navicat软件、 python操作MySQL
查询关键字之having过滤
having与where的功能是一模一样的 都是对数据进行筛选
where用在分组之前的筛选
havng用在分组之后的筛选
为了更好的区分 所以将where说成筛选 havng说成过滤
# 统计每个部门年龄在30岁以上的员工平均薪资并且保留平均薪资大于10000的部门
'''编写SQL语句 不要指望着一步到位 边写边看慢慢拼凑'''
# 1.先获取每个部门年龄在30岁以上的员工的平均薪资
先筛选出30岁以上的员工数据 然后再对数据进行分组
# 2.在过滤出平均薪资大于10000的数据
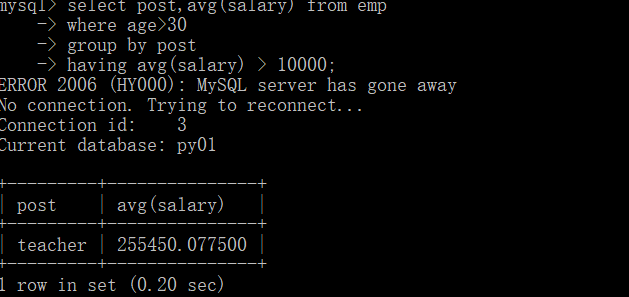
select post,avg(salary) from emp
where age>30
group by post
having avg(salary) > 10000;
'''针对聚合函数 如果还需要在其他地方作为条件使用 可以先起别名'''
select post,avg(salary) as avg_salary from emp
where age>30
group by post
having avg_salary > 10000
查询关键字之distinct去重
# 去重的前提 数据必须是一模一样的才可以(如果数据有主键肯定无法去重)
select distinct age from emp;
"""
等我们学到django orm之后 数据会被封装成对象
那个时候主键很容易被我们忽略 从而导致去重没有效果!!!
"""
查询关键字之order by排序
# 1.按照薪资高低排序
select * from emp order by salary; # 默认是升序(从大到小)
select * from emp order by salary asc; # 关键字asc 可以省略
select * from emp order by salary desc; # 降序(从大到小)
# 2.先按照年龄升序排序 如果年龄相同 则再按照薪资降序排序
select * from emp order by age asc,salary desc;
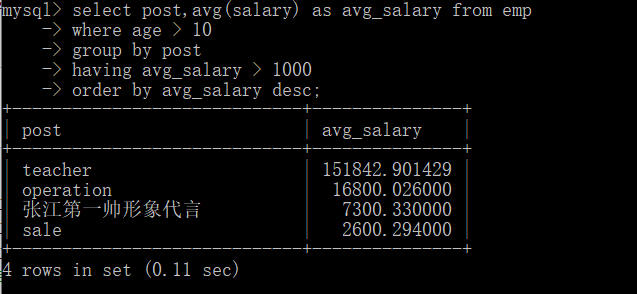
