协程Part1-boost.Coroutine.md
首先,在计算机科学中 routine 被定义为一系列的操作,多个 routine 的执行形成一个父子关系,并且子 routine 一定会在父 routine 结束前结束,也就是一个个的函数执行和嵌套执行形成了父子关系。
coroutine 也是广义上的 routine,不同的是 coroutine 能够通过一些操作保持执行状态,显式地挂起和恢复,相对于 routine 的单控制流,coroutine 能提供一个加强版的控制流。
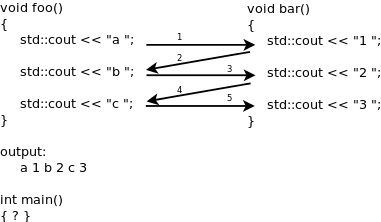
协程执行转移
如图中的处理流程,多个 coroutine 通过一些机制,首先执行 routine foo 上的 std::cout << "a" 然后切换到 routine bar 上执行 std::cout << "b",再切换回 routine foo 直到两个 routine 都执行完成。
coroutine 如何运行?
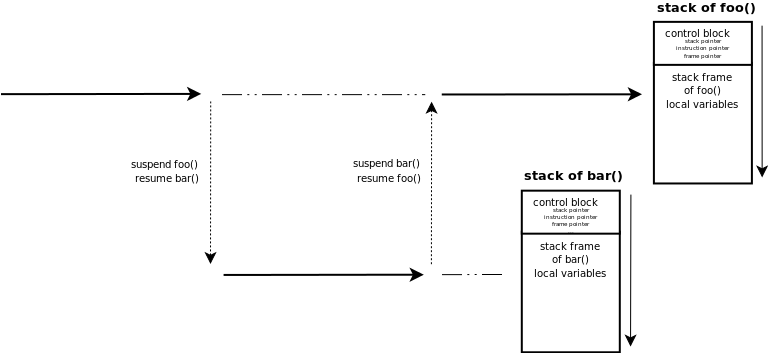
通常每个 corotuine 都有自己的 stack 和 control-block,类似于线程有自己的线程栈和control-block,当协程触发切换的时候,当前 coroutine 所有的非易失(non-volatile)寄存器都会存储到 control-block 中,新的 coroutine 需要从自己相关联的 control-block 中恢复。
协程的分类
A. 根据协程的执行转移机制可以分为非对称协程和对程协程:
- 非对称协程能知道其调用方,调用一些方法能让出当前的控制回到调用方手上。
- 对程协程都是平等的,一个对程协程能把控制让给任意一个协程,因此,当对称协程让出控制的时候,必须指定被让出的协程是哪一个。
B. 根据运行时协程栈的分配方式又能分为有栈协程和无栈协程:
通常情况下,有栈协程比无栈协程的功能更加强大,但是无栈协程有更高的效率,除此之外还有下面这些区别:
有栈协程能够在嵌套的栈帧中挂起并且在之前嵌套的挂起点恢复,而无栈协程只有最外层的 coroutine 才能够挂起,由顶层 routine 调用的 sub-routine 是不能够被挂起的。
有栈协程通常需要分配一个确定且固定的内存用来适配 runtime-stack,上下文的切换的时候相比于无栈协程也更加消耗资源,比如无栈协程仅仅只需要存储一个程序计数器(EIP)。有栈协程在语言(编译器)的支持下,有栈协程能够利用编译期计算得到非递归协程栈的最大大小,因此,内存的使用方面能够有所优化。无栈协程,不是代表没有运行时的栈,无栈只是代表着无栈协程所使用的栈是当前所在上下文的栈(比如一个函数 ESP~EBP 的区间内),所以能够正常调用递归函数。相反,有栈协程调用递归函数的时候,所使用的栈是该协程所申请的栈。
分三个方面来总结的话就是:
内存资源使用:无栈协程借助函数的栈帧来存储一些寄存器状态,可以调用递归函数。而有栈协程会要申请一个内存栈用来存储寄存器信息,调用递归函数可能会爆栈。
速度:无栈协程的上下文比较少,所以能够进行更快的用户态上下文切换。
功能性:有栈协程能够在嵌套的协程中进行挂起/恢复,而无栈协程只能对顶层的协程进行挂起,被调用方是不能挂起的。
Boost.Coroutine
C++ Boost 库在 2009 年就提供了一个子库叫做 Boost.Coroutine 实现了有栈协程,且实现了对称(symmetric)和非对程(symmetric)协程。
1. 非对程协程(Asymmetric coroutine)
非对程协程提供了 asymmetric_coroutine<T>::push_type 和 asymmetric_coroutine<T>::pull_type 两种类型用于处理协程的协作。由命名可以理解,非对程协程像是创建了一个管道,通过push_type写入数据,通过pull_type拉取数据。
协程例子 A
boost::coroutines::asymmetric_coroutine<int>::pull_type source(
[&](boost::coroutines::asymmetric_coroutine<int>::push_type& sink){
int first=1,second=1;
sink(first);
sink(second);
for(int i=0;i<8;++i){
int third=first+second;
first=second;
second=third;
sink(third);
}
});
for(auto i : source)
std::cout << i << " ";
output:
1 1 2 3 5 8 13 21 34 55
上面的例子是协程实现的斐波那契数列计算,在上面的例子中,push_type 的实例构造时接受了一个函数作为构造函数入参,而这个函数就是 协程函数(coroutine function),coroutine 在 pull_type 创建的上下文下运行。
该协程函数的入参是一个以 push_type&,当实例化外层上下文中 pull_type 的时候,Boost 库会自动合成一个 push_type 传递给协程函数使用,每当调用 asymmetric_coroutine<>::push_type::operator() 的时候,协程会重新把控制权交还给push_type所在的上下文。其中asymmetric_coroutine<T> 的模板参数 T 定义了协程协作时使用的数据类型。
