【python疫情可视化】用pyecharts开发全国疫情动态地图,效果酷炫!
一、效果演示
我用python开发了一个动态疫情地图,首先看下效果: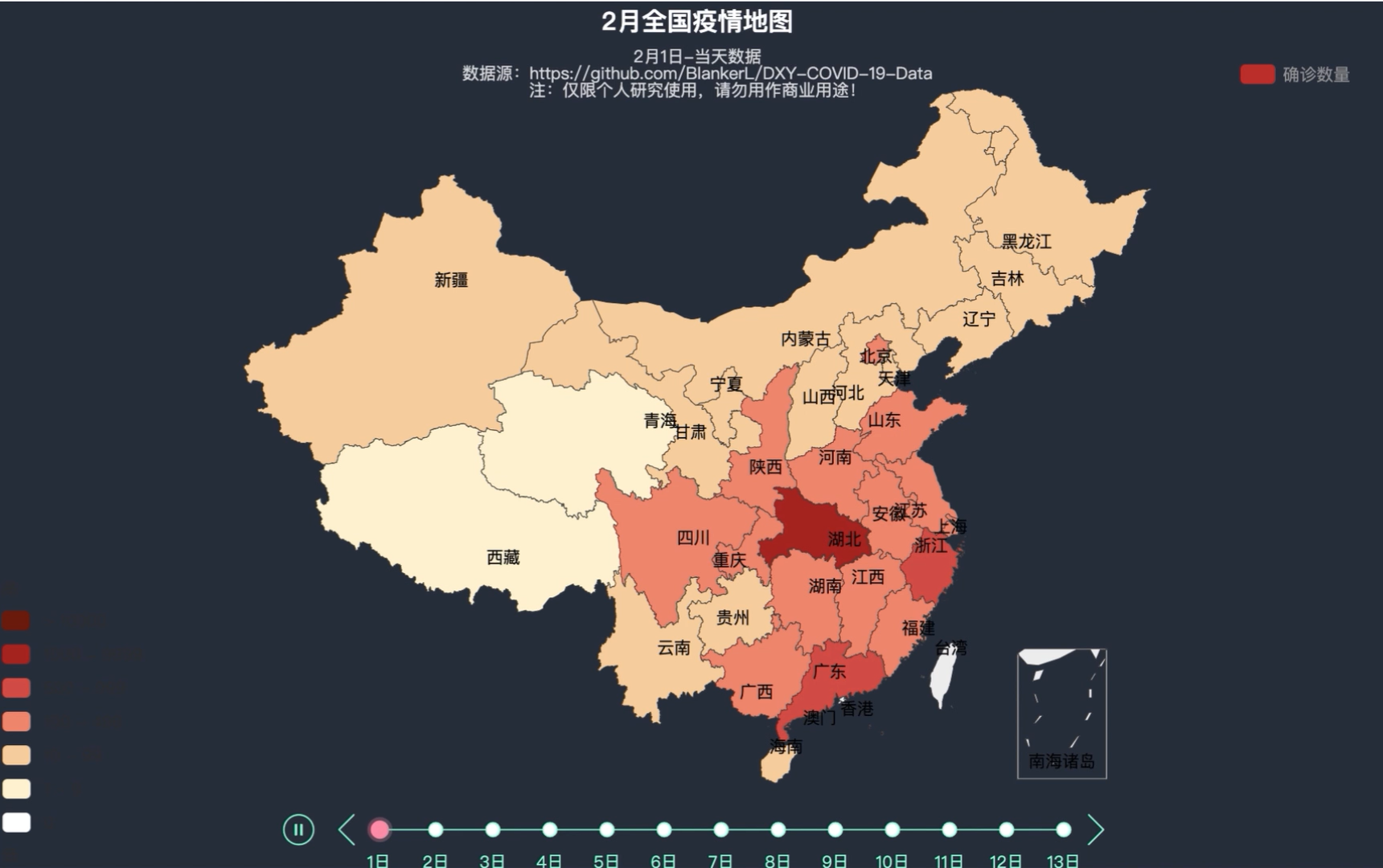
如图所示,地图根据实时数据通过时间线轮播的方式,动态展示数据的变化。随着时间的推移,疫情确诊数量的增多,地图各个省份颜色逐渐加深,可以很明显地看到动态可视化效果。
这个动态疫情地图,是通过python的第三方库pyecharts制作完成的。数据来源是github上的一位大神:
https://github.com/BlankerL/DXY-COVID-19-Data
在此,感谢github作者整理的数据来源,方便我们数据分析人员使用。
针对此数据源,我还开发了一个定时自动下载疫情数据的python脚本,有兴趣的小伙伴可以滴滴我。
二、代码分解
下面,通过python代码(部分核心代码)逐一分解,这个动态疫情地图是怎样实现的:
首先,导入需要的库:
import pandas as pd # 用于读取excel文件from pyecharts import options as opts # 可视化选项from pyecharts.charts import Timeline, Map # 时间线、地图from pyecharts.globals import ThemeType # 图表主题
然后,定义好数据源文件,并做一些初始的数据清洗、数据预处理工作:
# 数据源文件src_file = 'DXYArea_0214.xls'# 中间文件mid_file = 'to_csv4.csv'# 疫情地图所用颜色list_color = ['#F4AD8B', '#EF826F', '#EE806E', '#BD3932', '#801D17']# 读取数据df = pd.read_excel(io=src_file, usecols=['provinceName','province_confirmedCount','updateTime'],) # 读取数据源df['updateTime'] = df['updateTime'].astype(str).str[0:10]df2 = df.groupby(['provinceName', 'updateTime']).apply(lambda t: t[t.province_confirmedCount == t.province_confirmedCount.max()]) # 按省份日期分组统计确诊数量df2 = df2[['provinceName', 'province_confirmedCount', 'updateTime']]df2 = df2.drop_duplicates() # 删除重复值df2 = df2.reset_index(drop=True) # 重置索引df2.to_csv(mid_file, index=False) # 保存csvdf3 = pd.read_csv(mid_file)
筛选出指定日期的数据,并做一定的数据处理,供后续可视化代码读取调用:
# 筛选出指定日期的数据df_20200201 = df3[df3['updateTime'].str.contains("2020-02-01")]df_20200202 = df3[df3['updateTime'].str.contains("2020-02-02")]df_20200203 = df3[df3['updateTime'].str.contains("2020-02-03")]df_20200204 = df3[df3['updateTime'].str.contains("2020-02-04")]df_20200205 = df3[df3['updateTime'].str.contains("2020-02-05")]df_20200206 = df3[df3['updateTime'].str.contains("2020-02-06")]df_20200207 = df3[df3['updateTime'].str.contains("2020-02-07")]df_20200208 = df3[df3['updateTime'].str.contains("2020-02-08")]df_20200209 = df3[df3['updateTime'].str.contains("2020-02-09")]df_20200210 = df3[df3['updateTime'].str.contains("2020-02-10")]df_20200211 = df3[df3['updateTime'].str.contains("2020-02-11")]df_20200212 = df3[df3['updateTime'].str.contains("2020-02-12")]df_20200213 = df3[df3['updateTime'].str.contains("2020-02-13")]
最后,也是最关键的代码,可视化地图部分:
