在 Nebula K8s 集群中使用 nebula-spark-connector 和 nebula-algorithm
{kind=link}

解决思路
解决 K8s 部署 Nebula Graph 集群后连接不上集群问题最方便的方法是将 nebula-algorithm / nebula-spark 运行在与 nebula-operator 相同的网络命名空间里,将 show hosts meta 的 MetaD 域名:端口 格式的地址填进配置里就可以了。
注:这里需要 2.6.2 或者更新的版本,nebula-spark-connector / nebula-algorithm 才支持域名形式的 MetaD 地址。
这里来具体实操下网络配置:
- 获取 MetaD 地址
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 08:22:33 UTC
这里需要记录 Host 名以便后续的配置文件中使用该名称。
- 填写 nebula-algorithm 的配置文件
参考文档 https://github.com/vesoft-inc/nebula-algorithm/blob/master/nebula-algorithm/src/main/resources/application.conf。填写配置文件有两种方法:修改 TOML 文件或者在 nebula-spark-connector 代码中添加配置信息。
方法一:修改 TOML 文件
# ...
nebula: {
# algo's data source from Nebula. If data.source is nebula, then this nebula.read config can be valid.
read: {
# 这里填上刚获得到的 meta 的 Host 名,多个地址的话用英文字符下的逗号隔开;
metaAddress: "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559"
#...
方法二:调用 nebula-spark-connector 的代码
val config = NebulaConnectionConfig
.builder()
// 这里填上刚获得到的 meta 的 Host 名
.withMetaAddress("nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("foo_bar_space")
.withLabel("person")
.withNoColumn(false)
.withReturnCols(List("birthday"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
好的,到现在为止,过程看起来非常简单。那么,为什么这么简单的过程却值得一篇文章呢?
配置信息容易忽略的问题
刚才我们讲了具体的实际操作,但当中有一些理论小知识在这里:
a. MetaD 隐含地需要保证 StorageD 的地址能被 Spark 环境访问;
b. StorageD 地址是从 MetaD 获取的;
c. Nebula K8s Operator 里,MetaD 中存储的 StorageD 地址(服务发现)的来源是 StorageD 的配置文件,而它是 K8s 的内部地址。
背景知识
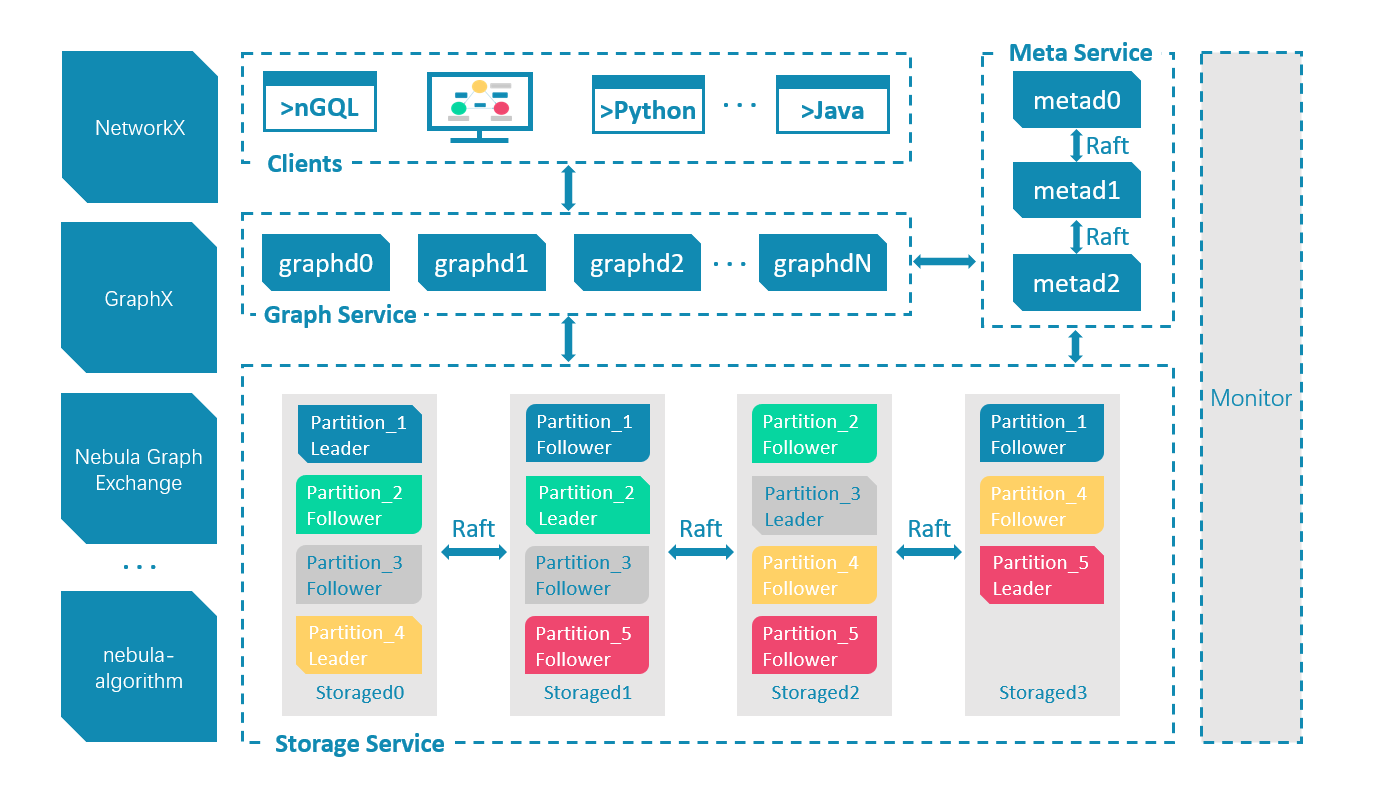
a. 的理由比较直接,和 Nebula 的架构有关:图的数据都存在 Storage Service 之中,通常用语句的查询是透过 Graph Service 来透传,只需要 GraphD 的连接就足够,而 nebula-spark-connector 使用 Nebula Graph 的场景是扫描全图或者子图,这时候计算存储分离的设计使得我们可以绕过查询、计算层直接高效读取图数据。
那么问题来了,为什么需要且只要 MetaD 的地址呢?
这也是和架构有关,Meta Service 里包含了全图的分布数据与分布式的 Storage Service 的各个分片和实例的分布,所以一方面因为只有 Meta 才有全图的信息(需要),另一方面因为从 Meta 可以获得这部分信息(只要)。到这里 b. 的答案也有了。