# 3.统计各部门年龄在10岁以上的员工平均工资 并且保留平均工资大于1000的部门并按照从大到小的顺序排序
select post,avg(salary) as avg_salary from emp
where age > 10
group by post
having avg_salary > 1000
order by avg_salary desc;
查询关键字之limit分页
# 分页即限制展示条数
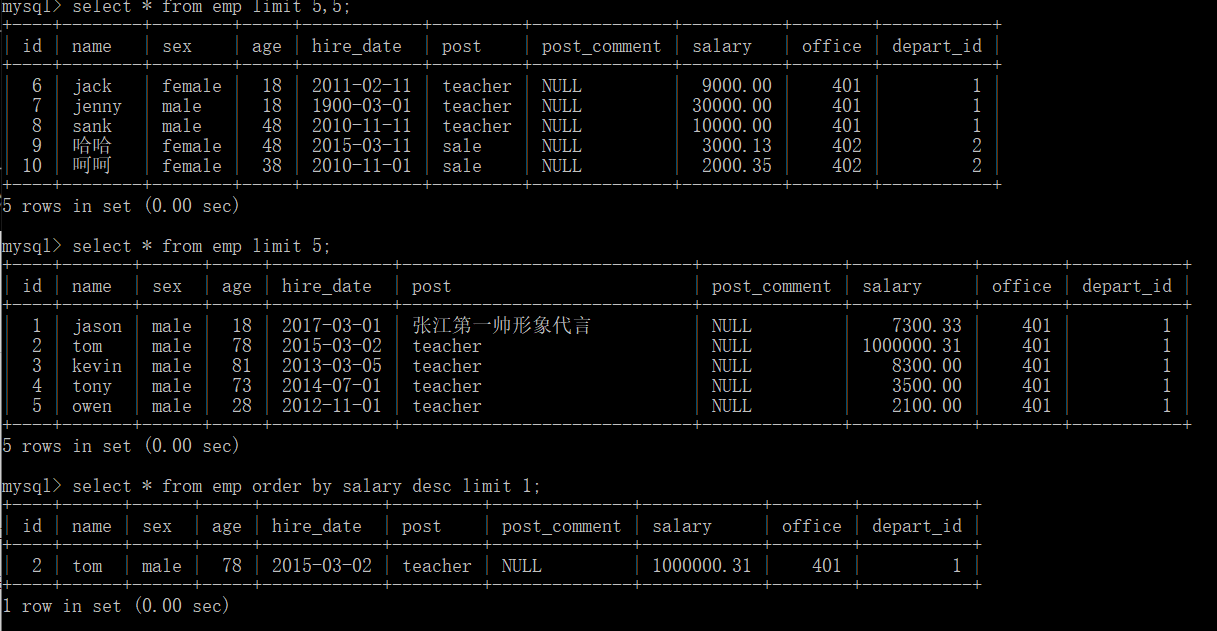
# 1.限制只展示五条数据
select * from enp limit 5;
# 2.分页效果
select * from emp limit 5,5;
# 3.查询工资最高的人的详细信息
select * from emp order by salary desc limit 1;
"""
当数据特别多的时候 经常使用limit来限制展示条数 节省资源 防止系统崩溃
"""
查询关键字之regexp正则
select * from emp where name regexp '^j.*(n|y)$';
"""
补充说明:我们目前所讲的是MySQL查询关键字中使用频率较高的一些
其实还有一些关键字目前无需讲解 并且SQL语句里面同样还支持流程控制语法
"""

多表查询思路
# 多表查询的思路总共就两种
1.子查询
就相当于是我们日常生活中解决问题的方式(一步步解决)
将一条SQL语句的查询结果加括号当做另外一条SQL语句的查询条件
eg:以昨天的员工表和部门表为例 查询jason所在的部门名称
子查询的步骤
1.先查jason所在的部门编号
2.根据部门编号去部门表中查找部门名称 2.连表操作
先将多张表拼接到一起 形成一张大表 然后基于单表查询获取数据
eg:以昨天的员工表和部门表为例 查询jason所在的部门名称
连表操作
1.先将员工表和部门表按照某个字段拼接到一起
2.基于单表查询
# 实际演练
create table dep(
id int primary key auto_increment,
name varchar(32));
create table emp(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female') default 'male',
age int,
dep_id int);
insert into dep values(200,'技术'),(201,'人力资源'),(202,'销售'),(203,'运营'),(205,'保安');
