LevelDB源码分析--Cache及Get查找流程
本打算接下来分析version相关的概念,但是在准备的过程中看到了VersionSet的table_cache_这个变量才想起还有这样一个模块尚未分析,经过权衡觉得leveldb的version相对Cache来说相对复杂,而且version虽然对整个leveldb来说实现上跟其他功能十分紧密,但是从概念上来说却相对弱很多,有点感觉是附加的功能的感觉。所以从介绍系统首先应该注意的是整个系统概念的完整性的角度说还是先分析Cache相关的功能。
我们先来看Cache的基本框架结构数据:
struct LRUHandle {
void* value; //cache的对象句柄,table的时候为table&file, block时为(table&file)_offset
void (*deleter)(const Slice&, void* value); //回调函数
LRUHandle* next_hash; //hash表冲突解决指针
LRUHandle* next; //LRU双链表指针
LRUHandle* prev; //LRU双链表指针
size_t charge; // TODO(opt): Only allow uint32_t?
size_t key_length;
uint32_t refs;
uint32_t hash; //根据key计算出的hash值,实现在hash.cc中
char key_data[]; // encode后的file_num
};
HandleTable是一个简单的hashtable的链式实现,其成员如下:
HandleTable{
uint32_t length_;
uint32_t elems_;
LRUHandle** list_;
};
LRUCache包含了一个HashTable(HandleTable)和一个双向链表头及容量、使用情况、互斥锁,每当insert的时候会同时插入HashTable中和双向链表中。
LRUCache{
size_t capacity_;
port::Mutex mutex_;
size_t usage_;
LRUHandle lru_;
HandleTable table_;
};
LRUCache的与HandleTable和LRUHandle(途中绿色框)之间的基本关系图可以描述如下:
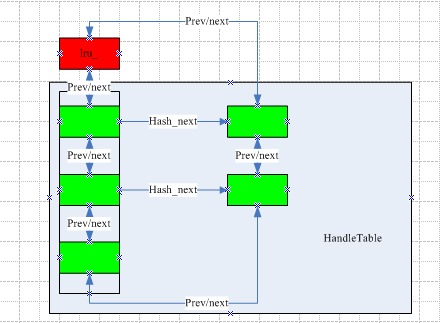
为了图形的简化,其中的地址和对象的关系未完整展现,lru_是对象而其他的绿色框都应该是表示的地址,大致图形便于理解,具体的关系请参阅源码。
ShardedLRUCache结构就更为简单,就是一个LRUCahce的数组,这样可以简单的集合封装多个LRUCache来达到分片降低锁的粒度增加并发度的目的。
在了解了基本关系之后要去理解其中的代码就十分简单了,这里不再一一列举,唯一要说明的是HandleTable 的hash自动增长模式,当HandleTable中的element 大于其hash数组大小的时候就对数组进行resize为最小的大于当前element个数的4的倍数,再将旧的element迁移到新的hash数组中。
if (elems_ > length_)
Resize();
void Resize() {
uint32_t new_length = ;
while (new_length < elems_) {
new_length *= ;
}
LRUHandle** new_list = new LRUHandle*[new_length]; //新建hash数组
for (uint32_t i = ; i < length_; i++) { //将原始的element迁移至新hash数组
LRUHandle* h = list_[i];
while (h != NULL) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - )];
h->next_hash = *ptr;
*ptr = h;
h = next;
count++;
}
}
delete[] list_;//删除就数组、使用新表
list_ = new_list;
length_ = new_length;
}
};
以上就是leveldb中关于LRUCache的基本结构了,但是leveldb在使用过程中又进行了一些变异和封装,如TableCache和DBImpl中的一个block_cache。我们这里先来对这两个概念进行一下梳理:由代码可以看出TableCache缓存的只是一个Table对象和RandomAccessFile对象的引用。而从Table::Open函数可以知道这个Table对象只保存了基本的管理信息(具体包括的内容前面的文章已经阐述过,请仔细查证),所以Table中的实际数据并未缓存其中。那么其中的实际数据在什么地方缓存呢?这里leveldb用到了另外的一个option中的ShardedLRUCache,当然这个cache由于是在option中那么说明其实可以改变的,你可以根据你的业务目标自行设计一个。到此你可能有点晕了,leveldb我要在cache中获取一个KV对的流程是怎么样的呢?这么设计的原因是什么呢?