def timeline_map() -> Timeline:tl = Timeline(init_opts=opts.InitOpts(page_title="疫情地图4",theme=ThemeType.CHALK,width="1000px", height="620px"),)for idx in range(0, 13):provinces = []confirm_value = []for item_pv in df_list[idx]['provinceName']:provinces.append(item_pv)for item_pc in df_list[idx]['province_confirmedCount']:confirm_value.append(item_pc)zipped = zip(provinces, confirm_value)f_map = (Map(init_opts=opts.InitOpts(width="900px",height="500px",page_title="疫情地图4",bg_color=None)).add(series_name="确诊数量",data_pair=[list(z) for z in zipped],maptype="china",is_map_symbol_show=False).set_global_opts(title_opts=opts.TitleOpts(title="2月全国疫情地图",subtitle="2月{}日-当天数据\n""数据源:https://github.com/BlankerL/DXY-COVID-19-Data\n""注:仅限个人研究使用,请勿用作商业用途!".format(idx + 1),pos_left="center", ),legend_opts=opts.LegendOpts(is_show=True, pos_top="40px", pos_right="30px"),visualmap_opts=opts.VisualMapOpts(is_piecewise=True, range_text=['高', '低'], pieces=[{"min": 10000, "color": "#751d0d"},{"min": 1000, "max": 9999, "color": "#ae2a23"},{"min": 500, "max": 999, "color": "#d6564c"},{"min": 100, "max": 499, "color": "#f19178"},{"min": 10, "max": 99, "color": "#f7d3a6"},{"min": 1, "max": 9, "color": "#fdf2d3"},{"min": 0, "max": 0, "color": "#FFFFFF"}]),).set_series_opts(label_opts=opts.LabelOpts(is_show=True),markpoint_opts=opts.MarkPointOpts(symbol_size=[90, 90], symbol='circle'),effect_opts=opts.EffectOpts(is_show='True', )))tl.add(f_map, "{}日".format(idx + 1))tl.add_schema(is_timeline_show=True, # 是否显示play_interval=800, # 播放间隔symbol=None, # 图标is_loop_play=True # 循环播放)return tl
核心代码就是这些,执行成功之后,就是这样的效果啦:
【python疫情可视化】用pyecharts开发全国疫情动态地图,效果酷炫!的更多相关文章
- 【python可视化系列】python数据可视化利器--pyecharts
学可视化就跟学弹吉他一样,刚开始你会觉得自己弹出来的是噪音,也就有了在使用python可视化的时候,总说,我擦,为啥别人画的图那么溜: [python可视化系列]python数据可视化利器--pyec ...