insert into emp(name, age, dep_id) values('jason',18,200),('tony',28,201),('kvein',39,203),('jack',48,204);
# 使用子查询 获取jason所在的部门名称
# 1.先获取jason的部门编号
select dep_id from emp where name='jason';
# 2.将结果加括号作为查询条件
select name from dep where id=(select dep_id from emp where name='jason');
# 使用连表操作 获取jason所在的部门名称
笛卡尔积(了解知识)
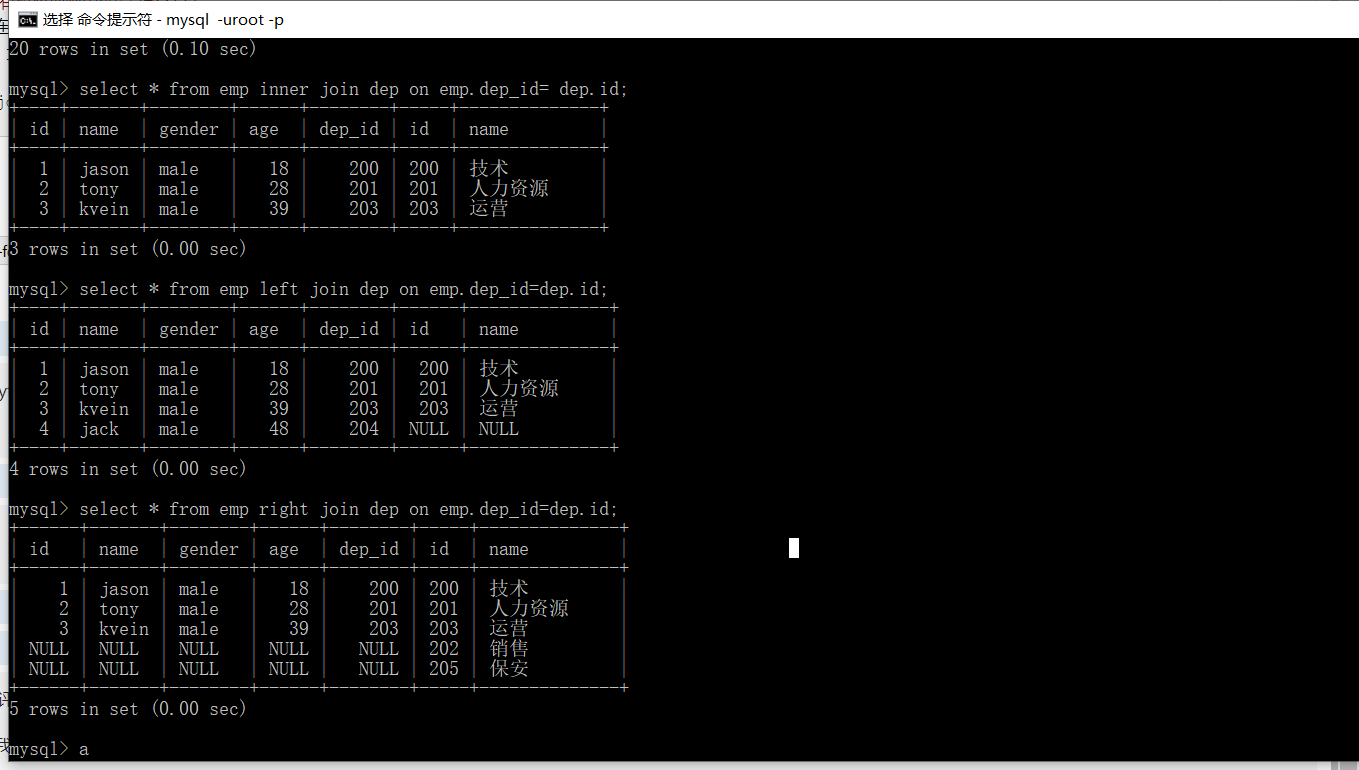
select * from emp,dep; # 会讲所有的数据全部对应一遍
select * from emp,dep where emp.dep_id=dep.id; # 效率低下
"""
1.一条SQL语句的查询结果 我们也可以看成是一张虚拟表
2.如果一条SQL语句中设计到多张表的字段名称编写 建议使用表名前缀做区分
"""
连表操作有四个关键字
inner join 内连接
select * from emp inner join dep on emp.dep_id= dep.id;
'''只连接两张表中有对应关系的数据'''
left join 左链接
select * from emp left join dep on emp.dep_id=dep.id;
'''以左表为基准 展示所有的数据 没有对应项则用NULL填充'''
right join 右链接
select * from right emp join dep on emp.dep_id=dep.id;
'''以右表为基准 展示所有的数据 没有对应项则用NULL填充'''
union 全连接
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
'''左右两表数据全部展示 没有对应项则用NULL填充'''
答案求解
select dep.name from emp
inner join dep on emp.dep_id=dep.id
where emp.name='jason';
