python数据可视化-matplotlib入门(7)-从网络加载数据及数据可视化的小总结
除了从文件加载数据,另一个数据源是互联网,互联网每天产生各种不同的数据,可以用各种各样的方式从互联网加载数据。
一、了解 Web API
Web 应用编程接口(API)自动请求网站的特定信息,再对这些信息进行可视化。每次运行,都会获取最新的数据来生成可视化,因此即便网络上的数据瞬息万变,它呈现的信息也都是最新的。
Web API是网站的一部分,用于与使用非常具体的URL请求特定信息的程序交互。这种请求称为API调用。请求的数据将以易于处理的格式(如JSON或CSV)返回。
GitHub(https://github.com/)上的项目都存储在仓库中,后者包含与项目相关联的一切:代码、项目参与者的信息、问题或bug报告等,编写一个自动下载GitHub上的Python项目的相关信息。
在浏览器中打开: https://api.github.com/search/repositories?q=language:python&sort=stars,可以看到如下内容,
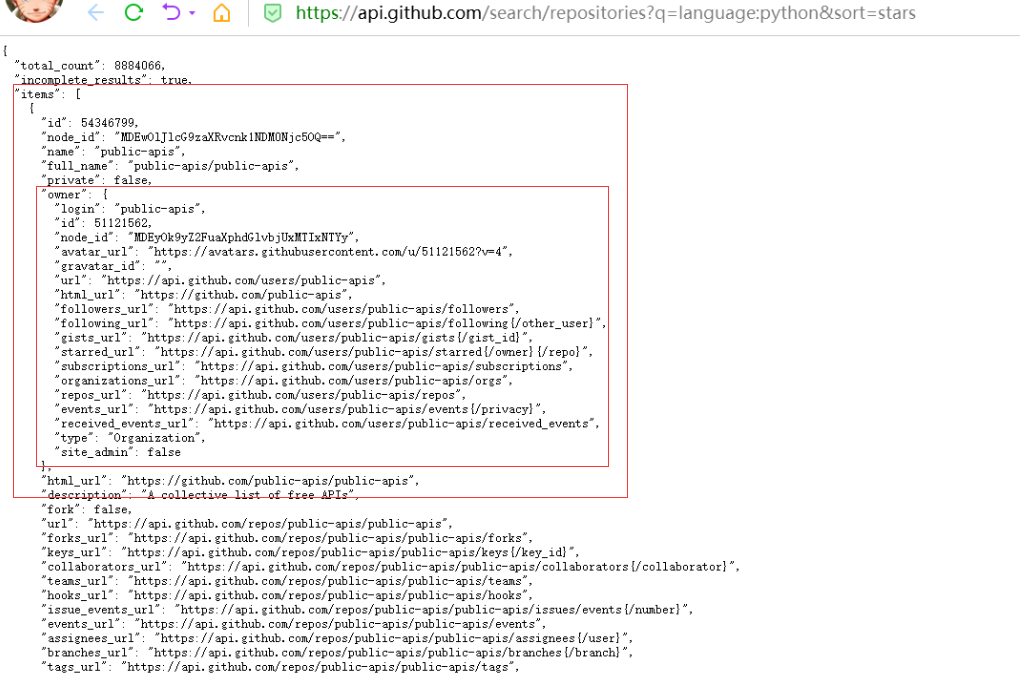
此调用返回GitHub当前托管了total_count 8884066个Python项目,还有最受欢迎的Python仓库的信息。
其中第一部分( https://api.github.com/ )将请求发送到GitHub网站中响应API调用的部分;
第二部分( search/repositories )让API搜索GitHub上的所有仓库。
repositories 后面的问号指出我们要传递一个实参。 q 表示查询,而等号让我们能够开始指定
查询( q= )。通过使用 language:python ,我们指出只想获取主要语言为Python的仓库的信息。
最后一部分( &sort=stars )指定将项目按其获得的星级进行排序。
但我们不能每次通过打开网页的形式来获取数据。但可以通过python中相关库
二、安装 requests
requests是一个很实用的Python HTTP客户端库,专门用于发送HTTP请求,方便编程,编写爬虫和测试服务器响应数据时经常会用到,
Requests主要相关参数有:
r.status_code 响应状态码
r.heards 响应头
r.cookies 响应cookies
r.text 响应文本
r. encoding 当前编码
r. content 以字节形式(二进制)返回
鉴于一直都使用的是anaconda3,可直接打开 anaconda prompt,然后输入命令:pip install --user requests 安装即可。
下面来编写一个程序,执行API调用并处理结果,找出GitHub上星级最高的Python项目,代码如下:
import requests # 导入模块requests url='https://api.github.com/search/repositories?q=language:python&sort=stars'#存储API调用的URL