第一个问题:leveldb中的Cache其实也是实现了分层,先cache一个SSTable的基本信息,而不是将整个SSTable的读到内存;再用一个cache缓存SSTable下一层级的实际的Block数据。那么获取数据的时候就得先根据基本信息获取到大致的SSTable,得到SSTable的句柄,再根据SSTable缓存中的基本信息获得应该去哪个block的信息,然后再根据block的句柄得到(SSTable句柄+Block句柄)去block缓存中获取实际的数据。
第二个问题:由于分层而不是将整个SSTable一次性的缓存到内存,那么得到的好久就显而易见了,可以减少内存的占用量。
我们来浏览一下Table_cache中各个函数的功能,首先看Get
Status TableCache::Get(const ReadOptions& options,
uint64_t file_number, //file句柄
uint64_t file_size,
const Slice& k, //查找的key
void* arg,
void (*saver)(void*, const Slice&, const Slice&)) {
Status s = FindTable(file_number, file_size, &handle); //查找到Cache handle
if (s.ok()) {
Table* t = reinterpret_cast<TableAndFile*>(cache_->Value(handle))->table;
s = t->InternalGet(options, k, arg, saver);
cache_->Release(handle);
}
return s;
}
再看FindTable:
Status TableCache::FindTable(uint64_t file_number, uint64_t file_size,
Cache::Handle** handle) { EncodeFixed64(buf, file_number); //根据file_num组一个key
Slice key(buf, sizeof(buf));
*handle = cache_->Lookup(key); //查找当前SSTable的信息是否已经在Table_cache中
if (*handle == NULL) { //如果不在则打开SSTable,
std::string fname = TableFileName(dbname_, file_number);
s = env_->NewRandomAccessFile(fname, &file);//尝试ldb后缀
if (!s.ok()) {
std::string old_fname = SSTTableFileName(dbname_, file_number); //尝试sst后缀
if (env_->NewRandomAccessFile(old_fname, &file).ok()) {
s = Status::OK();
}
}
if (s.ok()) {
s = Table::Open(*options_, file, file_size, &table); //读取文件管理信息生成Table对象
}
if (!s.ok()) {
} else { //将内容缓存至TableCache中
TableAndFile* tf = new TableAndFile;
tf->file = file;
tf->table = table;
*handle = cache_->Insert(key, tf, , &DeleteEntry);
}
}
return s;
}
再看Table的InternalGet,其功能是在SSTable中查找key。这里我们需要明确的一件事情是我们的内部迭代器Seek某个key的时候,都是返回一个>=该key的一个位置。具体可以参照SkipList中的Seek,他简单调用了一个FindGreaterOrEqual的函数,这个函数的意思就极其明显了。那么当我们得到这个位置以后必须判断该位置的key是否是我们查找的可以,如果是查找的key才将对应的value保存起来,这个工作就是由传入的saver函数来执行的。具体代码可以查看SaveValue这个函数。我们这里详细分析这个InternalGet
Status Table::InternalGet(const ReadOptions& options, const Slice& k,
void* arg,
void (*saver)(void*, const Slice&, const Slice&)) {
Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator);
iiter->Seek(k); //查找key可能存在的block
if (iiter->Valid()) {
if (filter != NULL &&
handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) { //根据bloomfilter判断是否在块中
// Not found
} else {
Iterator* block_iter = BlockReader(this, options, iiter->value());
block_iter->Seek(k); //读取block内容然后在block中查找
if (block_iter->Valid()) {
(*saver)(arg, block_iter->key(), block_iter->value());
}
s = block_iter->status();
delete block_iter;
}
}
if (s.ok()) {
s = iiter->status();