"""
了解
我们学会了连表操作之后 其实就可以将N多张表拼接到一起
思路:我们可以将两张表拼接之后的结果起别名当做一张表使用
然后再去跟另外一张表拼接
select * from emp inner join
(select emp.id as epd,emp.name,dep.id from emp inner join dep on emp.dep_id=dep.id) as t1
on emp.id=t1.epd;
"""
可视化软件之Navicat
Navicat可以充当很多数据库软件的客户端 提供了图形化界面能够让我们更加快速操作数据库
# 下载
navicat有很多版本 并且都是默认都是收费使用
正版可以免费体验14天
针对这种图形化软件 版本越新越好(不同版本图标颜色不一样 但是主题功能是一样的)
# 使用
内部封装了SQL语句 用户只需要鼠标点点点就可以快速操作
连接数据库 创建库和表 录入数据 操作数据
外键 SQL文件 逆向数据库到模型 查询(自己写SQL语句)
# 使用navicat编写SQL 如果自动补全语句 那么关键字都会变大写
SQL语句注释语法(快捷键与pycharm中的一致 ctrl+?)
#
--
# 运行SQL文件
多表查询练习题
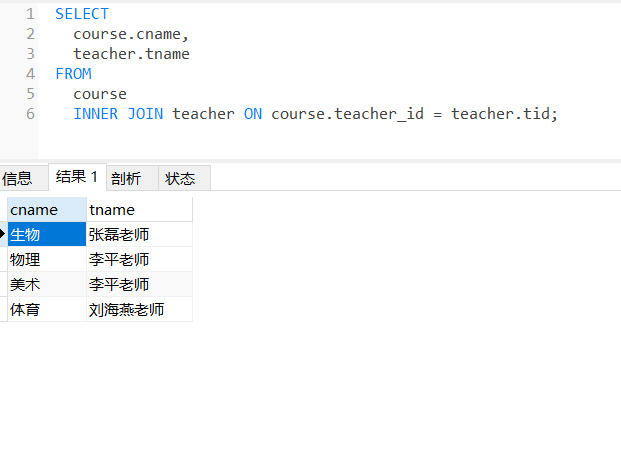
1、查询所有的课程的名称以及对应的任课老师姓名
SELECT
course.cname,
teacher.tname
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid;

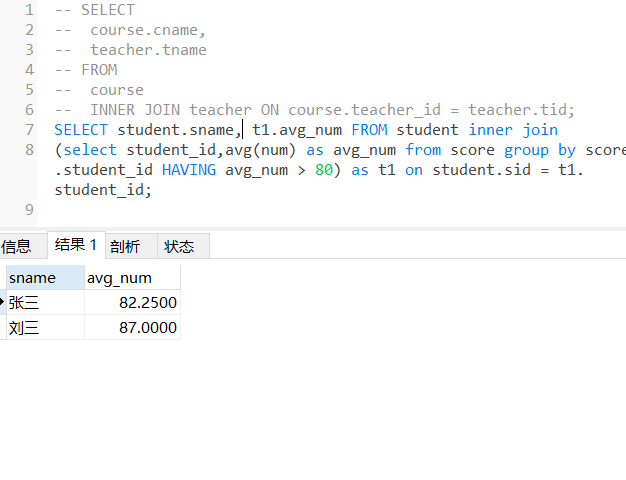
4、查询平均成绩大于八十分的同学的姓名和平均成绩
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN ( SELECT student_id, avg( num ) AS avg_num FROM score GROUP BY score.student_id HAVING avg_num > 80 ) AS t1 ON student.sid = t1.student_id;
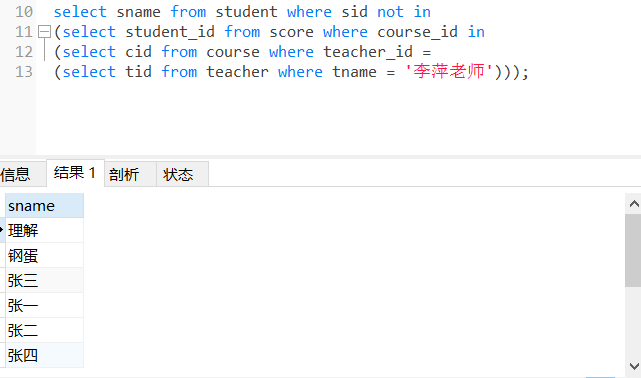
7、查询没有报李平老师课的学生姓名
select sname from student where sid not in