r = requests.get(url) # 调用get()并将URL传递给它,响应对象存储在变量 r中
print("Status code:",r.status_code) #包含一个名为status_code的属性
response_dict = r.json() # 使用方法json()将这些信息转换为一个Python字典
print(response_dict.keys()) #打印出字典的key
上述代码有两行打印,运行结果如下:
Status code: 200
dict_keys(['total_count', 'incomplete_results', 'items'])
状态码为200,请求成功。响应字典包含三个键: 'total_count'和 'incomplete_results'和 'items'
将API调用返回的信息存储到字典中,就可以利用前面了解的字典的键-值对来研究自己喜欢的信息了。
三、整理字典中的信息
上述代码response_dict = r.json()实际上已将请求信息转为字典,那查看一下字典里有些什么内容。
从浏览器中打开的内容可以看到,返回的内容中是字典中包含字典
(items是作为最上那个大括号中的key,对应的值,是由多个字典组成的字典列表,‘id’,‘node_id’,‘name’等也是items列表中第一子字典的key,见红色方框部分,列表字典等相互嵌套,好好分析一下)。
1)先看一下与 'total_count'关联的值
print("Total repositories:", response_dict['total_count'])
2)items本身是一个字典,‘id’,‘node_id’,‘name’等均是key,后面对应的都是值,可以查一下有多少个key
repo_dicts = response_dict['items'] #建一个变量字典repo_dicts,将items字典列表存储在 repo_dicts
print("Repositories returned:", len(repo_dicts))# 打 repo_dicts的长度,获得item字典的长度信息
3)查看第一个item的详细信息,并打印出所有key
repo_dict = repo_dicts[0] #提取了repo_dicts中的第一个字典
print("\nKeys:", len(repo_dict)) #打印这个字典包含的键数
print("\n")
for key in repo_dict.keys():#打印这个字典的所有键
print(key)
整体运行结果(下图白色部分为浏览器打开):
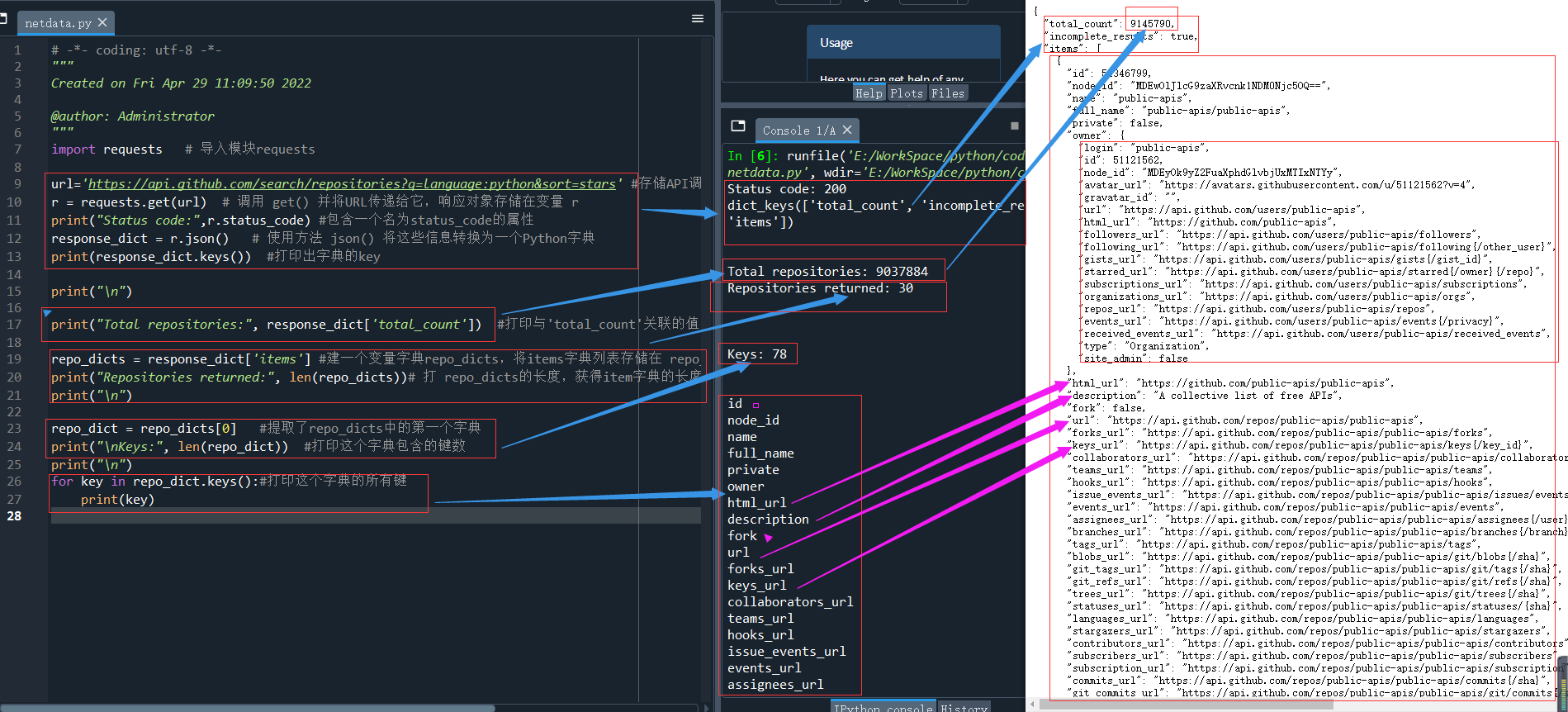
思考一下,为什么图中的Total repositories一个是9037884,另一个为9145790,两者不一致?