- 详细的 Nebula Graph 架构信息可以参考架构三部曲系列
下面我们看看 c. 背后的逻辑:
c. Nebula K8s Operator 里,MetaD 中存储的 StorageD 地址(服务发现)的来源是 StorageD 的配置文件,而它是 k8s 的内部地址。
这和 Nebula Graph 里的服务发现机制有关:在 Nebula Graph 集群中,Graph Service 和 Storage Service 都是通过心跳将自己的信息上报给 Meta Service 的,而这其中服务自身的地址的来源则来自于他们相应的配置文件中的网络配置。
关于服务自身的地址配置请参考文档:Storage networking 配置
关于服务发现详细的信息请参考四王的文章:图数据库 Nebula Graph 集群通信:从心跳说起。

最后,我们知道 Nebula Operator 是一个在 K8s 集群中按照配置,自动创建、维护、扩缩容 Nebula 集群的 K8s 控制面的应用,它需要抽象一部分内部资源相关的配置,这就包括了 GraphD 和 StorageD 实例的实际地址,他们是被配置的地址实际上是 headless service 地址。
而这些地址(如下)默认是没法被 K8s 外部网络访问的,所以针对 GraphD、MetaD 我们可以方便创建服务将其暴露出来。
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 09:22:33 UTC
(root@nebula) [(none)]> show hosts graph
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| "nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local" | 9669 | "ONLINE" | "GRAPH" | "d113f4a" | "2.6.2" |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
Got 1 rows (time spent 2072/3403 us)
Mon, 14 Feb 2022 10:03:58 UTC
(root@nebula) [(none)]> show hosts storage
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| "nebula-storaged-0.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-1.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-2.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
Got 3 rows (time spent 1603/2979 us)
Mon, 14 Feb 2022 10:05:24 UTC
然而,因为前边提到的 nebula-spark-connector 通过 Meta Service 去获取 StorageD 的地址,且这个地址是服务发现而得,所以 nebula-spark-connector 实际上获取的 StorageD 地址就是上边的这种 headless 的服务地址,没法直接从外部访问。
所以,我们在有条件的情况下,只需要让 Spark 运行在和 Nebula Cluster 相同的 K8s 网络里,一切就迎刃而解了,否则,我们需要:
将 MetaD 和 StorageD 的地址利用 Ingress 等方式将其 L4(TCP)暴露出来。
可以参考 Nebula Operator 的文档:https://github.com/vesoft-inc/nebula-operator
通过反向代理和DNS让这些 headless 服务能被解析到相应的 StorageD。
那么,有没有更方便的方式?