}
delete iiter;
return s;
}
另外TableCache中还有一个NewIterator的函数,顾名思义他就是生成一个遍历Cache的SSTable的迭代器,他基本上也是简单的调用Table 的 NewIterator。leveldb的Iterator设计也比较精妙,比如NewTwoLevelIterator这个东西,我们稍后会有篇幅来介绍,这里你只需要知道他就是生成一个遍历SSTable的迭代器就可以了。
理清了基本数据关系,最后就该轮到介绍我们大家最关心的DB_Impl的Get函数了,由于DB_Impl是DB虚类的一个子类,所以用户调用DB的get的时候实际调用的是这个函数的实现。
Status DBImpl::Get(const ReadOptions& options,
const Slice& key,
std::string* value) {
// 锁,Sequence,version,ref等一系列的一些设置
{
//查找是否在memtable中,这是最新的数据
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != NULL && imm->Get(lkey, value, &s)) {
// 查找是否在imutable memtable中,这是次新的数据
} else {
s = current->Get(options, lkey, value, &stats); //否则到当前版本中的SSTable中查找
have_stat_update = true;
}
}
//其他一些处理,以及判断是否需要出发compaction
return s;
}
这个Get从代码中可以看到调用了Memtable的Get和当前version(current)的Get,我们来看看当前version中的查找:
Status Version::Get(const ReadOptions& options,
const LookupKey& k,
std::string* value,
GetStats* stats) {
// 从0级开始一级一级查找,0级最新,1级次新,依次更旧,
//所以查找的时候不能跳跃级别 ,找到最新的数据以后旧的数据就不在需要了
for (int level = ; level < config::kNumLevels; level++) {
size_t num_files = files_[level].size();
if (num_files == ) continue;
//取得文件句柄
FileMetaData* const* files = &files_[level][];
if (level == ) {
// Level-0 需要查找全部文件,因为level-0中可能存在重叠
for (uint32_t i = ; i < num_files; i++) {
FileMetaData* f = files[i];
if (ucmp->Compare(user_key, f->smallest.user_key()) >= &&
ucmp->Compare(user_key, f->largest.user_key()) <= ) {
tmp.push_back(f);
}
}
//按文件新旧程度排序,新的在最前面
std::sort(tmp.begin(), tmp.end(), NewestFirst);
files = &tmp[];
num_files = tmp.size();
} else {
// 找到第一个 largest key >= ikey的文件(SSTable).
uint32_t index = FindFile(vset_->icmp_, files_[level], ikey); tmp2 = files[index];
if (ucmp->Compare(user_key, tmp2->smallest.user_key()) < ) {
// 不在该文件中
files = NULL;
num_files = ;
} else {
files = &tmp2;
num_files = ;
}
}
//找到具体的SSTable以后在该SSTable的缓存中进行具体查找
s = vset_->table_cache_->Get(options, f->number, f->file_size,
ikey, &saver, SaveValue);
switch (saver.state) {
case kNotFound:
break; // 继续查找,知道找出的所有文件都查找完
case kFound:
return s;
case kDeleted:
s = Status::NotFound(Slice()); // 已经被删除,直接返回
return s;
case kCorrupt:
s = Status::Corruption("corrupted key for ", user_key);
return s;
}
}
}
return Status::NotFound(Slice()); // Use an empty error message for speed
}
LevelDB源码分析--Cache及Get查找流程的更多相关文章
- Leveldb源码分析--1
coming from http://blog.csdn.net/sparkliang/article/details/8567602 [前言:看了一点oceanbase,没有意志力继续坚持下去了,暂 ...
- leveldb源码分析--Key结构
[注]本文参考了sparkliang的专栏的Leveldb源码分析--3并进行了一定的重组和排版 经过上一篇文章的分析我们队leveldb的插入流程有了一定的认识,而该文设计最多的又是Batch的概念 ...