由于 pull_type 提供了input iterator,重载了 std::begin和std::end所以能够用 range-based for 循环方式来输出结果。
另外要注意的是,当第一次实例化pull_type的时候,控制权就会转移到协程上,执行协程函数,就好比要拉取(pull)数据需要有数据先写入(push)。
协程例子 B
struct FinalEOL{
~FinalEOL(){
std::cout << std::endl;
}
};
const int num=5, width=15;
boost::coroutines::asymmetric_coroutine<std::string>::push_type writer(
[&](boost::coroutines::asymmetric_coroutine<std::string>::pull_type& in){
// finish the last line when we leave by whatever means
FinalEOL eol;
// pull values from upstream, lay them out 'num' to a line
for (;;){
for(int i=0;i<num;++i){
// when we exhaust the input, stop
if(!in) return;
std::cout << std::setw(width) << in.get();
// now that we've handled this item, advance to next
in();
}
// after 'num' items, line break
std::cout << std::endl;
}
});
std::vector<std::string> words{
"peas", "porridge", "hot", "peas",
"porridge", "cold", "peas", "porridge",
"in", "the", "pot", "nine",
"days", "old" };
std::copy(boost::begin(words),boost::end(words),boost::begin(writer));
output:
peas porridge hot peas porridge
cold peas porridge in the
pot nine days old
接下来的这个例子主要说明了控制的反转,通过在主上下文中实例化的类型是push_type,逐个传递一系列字符串给到协程函数完成格式化输出,其构造函数是以pull_type&作为入参的匿名函数,在实例化push_type的过程中,库仍然会合成一个pull_type传递给该匿名函数,也就是协程函数。
与实例化pull_type不同,在主上下文中实例化push_type并不会直接进入到协程函数中,而是需要调用push_type::operator() 才能切换到协程上。
asymmetric_coroutine<T> 的模板参数 T 的类型不是 void 的时候,在协程函数中,可以通过pull_type::get()来获取数据,并通过pull_type::bool()判断协程传递的数据是否合法。
协程函数会以一个简单的return语句回到调用方的routine上,此时pull_type和push_type都会变成完成状态,也就是pull_type::operator bool()和push_type::operator bool() 都会变成 false;
协程的异常处理
coroutine函数内的代码不能阻止 unwind 的异常,不然会 stack-unwinding失败。
stack unwinding 通常和异常处理一起讨论,当异常抛出的时候,执行权限会立即向上传递直到任意一层 catch 住抛出的异常,而在向上传递前,需要适当地回收、析构本地自动变量,如果一个自动变量在异常抛出的时候被合适地被释放了就可以称为"unwound"了。
try {
// code that might throw
} catch(const boost::coroutines::detail::forced_unwind&) {
throw;
} catch(...) {
// possibly not re-throw pending exception
}
在 coroutine 内部捕获到了 detail::forced_unwind 异常时要继续抛出异常,否则会 stack-unwinding 失败,另外在 push_type 和 pull_type 的构造参数 attribute 也控制是是否需要 stack-unwinding。
2. 对称协程(Symmetric coroutine)
相对于非对称协程来说,对称协程能够转移执行控制给任意对称协程。
std::vector<int> merge(const std::vector<int>& a,const std::vector<int>& b)
{
std::vector<int> c;