非常抱歉的是,目前最方便的方式依然是如文章最开头所介绍:让 Spark 运行在 Nebula Cluster 内部。实际上,我在努力推进 Nebula Spark 社区去支持可以配置的 StorageAddresses 选项,有了它之后,前边提到的 2. 就是不必要的了。
更便捷的 nebula-algorithm + nebula-operator 体验
为了方便在 K8s 上尝鲜 nebula-graph、nebula-algorithm 的同学,这里安利下本人写的一个小工具 Neubla-Operator-KinD,它是个一键在 Docker 环境内部单独部署一个 K8s 集群,并在其中部署 Nebula Operator 以及所有依赖(包括 storage provider)的小工具。不仅如此,它还会自动部署一个小的 Nebula 集群。可以看下边的步骤哈:
第一步,部署 K8s + nebula-operator + Nebula Cluster:
curl -sL nebula-kind.siwei.io/install.sh | bash
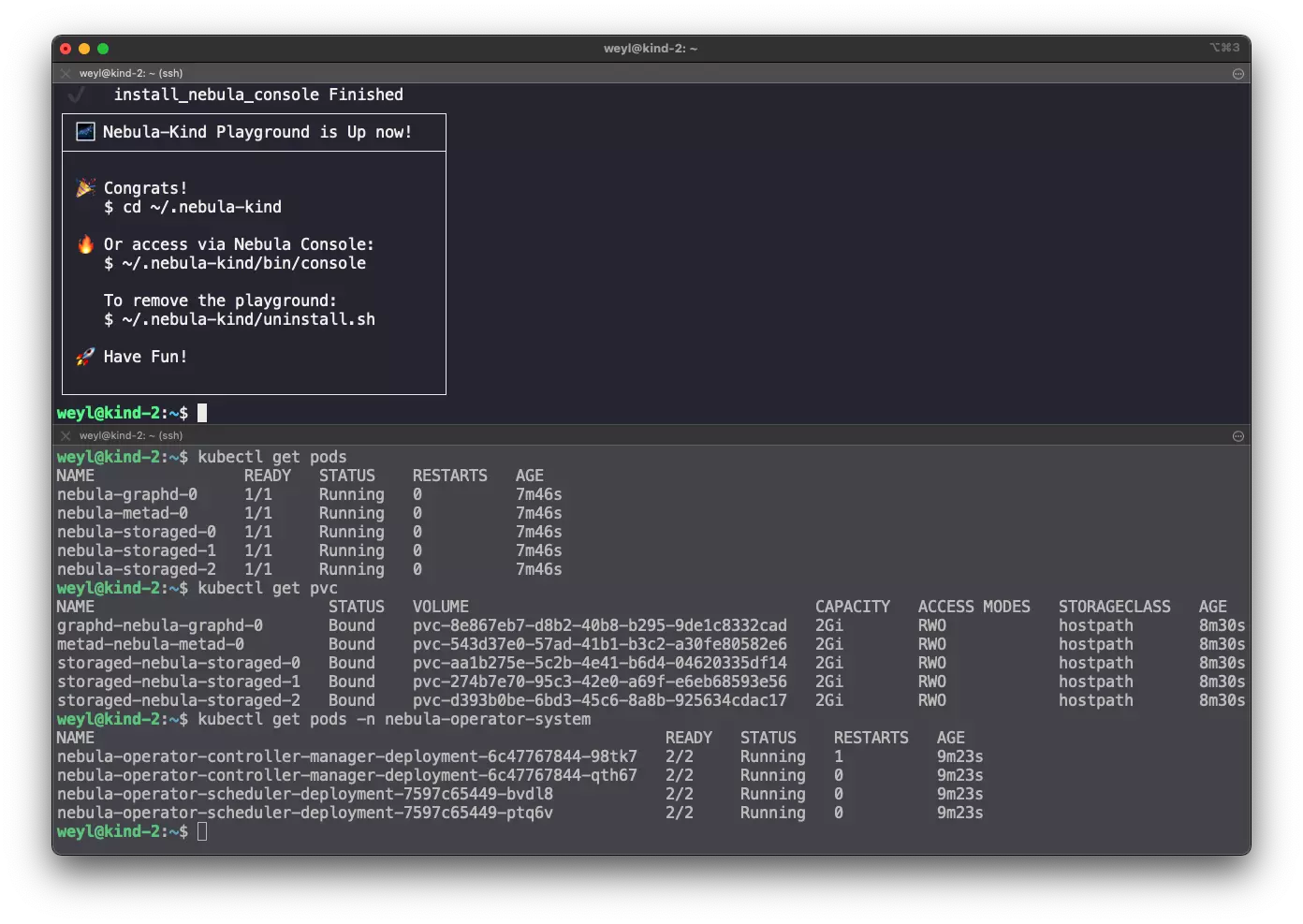
第二步,照着工具文档里的 what's next
a. 用 console 连接集群,并加载示例数据集
- 创建一个 Spark 环境
kubectl create -f http://nebula-kind.siwei.io/deployment/spark.yaml
kubectl wait pod --timeout=-1s --for=condition=Ready -l '!job-name'
- 等上边的 wait 都 ready 之后,进入 spark 的 pod。
kubectl exec -it deploy/spark-deployment -- bash
- 下载 nebula-algorithm 比如
2.6.2这个版本,更多版本请参考 https://github.com/vesoft-inc/nebula-algorithm/。
注意事项:
- 官方发布的版本在这里可以获取:https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/
- 因为这个问题:https://github.com/vesoft-inc/nebula-algorithm/issues/42 只有
2.6.2或者更新的版本才支持域名访问 MetaD。
# 下载 nebula-algorithm-2.6.2.jar
wget https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/2.6.2/nebula-algorithm-2.6.2.jar
# 下载 nebula-algorthm 配置文件
wget https://github.com/vesoft-inc/nebula-algorithm/raw/v2.6/nebula-algorithm/src/main/resources/application.conf
- 修改 nebula-algorithm 中的 mete 和 graph 地址信息。
sed -i '/^ metaAddress/c\ metaAddress: \"nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559\"' application.conf