- leveldb源码分析--SSTable之block
在SSTable中主要存储数据的地方是data block,block_builder就是这个专门进行block的组织的地方,我们来详细看看其中的内容,其主要有Add,Finish和CurrentSi ...
- leveldb源码分析--WriteBatch
从[leveldb源码分析--插入删除流程]和WriteBatch其名我们就很轻易的知道,这个是leveldb内部的一个批量写的结构,在leveldb为了提高插入和删除的效率,在其插入过程中都采用了批 ...
- RecyclerView 源码分析(一) —— 绘制流程解析
概述 对于 RecyclerView 是那么熟悉又那么陌生.熟悉是因为作为一名 Android 开发者,RecyclerView 是经常会在项目里面用到的,陌生是因为只是知道怎么用,但是却不知道 Re ...
- angularjs源码分析之:angularjs执行流程
angularjs用了快一个月了,最难的不是代码本身,而是学会怎么用angular的思路思考问题.其中涉及到很多概念,比如:directive,controller,service,compile,l ...
- leveldb源码分析--日志
我们知道在一个数据库系统中为了保证数据的可靠性,我们都会记录对系统的操作日志.日志的功能就是用来在系统down掉的时候对数据进行恢复,所以日志系统对一个要求可靠性的存储系统是极其重要的.接下来我们分析 ...
- leveldb源码分析之Slice
转自:http://luodw.cc/2015/10/15/leveldb-02/ leveldb和redis这样的优秀开源框架都没有使用C++自带的字符串string,redis自己写了个sds,l ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
随机推荐
- 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)
不多说,直接上干货! 解决办法 因为,如下,我的Hadoop HA集群. 1.首先在hdfs-site.xml中添加下面的参数,该参数的值默认为false: <property> < ...
- Yum安装Zabbix4.2.0
目录 1. 下载所需的存储库 2. 安装zabbix 3. 安装mysql 4. 配置数据库 5. 基本配置 6. zabbix配置文件 7. 进入web安装zabbix 1. 下载所需的存储库 # ...
- j2ee高级开发技术课程第三周
一.分析Filter例子(轻量级javaee企业应用实战p132) // 执行过滤的核心方法 public void doFilter(ServletRequest request, ServletR ...
- Python高级特性: 函数编程 lambda, filter,map,reduce
一.概述 Python是一门多范式的编程语言,它同时支持过程式.面向对象和函数式的编程范式.因此,在Python中提供了很多符合 函数式编程 风格的特性和工具. 以下是对 Python中的函数式编程 ...
- FineUI开源版(ASP.Net)初学手册
女朋友鄙视我原创少... 1.下载 进入官方论坛:http://www.fineui.com/bbs/ 要用到下载源代码和空项目下载 http://fineui.codeplex.com/ http: ...
- 让浏览器兼容ES6语法(gulp+babel)
使用gulp+babel搭建ES6环境 前言 我们查阅资料可以知道ECMAScript 2015(简称ES6)已经于2015年发布,由于用户使用的浏览器版本在安装的时候可能早于ES6的发布,而到了今天 ...
- 看 Netty 在 Dubbo 中如何应用
目录: dubbo 的 Consumer 消费者如何使用 Netty dubbo 的 Provider 提供者如何使用 Netty 总结 前言 众所周知,国内知名框架 Dubbo 底层使用的是 Net ...
- vscode 自动提示Threejs
转自:https://blog.csdn.net/github_39125824/article/details/82633993 1.首先,你要安装Node.js 2.在vscode的 查看-> ...
- Spring加载properties文件的两种方式
在项目中如果有些参数经常需要修改,或者后期可能需要修改,那我们最好把这些参数放到properties文件中,源代码中读取properties里面的配置,这样后期只需要改动properties文件即可, ...
- 乐字节-Java8新特性之函数式接口
上一篇小乐带大家学过 Java8新特性-Lambda表达式,那什么时候可以使用Lambda?通常Lambda表达式是用在函数式接口上使用的.从Java8开始引入了函数式接口,其说明比较简单:函数式接口 ...