- python数据可视化:pyecharts
发现了一个做数据可视化非常好的库:pyecharts.非常便捷好用,大力推荐!! 官方介绍:pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 ...
- Python数据可视化实战:实时更新海外疫情数据,实现数据可视化
前言 我国的疫情已经得到了科学的控制,开始了全面的复工复产,但是国外的疫情却“停不下来”.国外现在可谓就是处于水深火热当中啊,病毒极强的传染性,导致了许多的人都“中招”了,我国已经全面复工复产了,人大 ...
- 【疫情动态条形图】用Python开发全球疫情排名动态条形图bar_chart_race
一.开发背景 你好,我是 @马哥python说 ,这是我用Python开发的全球疫情动态条形图,演示效果: https://www.zhihu.com/zvideo/15603276220259696 ...
- Codevs 1218 疫情控制 2012年NOIP全国联赛提高组
1218 疫情控制 2012年NOIP全国联赛提高组 时间限制: 2 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description H 国有 n 个城市,这 ...
- 如何使用Python快速制作可视化报表----pyecharts
如何使用Python快速制作可视化报表 数据可视化能力已经越来越成为各岗位的基础技能.领英的数据报告显示,数据可视化技能在2017年中国最热门技能中排名第一. 就数据分析而言,可视化探索几乎是你正 ...
- (数据科学学习手札108)Python+Dash快速web应用开发——静态部件篇(上)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札121)Python+Dash快速web应用开发——项目结构篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- Python数据可视化编程实战pdf
Python数据可视化编程实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1vAvKwCry4P4QeofW-RqZ_A 提取码:9pcd 复制这段内容后打开百度 ...
随机推荐
- SynchronizedMap 和 ConcurrentHashMap 有什么区 别?
SynchronizedMap 一次锁住整张表来保证线程安全,所以每次只能有一个线程来 访为 map. ConcurrentHashMap 使用分段锁来保证在多线程下的性能. ConcurrentHa ...
- CAS 的问题 ?
1.CAS 容易造成 ABA 问题 一个线程 a 将数值改成了 b,接着又改成了 a,此时 CAS 认为是没有变化,其实 是已经变化过了,而这个问题的解决方案可以使用版本号标识,每操作一次 versi ...
- 对于 GC 方面,在使用 Elasticsearch 时要注意什么?
1.SEE:https://elasticsearch.cn/article/32 2.倒排词典的索引需要常驻内存,无法 GC,需要监控 data node 上 segmentmemory 增长趋势. ...
- Elasticsearch 在部署时,对 Linux 的设置有哪些优化方 法?
1.64 GB 内存的机器是非常理想的, 但是 32 GB 和 16 GB 机器也是很常见的. 少于 8 GB 会适得其反. 2.如果你要在更快的 CPUs 和更多的核心之间选择,选择更多的核心更好. ...
- CPF 使用C#的Native AOT 发布程序
微软已经将AOT的包移到Nuget了,之前是在实验测试服务器上的.并且由之前的alpha版本改成了preview版本. C#的开发效率,接近C++的运行效率,而且可以防止反编译,可以支持大部分反射功能 ...
- python学习笔记(五)——静态方法、类方法、运算符重载
我们都知道类名是不能够直接调用类方法的.在C++中,把成员方法声明为 static 静态方法后可以通过类名调用.同样的在python中也可以通过定义静态方法的方式让类名直接调用. 静态方法 使用 @s ...
- printf()函数压栈a++与++a的输出
printf()中a++与++a的输出问题 在C语言中有个很常用的函数printf(),使用时从右向左压栈,也就是说在printf("%d %d %d %d\n",a,a++,++ ...
- 关于css中选择器的小归纳(一)
关于css中选择器的小归纳 一.基本选择器 基本选择器是我们平常用到的最多的也是最便捷的选择器,其中有元素选择器(类似于a,div,body,ul),类选择器(我们在HTML标签里面为其添加的clas ...
- javaweb之连接数据库
最近做完了一个图书系统的增删改查,想着来总结一下这几个月的所学内容. 一.首先你需要在电脑上安装上mysql或者sql server(本文以mysql为例) mysql官网:MySQL :: Begi ...
- hive启动出错
Hive启动报错:java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument - 狗子的进阶史 - ...