sed -i '/^ graphAddress/c\ graphAddress: \"nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local:9669\"' application.conf
##### change space
sed -i '/^ space/c\ space: basketballplayer' application.conf
##### read data from nebula graph
sed -i '/^ source/c\ source: nebula' application.conf
##### execute algorithm: labelpropagation
sed -i '/^ executeAlgo/c\ executeAlgo: labelpropagation' application.conf
- 在 basketballplayer 图空间执行 LPA 算法
/spark/bin/spark-submit --master "local" --conf spark.rpc.askTimeout=6000s \
--class com.vesoft.nebula.algorithm.Main \
nebula-algorithm-2.6.2.jar \
-p application.conf
- 结果如下:
bash-5.0# ls /tmp/count/
_SUCCESS part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
bash-5.0# head /tmp/count/part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
_id,lpa
1100,1104
2200,2200
2201,2201
1101,1104
2202,2202
下面,你就可以 Happy Graphing 啦!
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
{kind=link}
在 Nebula K8s 集群中使用 nebula-spark-connector 和 nebula-algorithm的更多相关文章
- 【K8S学习笔记】Part2:获取K8S集群中运行的所有容器镜像
本文将介绍如何使用kubectl列举K8S集群中运行的Pod内的容器镜像. 注意:本文针对K8S的版本号为v1.9,其他版本可能会有少许不同. 0x00 准备工作 需要有一个K8S集群,并且配置好了k ...
- k8s 集群中的etcd故障解决
一次在k8s集群中创建实例发现etcd集群状态出现连接失败状况,导致创建实例失败.于是排查了一下原因. 问题来源 下面是etcd集群健康状态: [root@docker01 ~]# cd /opt/k ...
- 将 master 节点服务器从 k8s 集群中移除并重新加入
背景 1 台 master 加入集群后发现忘了修改主机名,而在 k8s 集群中修改节点主机名非常麻烦,不如将 master 退出集群改名并重新加入集群(前提是用的是高可用集群). 操作步骤 ssh 登 ...