(select student_id from score where course_id in
(select cid from course where teacher_id =
(select tid from teacher where tname = '李萍老师')));
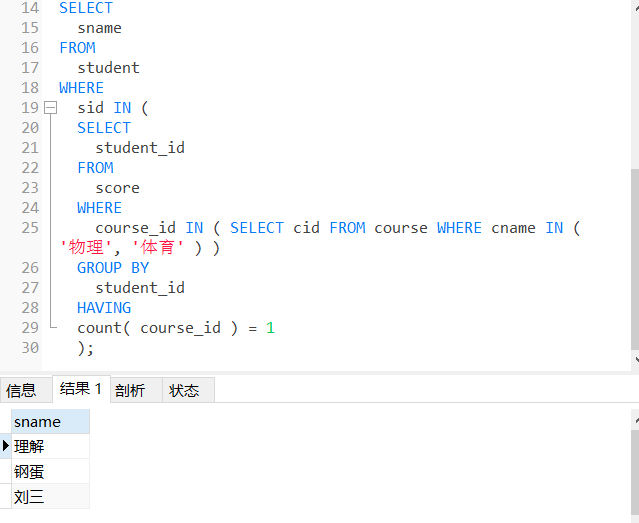
8、查询没有同时选修物理课程和体育课程的学生姓名(两门都选了和一门都没选的 都不要 只要选了一门)
SELECT
sname
FROM
student
WHERE
sid IN (
SELECT
student_id
FROM
score
WHERE
course_id IN ( SELECT cid FROM course WHERE cname IN ( '物理', '体育' ) )
GROUP BY
student_id
HAVING
count( course_id ) = 1
);
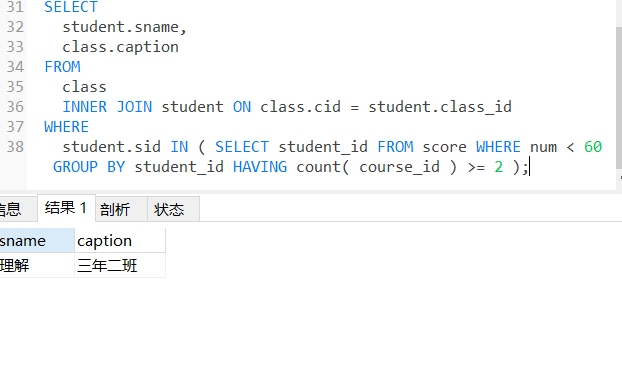
9、查询挂科超过两门(包括两门)的学生姓名和班级
SELECT
student.sname,
class.caption
FROM
class
INNER JOIN student ON class.cid = student.class_id
WHERE
student.sid IN ( SELECT student_id FROM score WHERE num < 60 GROUP BY student_id HAVING count( course_id ) >= 2 );
navicat软件、 python操作MySQL的更多相关文章
- 多表查询思路、navicat可视化软件、python操作MySQL、SQL注入问题以及其他补充知识
昨日内容回顾 外键字段 # 就是用来建立表与表之间的关系的字段 表关系判断 # 一对一 # 一对多 # 多对多 """通过换位思考判断""" ...
- Python全栈开发之MySQL(二)------navicate和python操作MySQL
一:Navicate的安装 1.什么是navicate? Navicat是一套快速.可靠并价格相宜的数据库管理工具,专为简化数据库的管理及降低系统管理成本而设.它的设计符合数据库管理员.开发人员及中小 ...