std::size_t idx_a=0,idx_b=0;
boost::coroutines::symmetric_coroutine<void>::call_type* other_a=0,* other_b=0;
boost::coroutines::symmetric_coroutine<void>::call_type coro_a(
[&](boost::coroutines::symmetric_coroutine<void>::yield_type& yield) {
while(idx_a<a.size())
{
if(b[idx_b]<a[idx_a]) // test if element in array b is less than in array a
yield(*other_b); // yield to coroutine coro_b
c.push_back(a[idx_a++]); // add element to final array
}
// add remaining elements of array b
while ( idx_b < b.size())
c.push_back( b[idx_b++]);
});
boost::coroutines::symmetric_coroutine<void>::call_type coro_b(
[&](boost::coroutines::symmetric_coroutine<void>::yield_type& yield) {
while(idx_b<b.size())
{
if (a[idx_a]<b[idx_b]) // test if element in array a is less than in array b
yield(*other_a); // yield to coroutine coro_a
c.push_back(b[idx_b++]); // add element to final array
}
// add remaining elements of array a
while ( idx_a < a.size())
c.push_back( a[idx_a++]);
});
other_a = & coro_a;
other_b = & coro_b;
coro_a(); // enter coroutine-fn of coro_a
return c;
}
std::vector< int > a = {1,5,6,10};
std::vector< int > b = {2,4,7,8,9,13};
std::vector< int > c = merge(a,b);
print(a);
print(b);
print(c);
output:
a : 1 5 6 10
b : 2 4 7 8 9 13
c : 1 2 4 5 6 7 8 9 10 13
上面的例子是使用对称协程实现的一个有序数组的合并,对称协程提供了相类似的symmetric_coroutine<>::call_type 和 symmetric_coroutine<>::yield_type 两种类型用于对称协程的协作。call_type 在实例化的时候,需要接受一个以yield_type& 作为参数的(协程)函数进行构造,Boost库会自动合成一个yield_type作为实参进行传递,并且实例化 call_type 的时候,不会转移控制到协程函数上,而是在第一次调用call_type::operator()的时候才会进入到协程内。
yield_type::operator() 的调用需要提供两个参数,分别是需要转移控制的协程和需要传递的值,如果 symmetric_coroutine<T> 的模板参数类型是 void,那么不需要提供值,只是简单的转移控制。
在异常处理和退出方面,对称协程和非对称协程基本一致,非对程提供了一种多协程协作方案。
结语
虽然 Boost.Coroutine 库已经被标记为标记为已过时(deprecated)了,但是可以从历史的角度来理解协程的分类和基本工作原理,为现在多样化的协程探索拓宽道路。
协程Part1-boost.Coroutine.md的更多相关文章
- Lua的协程(coroutine)
-------------------------------------------------------------------------------- -- 不携带参数 ---------- ...
- coroutine协程
如果你接触过lua这种小巧的脚本语言,你就会经常接触到一个叫做协程的神奇概念.大多数脚本语言都有对协程不同程度的支持.但是大多编译语言,如C/C++,根本就不知道这样的东西存在.当然也很多人研究如何在 ...
- Coroutine(协程)模式与线程
概念 协程(Coroutine)这个概念最早是Melvin Conway在1963年提出的,是并发运算中的概念,指两个子过程通过相互协作完成某个任务,用它可以实现协作式多任务,协程(coroutine ...
- 云风协程库coroutine源码分析
前言 前段时间研读云风的coroutine库,为了加深印象,做个简单的笔记.不愧是大神,云风只用200行的C代码就实现了一个最简单的协程,代码风格精简,非常适合用来理解协程和用来提升编码能力. 协程简 ...