有了key,就很容易查询到相关的值了(当然这里都是字符串,如果是数字型的就能可视化)
四,数字可视化
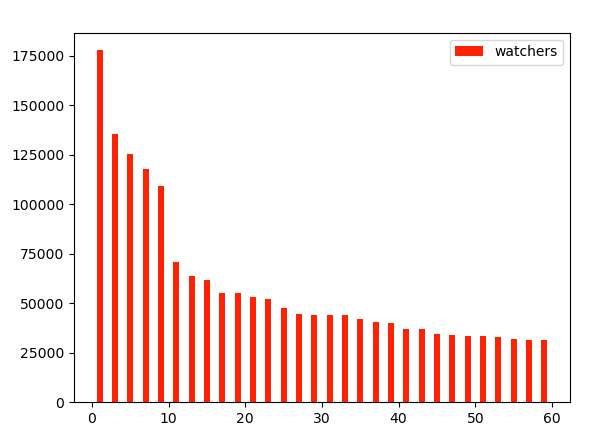
通过浏览器打开页面,会发现"forks": 32471, "open_issues": 305, "watchers": 177777等有相关数据,于是,可以通过对应的key,将相关数据整合成一个数据列表,然后显示出来,比如可视化wathers
count=0
watchers, counts= [], []
for repo_dict in repo_dicts:
watchers.append(repo_dict['watchers'])
count += 1
counts.append(count) plt.bar(counts,watchers, label="watchers", color='#ff2204')
plt.legend()
plt.show()
运行结果:
五、数据可视化的小总结:
matplotlib中数据可视化的方法主要就是调用pyplot接口,再直接调用对象的建立方法,在方法中对该对象进行相应的属性设置,所以掌握这种方法的核心就在于掌握每种对象的建立方法和具体参数设置。Python数据可视化的难处在于掌握参数的设置,内置的参数虽然很多,但一般都用不上(可以留着慢慢钻研),将用得上的参数和参数值几何整理下来,做到这样,对于Python的可视化学习暂时足矣。剩下的时间该去学习其他更为有用的!
简而化之,
曲线图 plt.plot(squares, linewidth=5) 只需要提供一组数据即可
散点图 plt.scatter(x, y,c='r',edgecolor='none',s=100) ,x,y分别为x轴,y轴坐标位置,x,y对应
柱图 plt.bar(x,y, label="Test one", color='r') x为x轴位置,y为值,x如为数列,则y对应相同长度
柱图 plt.hist(list, bins, histtype='bar', rwidth=0.8,color='r') bins为柱图划分范围,表现在x轴上,list为数列,显示在y 轴
饼图 plt.pie(slices) slices 为一数列
堆叠图 plt.stackplot(days, times,labels=labellist,colors=colorlist) days为一维数列,times为多维数列,每一维数列元素个数与days一样。
python数据可视化-matplotlib入门(7)-从网络加载数据及数据可视化的小总结的更多相关文章
- echarts 图表重新加载,原来的数据依然存在图表上
问题 在做一个全国地图上一些饼图,并且向省一级的地图钻取的时候,原来的饼图依然显示 原因 echars所有添加的图表都在一个series属性集合中,并且同一个echars对象默认是合并之前的数据的,所 ...