- navicat软件设置连接mysql数据库
navicat软件设置连接mysql数据库 适用范围及演示使用工具 适用范围:mysql全部系列(含Linux和Windows系统下的mysql) 演示使用工具:Navicat 8.0 MySQL 演 ...
- Python操作MySQL数据库(步骤教程)
我们经常需要将大量数据保存起来以备后续使用,数据库是一个很好的解决方案.在众多数据库中,MySQL数据库算是入门比较简单.语法比较简单,同时也比较实用的一个.在这篇博客中,将以MySQL数据库为例,介 ...
- Python(九) Python 操作 MySQL 之 pysql 与 SQLAchemy
本文针对 Python 操作 MySQL 主要使用的两种方式讲解: 原生模块 pymsql ORM框架 SQLAchemy 本章内容: pymsql 执行 sql 增\删\改\查 语句 pymsql ...
- 练习:python 操作Mysql 实现登录验证 用户权限管理
python 操作Mysql 实现登录验证 用户权限管理
- Python操作MySQL
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb ...
- Python操作Mysql之基本操作
pymysql python操作mysql依赖pymysql这个模块 下载安装 pip3 install pymysql 操作mysql python操作mysql的时候,是通过”游标”来进行操作的. ...
- python成长之路【第十三篇】:Python操作MySQL之pymysql
对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎 ...
- python操作mysql数据库的相关操作实例
python操作mysql数据库的相关操作实例 # -*- coding: utf-8 -*- #python operate mysql database import MySQLdb #数据库名称 ...
随机推荐
- IOC——Spring的bean的管理(注解方式)
注解(简单解释) 1.代码里面特殊标记,使用注解可以完成一定的功能 2.注解写法 @注解名称(属性名称=属性值) 3.注解使用在类上面,方法上面和属性上面 注意:注解方式不能完全替代配置文件方式 Sp ...
- js技术之如何在JS中获取input的值
在JavaScript中获取input元素value的值: 方法一:var variations_number = $("#input的id名").val(); 1 <!DO ...
- 《剑指offer》面试题4:替换空格
面试题4:替换空格 题目:请实现一个函数,把字符串中的每个空格替换成"%20",例如输入"We are happy.",则输出"we%20are%20 ...
- 无人车系统仿真相关软件介绍-dSPACE
今天本来是想简单的介绍一下dSPACE的Automotive simulation models(简称ASM),但是想想还是把dSPACE这个公司的整个开发流程写一下.这样也可以了解一下汽车的整个软件 ...
- css流程图、步骤图,流程线与环节分别实现,支持单环节、多环节情况。scss生成CSS
适用于分步骤操作的页面导航图 实现结果如下 上图对应下述代码,稍作修改可以生成下图.css代码如下: @charset "UTF-8"; /**单列宽度 单行高度 列数 行数*/ ...
- 移动端——touch事件
1.touchstart 当手指触碰屏幕时候触发 dom.addEventListener('touchstart',function(e){}); startX=e.touches[0].clien ...
- java中接口到底是干什么的,怎么用,深入剖析
6.总结性深一层次综合剖析接口概念[新手可忽略不影响继续学习] 通过以上的学习, 我们知道,所有定义在接口中的常量都默认为public.static和final.所有定义在接口中的方法默认为publi ...
- jsp笔记---标签
<meta>标签 <meta> 标签提供了 HTML 文档的元数据.元数据不会显示在客户端,但是会被浏览器解析. META元素通常用于指定网页的描述,关键词,文件的最后修改时间 ...
- 没有高度的div中的子元素高度自动撑开
直接上代码: 很多时候 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&q ...
- 手撕spring核心源码,彻底搞懂spring流程
引子 十几年前,刚工作不久的程序员还能过着很轻松的日子.记得那时候公司里有些开发和测试的女孩子,经常有问题解决不了的,不管什么领域的问题找到我,我都能帮她们解决.但是那时候我没有主动学习技术的意识,只 ...