :3、Maven独立插件安装与settings.xml配置
文章目录: Taurus.MVC-Java 版本打包上传到Maven中央仓库(详细过程):1.JIRA账号注册 Taurus.MVC-Java 版本打包上传到Maven中央仓库(详细过程):2.PGP ...
- haodoop数据压缩
压缩概述 压缩技术能够有效减少底层存储系统(HDFS)读写字节数.压缩提高了网络宽带和磁盘空间的效率.在运行MR程序时,I/O操作,网络数据传输,Shuffle和Merge要花大量的时间,尤其是数据规 ...
- k8s日志架构和基本日志
如果一个容器崩溃了.一个Pod被驱逐了.或者一个节点停机了,您通常仍然需要访问您应用程序的日志.为此,您需要一个生命周期与节点.Pod.容器相对独立的存储空间来存储应用程序日志和系统日志. 此时,我们 ...
- 使用Prometheus和Grafana监控RabbitMQ集群 (使用RabbitMQ自带插件)
配置RabbitMQ集群 官方文档:https://www.rabbitmq.com/prometheus.html#quick-start 官方github地址:https://github.com ...
- 第六章:Django 综合篇 - 4:django-admin和manage.py
目录 一.Django内置命令选项 check dbshell diffsettings flush makemigrations migrate runserver shell startapp s ...
- 9. Fluentd部署:日志
Fluentd是用来处理其他系统产生的日志的,它本身也会产生一些运行时日志.Fluentd包含两个日志层:全局日志和插件级日志.每个层次的日志都可以进行单独配置. 日志级别 Fluentd的日志包含6 ...
- Anaconda安装和卸载+虚拟环境Tensorflow安装以及末尾问题大全(附Anaconda安装包),这一篇就够了!!!
前言 实话说,在自己亲手捣鼓了一下午加一晚上后,本人深深地感受到了对于"Anaconda安装+虚拟环境Tensorflow安装"里面的坑点之多,再加上目前一些博主的资料有点久远,尤 ...
- [题解] Atcoder Regular Contest ARC 146 A B C D 题解
点我看题 A - Three Cards 先把所有数按位数从多到少排序,答案的位数一定等于位数最多的三个数的位数之和\(tot\).对于每个i,把有i位的数排序,并记录每个i的排序结果.最后枚举答案中 ...