- 实现一个简单的C++协程库
之前看协程相关的东西时,曾一念而过想着怎么自己来实现一个给 C++ 用,但在保存现场恢复现场之类的细节上被自己的想法吓住,也没有深入去研究,后面一丢开就忘了.近来微博上看人在讨论怎么实现一个 user ...
- 浅谈Go语言的Goroutine和协程
0x00.前言 前面写了一篇初识Go语言和大家一起学习了Go语言的巨大潜力.语言简史.杀手锏特性等,感兴趣的读者可以回顾一下. 今天来学习Go语言的Goroutine机制,这也可能是Go语言最为吸引人 ...
- Python PEP 492 中文翻译——协程与async/await语法
原文标题:PEP 0492 -- Coroutines with async and await syntax 原文链接:https://www.python.org/dev/peps/pep-049 ...
- Lua学习笔记(六):协程
多线程和协程 多线程是抢占式多任务(preemptive multitasking),每个子线程由操作系统来决定何时执行,由于执行时间不可预知所以多线程需要使用同步技术来避免某些问题.在单核计算机中, ...
- Lua 5.3 协程简单示例
Lua 5.3 协程简单示例 来源 http://blog.csdn.net/vermilliontear/article/details/50547852 生产者->过滤器->消费者 模 ...
- Golang源码探索(二) 协程的实现原理
Golang最大的特色可以说是协程(goroutine)了, 协程让本来很复杂的异步编程变得简单, 让程序员不再需要面对回调地狱, 虽然现在引入了协程的语言越来越多, 但go中的协程仍然是实现的是最彻 ...
随机推荐
- C# 常见面试问题
C# 常见面试问题 EntityFramework 数据持久化 C#中的委托是什么?事件是不是一种委托? C#中的委托是一种引用类型,表示具有相同方法签名的方法的引用.类似于函数指针,也就是说它们是指 ...
- MyBatis创建第二个项目
MyBatis创建第二个项目 Mysql文件配置 /* Navicat Premium Data Transfer Source Server : Mybatis Source Se ...
- 分布式MinIO快速入门
官方文档地址:http://docs.minio.org.cn/docs/master/distributed-minio-quickstart-guide Minio服务基于命令行传入的参数自动切换 ...
- MySQL 的七种日志总结
文章转载自:https://mp.weixin.qq.com/s/ewv7HskHvH3O7kFyOmoqgw 一.MySQL 日志分类 日志类别 说明 备注 错误日志 错误日志记录了当MySQL启动 ...
- 【.NET 6+Loki+Grafana】实现轻量级日志可视化服务功能
前言:日志功能是几乎所有程序或系统都必备的一个功能.该文章通过使用Loki+Grafana来实现日志记录与可视化查询,欢迎围观. 有关环境: 操作系统:WIN 10 .NET环境:.NET 6 开发环 ...
- 洛谷P4513 小白逛公园 (线段树)
这道题看起来像是线段树和最大子段和的结合,但这里求最大子段和不用dp,充分利用线段树递归的优势来处理.个人理解:线段树相当于把求整个区间的最大子段和的问题不断划分为很多个小问题,容易解决小问题,然后递 ...
- 微信电脑版DAT文件转图片工具
一键批量将微信聊天接受到的加密存储DAT图片文件转化为普通图片. 通过查看转化后的图片,您可以: (1)清理无用的历史图片,节省电脑硬盘存储空间. (2)恢复寻找重要照片资料. 下载地址:点此下载 微 ...
- MyBatis(介绍和环境配置)
ORM(Object Relational Mapping) 设计模式,思想 对象关系映射,是一种数据持久化技术.它在对象模型和关系型数据库之间建立起对应关系,并且提供了一种机制,通过JavaBea ...
- iframe的简单使用
看人家写的真的是摸不着头脑.自己写.还是清楚 局部数据的刷新:可以使用ajax.这里只是简单的演示 只作:例子使用.简单演示页面跳转 a标签中target属性和iframe中的name对应.相当于将该 ...
- 最近无聊搭建一个齐博X1的下载页面
https://layui.wanxiangsucai.com/ 用layui官方镜像站的模版 改了个齐博X1的下载页面 https://x1.wanxiangsucai.com/ 哈哈哈!!! 还有 ...