- Python 绘图库Matplotlib入门教程
0 简单介绍 Matplotlib是一个Python语言的2D绘图库,它支持各种平台,并且功能强大,能够轻易绘制出各种专业的图像. 1 安装 pip install matplotlib 2 入门代码 ...
- IOS空数据页面,网络加载失败以及重新登陆View的封装(不需要继承)
一.问题 对于B2C和B2B项目的开发者,可能会有一个订单列表为空,或者其他收藏页面为空,用户token失效,判断用户要重新登陆,以及后台服务错误等提示.本篇课文,看完大约10分钟. 原本自己不想写空 ...
- [原创.数据可视化系列之三]使用Ol3加载大量点数据
不管是百度地图还是高德地图,都很难得见到在地图上加载大量点要素,比如同屏1000的,因为这样客户端性能会很低,尤其是IE系列的浏览器,简直是卡的要死.但有的时候,还真的需要,比如,我要加载全球的AQI ...
- 【4】TensorFlow光速入门-保存模型及加载模型并使用
本文地址:https://www.cnblogs.com/tujia/p/13862360.html 系列文章: [0]TensorFlow光速入门-序 [1]TensorFlow光速入门-tenso ...
- android快捷开发之Retrofit网络加载框架的简单使用
大家都知道,安卓最大的特点就是开源化,这自然会产生很多十分好用的第三方API,而基本每一个APP都会与网络操作和缓存处理机制打交道,当然,你可以自己通过HttpUrlConnection再通过返回数据 ...
- android 网络加载图片,对图片资源进行优化,并且实现内存双缓存 + 磁盘缓存
经常会用到 网络文件 比如查看大图片数据 资源优化的问题,当然用开源的项目 Android-Universal-Image-Loader 或者 ignition 都是个很好的选择. 在这里把原来 ...
- iOS网络加载图片缓存策略之ASIDownloadCache缓存优化
iOS网络加载图片缓存策略之ASIDownloadCache缓存优化 在我们实际工程中,很多情况需要从网络上加载图片,然后将图片在imageview中显示出来,但每次都要从网络上请求,会严重影响用 ...
- Swift语法基础入门四(构造函数, 懒加载)
Swift语法基础入门四(构造函数, 懒加载) 存储属性 具备存储功能, 和OC中普通属性一样 // Swfit要求我们在创建对象时必须给所有的属性初始化 // 如果没办法保证在构造方法中初始化属性, ...
随机推荐
- Eureka和ZooKeeper都可以提供服务注册与发现的功能,请说说两个的区别?
1.ZooKeeper保证的是CP,Eureka保证的是AP ZooKeeper在选举期间注册服务瘫痪,虽然服务最终会恢复,但是选举期间不可用的 Eureka各个节点是平等关系,只要有一台Eureka ...
- springmvc对参数接收的两个注解@RequestParam和@RequestBody
@RequestParam 作用:将请求参数绑定到控制器的方法参数上,主要用于接收几班类型参数 语法:@RequestParam(value="参数名",required=&quo ...
- Spring 支持的 ORM?
Spring 支持以下 ORM:HibernateiBatisJPA (Java Persistence API)TopLinkJDO (Java Data Objects)OJB
- 32 位和 64 位的 JVM,int 类型变量的长度是多数?
32 位和 64 位的 JVM 中,int 类型变量的长度是相同的,都是 32 位或者 4个字节.
- SpringCloud个人笔记-03-Config初体验
sb-cloud-config 配置中心 <?xml version="1.0" encoding="UTF-8"?> <project xm ...
- STM32 标准库
CMSIS 标准及库层次关系 因为基于Cortex 系列芯片采用的内核都是相同的,区别主要为核外的片上外设的差异,这些差异却导致软件在同内核,不同外设的芯片上移植困难.为了解决不同的芯片厂商生产的Co ...
- IdentityServer4系列 | 支持数据持久化
一.前言 在前面的篇章介绍中,一些基础配置如API资源.客户端资源等数据以及使用过程中发放的令牌等操作数据,我们都是通过将操作数据和配置数据存储在内存中进行实现的,而在实际开发生产中,我们需要考虑如何 ...
- PAT B1013 数素数
输入样例: 5 27 输出样例: 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 解题思路: 从2开始 ...
- idea启动tomcat后控制台日志显示中文乱码问题
想必有些人 会遇到 控制台中文乱码: 可以通过以下方法解决该中文乱码问题: 1. 点击Help => Edit custom VM Options,在最后面添加 "-Dfile.en ...
- Exchange日志清理
1.清理日志--完整备份 Exchange Server 2013被部署在Windows Server 2012 及以上版本的操作系统中,使用操作系统内的"Windows Server Ba ...