- k8s集群中遇到etcd集群故障的排查思路
一次在k8s集群中创建实例发现etcd集群状态出现连接失败状况,导致创建实例失败.于是排查了一下原因. 问题来源 下面是etcd集群健康状态: 1 2 3 4 5 6 7 8 9 10 11 [roo ...
- k8s集群中部署prometheus server
1.概述 本文档主要介绍如何在k8s集群中部署prometheus server用来作为监控的数据采集服务器,这样做可以很方便的对k8s集群中的指标.pod的.节点的指标进行采集和监控. 2.下载镜像 ...
- 如何在 Serverless K8s 集群中低成本运行 Spark 数据计算?
作者 | 柳密 阿里巴巴阿里云智能 ** 本文整理自<Serverless 技术公开课>,关注"Serverless"公众号,回复"入门",即可获取 ...
- 实操教程丨如何在K8S集群中部署Traefik Ingress Controller
注:本文使用的Traefik为1.x的版本 在生产环境中,我们常常需要控制来自互联网的外部进入集群中,而这恰巧是Ingress的职责. Ingress的主要目的是将HTTP和HTTPS从集群外部暴露给 ...
- 终于解决 k8s 集群中部署 nodelocaldns 的问题
自从开始在 kubernetes 集群中部署 nodelocaldns 以提高 dns 解析性能以来,一直被一个问题困扰,只要一部署 nodelocaldns ,在 coredns 中添加的 rewr ...
- k8s集群中部署Rook-Ceph高可用集群
先决条件 为确保您有一个准备就绪的 Kubernetes 集群Rook,您可以按照这些说明进行操作. 为了配置 Ceph 存储集群,至少需要以下本地存储选项之一: 原始设备(无分区或格式化文件系统) ...
随机推荐
- 关于C++ scanf的一个小知识
关于C++的scanf,其实在使用时有一个注意的点. 我们来看一个简单的例子. 对于输入的一行,如果这一行的开头需要输入一个字符,例如这样的输入: A 10 20 B 30 A 3 50 ... 我们 ...
- Thread中常用API
1.sleep方法 线程的 sleep 方法会使线程休眠指定的时间长度.休眠的意思是,当前逻辑执行到此不再继续执行,而是等待指定的时间.但在这段时间内,该线程持有的锁并不会释放.这样设计很好理解,因为 ...
- wget: unable to resolve host address ‘dl.grafana.com’的解决方法
[root@Server-qnrsyp system]# wget --no-check-certificate https://dl.grafana.com/oss/release/grafana_ ...
- Mysql Json函数之搜索 (三)
本节中的函数对JSON值执行搜索操作,以从其中提取数据,报告数据是否在其中的某个位置或报告其中的数据的路径. JSON_CONTAINS(target, candidate[, path]) 通过返回 ...
- 使用C++开发PHP扩展
目前,PHP编程语言也是相当成熟,各种文档,各种问题,只要Google一下,总有你想要的答案.当然"如何开发PHP扩展"的文章也不少,但是很少有专门来介绍使用C++开发PHP扩展的 ...
- 聊天泡泡(仿微信)By-H罗
在做私信时,聊天泡泡仿着QQ做时,聊天泡泡底图有露出,不怎么好看,微信的就比较好看,当时就因为那2行纠结了好久 - (void)viewDidLoad { [super viewDidLoad]; / ...
- 计算机网络再次整理————tcp周边[八]
前言 tcp的包的格式可以看我以前的计算机网络整理,下面这些周边只是为了开发时候我们能用到一些理论知识. 正文 首先要介绍的就是域名,为啥有域名这东西呢?单纯站在网络的角度上讲这属于应用层的东西了. ...
- shell——wait与多进程并发
在脚本里用&后台打开多个子进程,用wait命令可以使这些子进程并行执行. 例1: fun1(){ while true do echo 1 sleep 1 done } fun2(){ whi ...
- Java中Arrays数组工具类的使用全解
本文几乎涵盖了所有的Arrays工具类(基于Java 11)的方法以及使用用例,一站式带你了解Arrays类的用法,希望对大家有帮助. 码字不易,三连支持一下吧 Arrays数组工具类 方法一览表 快 ...
- 剑指Offer系列_30_包含min函数的栈
以空间换时间: package leetcode.sword_to_offfer.day01; import java.util.Stack; /** * 定义栈的数据结构,请在该类型中实现一个能够得 ...